搜狗搜索日志分析系统
Posted handsome-24
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜狗搜索日志分析系统相关的知识,希望对你有一定的参考价值。
前奏:请提前搭建好你的集群和必要的软件:hadoop + jdk + hive + Sqoop + HBase;
数据(链接是网友的,感谢,感谢,感谢。里面有测试数据):链接:http://pan.baidu.com/s/1dFD7mdr 密码:xwu8
一:数据预处理(Linux 环境):
1 搜狗数据的数据格式: 2 访问时间 用户 ID [查询词] 该 URL 在返回结果中的排名 用户点击的顺序号 用户点击的 URL 3 其中,用户 ID 是根据用户使用浏览器访问搜索引擎时的 Cookie 信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户 ID。
1:查看数据,构建系统前,需要了解如何进行数据相关的预处理:
进入实验数据文件夹,然后进行less 查看: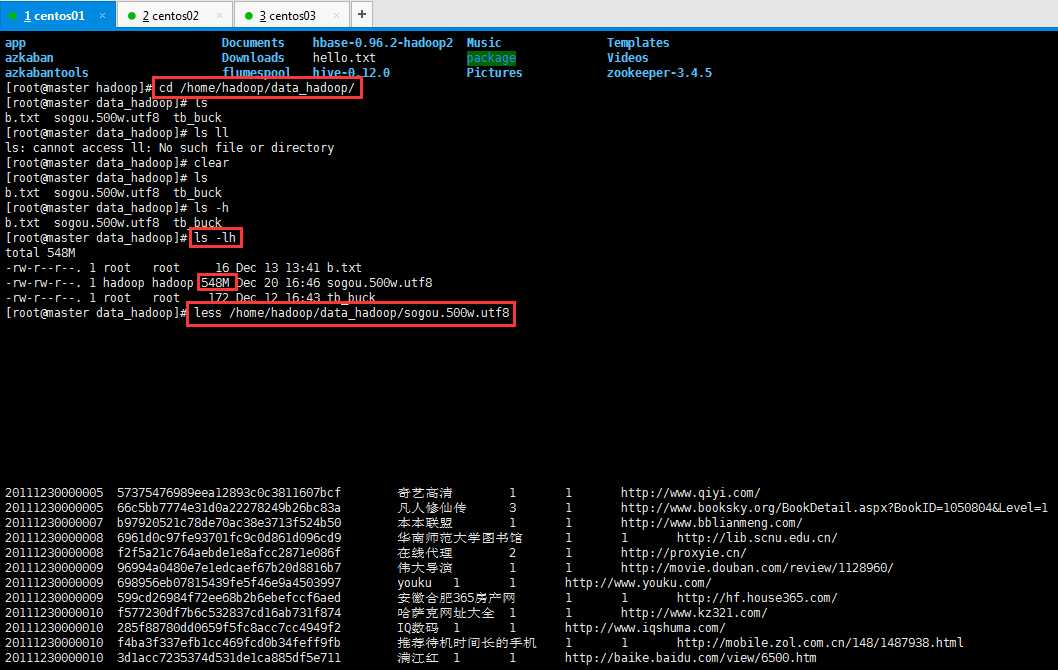
解决中文显示乱码问题:
本步骤已经完成从 gbk 转化为 utf-8 格式,不需要再操作。见下面目录,该目录是乱码清洗的 Java 代码:
查看总行数,如下所示(小等片刻):
1 [[email protected] data_hadoop]# wc -l /home/hadoop/data_hadoop/sogou.500w.utf8 2 5000000 /home/hadoop/data_hadoop/sogou.500w.utf8 3 [[email protected] data_hadoop]#
截取部分数据数据(此操作没卵用):
1 [[email protected] data_hadoop]# head -100 sogou.500w.utf8 > sogou.500w.utf8.demo 2 [[email protected] data_hadoop]# ls 3 b.txt sogou.500w.utf8 sogou.500w.utf8.demo tb_buck 4 [[email protected] data_hadoop]# wc -l sogou.500w.utf8.demo 5 100 sogou.500w.utf8.demo
2:数据扩展:
将时间字段拆分并拼接,添加年、月、日、小时字段;
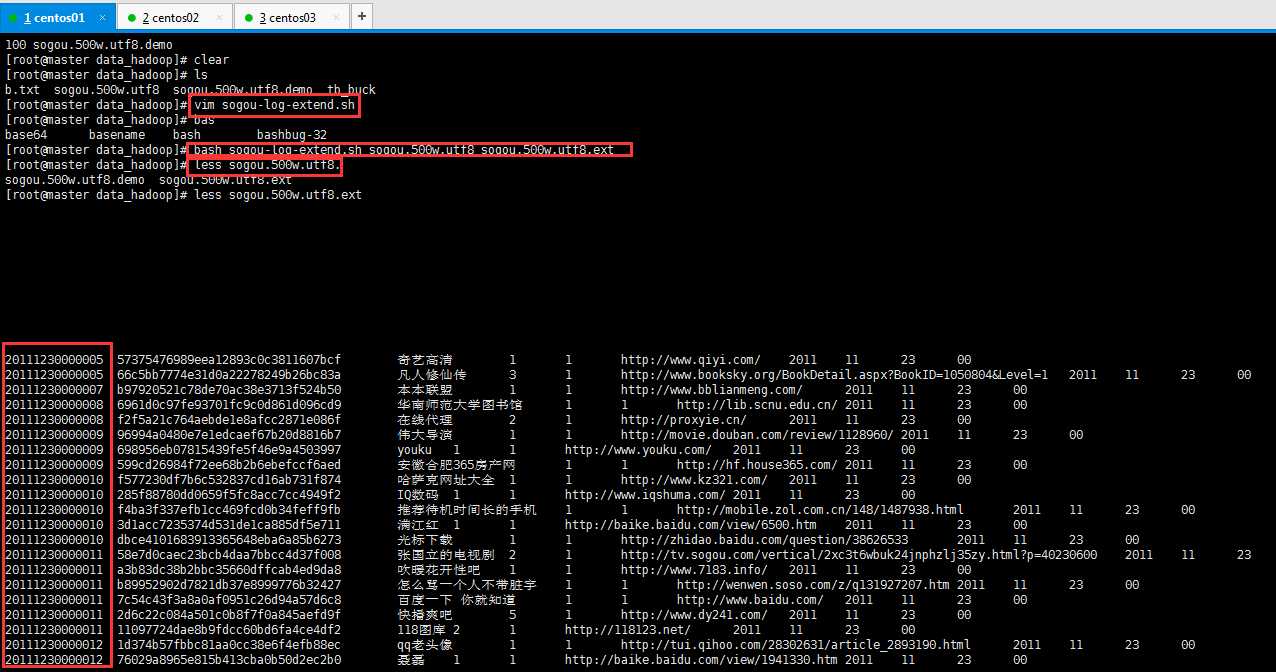
利用bash命令执行sogou-log-extend.sh文件,该文件的内容如下:
1 #!/bin/bash
2 #infile=/data/sogou-data/sogou.500w.utf8
3 infile=$1
4 #outfile=/data/sogou-data/sogou.500w.utf8.final
5 outfile=$2
6 awk -F ‘ ‘ ‘{print $0" "substr($1,0,4)" "substr($1,4,2)" "substr($1,6,2)" "substr($1,8,2)}‘ $infile > $outfile
3:数据过滤
过滤第 2 个字段(UID)或者第 3 个字段(搜索关键词)为空的行(需要用第 2 步数据扩展的结果):
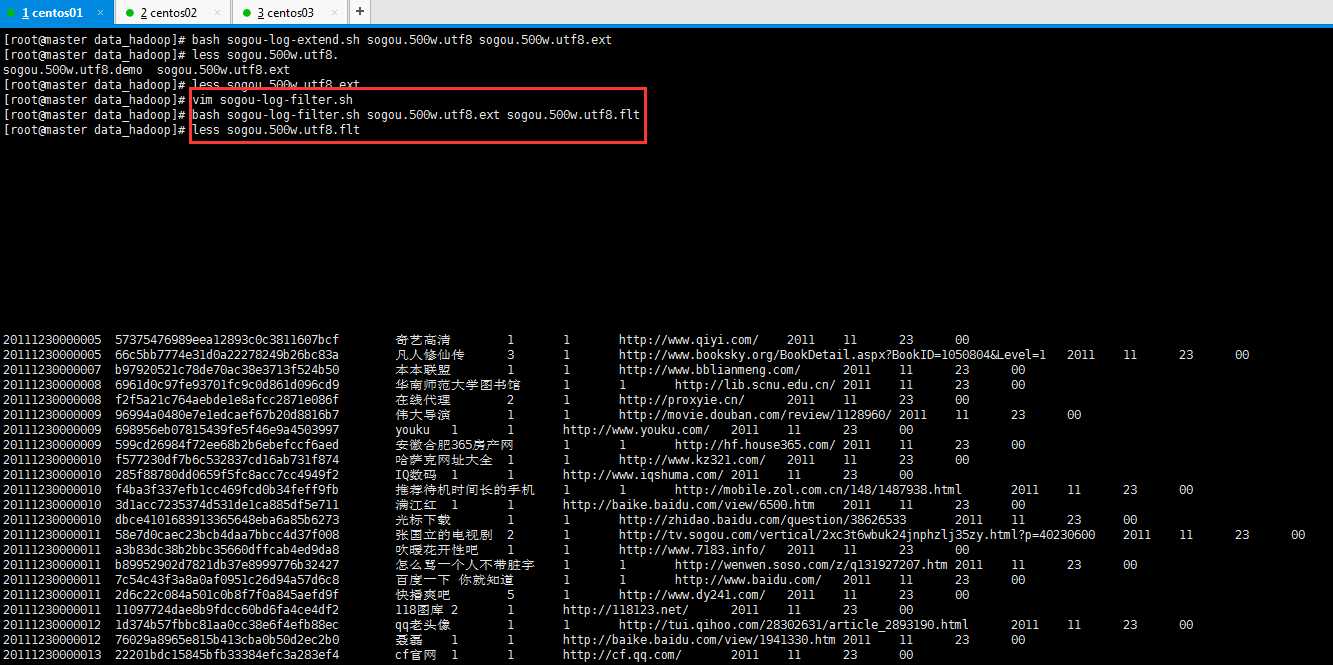
利用bash命令执行sogou-log-filter.sh文件,文件内容如下:
1 #!/bin/bash
2 #infile=/data/sogou-data/sogou.500w.utf8.ext
3 infile=$1
4 #outfile=/data/sogou-data/sogou.500w.utf8.flt
5 outfile=$2
6 awk -F " " ‘{if($2 != "" && $3 != "" && $2 != " " && $3 != " ") print $0}‘ $infile > $outfile
最后,将数据加载到 HDFS 上,操作如下所示(上传到hdfs略慢,记得先启动你的集群哈):
创建hadoop fs -mkdir -p /sougou/20111230的时候多了一个u,my god,导致后来创建数据表的时候未导入数据。可以选择重新删除表,建表,或者直接使用命令导入;
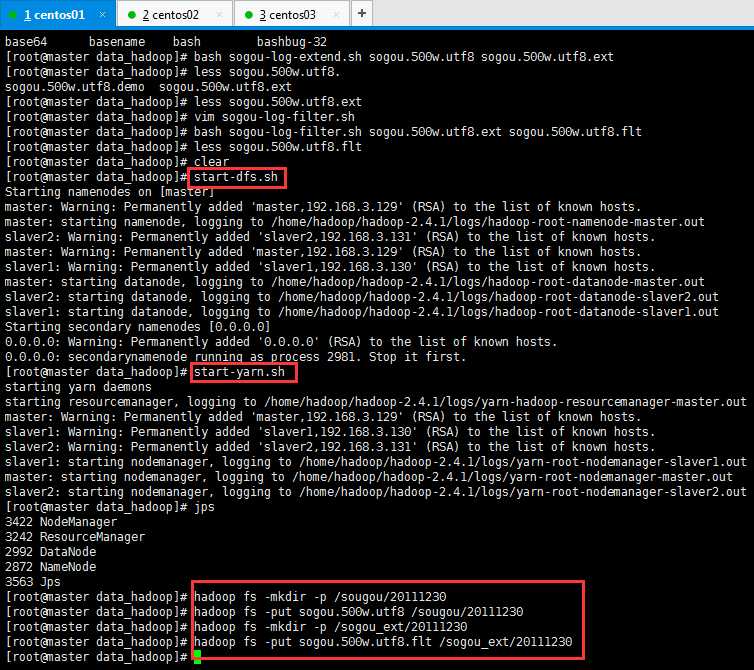
二、基于 Hive 构建日志数据的数据仓库(要求:Hadoop 集群正常启动):
1:打开 Hive 客户端:
基本操作:利用bin文件夹下hive打开Hive客户端。
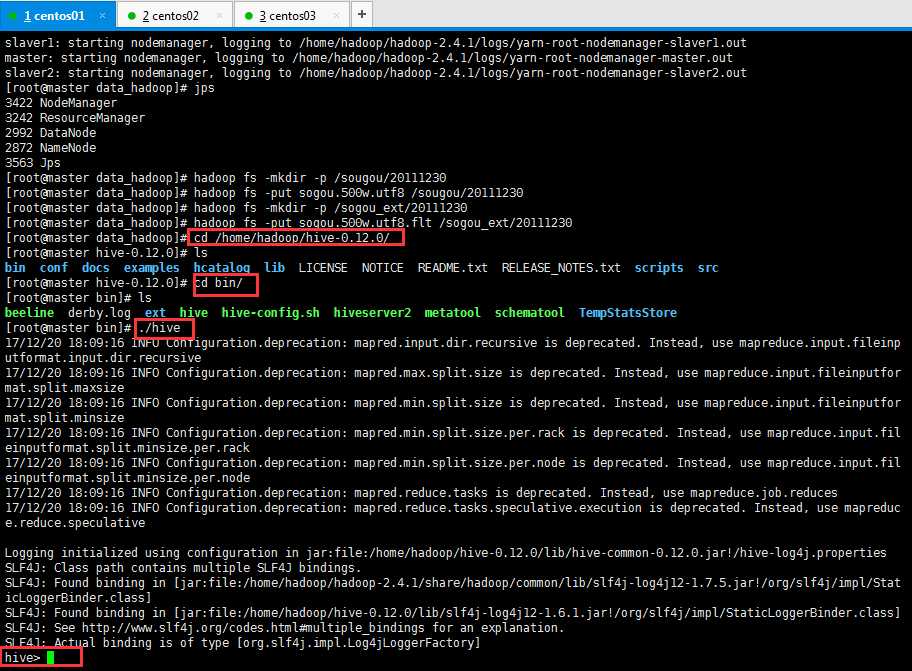
2:Hive的基本操作:

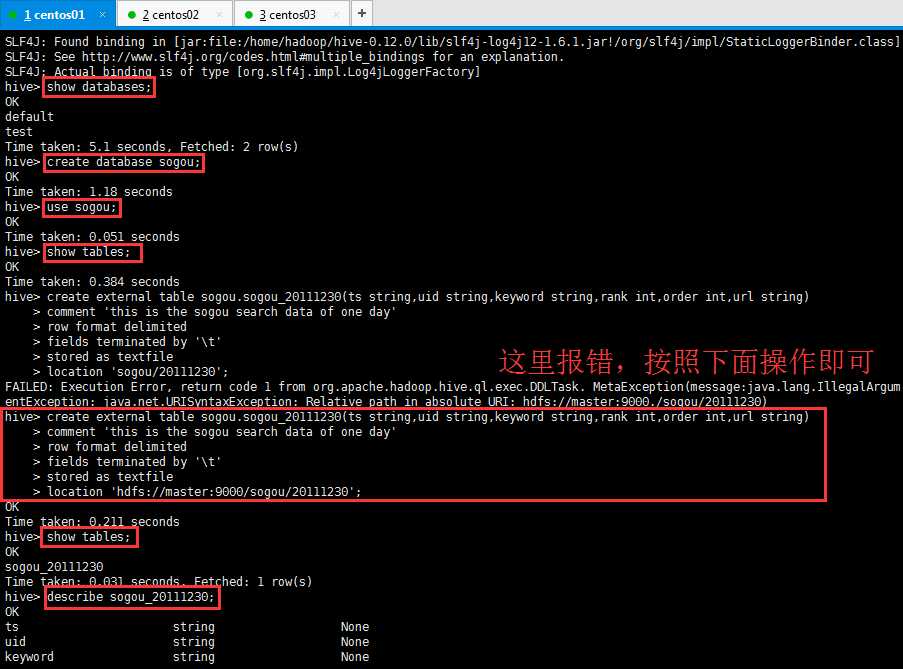
1 # 查看数据库 2 show databases; 3 # 创建数据库 4 create databases sogou; 5 # 使用数据库 6 use sogou; 7 # 查看所有表名 8 show tables; 9 # 创建外部表,使用相对路径绝对URI, # 创建数据库要小心关键字冲突,不能使用date,order,user等关键字。 10 create external table sogou.sogou_20111230(ts string,uid string,keyword string,rank int,sorder int,url string)Row FORMAT DELIMITED FIELDS TERMINATED BY ‘ ‘ stored as TEXTFILE location ‘hdfs://master:9000/sogou/20111230‘; 11 # 查看新创建的表结构 12 show create table sogou.sogou_20111230; 13 describe sogou.sogou_20111230; 14 # 删除表 15 drop table sogou.sogou_20111230;
2:创建分区表(按照年、月、天、小时分区):
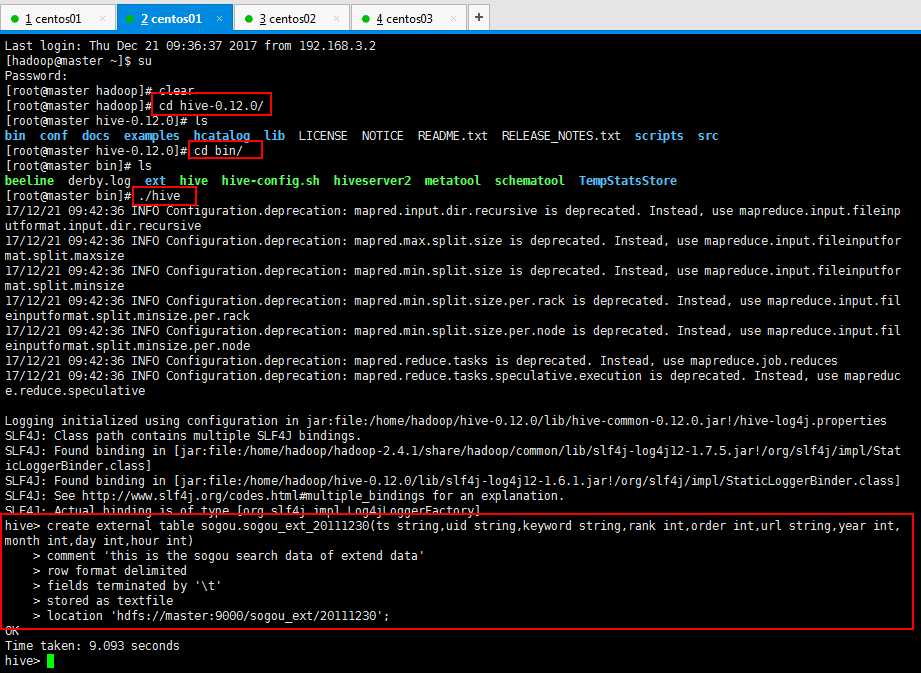
创建扩展 4 个字段(年、月、日、小时)数据的外部表:
create external table sogou.sogou_ext_20111230(ts string,uid string,keyword string,rank int,sorder int,url string,year int,month int,day int,hour int)row format delimited fields terminated by ‘ ‘ stored as textfile location ‘/sogou_ext/20111230‘;
