Thinking in SQL系列之四:数据挖掘C4.5决策树算法
Posted niulity
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Thinking in SQL系列之四:数据挖掘C4.5决策树算法相关的知识,希望对你有一定的参考价值。
原创: 牛超 2017-02-11 Mail:10867910@qq.com
C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5的目标是通过学习,积累经验,为后续决策服务。
该算法目前能找到各类版本,C、JAVA、PYTHON。而SQL版本闻所未闻,前篇我有提过,数据处理,SQL为王,如何以SQL的思维来实现C4.5决策树算法是本篇的重点。
PS:多年与SQL打交道,写下本篇,也算是一种情怀吧。文中很多都是个人观点,萝卜白菜,勿计较。
C4.5的核心是分裂规则,因为它们决定给定节点上的元组如何分裂。本篇实现比较流行的属性选择度量,即信息增益、增益率。这个规则也是要实现的重点功能,后续程序会有介绍。
先祭出为实现该算法的几个数学公式
信息增益,又称为熵
按照类标签对训练数据集D的属性集A进行划分,得到信息熵,著名的香农定理:
 (1)
(1)
按照属性集A中每个属性进行划分,得到一组信息熵:
 (2)
(2)
信息增益定义:
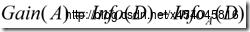 (3)
(3)
分裂信息的度量(类似公式1)
 (4)
(4)
信息增益率定义:
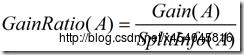 (5)
(5)
选择具有最大增益率的属性作为分裂属性。
接下来以一个很典型被引用过多次的训练数据集D为例,来说明C4.5算法如何通过分裂规则来选择决策结点。

上面的训练集有4个属性,即属性集合A=天气, 温度, 湿度, 风速;而类标签有2个,即类标签集合C=进行, 取消,分别表示适合户外运动和不适合户外运动,其实是一个二分类问题。上面的图形象地描述了第一次分裂的属性为天气,由左边的学习样本集形成树的第一层。
结合之前提到的5个公式,可以通过下列SQL给出第一次分裂的实现思路:
WITH TDATA AS (
SELECT '晴' OUTLOOK,'炎热' TEMP,'高' HUMIDITY,'弱' WINDY,'取消' ACTION FROM DUAL UNION ALL
SELECT '晴','炎热','高','强','取消' FROM DUAL UNION ALL
SELECT '阴','炎热','高','弱','进行' FROM DUAL UNION ALL
SELECT '雨','适中','高','弱','进行' FROM DUAL UNION ALL
SELECT '雨','寒冷','正常','弱','进行' FROM DUAL UNION ALL
SELECT '雨','寒冷','正常','强','取消' FROM DUAL UNION ALL
SELECT '阴','寒冷','正常','强','进行' FROM DUAL UNION ALL
SELECT '晴','适中','高','弱','取消' FROM DUAL UNION ALL
SELECT '晴','寒冷','正常','弱','进行' FROM DUAL UNION ALL
SELECT '雨','适中','正常','弱','进行' FROM DUAL UNION ALL
SELECT '晴','适中','正常','强','进行' FROM DUAL UNION ALL
SELECT '阴','适中','高','强','进行' FROM DUAL UNION ALL
SELECT '阴','炎热','正常','弱','进行' FROM DUAL UNION ALL
SELECT '雨','适中','高','强','取消' FROM DUAL
) ,TA AS (
SELECT TDATA.*,
ACTION ACTION1,
COUNT(1) OVER ( PARTITION BY ACTION ) PA ,
COUNT(1) OVER ( PARTITION BY OUTLOOK ) PW1 ,
COUNT(1) OVER ( PARTITION BY TEMP ) PT1,
COUNT(1) OVER ( PARTITION BY HUMIDITY ) PH1 ,
COUNT(1) OVER ( PARTITION BY WINDY ) PN1,
