聚类(Clustering)
Posted joeric07
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类(Clustering)相关的知识,希望对你有一定的参考价值。
- 简介
相对于决策树、朴素贝叶斯、SVM等有监督学习,聚类算法属于无监督学习。
有监督学习通常根据数据集的标签进行分类,而无监督学习中,数据集并没有相应的标签,算法仅根据数据集进行划分。
由于具有出色的速度和良好的可扩展性,Kmeans聚类算法算得上是最著名的聚类方法。
- 基本思想
在没有标签的数据集中,所有的数据点都是同一类的。
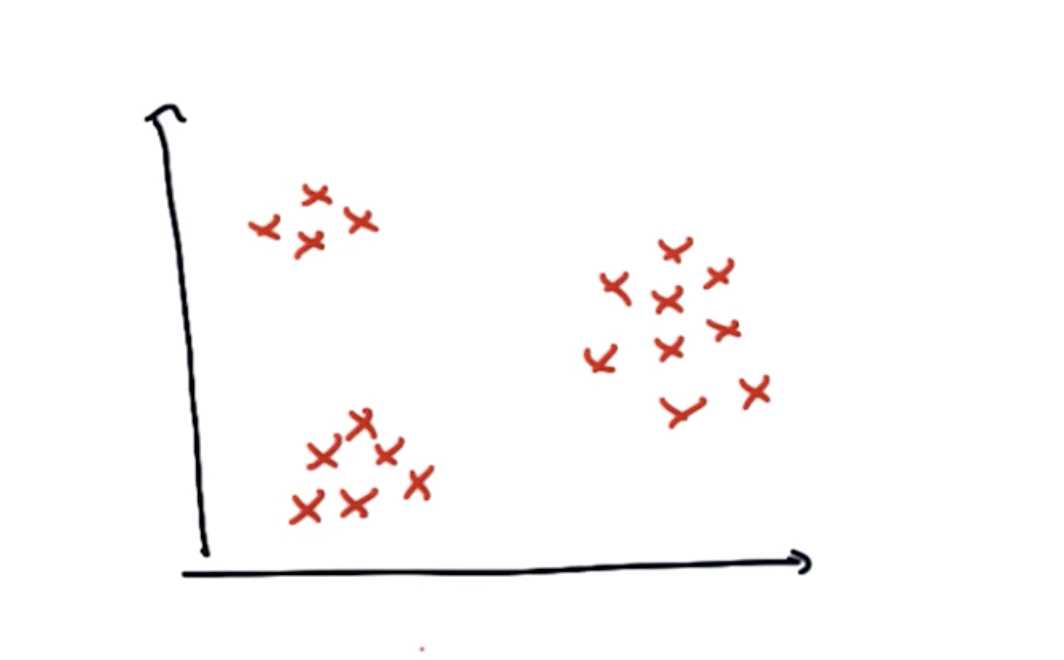
在这张图中,虽然数据都为同一类,但是可以直观的看出,数据集存在簇或聚类。这种数据没有比标签,但能发现其结构的情况,称作非监督学习。
最基本的聚类算法,也是目前使用最多的聚类算法叫做K-均值(K-Means)。
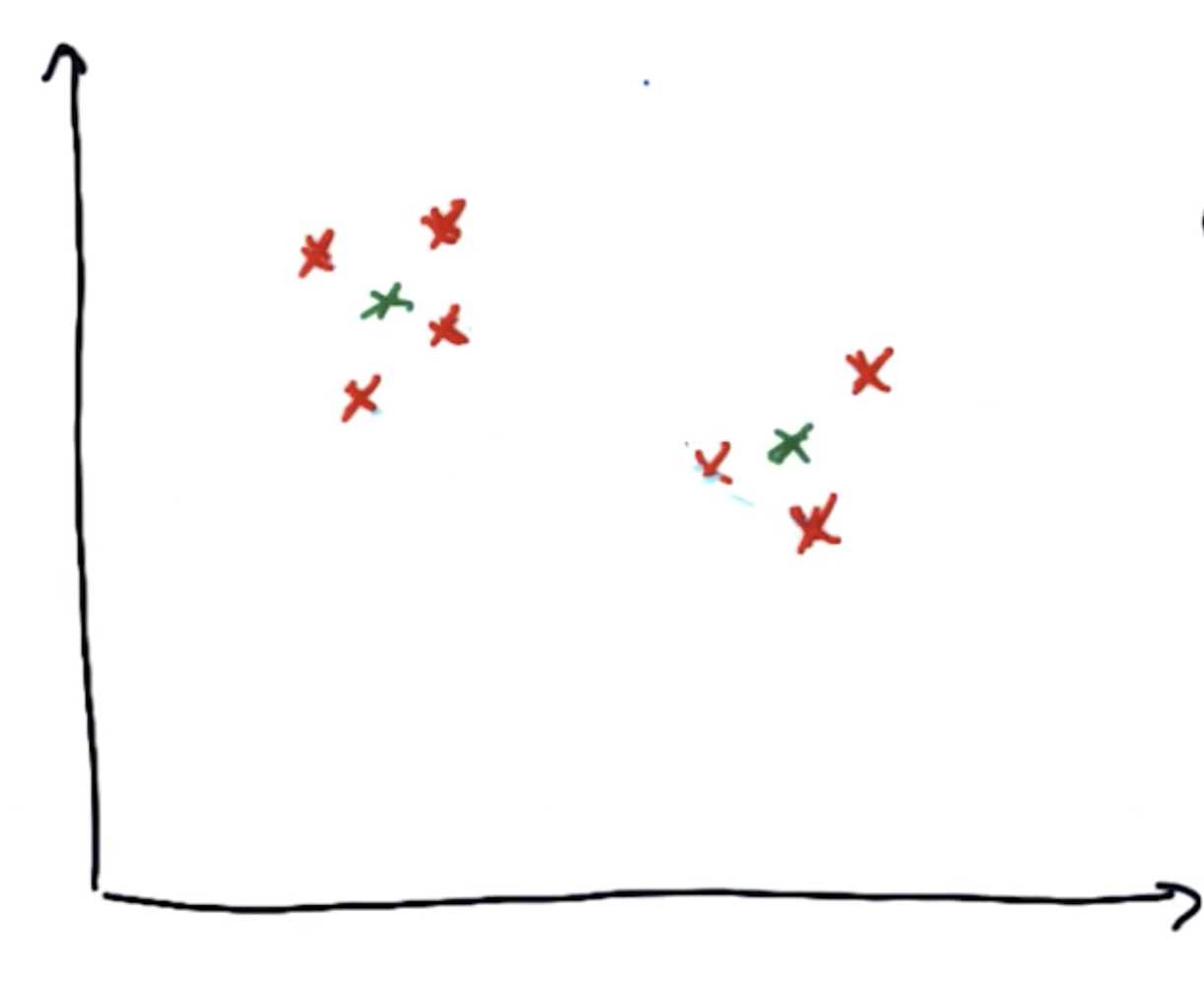
假设一组数据集为下图:
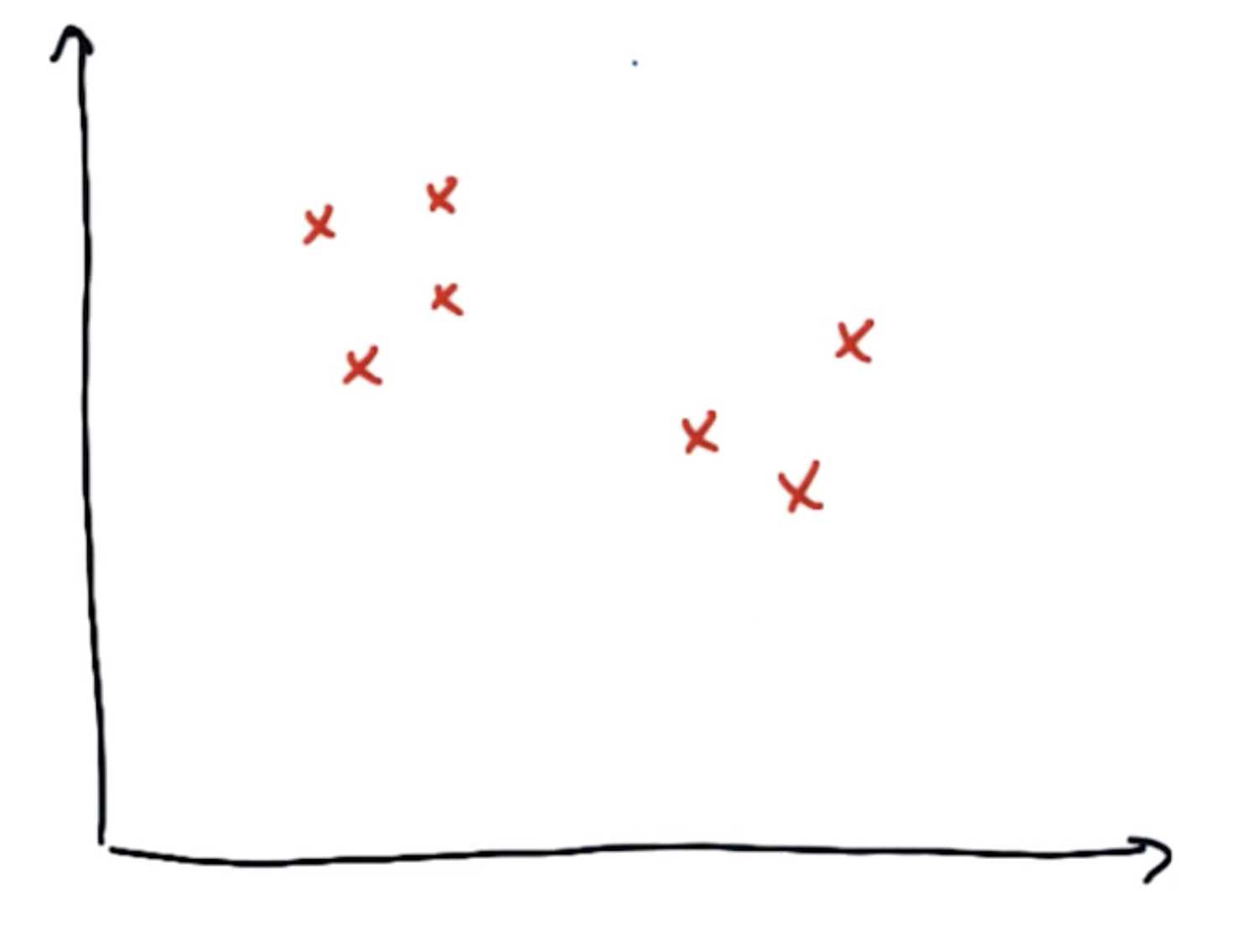
