聚类算法(Clustering Algorithms)之层次聚类(Hierarchical Clustering)
Posted Data Strategy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法(Clustering Algorithms)之层次聚类(Hierarchical Clustering)相关的知识,希望对你有一定的参考价值。
在之前的系列中,大部分都是关于监督学习(除了PCA那一节),接下来的几篇主要分享一下关于非监督学习中的聚类算法(clustering algorithms)。
先了解一下聚类分析(clustering analysis)
Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense) to each other than to those in other groups(clusters). it is a main task of exploratory analysis, and a common technique for statistical data analysis, used in many fields, including pattern recognition, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. --WIKI
聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计方法,同时也是数据挖掘的一个重要算法。聚类(cluster)分析是由若干模式(pattern)组成的,通常,模式是一个度量(measurement)的向量,或者是多维空间中的一个点。聚类分析以相似性为基础,在一个聚类中的模式之间比不在同一聚类中的模式之间具有更多的相似性。-- 百度百科
聚类分析本身不是一种特定的算法,是用来解决一般任务的方法。它可以通过不同的算法来实现,这些算法不同之处在于它们对于集群结构的理解以及如何有效地找到这些集群。流行的集群概念包括,在一个集群的成员之间距离比较小,数据空间的密集区域,间隔或特定统计分布的组。因此,可以将聚类公式化为一个多目标优化问题。合适的聚类算法和参数的设置取决于所使用的数据集和对于聚类结果的用途。设置的参数例如要使用的距离函数,密度阈值或预计要聚类的数量。
Process of clustering(聚类分析的过程):
聚类分析的整个过程包括四个基本步骤:
A. Feature Selection or Extraction (特征选择和提取)
特征选择是确定最有效的原始特征子集用于聚类的过程。特征提取是将一个或多个输入特征转换为初始显著特征的过程。聚类过程高度依赖于此步骤。对特征的轻率剔除会增加内卷involution(involution: a function, transformation, or operator that is equal to its inverse),并可能导致额外的无关紧要的簇(clusters).
B. Clustering Algorithm Design or Selection (聚类算法的设计和选择)
不可能定理指出,“没有一个单一的聚类算法可以同时满足数据聚类的三个基本公理,即scale-invariance(尺度不变性)、consistency(一致性)和richness(丰富性)。因此,不可能为在不同的科学、社交、医学等其它领域中建立一个通用的聚类方法框架。从而,通过对应用领域的认知来精确剔除该算法是非常重要的。通常,所有算法都基于不同的输入参数,例如聚类的数量,优化/构造标准,终止条件,邻近度等。额外设计或者剔除这些不同的参数和标准,以此来作为这个步骤的前提条件。
C. Cluster Validation (聚类验证)
将不同的聚类算法用于同一数据集可以产生不同的结果。甚至是相同的算法,不同的参数也会产生不同的聚类结果。因此,必须验证或评估该聚类方法产生的结果。评估标准分为:
1)内部指标:内部指标是通过和它的数据进行比较来评估由聚类算法产生的聚类
2)外部指标:外部指标通过利用已知的知识(例如:类别标签)来评估聚类结果。
3)相对指标:顾名思义,该标准将结果与不同算法产生的其他结果进行比较。
D. Results Interpretation 结果解析
聚类过程的最后一步涉及聚类的展示。聚类的最终目的是为了让人们更了解原始数据,以便它们更有效地分析和解决难题。
因为“Cluster(集群)”的概念无法精确地被定义,所以聚类的算法种类有很多,比较常见的有:
Connectively - based clustering (hierarchical clustering)
基于连接的聚类(层次聚类)
Centroid-based clustering -- k-means
Density-based clustering -- kernel density estimation
基于密度的聚类 -- 例如:核密度估计
Grid-based clustering 基于网格的集群
