R语言机器学习 | 4 线性判别分析 (LDA)
Posted PsychRun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言机器学习 | 4 线性判别分析 (LDA)相关的知识,希望对你有一定的参考价值。
线性判别分析(linear discriminant analysis, LDA)是一种经典的线性学习方法,也叫作Fisher判别法。
LDA的核心思想是将高维数据投影到较低维空间中。以二分类问题为例,给定一个训练集,将样本点投影到一条直线上,使得类内样本的投影点尽可能接近,不同类样例的投影点尽可能相互远离。换句话说,就是“投影后类内方差最小,类间方差最大”,然后在低维空间进行分类。由于LDA是将数据向低维空间进行投影,因此LDA本身具有降维的属性。下面是LDA分类思想的示意图,其坐标横轴和纵轴代表的是X1和X2两个特征。
线性判别法示意图
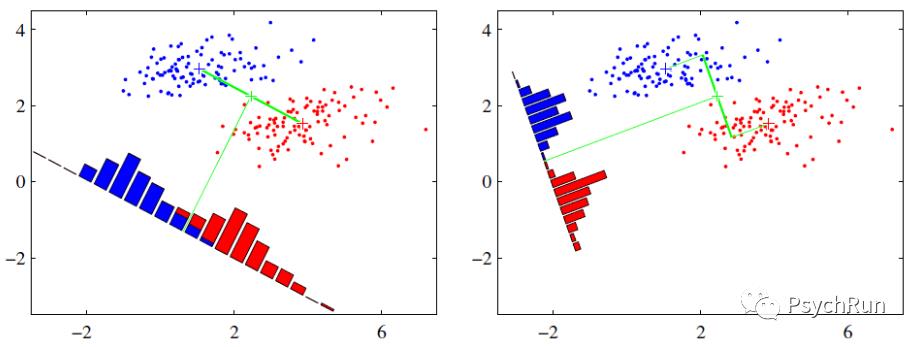
要使红色和蓝色数据中心之间的距离尽可能的大,而每一种类别数据的投影点尽可能接近。因此右图比左图的投影效果更好。
上面是一个通用的介绍,下面举一个更加清楚的例子来说明LDA的投影思想(参考自: https://www.youtube.com/watch?v=azXCzI57Yfc)。该数据集的背景是:使用人体两个基因的表达程度来判断某种药对人是否有效,有两个特征:Gene X 和 Gene Y,标签是二分类的有效(绿)和无效(红)。我们要将该二维数据投影到一条直线上,使其更好地在一维空间(直线)上进行区分:
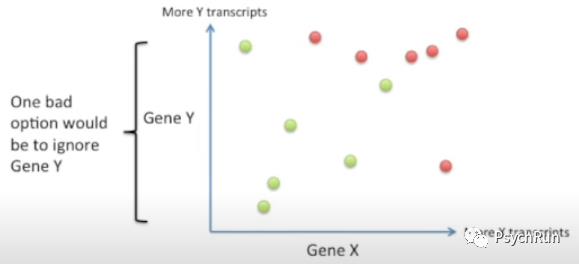
基因和药效数据集示意图
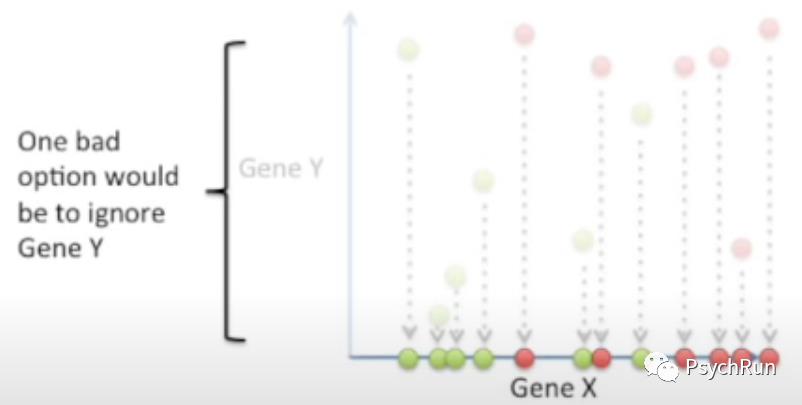
一个不好的投影示范:投影到x轴,相当于只利用单个特征的信息
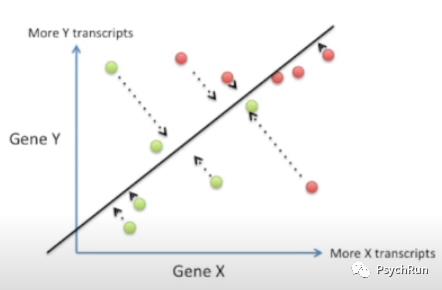
LDA: 使样本点投影在最佳的直线上,满足投影后类内方差最小,类间方差最大
可以看到,LDA使用了所有特征的信息,建立了一个新的坐标轴(即那根直线),将数据投影到新的坐标轴后,就可以进行最佳的分类!
