机器学习之决策树
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之决策树相关的知识,希望对你有一定的参考价值。
1、算法介绍
决策树是一种基本的分类和回归方法,决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。决策树学习通常包括三个步骤:特征选择、决策树的生成和决策树的修剪。决策树的本质是从训练数据集中归纳出一组分类规则。本文主要是对决策树的ID3算法的介绍,后文会介绍C4.5和CART算法。
2、算法优缺点
优点:计算复杂度不高,结果易于理解,对于中间值的缺失不敏感,可以处理不相关特征。
缺点:可能会产生过拟合问题。
适用于标称型(ID3和C4.5)和数值型(CART算法)
3、特征选择
熵:
设X是一个取有限个值的离散随机变量,其概率分布为:
则随机变量X的熵定义为:条件熵:
条件熵H(Y|X):表示在己知随机变量X的条件下随机变量Y的不确定性,定义为X给定条件下Y的条件概率分布的熵对X的数学期望:
信息增益:
信息增益:特征A对训练数据集D的信息增益,g(D,A), 定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即g(D,A)=H(D)-H(D|A)
因此,选择信息增益最优,也即是信息增益最大的特征作为节点,然后再循环构建决策树。
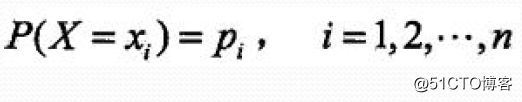
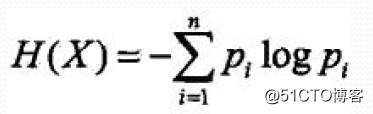
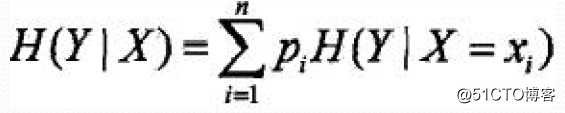
4、数学例子
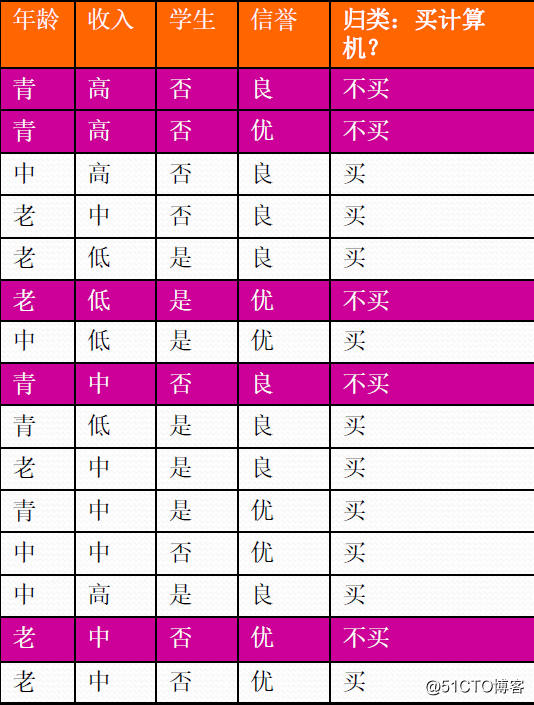
首先计算熵:
样本总共有15条记录,其中不买的有5条记录,买的有10条记录。
所以H(D) = -5/15log2(5/15)-10/15log2(10/15) = 0.92
再计算条件熵:
年龄:青年有5条记录,其中不买的为3条,买的记录为2条
中年有4条记录,其中不买的为0条,买的记录为4条
老年有6条记录,其中不买的为2条,买的记录为4条
则条件熵为5/15*(-3/5*log(3/5,2)-2/5*log(2/5,2)) + 4/15*(0 - 4/4*log(4/4,2)) + 6/15*(-2/6*log(2/6,2)-4/6*log(4/6,2)) = 0.69
所以年龄的信息增益为0.23
当特征值取收入,学生,信誉时,信息增益分别为:0.03,0.17,0.03
故选择年龄为第一次迭代的节点,然后再重复上述步骤,最后完成树的构建。
5、ID3代码实现
from sklearn.model_selection import train_test_split
import math
def getData():
#获取数据集,数据来自uci的mushroom.data
data_x = [];data_y = [];train = []
with open(‘mushroom.data‘) as f:
for line in f:
line = line.strip().split(‘,‘)
data_x.append(line[1:])
data_y.append(line[0])
train_x,test_x,train_y,test_y = train_test_split(data_x,data_y,test_size=0.8,random_state=0)
for x,y in zip(train_x,train_y):
x.append(y)
train.append(x)
return train,test_x,test_y
def calI(prob):
‘‘‘封装对数计算公式‘‘‘
I = 0.0
for p in prob:
if p != 0: # p=0时不能计算log
I += -p * math.log(p, 2)
return I
def calInfo(dataSet):
‘‘‘计算信息熵‘‘‘
values = [value[-1] for value in dataSet]
uniqueVal = set(values)
prob = []
for val in uniqueVal:
#计算p
prob.append(values.count(val) / float(len(values)))
return calI(prob)
def splitDataSet(dataSet, axis, value):
#划分数据集,三个参数分别是待划分的数据集,划分数据集的体征,需要返回的值
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)#把符合返回的值那些返回(axis那一列不添加)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #计算特征的数目