基于连接的聚类(也称为分层聚类),是基于这样的一个核心思想:即与附近的对象而不是较远的对象更为相关。该算法根据距离将对象连接起来形成簇(cluster)。可以通过连接各部分所需的最大距离来大致描述集群。在不同的距离,形成不同簇,这可以使用一个树状图来呈现。这也解析了“分层聚类”的来源,这些算法不提供数据集的单一部分,而是提供一个广泛的集群层次结构,这些集群以一定的距离合并。在树状图中,y轴标记聚类合并的距离,而对象沿x轴放置,以使聚类不混合。
基于连接的聚类是一群方法,它们的区别在于计算距离的方式不同。除了选用距离函数之外,还需要确定要使用的连接标准(因为一个聚类包含多个对象,因此有多个候选对象可以用来计算距离)。流行的选择称为“单链接聚类”(最小对象距离),“完整链接聚类”(最大对象距离)和“UPGMA”或者“WPGMA”(“Unweighted or Weighted Pair Group Method with Arithmetic Mean”, 也称为平均链接集群)。此外,分层聚类可以是聚集性的(从单个元素开始并将其聚合为聚类)或分散性的(从完整的数据集开始并将其划分为分区)。
分层聚类通过依次合并或拆分嵌套聚类来构建它们。聚类的这种层次结构表现为树(或者树模型)。这棵树的根是唯一的簇(cluster),聚集了所有样本,树叶是仅包含了一个样本的簇(cluster)。(还是叫cluster更形象一点)
分层聚类涉及创建从上到下具有预定顺序的聚类。因此,可以说是有两种类型的层次聚类,即分裂聚类和聚集聚类。
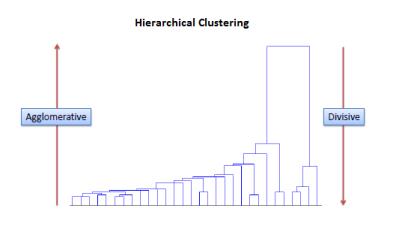
Divisive method 分层方法
在divisive 或者从上至下的聚类方法中,所有的观测值被分配给了一个单一的聚类,然后将这个cluster分开至至少两个相似的clusters. 最后我们在每个聚类上进行递归,直到每个observation只有一个聚类。在某些情况下,分类算法比聚集算法产生的精度更高,但是从概念上更复杂。
Agglomerative method 聚集方法
在聚集或者自下而上的聚类方法中,把每个观测值分配到他自己的聚类中,然后计算每个聚类之间的相似度(例如:距离),并且结合两个最相似的聚类。最后,重复步骤2和步骤3直到仅剩下一个单一聚类。相关的算法展示如下:

在执行任何聚类之前,需要使用距离函数确定包含每个点之间距离的邻近矩阵。然后,更新矩阵以显示每个集群之间的距离。下面三个方法的不同之处在于如何测量每个集群之间的距离。
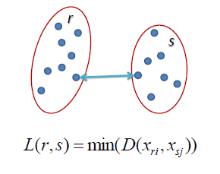
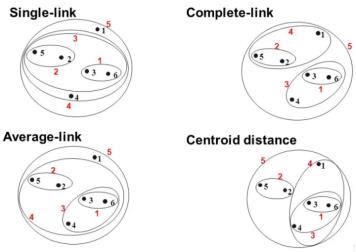
Single linkage 最短距离
在single linkage 层次聚类中,两个聚类之间的距离是通过在属于每个聚类中的两个点的最短的距离来定义的。例如,聚类”r” 和”s”之间的距离等于图上面两个最近点之间的距离,即那个箭头的长度。
Complete linkage
在complete linkage 层次聚类中,两个聚类之间的距离定义为每个聚类中两个点之间的最长距离。例如,聚类”r” 和”s”之间的距离等于它们最远的两个点的长度,即下图中那个箭头的长度。
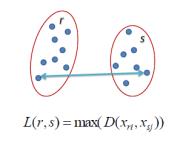
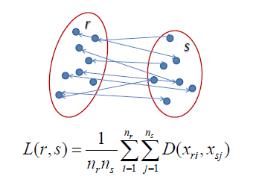
Average linkage
在average linkage层次聚类中,两个聚类之间的距离定义为一个聚类中每个点到另一个聚类中每个点之间的平均距离。例如,集群”r”和”s”之间的距离等于每个箭头将一个集群的点连接到另一个集群的点之间的平均长度。
Ward’s 的方法旨在最大程度地降低总的集群内的方差。在每一步中,将集群间距离最小的一对集群合并。换句话说,它以最小化与每个集群相关的损失的方式来形成集群。在每个步骤中,考虑每个可能的集群对组合,并将合并之后信息损失(information loss)增加最小化的两个集群合并。这里信息损失是由Ward根据 error sum-of-squares criterion (ESS)定义的。ESS不明白的可以google或者百度哈。
Affinity: str or callable, default=’euclidean’
用来计算linkage(连接)的度量,欧式距离,L1,L2,manhattan, cosine,或者precomputed等。如果linkage这个参数选择的是 “ward”,那么这里只能使用’euclidean’欧氏距离。
Connectivity: array-like, default=None
Compute_full_tree: ‘auto’ or bool, default=’auto’
在n_clusters处早停树结构。在和样本数量相比,聚类数量不小的情况下,非常有助于减少计算时间。
Linkage:{‘ward’,’complete’,average’,’single’}, default=’ward’
在计算距离时使用到的Linkage方法。
使用的连接标准。这个连接标准决定了在不同的observation之间使用哪个距离计算方式。该算法将会合并那些最小化该标准的聚类对。
‘ward’:最小化要合并的集群的方差(在这种场景下类似于k-means 目标函数,但是采用了一个聚集的分层方法)。
