统计学习方法c++实现之四 决策树
Posted bobxxxl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了统计学习方法c++实现之四 决策树相关的知识,希望对你有一定的参考价值。
决策树
前言
决策树是一种基本的分类和回归算法,书中主要是讨论了分类的决策树。决策树在每一个结点分支规则是一种if-then规则,即满足某种条件就继续搜索左子树,不符合就去右子树,看起来是用二叉树实现对吧,实际的CART决策树就是二叉树,等会再介绍。现在先来看看决策树的理论部分。代码地址https://github.com/bBobxx/statistical-learning/blob/master/src/decisiontree.cpp
决策树相关理论
决策树的学习通常包括三个部分:特征选择, 决策树生成和决策树修剪。
特征选择
我们抛开烦人的公式和术语,用通俗的思想(没办法,本人只有通俗的思想)来理解一下,现在给你很多数据,有很多类,每个数据有n维的特征,怎么分?最简单的,不如来个全连接神经网络,把数据丢进去,让模型自己去学习去,恩.....这个办法可能是准确率最高的,但是我们这里学习的是决策树,而且有些场景根本不需要神经网络也可以分类的很准确,现在让我们用决策树解决这个问题。
首先,面对n维特征,和k个类别,仿佛无从下手。咋办呢,笨一点的办法,就从第一个特征开始,如果第一个特征有m个不同取值,那我就按这个特征取值把数据分成m份,对这份特征子集,我再选第二个特征,第二个特征比如有l个不同取值,那么对于m个子集,每个又可以最多分出l个子集(最多而不是一定,因为m某个子集中的数据的第二维特征可能取不全l个值),那么现在我们最多有(m imes l) 个子集,然后是第三维特征......直到第n维特征或者某个子集中的数据类别几乎一样我们就停止。对于这种分法很明显确实是个树结构对吧,只不过你的树可能是这样子的:

不好意思,弄错了,一般树结构是这样子的:

思路很简单,但是过程很复杂对吧,没错,这就是决策树,但是如果真写成上面这样也太没效率了,比如说,现在给你很多人的数据,让你分出是男是女,特征有这么几个:身高,体重,头发长短,身份证上的性别。没错最后一个特征一般不会给出的。现在开始按照上面的思路分类,就分10000个数据吧,身高的取值有十种,就当做150到190取十个数吧,体重先不谈,如果从身高这个特征开始分就能把你分吐血。聪明的同学(应该是不笨的)一眼就能看出来,我直接用最后一个特征,一下子就分出来了,就算没有最后这个特征,我用头发长短这个也可以很好的分。
没错,看出特征选择的重要了吧,这就是决策树的第一步,要先选择最具有分类能力的特征,注意每一维特征只用一次。怎么选呢,这就涉及到了信息增益(ID3决策树), 信息增益比(C4.5决策树),和基尼指数(CART决策树)。皮一下,这里就只介绍基尼指数吧,其他的就看书吧。
基尼指数:(Gini(D,A)=frac{|D_1|}{|D|}Gini(D_1)+frac{|D_2|}{|D|}Gini(D_2))
其中,A代表某一维特征,D代表的数据集合,根据A是否取a将D分为(D_1) 和(D_2)两个子集,(|D|,|D_1|,|D_2|)分别代表各自的数量。
其中,(Gini(D) = sum_{k=1}^{K}frac{|C_k|}{|D|}(1-frac{|C_k|}{|D|}))
(C_k)代表某一类,(frac{|C_k|}{|D|})代表这个集合中样本是第k类的概率。
基尼指数越大,表示样本集合的不确定性越大,我们在选取A的时候肯定希望分完后集合越确定越好,所以以后在进行特征选择的时候就需要选取基尼指数最小的那个特征。
决策树(CART)生成算法
- 对于当前根节点Root,对现有的样本集D,对所有的特征(A_i)的所有可能取值(a_j)计算基尼指数,选择使基尼指数最小的(A_i)和(a_j),根据样本点对(A_i=a_j)的测试为“是”或“否”将D分为(D_1)和(D_2)。
- (D_1)作为根节点Root的左子树的根节点Root_L的样本集,(D_2)作为根节点Root的右子树的根节点Root_R的样本集。
- 重复1,2直到结点中样本个数小于阈值,或样本集基本属于同一类,或者没有更多特征(代表已经将所有的特征都过一遍了)。
CART剪枝
请自行看书,反正我也没实现。
决策树的c++实现
代码结构
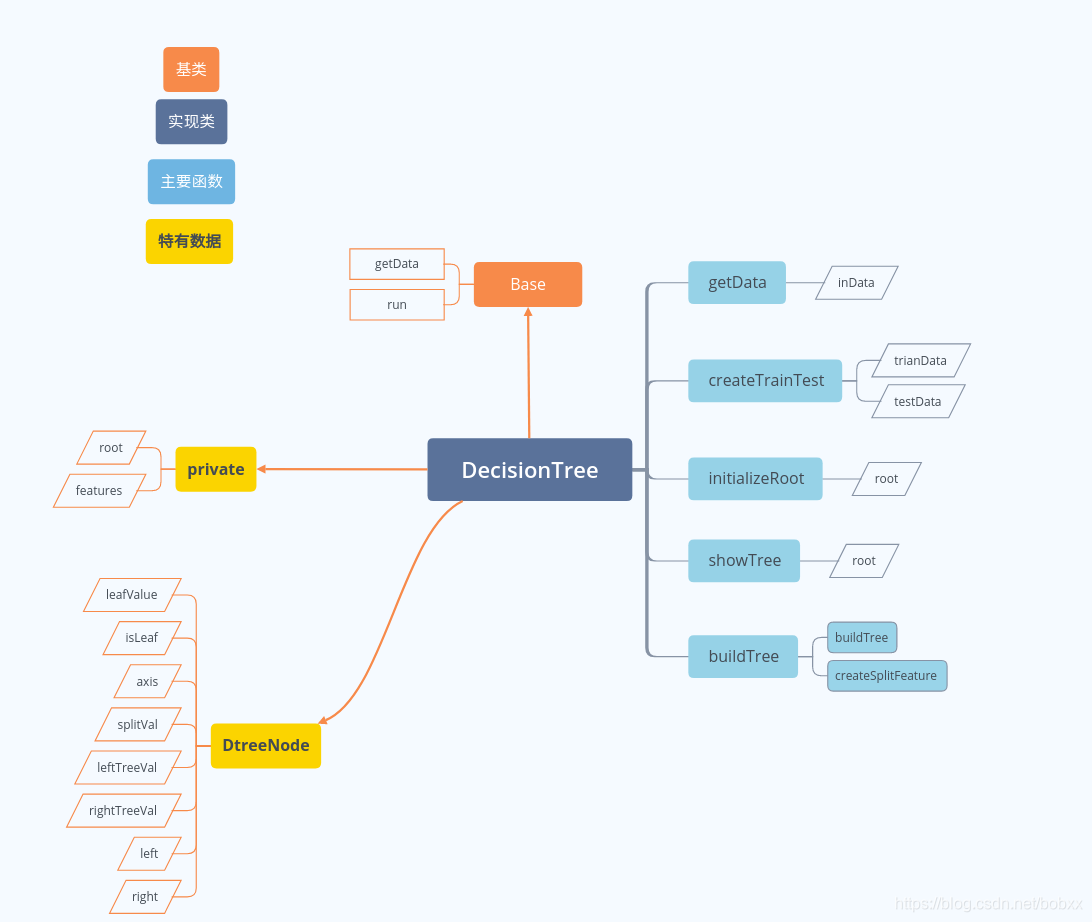
实现
这里只展示如何确定分割的特征和值
pair<int, double> DecisionTree::createSplitFeature(vector<vector<double >>& valRange){
priority_queue<pair<double, pair<int, double>>, vector<pair<double, pair<int, double>>>, std::greater<pair<double, pair<int, double>>>> minheap;
//pair<double, pair<int, double>> first value is Gini value, second pair (pair<int, double>) first value is split
//axis, second value is split value