上面讲的是二分类,而多分类的思想也很相似。以三分类为例,首先要找到所有数据的中心点(如下图),然后使得每一类数据的类内中心点与总中心点距离最远(类间方差最大),与类内样本距离最近(类内方差最小),之后,需要将数据投影到确定两条新的轴来将数据分开。
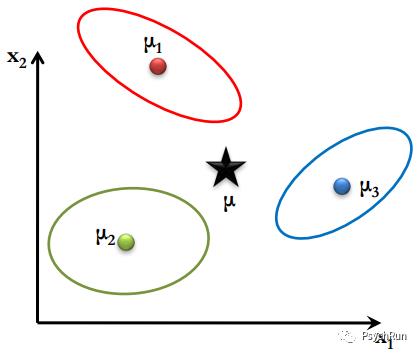
整个样本的中心点(黑)和三类样本的类内中心点(红、绿、蓝)
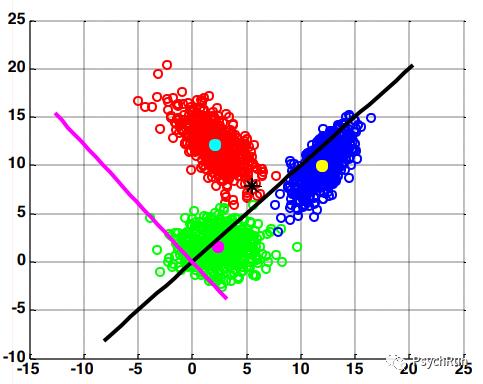
三分类LDA利用两条新的坐标轴将数据区分开
以上就是线性判别法LDA的主要思想,之后就是通过数学计算把直线求出来。具体的计算这里就不具体叙述了(实在看了也不会)。
2 LDA的R实现
初识交叉验证——留出法
这一节开始慢慢地介绍交叉验证!交叉验证通常有三种方法:留出法(Hold out)、留一法(LOOCV)和K-fold交叉验证。这里先介绍最简单的一种交叉验证方法(简单到都没交叉),即留出法。
顾名思义,留出法就是不把所有数据都用来训练建模,而是留出一部分数据(少于1/3)作为测试,如将70%的数据作为训练集,30%作为测试集。留出法的思想是用训练集的数据来训练模型,然后用测试集的数据来用该模型进行预测,从而评价模型的表现。
留出法示意图
使用经典的分类数据集鸢尾花(iris)作为示例数据(N=150),该数据集有4个特征:花萼长度(sepal.length)、花萼宽度(sepal.width)、花瓣长度(petal.length)、花瓣宽度(petal.width),目的是用这些特征来对三个品种的鸢尾花(Y)进行分类。

使用留出法,按照70-30比例将该数据集划分为训练集和测试集:
set.seed(100) #设置种子,使每次抽样固定,便于可重复index <- sample(nrow(iris),0.7*nrow(iris)) #在总样本中抽取70%的样本,将其打上标记,便于之后分组。train <- iris[index,] #把带标记的70%数据作为训练组test <- iris[-index,] #把不带标记的30%数据作为验证组
LDA的R实现
接下来进行LDA,使用MASS包中的lda()函数,使用方法和线性回归类似lda(Y~X1+X2...)。使用训练集的数据求出LDA模型之后,利用测试集对来评估模型表现,此时使用predict(model,newdata)进行预测。之后,输出混淆矩阵以评估模型表现,混淆矩阵也可以用热图进行绘制(如pheatmap包)。