操作如下所示:
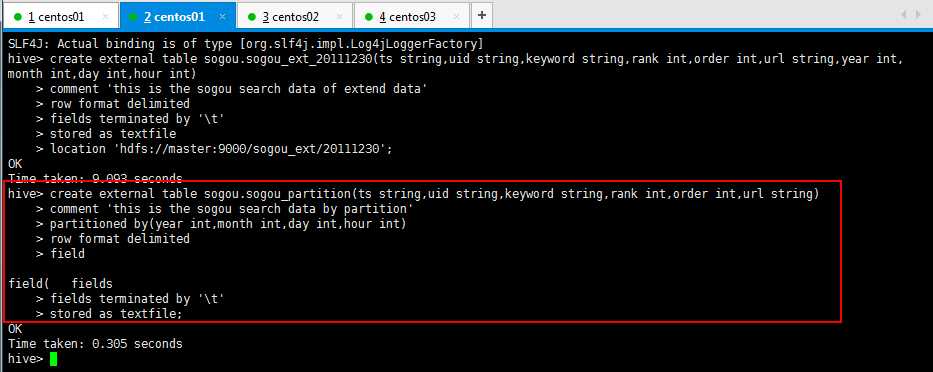
创建带分区的表:
hive> CREATE EXTERNAL TABLE sogou.sogou_partition(ts STRING,uid STRING,keyword STRING,rank INT,order INT,url STRING)
> COMMENT ‘This is the sogou search data by partition‘
> partitioned by (year INT,month INT,day INT,hour INT)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ‘ ‘
> STORED AS TEXTFILE;
OK
灌入数据(sogou_ext_20111230这个表里面的数据是创建的时候加载进去的,location ‘hdfs://master:9000/sogou_ext/20111230‘;):
1 # 设置动态分区。nonstrict全分区字段是动态的 2 set hive.exec.dynamic.partition.mode=nonstrict; 3 insert overwrite table sogou.sogou_partition partition(year,month,day,hour) select * from sogou.sogou_ext_20111230;
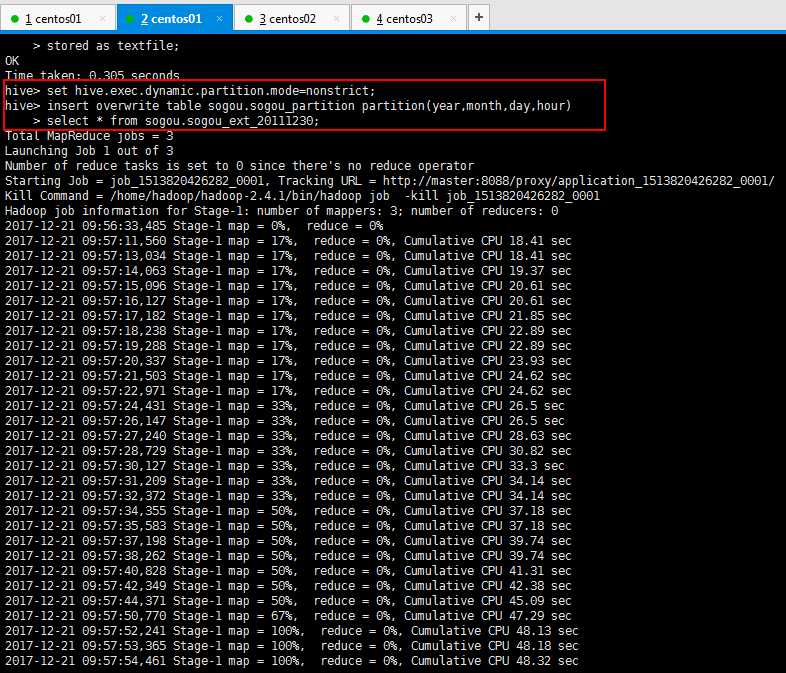
查询结果,如下所示:
1 hive> select * from sogou_ext_20111230 limit 10;2 hive> select url from sogou_ext_20111230 limit 10; 3 hive> select * from sogou_ext_20111230 where uid=‘96994a0480e7e1edcaef67b20d8816b7‘;
四、实现数据分析需求一:条数统计:
1:数据总条数:
|
1
|
hive> select count(*) from sogou.sogou_ext_20111230; |
2:非空查询条数:
1 hive> select count(*) from sogou.sogou_ext_20111230 where keyword is not null and keyword!=‘‘;
3:无重复总条数(根据 ts、uid、keyword、url):
1 hive> select count(*) from (select * from sogou.sogou_ext_20111230 group by ts,uid,keyword,url having count(*)=1) a;
4:独立 UID 总数:
1 hive> select count(distinct(uid)) from sogou.sogou_ext_20111230;
五、实现数据分析需求二:关键词分析:
1:查询关键词长度统计:
split是hive字符串分割函数:
split(str,regex),对于特殊字符,需要使用两个.eg:\\s表示空白字符。
1 hive> select avg(a.cnt) from (select size(split(keyword,‘\\s+‘)) as cnt from sogou.sogou_ext_20111230) a;
2:查询频度排名(频度最高的前 50 词):
1 hive> select keyword,count(*) as cnt from sogou.sogou_ext_20111230 group by keyword order by cnt desc limit 50;
可以看看广大网友最爱搜的词汇,哈哈哈哈,查询结果如下所示:
1 百度 38441 2 baidu 18312 3 人体艺术 14475 4 4399小游戏 11438 5 qq空间 10317 6 优酷 10158 7 新亮剑 9654 8 馆陶县县长闫宁的父亲 9127 9 公安卖萌 8192 10 百度一下 你就知道 7505 11 百度一下 7104 12 4399 7041 13 魏特琳 6665 14 qq网名 6149 15 7k7k小游戏 5985 16 黑狐 5610 17 儿子与母亲不正当关系 5496 18 新浪微博 5369 19 李宇春体 5310 20 新疆暴徒被击毙图片 4997 21 hao123 4834 22 123 4829 23 4399洛克王国 4112 24 qq头像 4085 25 nba 4027 26 龙门飞甲 3917 27 qq个性签名 3880 28 张去死 3848 29 cf官网 3729 30 凰图腾 3632 31 快播 3423 32 金陵十三钗 3349 33 吞噬星空 3330 34 dnf官网 3303 35 武动乾坤 3232 36 新亮剑全集 3210 37 电影 3155 38 优酷网 3115 39 两次才处决美女罪犯 3106 40 电影天堂 3028 41 土豆网 2969 42 qq分组 2940 43 全国各省最低工资标准 2872 44 清代姚明 2784 45 youku 2783 46 争产案 2755 47 dnf 2686 48 12306 2682 49 身份证号码大全 2680 50 火影忍者 2604
六、实现数据分析需求三:UID 分析
1:UID 的查询次数分布(查询 1 次的 UID 个数,...查询 N 次的 UID个数):
1 hive> select SUM(IF(uids.cnt=1,1,0)),SUM(IF(uids.cnt=2,1,0)),SUM(IF(uids.cnt=3,1,0)),SUM(IF(uids.cnt>3,1,0)) from 2 > (select uid,count(*) as cnt from sogou.sogou_ext_20111230 group by uid) uids;
2:UID 平均查询次数:
1 hive> select sum(a.cnt)/count(a.uid) from (select uid,count(*) as cnt from sogou.sogou_ext_20111230 group by uid) a;
3:查询次数大于 2 次的用户总数:
1 hive> select count(a.uid) from ( 2 > select uid,count(*) as cnt from sogou.sogou_ext_20111230 group by uid having cnt > 2) a;
4:查询次数大于 2 次的用户占比:
1 A UID 总数: 2 hive> select count(distinct (uid)) from sogou.sogou_ext_20111230; 3 B UID2 次以上的数量: 4 select count(a.uid) from ( 5 > select uid,count(*) as cnt from sogou.sogou_ext_20111230 group by uid having cnt > 2) a; 6 结果 C=B/A
5:查询次数大于 2 次的数据展示:
1 hive> select b.* from 2 >(select uid,count(*) as cnt from sogou.sogou_ext_20111230 group by uid having cnt > 2) a 3 >join sogou.sogou_ext_20111230 b on a.uid=b.uid 4 >limit 50;
七、实现数据分析需求四:用户行为分析:
1:点击次数与 Rank 之间的关系分析:
1 Rank 在 10 以内的点击次数占比 2 A: 3 4 hive> select count(*) from sogou.sogou_ext_20111230 where rank < 11; 5 6 B: 7 8 hive> select count(*) from sogou.sogou_ext_20111230; 9 10 占比:A/B 11 用户只翻看搜索引擎返回结果的前 10 个结果,即返回结果页面的第一页。这个用户行为决定了尽管搜索 12 引擎返回的结果数目十分庞大,但真正可能被绝大部分用户所浏览的,只有排在最前面的很小一部分而已。 13 所以传统的基于整个结果集合查准率和查全率的评价方式不再适用于网络信息检索的评价,我们需要着重 14 强调在评价指标中有关最靠前结果文档与用户查询需求的相关度的部分。
2:直接输入 URL 作为查询词的比例:
1 (1)直接输入 URL 查询的比例 2 A: 3 hive> select count(*) from sogou.sogou_ext_20111230 where keyword like ‘%www%‘; 4 5 B: 6 hive> select count(*) from sogou.sogou_ext_20111230; 7 8 占比:A/B 9 10 (2)直接输入URL的查询中,点击数点击的结果就是用户输入的URL的网址 所占的比例 11 C: 12 hive> select SUM(IF(instr(url,keyword)>0,1,0)) from 13 > (select * from sogou.sogou_ext_20111230 where keyword like ‘%www%‘) a; 14 占比:C/A 15 从这个比例可以看出,很大一部分用户提交含有URL的查询是由于没有记全网址等原因而想借助搜索引擎来找到自己想浏览的网页。因此搜索引擎在处理这部分查询的时候,一个可能比较理想的方式是首先把相关的完整URL地址返回给用户,这样有较大可能符合用户的查询需求。
3:独立用户行为分析(搜索具备多样性,因人而异,主要注意个性化需求):
1 (1)查询搜索过”仙剑奇侠传“的 uid,并且次数大于 3 2 3 hive> select uid,count(*) as cnt from sogou.sogou_ext_20111230 where keyword=‘仙剑奇侠传‘ group by uid having cnt > 3; 4 5 6 (2)查找 uid 是 653d48aa356d5111ac0e59f9fe736429 和 e11c6273e337c1d1032229f1b2321a75 的相关搜索记录 7 8 hive> select * from sogou.sogou_ext_20111230 where uid=‘653d48aa356d5111ac0e59f9fe736429‘ and keyword like ‘% 9 10 仙剑奇侠传%‘; 11 12 hive> select * from sogou.sogou_ext_20111230 where uid=‘e11c6273e337c1d1032229f1b2321a75‘ and keyword like ‘% 13 14 仙剑奇侠传%‘; 15 16 (3)分析打印结果 17 653d48aa356d5111ac0e59f9fe736429 www.163dyy.com 影视 4 e11c6273e337c1d1032229f1b2321a75 baike.baidu.com 信息 20
八、实现数据分析需求五:实时数据:
1 每个 UID 在当天的查询点击次数 2 3 (1)创建临时表 4 5 hive> create table sogou.uid_cnt(uid STRING, cnt INT) COMMENT ‘This is the sogou search data of one day‘ 6 7 >ROW FORMAT DELIMITED 8 9 >FIELDS TERMINATED BY ‘ ‘ 10 11 >STORED AS TEXTFILE; 12 13 14 (2)查询并插入 15 16 hive> INSERT OVERWRITE TABLE sogou.uid_cnt select uid,count(*) as cnt from sogou.sogou_ext_20111230 group by uid;
九、使用 Sqoop 将数据导入 mysql:
1 要求: 2 MySQL 服务启动且运行正常,命令为: 3 [[email protected] ~]$ /etc/init.d/mysqld status 4 Hadoop 集群启动且运行正常,命令为: 5 [[email protected] ~]$ jps 6 7 将前面生成的实时数据从 HDFS 导入到 MySQL 中,步骤如下: 8 以下操作都是在 MySQL 交互客户端执行。
然后创建数据表和使用sqoop将hive表里面的数据导入到mysql中:
1 (1)登录 MySQL 2 mysql -uhadoop -phadoop 3 (2)创建数据库 4 查看 test 数据库是否存在: 5 mysql> show databases; 6 如果不存在就创建: 7 mysql> create database test; 8 (2)创建表 9 提示:语句中的引号是反引号`,不是单引号’。 10 创建成功后,退出 MySQL。 11 mysql> CREATE TABLE `test`.`uid_cnt` ( 12 -> `uid` varchar(255) DEFAULT NULL, 13 -> `cnt` int(11) DEFAULT NULL 14 -> ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 15 (3)导入数据 16 进入 sqoop 安装主目录: 17 [[email protected] ~]$ cd /home/zkpk/sqoop-1.4.5.bin__hadoop-2.0.4-alpha 18 导入命令: 19 [[email protected] sqoop-1.4.5.bin__hadoop-2.0.4-alpha]$ bin/sqoop export --connect 20 21 22 jdbc:mysql://192.168.190.147:3306/test --username hadoop --password hadoop --table uid_cnt --export-dir ‘/user/hive/warehouse/sogou.db/uid_cnt‘ --fields-terminated-by ‘ ‘ 23 24 注意:红色 IP 部分需要使用 HadoopMaster 节点对应的 IP 地址 25 26 代码解释: 27 bin/sqoop export ##表示数据从 hive 复制到 mysql 中28 --connect jdbc:mysql://192.168.1.113:3306/test 29 --username root 30 --password admin 31 --table bb ##mysql 中的表,即将被导入的表名称 32 --export-dir ‘/user/hive/warehouse/sogou.db/uid_cnt‘ ##hive 中被导出的文件 --fields-terminated-by ‘ ‘ ##hive 中被导出的文件字段的分隔符
实验内容还有如下所示的操作,这里就不列了,下面开始进行自己的操作:
十、HBase Shell 操作命令实验 十一、使用 Sqoop 将数据导入 HBase 十二、HBase Java API 访问统计数据
---------------------------------------------------------------------分割线------------------------------------------------------------------------------
十三:实现数据分析需求五:实时数据:
根据,实现数据分析需求二:关键词分析,将分析的结果存到新建的数据表里面,这样方便使用sqoop将hive转换为mysql,进行web分析和统计。具体的业务可以根据具体的需求进行统计,然后将统计结果插入到对应的新建的数据表中。
1:业务指标一:分析频度最高的前 50 词;
1 (1)创建频度排名临时表sogou_frequency_ranking,将查询频度排名(频度最高的前 50 词)的结果保存到这个临时表中。 2 hive> create table sogou.sogou_frequency_ranking(keyword string,keywordCount int) 3 > comment ‘this is the sogou search data of one day‘ 4 > row format delimited 5 > fields terminated by ‘ ‘ 6 > stored as textfile ; 7 8 (2)查询并插入 9 hive> insert overwrite table sogou.sogou_frequency_ranking 10 > select keyword,count(*) as cnt from sogou.sogou_ext_20111230 group by keyword order by cnt desc limit 50; 11 (3)查看是否插入到临时表sogou_frequency_ranking 12 hive> select * from sogou.sogou_frequency_ranking;
十四:使用 Sqoop 将数据从Hive导入到 MySQL:
1 1: MySQL 服务启动且运行正常,命令为: 2 [[email protected] hadoop]# /etc/init.d/mysql status 3 SUCCESS! MySQL running (2086) 4 2:Hadoop 集群启动且运行正常,命令为: 5 [[email protected] hadoop]# jps 6 3115 ResourceManager 7 2957 SecondaryNameNode 8 2812 DataNode 9 3341 NodeManager 10 2692 NameNode 11 11038 Jps 12 10883 RunJar 13 [[email protected] hadoop]#
将前面生成的实时数据从 HDFS 导入到 MySQL 中,步骤如下:
以下操作都是在 MySQL 交互客户端执行。
登录,查看数据库,创建数据库,使用数据库,创建数据表:
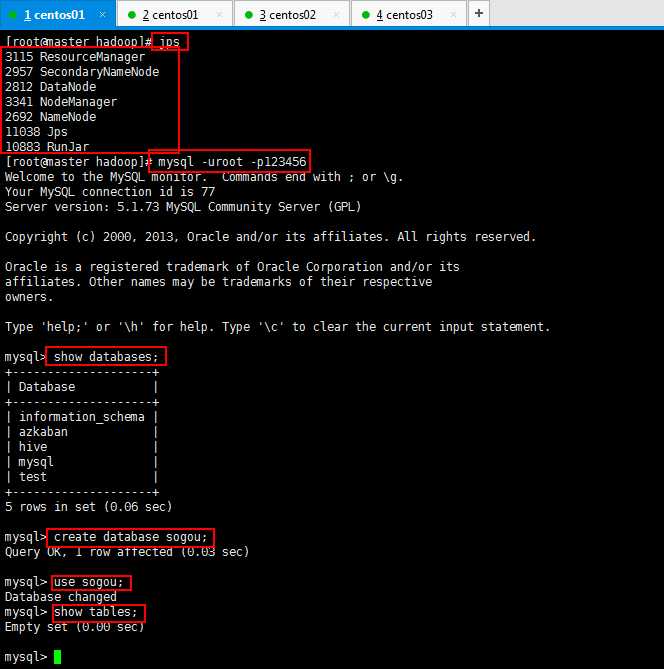
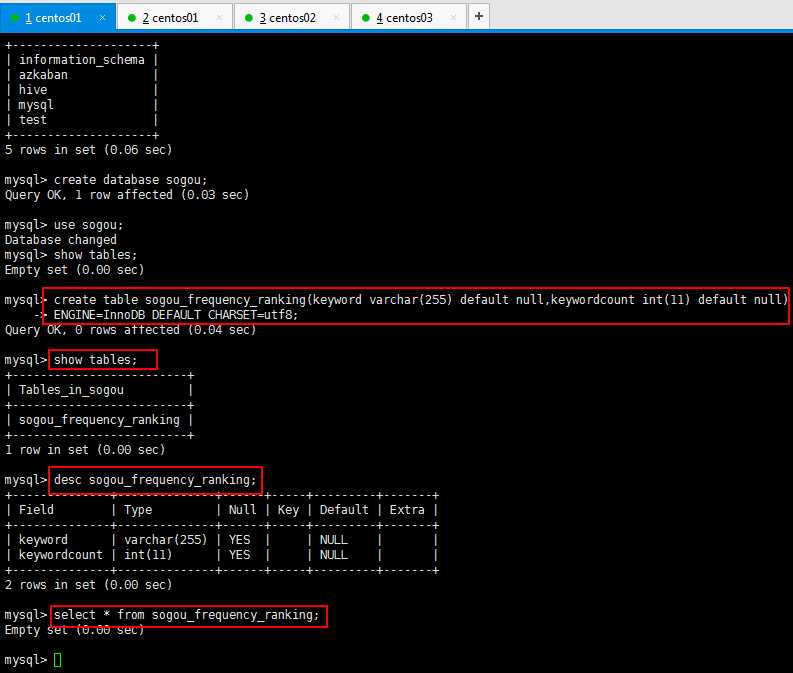
然后创建数据表,如下所示:
然后使用sqoop将hive数据表里面的数据导入到mysql中的数据表中;
1 #方式一: 2 bin/sqoop export ##表示数据从 hive 复制到 mysql 中 3 --connect jdbc:mysql://192.168.3.129:3306/test 4 --username root 5 --password 123456 6 --table bb ##mysql 中的表,即将被导入的表名称 7 --export-dir ‘/user/hive/warehouse/sogou.db/sogou_frequency_ranking‘ ##hive 中被导出的文件 8 --fields-terminated-by ‘ ‘ ##hive 中被导出的文件字段的分隔符 9 10 11 #方式二 12 [[email protected] sqoop]# bin/sqoop export --connect jdbc:mysql://192.168.3.129:3306/sogou --username root --password 123456 --table sogou_frequency_ranking --export-dir ‘/user/hive/warehouse/sogou.db/sogou_frequency_ranking‘ --fields-terminated-by ‘ ‘