‘average’:使用两组中每个观测值(observations)的距离平均值。
‘complete’ or ‘maximum’ linkage:使用两组的所有观测值(observations)之间的最大距离。
‘single’ : 使用两组的所有观测值(observations)之间的最小距离。
Distance_threshold: float, default=None
高于这个distance_threshold的linkage distance,那些cluster 就不会被合并,低于则被合并。
Compute_distances: bool, default=False
即使没有使用distance_threshold,也要计算clusters之间的距离。这可以用进行树状图可视化,但是会带来计算和内存的开销。
N_clusters: int,聚类的数量。
Labels_: ndarray of shape(n_samples), 每个点的标签。
N_leaves_:int,分层聚类中叶子的数量。
N_connected_components_:int, 图中估计的已连接成分。
Children_: 非叶节点的子节点。
Distances_: 子节点中对应位置的节点之间的距离。
自带的案例:
from sklearn.cluster import AgglomerativeClusteringimport numpy as npX = np.array([[1, 2], [1, 4], [1, 0],[4, 2], [4, 4], [4, 0]])clustering = AgglomerativeClustering().fit(X)
AgglomerativeClustering()clustering.labels_
plt.scatter(X[:,0],X[:,1],c=clustering.labels_,cmap='viridis')分类的结果:
Plot Hierarchical Clustering Dendragram:
import numpy as npfrom matplotlib import pyplot as pltfrom scipy.cluster.hierarchy import dendrogramfrom sklearn.datasets import load_irisfrom sklearn.cluster import AgglomerativeClusteringdef plot_dendrogram(model, **kwargs):# Create linkage matrix and then plot the dendrogram# create the counts of samples under each nodecounts = np.zeros(model.children_.shape[0])n_samples = len(model.labels_)for i, merge in enumerate(model.children_):current_count = 0for child_idx in merge:if child_idx < n_samples:current_count += 1 # leaf nodeelse:current_count += counts[child_idx - n_samples]counts[i] = current_countlinkage_matrix = np.column_stack([model.children_, model.distances_,counts]).astype(float)# Plot the corresponding dendrogramdendrogram(linkage_matrix, **kwargs)iris = load_iris()X = iris.data# setting distance_threshold=0 ensures we compute the full tree.model = AgglomerativeClustering(distance_threshold=0, n_clusters=None)model = model.fit(X)plt.title('Hierarchical Clustering Dendrogram')# plot the top three levels of the dendrogramplot_dendrogram(model, truncate_mode='level', p=3)plt.xlabel("Number of points in node (or index of point if no parenthesis).")plt.show()
以上是关于聚类算法(Clustering Algorithms)之层次聚类(Hierarchical Clustering)的主要内容,如果未能解决你的问题,请参考以下文章
A practical algorithm for distributed clustering and outlier detection
聚类算法(Clustering Algorithms)之层次聚类(Hierarchical Clustering)