COUNT(1) OVER ( PARTITION BY OUTLOOK,ACTION ) PW2 ,
COUNT(1) OVER ( PARTITION BY TEMP,ACTION ) PT2,
COUNT(1) OVER ( PARTITION BY HUMIDITY,ACTION ) PH2 ,
COUNT(1) OVER ( PARTITION BY WINDY,ACTION ) PN2,
COUNT(1) OVER () CNT
FROM TDATA
) ,TB AS (
SELECT DISTINCT TYPE , VALUE, ACTION ,CNT , C1 , C2
FROM TA
UNPIVOT (
(VALUE , C1 , C2 ) FOR TYPE IN (
(ACTION1 , PA , PA ) AS '0',
(OUTLOOK , PW1 , PW2 ) AS 'W',
(TEMP, PT1 , PT2 ) AS 'T',
(HUMIDITY ,PH1 , PH2 ) AS 'H',
(WINDY ,PN1 , PN2 ) AS 'N'
)
)
) , TC AS (
SELECT TYPE , VALUE , CNT,C1,
SUM( - C2/C1 * LOG(2,C2/C1) ) INFO_J,
DECODE(COUNT(DISTINCT ACTION),1,MIN(ACTION)) PURE_ACTION
FROM TB
GROUP BY TYPE , VALUE , CNT,C1
ORDER BY 1 , 2 , 3
) ,TD AS (
SELECT TYPE ,
SUM( - C1/CNT * LOG(2,C1/CNT) ) H_SPLIT_INFO ,--每个属性的分裂信息度量
SUM( C1/CNT * INFO_J ) INFO --每个属性的统计平均熵
FROM TC
GROUP BY TYPE
) , TE AS (
SELECT A.TYPE , --属性类别
A.H_SPLIT_INFO , --分裂信息度量
A.INFO , --每个属性的信息熵
B.H_SPLIT_INFO INFO_D,--类别信息熵
B.H_SPLIT_INFO - A.INFO GAIN ,--信息增益
(B.H_SPLIT_INFO - A.INFO) / A.H_SPLIT_INFO IGR --信息增益率
FROM TD A
JOIN TD B
ON B.TYPE = '0'
AND A.TYPE != B.TYPE
) , TF AS (
SELECT TC.TYPE ,ROWNUM RNUM, TC.VALUE ,TC.PURE_ACTION,
1 ALEVEL ,NULL PTYPE , 0 PRNUM
FROM TE
JOIN TC
ON TE.TYPE = TC.TYPE
AND TE.IGR = (SELECT MAX(IGR) FROM TE )
) SELECT * FROM TF
简单地介绍一下思路:因各个属性A与分类D的信息熵较为独立,为了能同时并行计算,首先构造集合TB,这里使用了反透视UNPIVOT操作,将各属性A转为一个集合TC后计算分类D以及各属性A的分裂度量(公式1、公式4),推入到TD中求统计平均值E(公式2)做为属性A的熵。接着将属性A的增益对分类D信息熵的依赖关系转为JOIN连接(集合TE)后同时计算各个属性的信息增益GAIN与增益率IGR。如下我们可以单独输出查看TE的结果。

集合TF实现的动作最简单,增益率最大的属性,结果如下:

这样便构建了决策树的第一层,其中第二行是“纯”的,可以直接做为决策树的叶子结点,而剩下的1,3行接着用来分裂其他属性。
通过进一步观察,我们可以发现这个分裂过程是递归的,递归终止的条件是分裂结点全部为叶子。SQL如何递归地找到所有分裂的结点,答案是借助11G的RSF特性。递归主体已经确认,但递归的过程会依赖上一层的属性值来构造新的集合,该用什么方式处理呢?有种方式,提前构造好属性与其它属性的组合E C4N(N=1..3),即N元笛卡尔并集,再与上次递归产生的集合连接后产生新的集合应该可以实现。但考虑到训练集基数可能很大会导致系统开销过高,所以不推荐这种方式。
纯SQL实现既然存在性能问题,我们可以用自定义函数来封装以产生子集合。终于忍不住把PLSQL推上场了?请不要误会,笔者不太会写FOR循环,而是借用动态SQL来构造集合TE,正如前篇所阐述:PLSQL是用来辅助SQL的,而非替代。Thinking in SQL的思想没有变。然后再考虑一下功能通用性,我们可以定义表来存储训练集数据,按批次生成决策树,并将OUTLOOK、WINDY抽象成C1、C2...C10,加上ORACLE很教条的自定义类型,程序就如下变成这样了:
1.创建C45学习训练集表
CREATE TABLE DATA_MINING_C45_LEARNING_T
(
BATCH_ID NUMBER,--批次ID
C1 VARCHAR2(100),--属性1
C2 VARCHAR2(100),
C3 VARCHAR2(100),
C4 VARCHAR2(100),
C5 VARCHAR2(100),
C6 VARCHAR2(100),
C7 VARCHAR2(100),
C8 VARCHAR2(100),
ACTION VARCHAR2(100) --决策动作
);--顺便创建索引
CREATE INDEX DATA_MINING_C45_LEARNING_N1 ON DATA_MINING_C45_LEARNING_T(BATCH_ID,C1) ;
CREATE INDEX DATA_MINING_C45_LEARNING_N2 ON DATA_MINING_C45_LEARNING_T(BATCH_ID,C2) ;
CREATE INDEX DATA_MINING_C45_LEARNING_N3 ON DATA_MINING_C45_LEARNING_T(BATCH_ID,C3) ;
CREATE INDEX DATA_MINING_C45_LEARNING_N4 ON DATA_MINING_C45_LEARNING_T(BATCH_ID,C4) ;
CREATE INDEX DATA_MINING_C45_LEARNING_N5 ON DATA_MINING_C45_LEARNING_T(BATCH_ID,C5) ;
CREATE INDEX DATA_MINING_C45_LEARNING_N6 ON DATA_MINING_C45_LEARNING_T(BATCH_ID,C6) ;
CREATE INDEX DATA_MINING_C45_LEARNING_N7 ON DATA_MINING_C45_LEARNING_T(BATCH_ID,C7) ;
CREATE INDEX DATA_MINING_C45_LEARNING_N8 ON DATA_MINING_C45_LEARNING_T(BATCH_ID,C8) ;
INSERT INTO DATA_MINING_C45_LEARNING_T(BATCH_ID , C1,C2,C3,C4,ACTION)
WITH TDATA AS (
SELECT '晴' OUTLOOK,'炎热' TEMP,'高' HUMIDITY,'弱' WINDY,'取消' ACTION FROM DUAL UNION ALL
SELECT '晴','炎热','高','强','取消' FROM DUAL UNION ALL
SELECT '阴','炎热','高','弱','进行' FROM DUAL UNION ALL
SELECT '雨','适中','高','弱','进行' FROM DUAL UNION ALL
SELECT '雨','寒冷','正常','弱','进行' FROM DUAL UNION ALL
SELECT '雨','寒冷','正常','强','取消' FROM DUAL UNION ALL
SELECT '阴','寒冷','正常','强','进行' FROM DUAL UNION ALL
SELECT '晴','适中','高','弱','取消' FROM DUAL UNION ALL
SELECT '晴','寒冷','正常','弱','进行' FROM DUAL UNION ALL
SELECT '雨','适中','正常','弱','进行' FROM DUAL UNION ALL
SELECT '晴','适中','正常','强','进行' FROM DUAL UNION ALL
SELECT '阴','适中','高','强','进行' FROM DUAL UNION ALL
SELECT '阴','炎热','正常','弱','进行' FROM DUAL UNION ALL
SELECT '雨','适中','高','强','取消' FROM DUAL
)
SELECT 1 , OUTLOOK , TEMP , HUMIDITY , WINDY , ACTION FROM TDATA;CREATE OR REPLACE TYPE DATA_MINING_C45_TREENODE IS OBJECT (