操作如下所示:
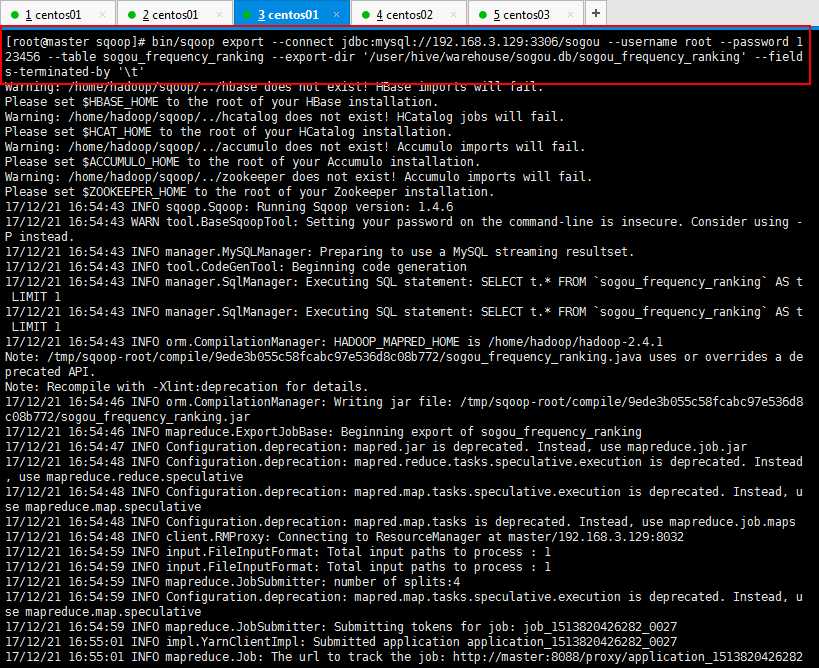
导入以后可以去mysql查看数据是否正确导入,如下所示:
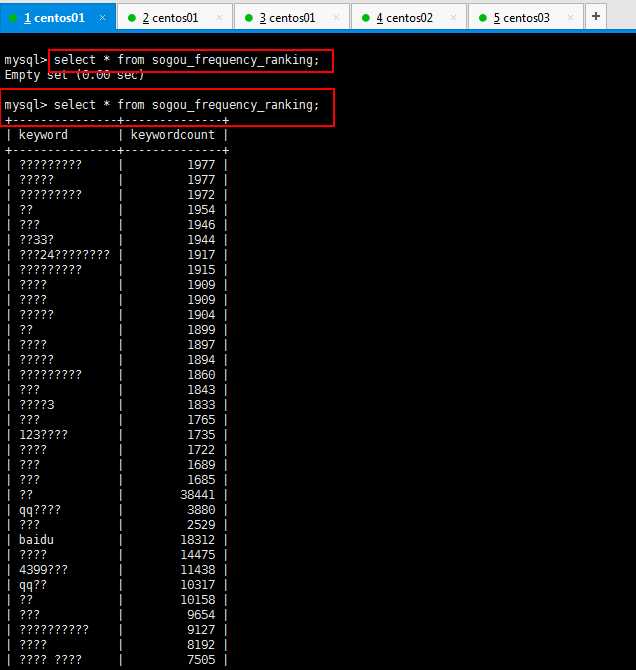
好吧,乱码了,解决一下乱码问题(hive数据表导入到mysql数据表 乱码了):
解决乱码问题参考:http://blog.csdn.net/zreodown/article/details/8850222
问题:Linux安装mysql 在/etc下没有my.cnf 解决办法?
1 Linux下用rpm包安装的MySQL是不会安装/etc/my.cnf文件的, 2 至于为什么没有这个文件而MySQL却也能正常启动和作用,在点有两个说法, 3 第一种说法,my.cnf只是MySQL启动时的一个参数文件,可以没有它,这时MySQL会用内置的默认参数启动, 4 第二种说法,MySQL在启动时自动使用/usr/share/mysql目录下的my-medium.cnf文件,这种说法仅限于rpm包安装的MySQL, 5 解决方法,只需要复制一个/usr/share/mysql目录下的my-medium.cnf 文件到/etc目录,并改名为my.cnf即可。
操作如下所示:
1 [[email protected] sqoop]# bin/sqoop export --connect "jdbc:mysql://192.168.3.129:3306/sogou?useUnicode=true&characterEncoding=utf-8" --username root --password 123456 --table sogou_frequency_ranking --export-dir ‘/user/hive/warehouse/sogou.db/sogou_frequency_ranking‘ --fields-terminated-by ‘ ‘ 2 Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail. 3 Please set $HBASE_HOME to the root of your HBase installation. 4 Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail. 5 Please set $HCAT_HOME to the root of your HCatalog installation. 6 Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail. 7 Please set $ACCUMULO_HOME to the root of your Accumulo installation. 8 Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail. 9 Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 10 17/12/22 09:58:28 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 11 17/12/22 09:58:28 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 12 17/12/22 09:58:29 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 13 17/12/22 09:58:29 INFO tool.CodeGenTool: Beginning code generation 14 17/12/22 09:58:30 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `sogou_frequency_ranking` AS t LIMIT 1 15 17/12/22 09:58:30 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `sogou_frequency_ranking` AS t LIMIT 1 16 17/12/22 09:58:30 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/hadoop-2.4.1 17 Note: /tmp/sqoop-root/compile/34b1a9d0c31df6785032f464c8bd9211/sogou_frequency_ranking.java uses or overrides a deprecated API. 18 Note: Recompile with -Xlint:deprecation for details. 19 17/12/22 09:58:36 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/34b1a9d0c31df6785032f464c8bd9211/sogou_frequency_ranking.jar 20 17/12/22 09:58:36 INFO mapreduce.ExportJobBase: Beginning export of sogou_frequency_ranking 21 17/12/22 09:58:37 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 22 17/12/22 09:58:38 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative 23 17/12/22 09:58:38 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative 24 17/12/22 09:58:38 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 