详细步骤:用R语言做文本挖掘
Posted 大数据挖掘DT数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详细步骤:用R语言做文本挖掘相关的知识,希望对你有一定的参考价值。
机器学习资料,点击底部"阅读原文",手慢无
目录
Part1 安装依赖包
Part2 分词处理
Part3文本聚类
Part4 文本分类
Part5情感分析
Part1 安装依赖包
R语言中中文分析的软件包是Rwordseg,Rwordseg软件包依赖rJava包,rJava需要本机中有安装Java。
Part2 分词处理
在RStudio中安装完相关软件包之后,才能做相关分词处理,请参照Part1部分安装需要软件包。
1. RWordseg功能
分词
> segmentCN(c("如果你因为错过太阳而流泪", "你也会错过星星"))
[[1]]
[1] "如果""你" "因为" "错" "过" "太阳" "而"
[8] "流泪"
[[2]]
[1] "你" "也" "会" "错" "过" "星星"
可以看到分词的效果不是很理想,“错过”这是一个词却被分开了,说明词库中不存在这个词,所以,我们有时候需要向词库中添加我们需要的词语。
加词删词
> insertWords("错过")
> segmentCN(c("如果你因为错过太阳而流泪", "你也会错过星星"))
[[1]]
[1] "如果""你" "因为" "错过" "太阳" "而" "流泪"
[[2]]
[1] "你" "也" "会" "错过" "星星"
有些情况下,你不希望某个词被分出来,例如还是“错过”这个词,这里“错”和“过”语义上已经不应该是一个词语了,所以,可以从词典中删除这个词,再添加上你需要的词语,继续做分词,效果就好多了。
> segmentCN("这个错过去你可以犯,但是现在再犯就不应该了")
[1] "这个" "错过" "去" "你" "可以" "犯" "但是"
[8] "现在" "再" "犯" "就" "不" "应该" "了"
>deleteWords("错过")
> insertWords("过去")
> segmentCN("这个错过去你可以犯,但是现在再犯就不应该了")
[1] "这个" "错" "过去" "你" "可以" "犯" "但是"
[8] "现在" "再" "犯" "就" "不" "应该" "了"
安装卸载词典
> segmentCN("2015年的几部开年戏都出现了唐嫣的身影")
[1] "2015年" "的" "几部" "开" "年"
[6] "戏" "都" "出现" "了" "唐"
[11] "嫣" "的" "身影"
>installDict("D:\R\sources\Dictionaries\singers.scel", dictname ="names")
3732 words were loaded! ... New dictionary 'names' was installed!
>segmentCN("2015年的几部开年戏都出现了唐嫣的身影")
[1] "2015年" "的" "几部" "开" "年"
[6] "戏" "都" "出现" "了" "唐嫣"
[11] "的" "身影"
>listDict()
Name Type Des
1 names 明星官方推荐,词库来源于网友上传
Path
1 E:/programFiles/R/R-3.1.2/library/Rwordseg/dict/names.dic
在不需要自己添加的词典时,还可以删除。
> uninstallDict()
3732 words were removed! ... The dictionary 'names' wasuninstalled!
>listDict()
[1] Name Type Des Path
<0 行>(或0-长度的row.names)
以上这些是基本的介绍,RWordseg还有更多的功能,请查看其中文文档。
2. 对某品牌官微做分词
数据来源是某服装品牌的官方微博从2012年到2014年末的微博。数据的基本内容结构如下图示,看内容大概能猜出来是哪个品牌了吧。

> installDict("D:\R\sources\Dictionaries\fushi.scel",dictname = "fushi")
> installDict("D:\R\sources\Dictionaries\Ali_fushi.scel",dictname = "alifushi")
> listDict()
Name Type
1 names 明星
2 pangu Text
3 fushi 服饰
4 ali 服饰
下一步是将数据读入R中,可以看到一共有1640条微博数据,注意数据的编码格式,readLines默认读取格式是gbk格式的,读取格式不对时会乱码。
>hlzj <-readLines("d:\R\RWorkspace\orgData.txt",encoding ="UTF-8")
>length(hlzj)
[1] 1640
接下来就是做分词了,要先去除数据中可能存在的数字和一些特殊符号,然后分词。