他们应该有两个簇,其中簇的中心如下图:
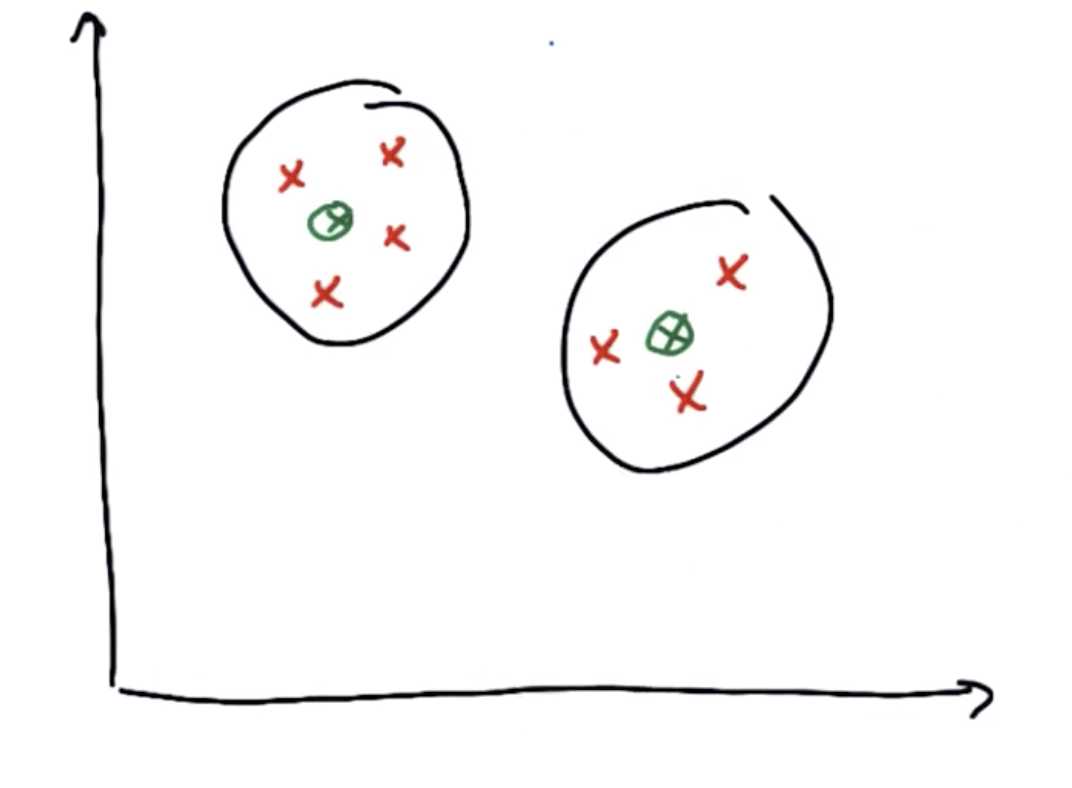
在K-Means算法中,首先随便画出聚类中心,它可以是不正确的:
(假设上方绿点为中心1,下方绿点为中心2)

K-Means算法分为两个步骤:
1、分配
2、优化
进行第一步,对于上图的数据集,首先找出在所有红色点中,距离中心1比距离中心2更近的点
简单的方法是找出两个中心点的垂直平分线,将红色的点分割为两部分,分别是距离各自中心更近的点
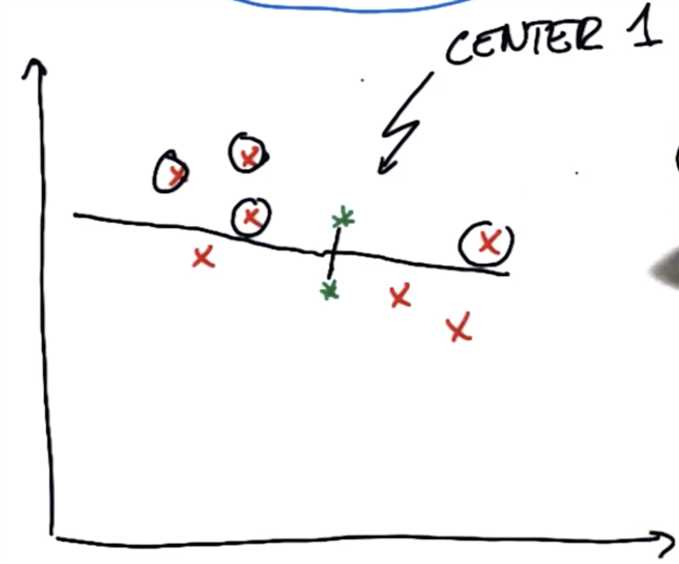