library(MASS)library(tidyverse)ld = lda(Species~.,data=train)ld#预测测试集z = predict(ld,newdata = test)(CM = table(test$Species,z$class)) #混淆矩阵CM.z$class是预测的分类结果(Accuracy = sum(diag(CM))/sum(CM)) #模型预测准确率 = 对角线个数(预测正确的个数)/总个数#利用热图来画混淆矩阵pheatmap::pheatmap(CM,color = colorRampPalette(c("navy", "white", "firebrick3"))(50),cluster_rows = F,cluster_cols = F)
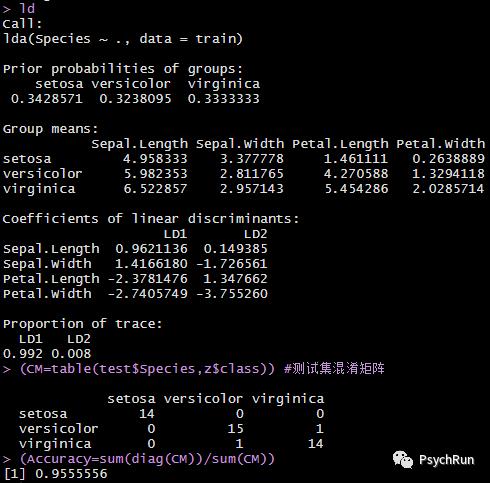
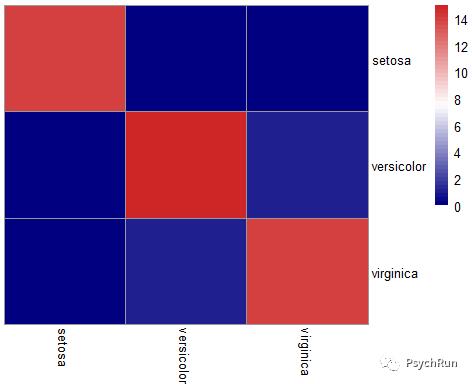
看到LDA模型输出了三种类别的先验概率、组均值、两条新的坐标轴系数LD1/LD2等。 从混淆矩阵可以看出,LDA分类器的分类效果很不错,正确率能达到95.6%!
下面画图看看,以新的两条轴(LD1/LD2)为坐标轴之后的分类情况:
#以ld1/ld2为坐标轴的可视化(特征空间)iris.LD = z$x # z$x是ld1/ld2值ggplot(data.frame(iris.LD),aes(x=LD1,y=LD2))+geom_point(aes(col=test$Species))
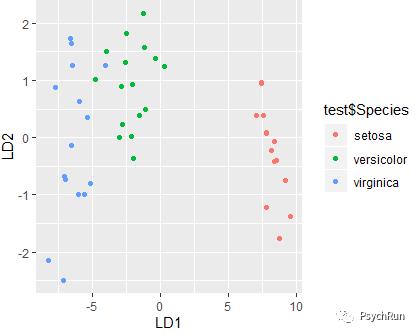
可以看到新的坐标轴下,三类鸢尾花被较好的区分开来了。
之后,我看了一下JASP的LDA实现,发现JASP输出的除了散点图还有密度图,借助这张图,可以更清晰地说明样本点在两条新坐标轴上的投影情况。
LDA就到这里,最后,由于做法类似,简单看一下二次判别分析(QDA)的实现。QDA的划分边界可以是抛物线,因此也就更为灵活。利用qda()这一函数即可进行二次判别分析,做法与lda没有什么区别。可以看到QDA的效果也不错,准确率为97.78%。
ld3 = qda(Species~.,data=train)pre.qd = predict(ld3,newdata = test)table(test$Species,pre.qd$class)#混淆矩阵
LDA的内容到这,由于判别分析的内容较多,故分几次学习。预计下一次学习距离判别法,包括马氏距离和K-最邻近法(KNN)。
注:部分图片来源于网络,侵删。
以上是关于R语言机器学习 | 4 线性判别分析 (LDA)的主要内容,如果未能解决你的问题,请参考以下文章