>hlzjTemp <- gsub("[0-90123456789 < > ~]","",hlzj)
> hlzjTemp <- segmentCN(hlzjTemp)
> hlzjTemp[1:2]
[[1]]
[1] "新品" "推荐" "时尚" "迷彩" "面料" "设计"
[7] "为" "简约" "的" "单" "西" "注入"
[13] "非同凡响""的" "野性" "魅力" "良好" "的"
[19] "防水" "效果" "使得" "实用" "性" "更"
[25] "高" "极" "具" "春日" "吸" "睛"
[31] "亮点" "春季" "新品" "海澜之家" "男士" "休闲"
[37] "西服" "韩版" "迷彩" "西装" "外套" "HWXAJAA"
[[2]]
[1] "小编" "推荐" "修身" "薄款" "连帽" "暖心"
[7] "设计" "防风" "保暖" "撞色" "线条" "设计"
[13] "年轻" "时尚" "走亲访友" "休闲" "出行" "的"
[19] "时尚" "选择" "活力" "过冬" "保暖" "轻松"
[25] "冬季" "热卖" "海澜之家" "正品" "男士" "保暖"
[31] "连帽" "羽绒服" "外套" "HWRAJGA"
可以看到微博内容都已经被做过分词处理了,这个过程很简单,但实际上可能需要多次查看分词处理结果,有些词库中不存在所以被截开了的词需要被添加进去,从而让分词效果达到最好。
3. 去停词
分词已经有结果了,但是分词的结果中存在很多像,“吧”,“吗”,“的”,“呢”这些无实际含义的语气词,或者是“即使”,“但是”这样的转折词,或者是一些符号,这样的词就叫做停词。要做进一步的分析可能需要去掉这些停词。
先自己整理一个停词表,这个停词表是我自己找的,包含一些常见的停词,然后根据实际内容中出现的一些无实际分析意义的词语,就可以作为我们的停词表了,网上能找到别人已经整理好的停词表。
>stopwords<- unlist(read.table("D:\R\RWorkspace\StopWords.txt",stringsAsFactors=F))
> stopwords[50:100]
V150 V151 V152 V153 V154 V155 V156
"哎哟" "唉" "俺" "俺们" "按" "按照" "吧"
V157 V158 V159 V160 V161 V162 V163
"吧哒" "把" "罢了" "被" "本" "本着" "比"
V164 V165 V166 V167 V168 V169 V170
"比方" "比如" "鄙人" "彼" "彼此" "边" "别"
V171 V172 V173 V174 V175 V176 V177
"别的" "别说" "并" "并且" "不比" "不成" "不单"
V178 V179 V180 V181 V182 V183 V184
"不但" "不独" "不管" "不光" "不过" "不仅" "不拘"
V185 V186 V187 V188 V189 V190 V191
"不论" "不怕" "不然" "不如" "不特" "不惟" "不问"
V192 V193 V194 V195 V196 V197 V198
"不只" "朝" "朝着" "趁" "趁着" "乘" "冲"
V199 V1100
"除""除此之外"
removeStopWords <- function(x,stopwords) {
temp <- character(0)
index <- 1
xLen <- length(x)
while (index <= xLen) {
if (length(stopwords[stopwords==x[index]]) <1)
temp<- c(temp,x[index])
index <- index +1
}
temp
}
> hlzjTemp2 <-lapply(hlzjTemp,removeStopWords,stopwords)
> hlzjTemp2[1:2]
[[1]]
[1] "新品" "推荐" "时尚" "迷彩" "面料" "设计"
[7] "简约" "单" "西" "注入" "非同凡响" "野性"
[13] "魅力" "防水" "效果" "实用" "性" "高"
[19] "极" "具" "春日" "吸" "睛" "亮点"
[25] "春季" "新品" "海澜之家" "男士" "休闲" "西服"
[31] "韩版" "迷彩" "西装" "外套" "HWXAJAA"
[[2]]
[1] "小编" "推荐" "修身" "薄款" "连帽" "暖心"
[7] "设计" "防风" "保暖" "撞色" "线条" "设计"
[13] "年轻" "时尚" "走亲访友" "休闲" "出行" "时尚"
[19] "选择" "活力" "过冬" "保暖" "轻松" "冬季"
[25] "热卖" "海澜之家" "正品" "男士" "保暖" "连帽"
[31] "羽绒服" "外套" "HWRAJGA"
跟hlzjTemp[1:2]的内容比较可以明显发现“的”这样的字都被去掉了。
4. 词云