baseEntropy = calInfo(dataSet) #香农熵
bestInfoGain = 0.0 #最好的信息增益
bestFeature = -1 #最好的信息增益对应的特征
for i in range(numFeatures):
featList = [example[i] for example in dataSet]#获得该列所可能取的值
uniqueVals = set(featList) #去重
newEntropy = 0.0 #条件熵
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)#划分数据集
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calInfo(subDataSet)
infoGain = baseEntropy - newEntropy #计算信息增益
if (infoGain > bestInfoGain): #选择最好的信息增益
bestInfoGain = infoGain
bestFeature = i
return bestFeature #返回列
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key=lambda x:x[1], reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
#迭代构建决策树
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]#类别完全相同停止划分
if len(dataSet[0]) == 1: #遍历完所有特征返回次数最多的
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
def classify(inputTree,featLabels,testVec):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
key = testVec[featIndex]
valueOfFeat = secondDict[key]
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else: classLabel = valueOfFeat
return classLabel
def correct_rate(test_y,predict_y):
#返回测试集的正确率
length = len(test_y)
score = 0
for num in range(length):
if test_y[num] == predict_y[num]:
score += 1
rate = str((score/float(length)) *100) + ‘%‘
return rate
if __name__ == ‘__main__‘:
train,test_x,test_y = getData()
labels = [‘cap-shape‘,‘cap-surface‘,‘cap-color‘,‘bruises‘,‘odor‘,‘gill-attachment‘,‘gill-spacing‘,‘gill-size‘,‘gill-color‘,‘stalk-shape‘,‘stalk-root‘,‘stalk-surface-above-ring‘,‘stalk-surface-below-ring‘,‘stalk-color-above-ring‘,‘stalk-color-below-ring‘,‘veil-type‘,‘veil-color‘,‘ring-number‘,‘ring-type‘,‘spore-print-color‘,‘population‘,‘habitat‘]
label = labels[:]
mytree = createTree(train, labels)
predict_y = []
for x in test_x:
y = classify(mytree,label,x)
predict_y.append(y)
print(‘正确率:‘,correct_rate(test_y,predict_y))博主在做交叉验证时出了问题,探索了很久,发现原因在于一开始选的数据集太过单一,导致树的构建不完整,在验证模型正确率时出现错误,因此改用了mushroom.data,此数据集在uci网站可以下载,共有8124个记录。
参考书籍:
《统计学习方法》--李航
《机器学习实战》--Peter
以上是关于机器学习之决策树的主要内容,如果未能解决你的问题,请参考以下文章