CTYPE NUMBER ,--属性分类
RNUM NUMBER ,--分类序号
CVALUE VARCHAR2(100) ,--属性值
PURE_ACTION VARCHAR2(100),--动作,有值表示叶子结点
TLEVEL NUMBER ,--层次
PARENT_CTYPE NUMBER,--父分类
PARENT_RNUM NUMBER--父类序号
) ;
CREATE OR REPLACE TYPE DATA_MINING_C45_TREENODE_TAB IS TABLE OF DATA_MINING_C45_TREENODE;
CREATE OR REPLACE FUNCTION FUN_DATA_MINING_C45_SPLIT( --C4.5单次分裂
P_BATCH_ID NUMBER ,--批次ID
P_ATTR_CNT NUMBER,--属性个数
P_TYPE NUMBER ,--父结点属性ID
P_VALUE VARCHAR2 ,--父结点值
P_RNUM NUMBER DEFAULT NULL--父结点序号
) RETURN DATA_MINING_C45_TREENODE_TAB
IS
V_SQL VARCHAR2(32767) ;--构造SQL
V_UNPIVOT_LIST VARCHAR2(4000);--动态反透视子句
V_TAB DATA_MINING_C45_TREENODE_TAB ;--返回集合
BEGIN
V_SQL := '
WITH TDATA AS (
SELECT *
FROM DATA_MINING_C45_LEARNING_T
WHERE BATCH_ID = :P_BATCH_ID
AND ( :P_TYPE IS NULL
[DEL]OR C%TYPE% = :P_VALUE [ENTER]OR :P_VALUE IS NULL
)
) ,
TA AS (
SELECT TDATA.*,
ACTION ACTION1,
COUNT(1) OVER ( PARTITION BY ACTION ) PA ,
COUNT(1) OVER ( PARTITION BY C1 ) C1_P1 ,
COUNT(1) OVER ( PARTITION BY C2 ) C2_P1,
COUNT(1) OVER ( PARTITION BY C3 ) C3_P1 ,
COUNT(1) OVER ( PARTITION BY C4 ) C4_P1,
COUNT(1) OVER ( PARTITION BY C1,ACTION ) C1_P2 ,
COUNT(1) OVER ( PARTITION BY C2,ACTION ) C2_P2,
COUNT(1) OVER ( PARTITION BY C3,ACTION ) C3_P2 ,
COUNT(1) OVER ( PARTITION BY C4,ACTION ) C4_P2,
COUNT(1) OVER () CNT
FROM TDATA
) ,
TB AS (
SELECT DISTINCT
TYPE , --类别
VALUE, --值
ACTION ,--决策
CNT , --采样数
CNT1 , --类别个数
CNT2 --类别决策个数
FROM TA
UNPIVOT (
(VALUE , CNT1 , CNT2 ) FOR TYPE IN (
(ACTION1 , PA , PA ) AS 0,
--动态构造反透视列,列转行
%V_UNPIVOT_LIST%
)
)
) --SELECT * FROM TB ORDER BY 1 ,2
, TC AS (
SELECT TYPE , VALUE , CNT,CNT1,
SUM( - CNT2/CNT1 * LOG(2,CNT2/CNT1) ) INFO_J,
DECODE(COUNT(DISTINCT ACTION),1,MIN(ACTION)) PURE_ACTION
FROM TB
GROUP BY TYPE , VALUE , CNT,CNT1
ORDER BY 1 , 2 , 3
) --SELECT * FROM TC
,TD AS (
SELECT TYPE ,
SUM( - CNT1/CNT * LOG(2,CNT1/CNT) ) H_SPLIT_INFO ,--每个属性的分裂信息度量
SUM( CNT1/CNT * INFO_J ) INFO --每个属性的统计平均熵
FROM TC
GROUP BY TYPE
) , TE AS (
SELECT A.TYPE , --属性类别