第二步是优化。首先将聚类中心和第一步分配完的点相连接,然后开始优化:移动聚类中心,使得与聚类中心相连接的线的平方和最短。
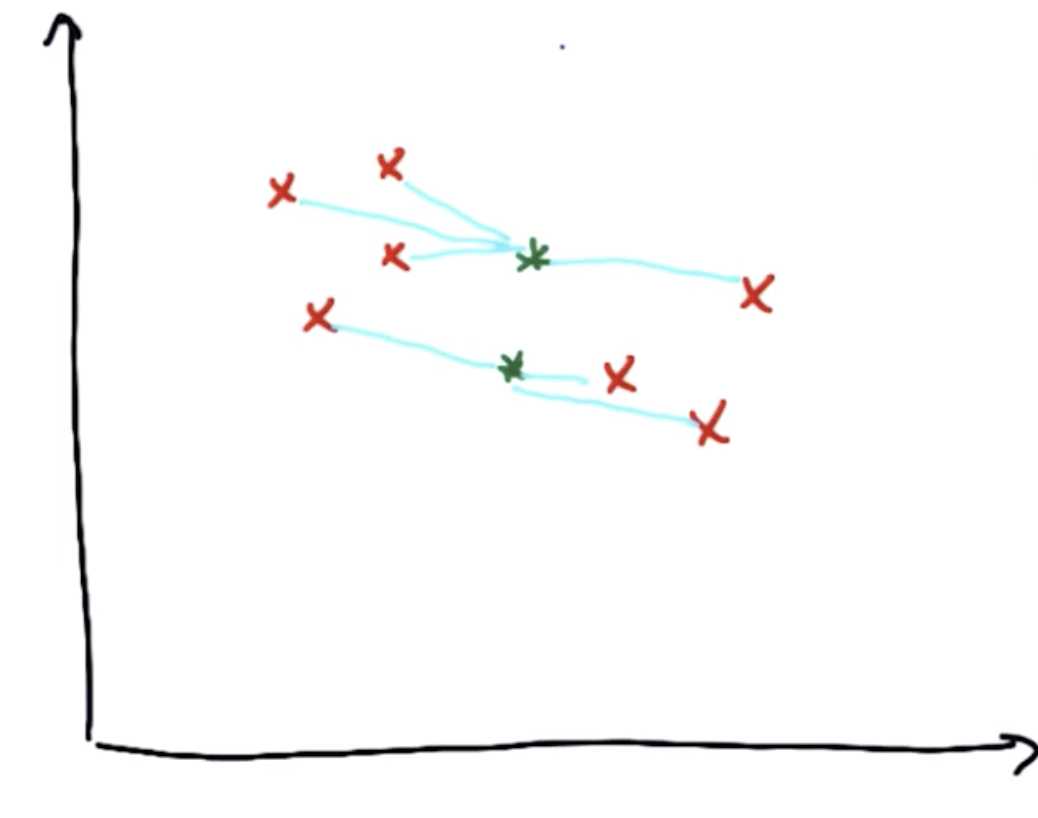
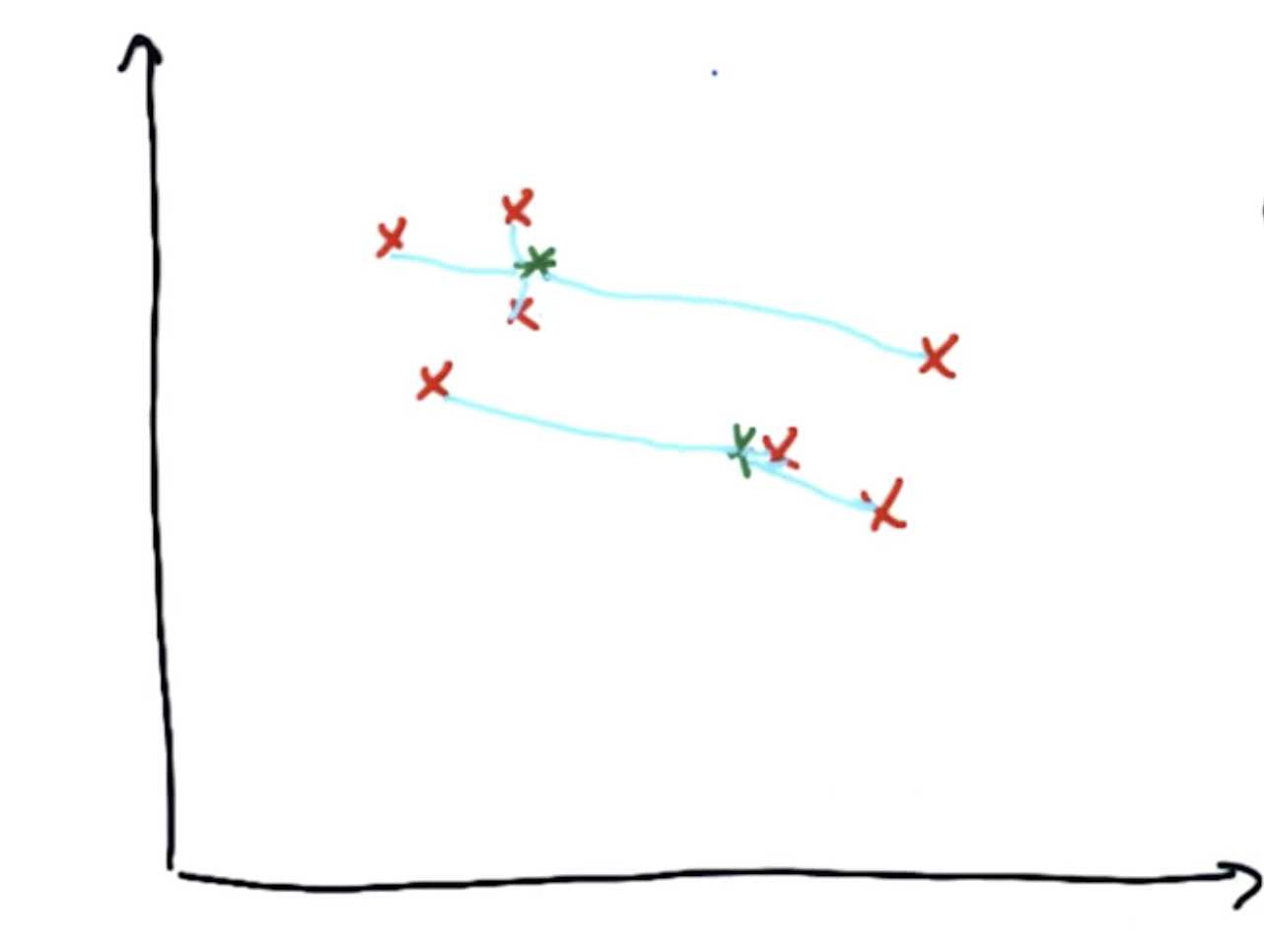
多次进行步骤1和2,即先分配再优化,聚类中心将会逐步移动到数据簇的中心。
- 代码实现
环境:MacOS mojave 10.14.3
Python 3.7.0
使用库:scikit-learn 0.19.2
sklearn.cluster.KMeans官方库:https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
>>> from sklearn.cluster import KMeans >>> import numpy as np >>> X = np.array([[1, 2], [1, 4], [1, 0], ... [10, 2], [10, 4], [10, 0]]) #输入六个数据点 >>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X) #确定一共有两个聚类中心 >>> kmeans.labels_ array([1, 1, 1, 0, 0, 0], dtype=int32) >>> kmeans.predict([[0, 0], [12, 3]]) #预测两个新点的聚类分类情况 array([1, 0], dtype=int32) >>> kmeans.cluster_centers_ #输出两个聚类中心的坐标 array([[10., 2.], [ 1., 2.]])
以上是关于聚类(Clustering)的主要内容,如果未能解决你的问题,请参考以下文章