机器学习之决策树
Posted junjiang3
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之决策树相关的知识,希望对你有一定的参考价值。
一、基本流程
决策树是一类常见的机器学习方法,其是基于树结构来进行决策的,这恰是人类在面临决策问题时很自然的一种处理机制。例如我们要对“这是好瓜吗?”这样的问题
进行决策时,通常会进行一系列的判断或者“子决策”。这个决策的流程如下图所示:
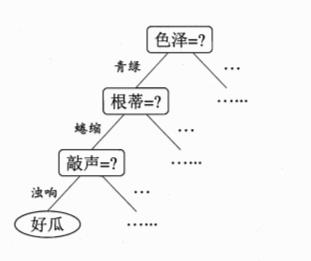
一般的,一棵树包含一个根节点,若干个内部节点和若干个叶子结点,叶子结点对应于决策结果,其它每个节点则对应于一个属性测试,每个节点包含的样本集合
根据属性测试的结果被划分到子节点中;根节点包含样本全集。决策树的目的是产生一课泛化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单而直
观的分而治之的策略,如下图所示:

由上图发现,很显然,决策树的生成是一个递归过程。
二、划分选择
由上图的算法可以看出,决策树学习的关键是第8行,即如何选择最优属性划分。通常,随着划分的不断进行,我们希望决策树的分直接点所包含的样本尽可能属于
同一类别,即结点的“纯度”越来越高。下面我们将介绍一种节点划分的方法——信息增益。
在介绍信息增益之前,我们先看看什么是信息熵。
信息熵是度量样本集合纯度最常用的一种指标,假设当前样本集合D中第k类样本所占比例![]() ,则D的信息熵定义为:
,则D的信息熵定义为:
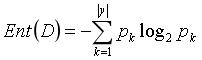
![]() 的值越小,则D的纯度越高。
的值越小,则D的纯度越高。
现在,我们来看看信息信息增益的计算过程,假设离散属性a有V个可能的取值![]() ,如果我们使用属性a来对样本D进行划分,则可能会产生V个分支节点,其中
,如果我们使用属性a来对样本D进行划分,则可能会产生V个分支节点,其中
第v个分支节点包含了D中所有在属性上a取值为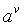 的样本,即为
的样本,即为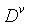 ,我们根据信息熵的公式即可计算出
,我们根据信息熵的公式即可计算出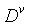 的信息熵,再考虑到不同的分支节点所包含的的样本数
的信息熵,再考虑到不同的分支节点所包含的的样本数
的不同,给分支节点赋予不同的权重![]() 即样本越多的分支节点的影响越大,于是即可计算出属性a对样本集D进行划分的信息增益,如下式所示:
即样本越多的分支节点的影响越大,于是即可计算出属性a对样本集D进行划分的信息增益,如下式所示:
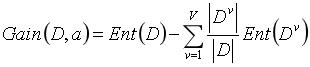
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。因此,我们可用信息增益来进行决策树的划分属性选择。即在算法的第8行选择
属性![]() ,著名的ID3决策树算法就是以信息增益为准则来进行选择划分属性的。
,著名的ID3决策树算法就是以信息增益为准则来进行选择划分属性的。
下面,我们以一个如下图所示的西瓜数据集为例,是用信息增益来构造一课决策树:
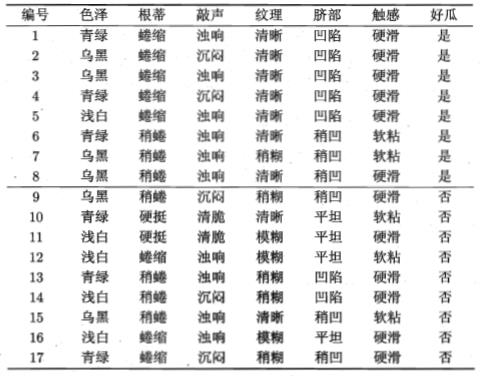
该数据集包含17个训练样本,很显然是一个二分类问题,|y|=2,在决策树学习开始之前,根节点包含D中所有的样例,其中正例占8/17,反例占9/17,于是根据公式
可以计算出根节点的信息熵为:
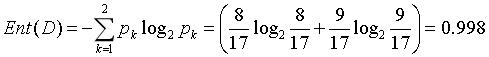
然后,我们要计算出当前属性集合{色泽,根蒂,敲声,纹理,脐部,触感}中每个属性的信息增益,以属性“色泽”为例,它有3个可能的取值:{青绿,乌黑,浅白},
若使用该属性对D进行划分,则得到3个子集,分别记为D1(色泽=青绿),D1(色泽=乌黑),D1(色泽=浅白)。以子集D1为例,其包含编号为{1,4,6,10,13,17}
的6个样例,其中正例占3/6,反例占3/6.因此我们可以计算出“色泽”划分之后所获得的3个分支结点的信息熵:
![]()
![]()
![]()
于是,我们可以计算出属性色泽的信息增益为:
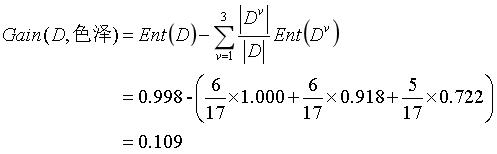
类似的,我们可计算出其他属性的信息增益为:
Gain(D,根蒂)=0.143;Gain(D,敲声)=0.141;Gain(D,纹理)=0.381;Gain(D,脐部)=0.289;Gain(D,触感)=0.006
显然,属性纹理的信息增益最大,于是它被选为划分属性,下图给出了基于“纹理”对根节点进行划分的结果:
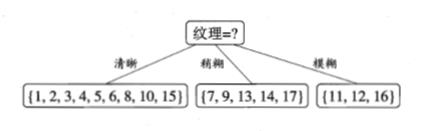
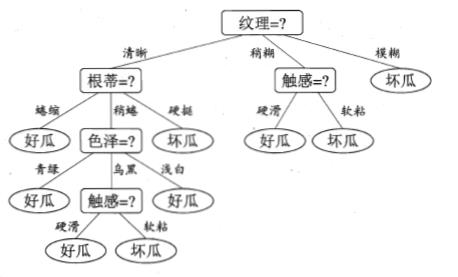
然后,使用递归的过程,对每个分支节点重复上述过程,最终可得到如下图所示的决策树:
三、剪枝处理
剪枝是决策树学习算法对付“过拟合”的主要手段,在决策树学习中,为了尽可能正确的分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这是
就可能因训练样本学习的“太好”了,以至于把训练集自身的一些特点当做所有数据都具有的一般性质二导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的
风险。
决策树剪枝的基本策略有“预剪枝”和“后剪枝”。其中预剪枝是指在决策树生成的过程中,对每个节点在划分前进行评估,若当前结点的划分不能带来决策树泛化能力的性能提升
,则停止划分并将当前节点标记为叶节点。而后剪枝则是先从训练集生成一颗完整的决策树,然后自底向下的对菲叶子结点进行考察,若将该结点对应的子树替换为叶子结点能
带来泛化能力的提升,则将该子树替换为叶子结点。
那么如何判断决策树泛化能力是否提升了呢,这可使用留出法进行判断,即留出一部分数据做为“验证集”以进行性能评估。
以上是关于机器学习之决策树的主要内容,如果未能解决你的问题,请参考以下文章