A.H_SPLIT_INFO , --分裂信息度量
A.INFO , --每个属性的信息熵
B.H_SPLIT_INFO INFO_D,--类别信息熵
B.H_SPLIT_INFO - A.INFO GAIN ,--信息增益
(B.H_SPLIT_INFO - A.INFO) / A.H_SPLIT_INFO IGR --信息增益率
FROM TD A
JOIN TD B
ON B.TYPE = 0
AND A.TYPE != B.TYPE
) , TF AS (
SELECT TC.TYPE ,ROWNUM RNUM, TC.VALUE ,TC.PURE_ACTION--,
--1 ALEVEL ,NULL PTYPE , 0 PRNUM
FROM TE
JOIN TC
ON TE.TYPE = TC.TYPE
AND TE.IGR = (SELECT MAX(IGR) FROM TE )
)
SELECT DATA_MINING_C45_TREENODE(TYPE ,RNUM , VALUE , PURE_ACTION , :P_TYPE , :P_RNUM )
FROM TF
' ;
WITH TA AS (
SELECT ROWNUM RNUM
FROM DUAL
CONNECT BY ROWNUM <= P_ATTR_CNT
)
SELECT LISTAGG( REPLACE( '(C%IDX% , C%IDX%_P1 , C%IDX%_P2 ) AS %IDX%' ,'%IDX%',RNUM ) , ','||CHR(10) ) WITHIN GROUP (ORDER BY RNUM)
INTO V_UNPIVOT_LIST
FROM TA
WHERE P_TYPE IS NULL OR RNUM != P_TYPE;
V_SQL := REPLACE(
REPLACE(
REPLACE( REPLACE( V_SQL ,'%TYPE%',P_TYPE ) ,'[DEL]', CASE WHEN P_TYPE IS NULL THEN '--' ELSE NULL END ) --替换依赖的上层属性
,'[ENTER]', CASE WHEN P_TYPE IS NULL THEN CHR(10) ELSE '--' END --换行符,根据参数决定是否开启(换行)
) , '%V_UNPIVOT_LIST%',V_UNPIVOT_LIST ) ;
EXECUTE IMMEDIATE V_SQL
BULK COLLECT INTO V_TAB
USING P_BATCH_ID ,P_TYPE , P_VALUE , P_TYPE , P_RNUM ;
RETURN V_TAB ;
END ;WITH TREE (CTYPE,RNUM,CVALUE,PURE_ACTION,TLEVEL,PARENT_CTYPE,PARENT_RNUM)
AS (
SELECT TA.CTYPE,TA.RNUM,TA.CVALUE,TA.PURE_ACTION,1 TLEVEL,TA.PARENT_CTYPE,TA.PARENT_RNUM
FROM TABLE( FUN_DATA_MINING_C45_SPLIT(1,4,NULL,NULL) ) TA --第一层
UNION ALL
SELECT TB.CTYPE,TB.RNUM,TB.CVALUE,TB.PURE_ACTION,TA.TLEVEL+1,TB.PARENT_CTYPE,TB.PARENT_RNUM
FROM TREE TA
JOIN TABLE( FUN_DATA_MINING_C45_SPLIT(1,4,TA.CTYPE,TA.CVALUE,TA.RNUM) ) TB
ON TA.PURE_ACTION IS NULL --不纯,继续分裂
)
SELECT *
FROM TREE;
6.数据看起来太抽象了?头脑影像化一下生成的整个决策树:
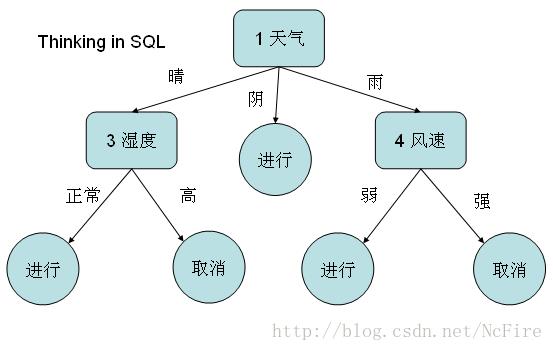
可以说,SQL本身做为关系代数的优秀产物,通过并、交、乘、除四则运算可以完成任意集合间的处理变换。在数据处理方面有其它语言不可替代的优势。大数据是吧,正如数学没有边界那样,SQL语言本身没有瓶颈。本篇正好写在ORACLE 12.2的来临之际,拭目以待,支持了CLOUD、SHARDING、HDFS的ORACLE,如何左右大数据领域的话语权。
以上是关于Thinking in SQL系列之四:数据挖掘C4.5决策树算法的主要内容,如果未能解决你的问题,请参考以下文章