25 17/12/22 09:58:39 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.3.129:8032 26 17/12/22 09:58:54 INFO input.FileInputFormat: Total input paths to process : 1 27 17/12/22 09:58:54 INFO input.FileInputFormat: Total input paths to process : 1 28 17/12/22 09:58:56 INFO mapreduce.JobSubmitter: number of splits:4 29 17/12/22 09:58:56 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative 30 17/12/22 09:58:59 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513907030061_0001 31 17/12/22 09:59:03 INFO impl.YarnClientImpl: Submitted application application_1513907030061_0001 32 17/12/22 09:59:04 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1513907030061_0001/ 33 17/12/22 09:59:04 INFO mapreduce.Job: Running job: job_1513907030061_0001 34 17/12/22 09:59:35 INFO mapreduce.Job: Job job_1513907030061_0001 running in uber mode : false 35 17/12/22 09:59:35 INFO mapreduce.Job: map 0% reduce 0% 36 17/12/22 09:59:56 INFO mapreduce.Job: map 100% reduce 0% 37 17/12/22 09:59:58 INFO mapreduce.Job: Job job_1513907030061_0001 completed successfully 38 17/12/22 09:59:59 INFO mapreduce.Job: Counters: 30 39 File System Counters 40 FILE: Number of bytes read=0 41 FILE: Number of bytes written=442056 42 FILE: Number of read operations=0 43 FILE: Number of large read operations=0 44 FILE: Number of write operations=0 45 HDFS: Number of bytes read=3096 46 HDFS: Number of bytes written=0 47 HDFS: Number of read operations=19 48 HDFS: Number of large read operations=0 49 HDFS: Number of write operations=0 50 Job Counters 51 Launched map tasks=4 52 Data-local map tasks=4 53 Total time spent by all maps in occupied slots (ms)=71883 54 Total time spent by all reduces in occupied slots (ms)=0 55 Total time spent by all map tasks (ms)=71883 56 Total vcore-seconds taken by all map tasks=71883 57 Total megabyte-seconds taken by all map tasks=73608192 58 Map-Reduce Framework 59 Map input records=50 60 Map output records=50 61 Input split bytes=741 62 Spilled Records=0 63 Failed Shuffles=0 64 Merged Map outputs=0 65 GC time elapsed (ms)=765 66 CPU time spent (ms)=2130 67 Physical memory (bytes) snapshot=206630912 68 Virtual memory (bytes) snapshot=1462874112 69 Total committed heap usage (bytes)=40493056 70 File Input Format Counters 71 Bytes Read=0 72 File Output Format Counters 73 Bytes Written=0 74 17/12/22 09:59:59 INFO mapreduce.ExportJobBase: Transferred 3.0234 KB in 80.053 seconds (38.6744 bytes/sec) 75 17/12/22 09:59:59 INFO mapreduce.ExportJobBase: Exported 50 records. 76 [[email protected] sqoop]#
导入以后查看mysql数据表,已经导入成功了,解决乱码问题:
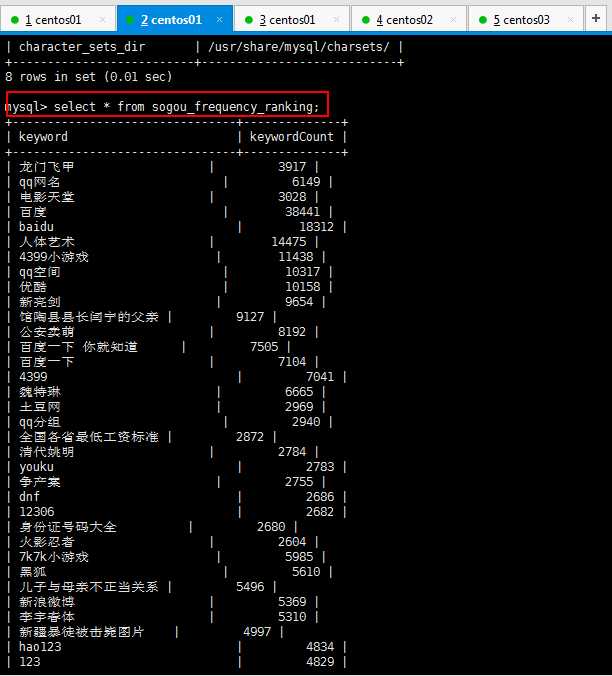
然后自己弄了ssh,把流程略通,就可以做报表展示了,这里省略ssh框架的搭建,将核心代码贴一下:
ssh源码地址:http://download.csdn.net/download/biexiansheng/10171949
No1:JSONUtil工具类,针对Json转换通用,如下所示:
1 package com.bie.utils;
2
3 import java.io.IOException;
4 import java.util.List;
5
6 import org.codehaus.jackson.JsonProcessingException;