vector<map<double, int>> dataDivByFeature(indim); //vector size is num of axis, map‘s key is the value of feature, map‘s value is
//num belong to feature‘value
vector<set<double>> featureVal(indim); //store value for each axis
vector<map<pair<double, double>, int>> datDivByFC(indim); //vector size is num of axis, map‘s key is the feature value and class value, map‘s value is
//num belong to that feature value and class
set<double> cls; //store num of class
for(const auto& featureId:features) {
if (featureId<0)
continue;
map<double, int> dataDivByF;
map<pair<double, double>, int> dtDivFC;
set<double> fVal;
for (auto& data:valRange){ //below data[featureId] is the value of one feature axis, data.back() is class value
cls.insert(data.back());
fVal.insert(data[featureId]);
if (dataDivByF.count(data[featureId]))
dataDivByF[data[featureId]] += 1;
else
dataDivByF[data[featureId]] = 0;
if (dtDivFC.count(std::make_pair(data[featureId], data.back())))
dtDivFC[std::make_pair(data[featureId], data.back())] += 1;
else
dtDivFC[std::make_pair(data[featureId], data.back())] = 0;
}
featureVal[featureId] = fVal;
dataDivByFeature[featureId] = dataDivByF;
datDivByFC[featureId] = dtDivFC;
}
for (auto& featureId: features) { // for each feature axis
if (featureId<0)
continue;
for (auto& feVal: featureVal[featureId]){ //for each feature value
double gini1 = 0 ;
double gini2 = 0 ;
double prob1 = dataDivByFeature[featureId][feVal]/double(valRange.size());
double prob2 = 1 - prob1;
for (auto& c : cls){ //for each class
double pro1 = double(datDivByFC[featureId][std::make_pair(feVal, c)])/dataDivByFeature[featureId][feVal];
gini1 += pro1*(1-pro1);
int numC = 0;
for (auto& feVal2: featureVal[featureId])
numC += datDivByFC[featureId][std::make_pair(feVal2, c)];
double pro2 = double(numC-datDivByFC[featureId][std::make_pair(feVal, c)])/(valRange.size()-dataDivByFeature[featureId][feVal]);
gini2 += pro2*(1-pro2);
}
double gini = prob1*gini1+prob2*gini2;
minheap.push(std::make_pair(gini, std::make_pair(featureId, feVal)));
}
}
features[minheap.top().second.first]=-1;
return minheap.top().second;
}这里使用循环嵌套计算符合条件的数据的数量,效率很低,有更好方法的同学麻烦告知一下,叩拜~
以上是关于统计学习方法c++实现之四 决策树的主要内容,如果未能解决你的问题,请参考以下文章
Thinking in SQL系列之四:数据挖掘C4.5决策树算法
Thinking in SQL系列之四:数据挖掘C4.5决策树算法
Thinking in SQL系列之四:数据挖掘C4.5决策树算法