空间点过程分析的R语言实现+PART1(1~4.6)
Posted hollywu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了空间点过程分析的R语言实现+PART1(1~4.6)相关的知识,希望对你有一定的参考价值。
研究WSN空间覆盖能力的论文或多或少会假设随机部署的节点位置是服从柏松点过程(Possion Point Process,PPP)的,刚接触到这个概念也是挺懵了,之前学过随机过程、排队论都是讲的一维上的Possion Process,而二维平面上的PPP如何实现呢?在许多论坛上搜索后,终于找到实现二维PPP的代码实现,原来有个大牛Adrian Baddeley集结了一帮人搞了一个R语言包spatstat专门研究Spatial point process。先给出二维平面上SPP生成代码:
library(spatstat) X <- runifpoint(100) # 二项过程 plot(X) X <- rpoispp(5) # 柏松过程()
plot(X)
X <- rpoispp(function(x, y) { exp( 2 + 5 * x) }) # 密度函数
plot(X)
plot(rMaternI(200, 0.05))
plot(rMaternII(200, 0.05))
《Analysing spatial point patterns in R》是Adrian Baddeley写的关于SPP/R入门材料,我想多了解研究空间随机分布点的统计方法,下面介绍材料的part1--Overview。
1. Introduction
首先介绍了点集表示的背景,一般用来表示二维平面上位置,也可以表示曲面上的或者三维空间中、时空中(这个很厉害的样子)的位置。对于有内在属性的点(要在画图中显示出区别)又称为marks,数据集中起注释作用的数据称为协变量(Covariates),比如spatial function定义了空间上的高度,通常使用像素值或等高线表现。
然后介绍了几个常用的概念。密度(Intensity)表示点集的稀疏情况,根据不同的情况存在均匀密度和非均匀密度的说法。节点间的作用(Interpoint interaction)表示点集的成簇情况。此外对于有协变量的数据,一般还会探求其与密度是否有关系。还演示了几个关于不同点集之间相互影响的例子。
SPP中的统计方法已经有了很长历史,尽管点过程中的概率理论发展的很好,但是统计方法并没发展起来。直到最近,有几项技术发展起来,包括概括统计学(ad hoc平均近邻距离,统计基础较少),与柏松过程比较(检查是否完全随机),建模(仍需完善)。
2. Statistical fomulation
在随机点过程数据集X中,不仅仅点的位置是随机的,点的数量也同样是随机的。研究过程:在得到一个点过程X后,我们只观察固定大小的采样窗口W内的数据,借此推断X的参数,直观上如图所示1。
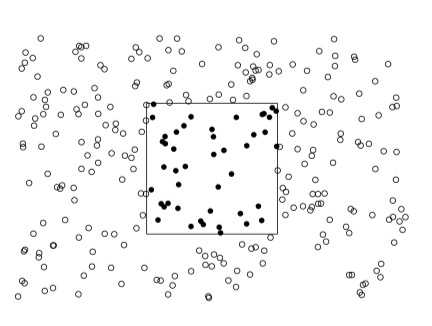
图1

3. The R system
介绍了R语言的运行界面,基本命令操作,一些SPP常用的包及其安装。
4. Introduction to spastat
首先介绍了数据集‘Swedish pines’的导入
data(swedishpines)
X <- swedishpines
plot(X)
学习intensity的概念,并使用高斯核估计/等高线将其可视化
summary(X)
plot(density(X,10))
contour(density(X, 10), axes = FALSE)
嵌块计数的方式进一步了解SPP,介绍了Ripley‘s K function以及Monte Carlo test的R实现
Q <- quadratcount(X, nx = 4, ny = 3) plot(X) plot(Q, add = TRUE, cex = 2)
以上是关于空间点过程分析的R语言实现+PART1(1~4.6)的主要内容,如果未能解决你的问题,请参考以下文章