7 import org.codehaus.jackson.map.ObjectMapper;
8 import org.codehaus.jackson.type.JavaType;
9
10 public class JsonUtils {
11
12 // 定义jackson对象
13 private static final ObjectMapper mapper = new ObjectMapper();
14 /**
15 * 将对象转换成json字符串
16 * @param data
17 * @return
18 * @throws IOException
19 */
20 public static String toJSONString(Object data) throws IOException {
21 try {
22 String string = mapper.writeValueAsString(data);
23 return string;
24 } catch (JsonProcessingException e) {
25 e.printStackTrace();
26 }
27 return null;
28 }
29
30 /**
31 * 将json结果集转化为对象
32 * @param jsonData
33 * @param beanType
34 * @return
35 */
36 public static <T> T parseObject(String jsonData, Class<T> beanType) {
37 try {
38 T t = mapper.readValue(jsonData, beanType);
39 return t;
40 } catch (Exception e) {
41 e.printStackTrace();
42 }
43 return null;
44 }
45
46 /**
47 * 将json数据转换成list
48 * @param jsonData
49 * @param beanType
50 * @return
51 */
52 public static <T> List<T> parseArray(String jsonData, Class<T> beanType) {
53 JavaType javaType = mapper.getTypeFactory().constructParametricType(List.class, beanType);
54 try {
55 List<T> list = mapper.readValue(jsonData, javaType);
56 return list;
57 } catch (Exception e) {
58 e.printStackTrace();
59 }
60 return null;
61 }
62 }
No2,控制层,将查询的内容转换为Json格式。
1 package com.bie.controller;
2
3 import java.util.List;
4
5 import javax.annotation.Resource;
6 import javax.servlet.http.HttpServletRequest;
7 import javax.servlet.http.HttpServletResponse;
8
9 import org.springframework.beans.factory.annotation.Autowired;
10 import org.springframework.stereotype.Controller;
11 import org.springframework.web.bind.annotation.RequestMapping;
12 import org.springframework.web.bind.annotation.RequestMethod;
13 import org.springframework.web.bind.annotation.ResponseBody;
14 import org.springframework.web.servlet.ModelAndView;
15
16 import com.bie.po.SogouFrequencyRanking;
17 import com.bie.service.impl.FrequencyRankingServiceImpl;
18 import com.bie.utils.JsonUtils;
19
20 @Controller
21 public class FrequencyRankingController {
22
23 @Autowired
24 private FrequencyRankingServiceImpl frequencyRankingService;
25
26 //@ResponseBody将返回值转化为json格式响应到客户端
27 @RequestMapping(value="/show",method=RequestMethod.POST)
28 public @ResponseBody void showFrequencyRanking(HttpServletRequest request, HttpServletResponse response){
29 response.setCharacterEncoding("utf-8");
30 try {
31 List<SogouFrequencyRanking> selectFrequencyRanking = frequencyRankingService.selectFrequencyRanking();
32
33 String jsonData = JsonUtils.toJSONString(selectFrequencyRanking);
34 System.out.println(jsonData);
35 response.getWriter().write(jsonData);
36 response.getWriter().flush();
37 response.getWriter().close();
38 } catch (Exception e) {
39 e.printStackTrace();
40 }
41
42 }
43
44
45 }
No3:前台页面,index.jsp,进行报表展示:
1 <%@ page language="java" contentType="text/html; charset=UTF-8" 2 pageEncoding="UTF-8"%> 3 <!DOCTYPE html> 4 <% 5 String path = request.getContextPath(); 6 String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/"; 7 %> 8 <html> 9 <head> 10 <base href="<%=basePath%>"> 11 <meta charset="utf-8"> 12 <title>ECharts</title> 13 <script src="https://apps.bdimg.com/libs/jquery/2.1.4/jquery.min.js"></script> 14 <script src="http://echarts.baidu.com/build/dist/echarts.js"></script> 15 <!--在线引用js文件,离线出现各种问题--> 16 </head> 17 <body> 18 19 ${list } 20 21 <!-- 为ECharts准备一个具备大小(宽高)的Dom --> 22 <div id="main" style="width: 1500px;height:500px;"></div> 23 <!-- ECharts单文件引入 --> 24 <script type="text/javascript"> 25 // 路径配置 26 require.config({ 27 paths: { 28 echarts: ‘http://echarts.baidu.com/build/dist‘ 29 } 30 }); 31 32 // 使用 33 require( 34 [ 35 ‘echarts‘, 36 ‘echarts/chart/bar‘, // 使用柱状图就加载bar模块,按需加载 37 ], 38 function (ec) { 39 // 基于准备好的dom,初始化echarts图表 40 var myChart = ec.init(document.getElementById(‘main‘)); 41 42 //myChart.setOption({ 43 var option ={ 44 title: { 45 text: ‘2011-12-30 分析搜狗搜索频度最高的前 50词‘ 46 }, 47 tooltip: { 48 trigger: ‘axis‘, 49 axisPointer : { // 坐标轴指示器,坐标轴触发有效 50 type : ‘line‘ // 默认为直线,可选为:‘line‘ | ‘shadow‘ 51 } 52 }, 53 legend: { 54 data:[‘数量‘] 55 }, 56 xAxis : { 57 // data: [] 58 }, 59 yAxis: [ 60 { 61 type : ‘value‘ 62 } 63 ], 64 series : [ 65 /* { 66 series[0] chart type has not been defined. 出现这种问题,是此处和下面的重新赋值冲突了,把这里注释了,下面重新赋值即可。 67 name:"数量", 68 type:"bar", 69 data:[] 70 } */ 71 ] 72 }; 73 // 为echarts对象加载数据 74 //myChart.setOption(option); 75 76 77 myChart.showLoading(); //数据加载完之前先显示一段简单的loading动画 78 var names=[]; //类别数组(实际用来盛放X轴坐标值) 79 var nums=[]; //销量数组(实际用来盛放Y坐标值) 80 $.ajax({ 81 type : "post", 82 //async : true, //异步请求(同步请求将会锁住浏览器,用户其他操作必须等待请求完成才可以执行) 83 url : "${pageContext.request.contextPath}/show",//请求发送到TestServlet处 84 data : {}, 85 dataType : "json", //返回数据形式为json 86 success : function(result) { 87 //alert(result.length); 88 //请求成功时执行该函数内容,result即为服务器返回的json对象 keyword keywordCount 89 if (result) { 90 //挨个取出类别并填入类别数组 //x坐标的值 91 for(var i=0;i<result.length;i++){ 92 names.push(result[i].keyword); 93 } 94 //alert(names); 95 //挨个取出销量并填入销量数组 //y坐标的值 96 for(var i=0;i<result.length;i++){ 97 nums.push(result[i].keywordCount); 98 } 99 //alert(nums); 100 //隐藏加载动画 101 myChart.hideLoading(); 102 //加载数据图表 103 myChart.setOption({ 104 xAxis: { //x坐标的值 105 data: names, 106 axisLabel:{//解决。Echarts中axislabel文字过长导致显示不全或重叠 107 interval: 0, 108 rotate:40, 109 } 110 }, 111 series: [{ //y坐标的值 112 // 根据名字对应到相应的系列 113 name:"数量", 114 type:"bar", 115 data: nums 116 }], 117 }); 118 } 119 }, 120 error : function(errorMsg) { 121 //请求失败时执行该函数 122 alert("图表请求数据失败!"); 123 myChart.hideLoading(); 124 } 125 }) 126 127 myChart.setOption(option); 128 } 129 ); 130 131 </script> 132 133 </body> 134 </html>
下面就是通过离线分析搜狗搜索2011年11月30日的搜索排名前五十,这里是我的指标一,更多指标自己可以去想和做:
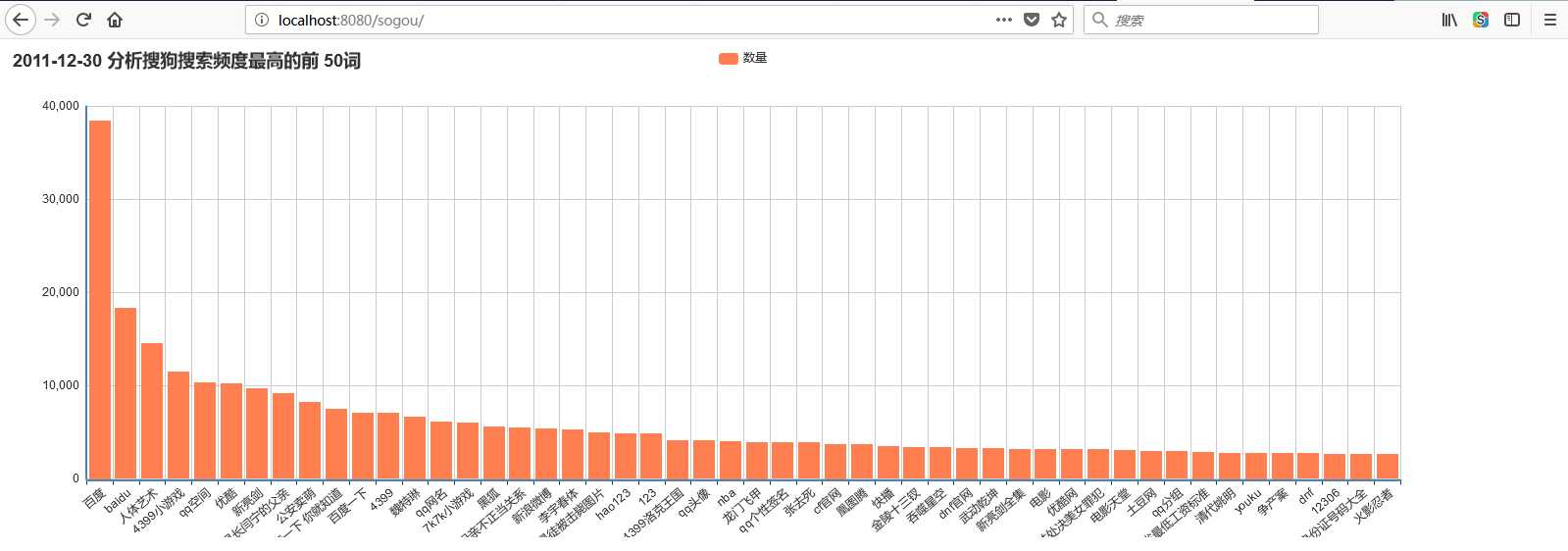
更多指标统计自己可以去做。
待续......
以上是关于搜狗搜索日志分析系统的主要内容,如果未能解决你的问题,请参考以下文章