词云是现在很常见的一种分析图,把这些词语放在一张图中,频次来显示词语的大小,这样就能很直观看出那些词语出现得比较多,在舆情分析中经常被用到。
下面的过程是将分词结果做一个统计,计算出每个词出现的次数并排序,然后取排名在前150的150个词语,用wordcloud()方法来画词云。
> words <- lapply(hlzjTemp2,strsplit," ")
> wordsNum <- table(unlist(words))
> wordsNum <- sort(wordsNum) #排序
> wordsData <- data.frame(words =names(wordsNum), freq = wordsNum)
> library(wordcloud) #加载画词云的包
> weibo.top150 <- tail(wordsData,150) #取前150个词
>colors=brewer.pal(8,"Dark2")
>wordcloud(weibo.top150$words,weibo.top150$freq,scale=c(8,0.5),colors=colors,random.order=F)

该品牌微博的内容有很明显的特征,品牌名“海澜之家”出现的次数远大于其他词语;其次出现频度比较高的词语是“链接”,“旗舰店”,“时尚”,“新品”,“修身”,“男装”,可以大概看出这个该品牌专注于男装,该微博账号经常做新品推荐,可能会提供服装链接到它的旗舰店;另外还能看到“全能星战”,“奔跑吧兄弟”这样的电视节目,稍微了解一下就知道,这是海澜之家这两年赞助的两个节目,所以在它的微博中出现多次是很正常的。
Part3文本聚类
分类和聚类算法,都是数据挖掘中最常接触到的算法,分类聚类算法分别有很多种。可以看下下面两篇文章对常见的分类聚类算法的简介:
分类算法:http://blog.csdn.net/chl033/article/details/5204220
聚类算法:http://blog.chinaunix.net/uid-10289334-id-3758310.html
文本分类聚类会要用到这些算法去实现,暂时不用深究算法细节,R中已经有成熟的可以直接调用的这些算法了。大概说下分类和聚类的差异,照我的理解,分类算法和聚类算法最后实现的效果是相同的,都是给一个集合划分成几个类别。不同的是分类算法是根据已知的确定类别去做划分,所以分类需要训练集,有训练、测试、预测这个过程;而聚类则未规定类别,它是基于给定集合的里面的内容,根据内容的相似度去给集合划分成指定的几个类(你可以指定划分成多少个类,而不是指定有哪些类),这些相似度的测量就是聚类算法的核心,这个度量标准可以是欧几里得距离、是曼哈顿距离、是切比雪夫距离等等。它们分别叫做有监督分类和无监督分类。
还是用Part2里面的例子。做聚类不需要训练集,将文本内容做完分词处理,也就是Part2里面2.对某品牌官微做分词,这里处理完得到的结果hlzjTemp,用这个做接下来的聚类工作。下图(图片来源:玩玩文本挖掘)是一个文本挖掘的过程,不管是分类还是聚类,都要经历前面一个过程将文本转为为Tem-Document Matrix。然后再做后续分析Analysis,及分类或者聚类。另一个参考:R语言进行中文分词和聚类

聚类算法是针对数值型变量的,先要将文本数据转换为matrix—数据矩阵。过程如下,这里需要用到tm软件包,先安装该软件包并加载。tm包中的Corpus()方法就是用来将文本转换为语料库的方法。DocumentTermMatrix()方法,显然就是将语料库转换为文档-词条矩阵,然后再将文档-词条矩阵转换为普通矩阵,过程如下:
>library(tm)
载入需要的程辑包:NLP
>corpus <-Corpus(VectorSource(hlzjTemp))
> hlzj.dtm<- DocumentTermMatrix(corpus,control=list(wordLengths=c(1,Inf)))
>hlzj.matrix <- as.matrix(hlzj.dtm)
补充说明:这个过程可能会遇到很多问题,没有详细的说明,附上两个参考:用tm进行文本挖掘、R语言文本挖掘。
接下来就是做聚类了,聚类算法有很多,常见的几种做聚类的方法
1. kmeans()
方法的介绍参考:http://blog.sina.com.cn/s/blog_4ac9f56e0101h8xp.html。运行结果kmeansRes是一个list,names方法可以查看到kmeansRes的所有维度或者说组件,其中第一个cluster就是对应的分类结果,我们可以查看到前三十个聚类的结果,第一排对应着行号,第二排对应着聚类的结果1-5分别代表1-5类。然后我们可以将原始微博和聚类结果赋值给一个新的list变量,这样我们就能看到聚类结果和每条微博对应的关系了。最后将这个新的list变量hlzj.kmeansRes导出到本地,就能很方便地查看到聚类结果了。当然我们也可以通过fix()方法查看hlzj.kmeansRes的内容,如图所示,content是原微博内容,type是聚类结果。每个类别对应的文本数据的特点就要靠我们自己来总结了,这是聚类的一个不足的地方。
> k <- 5
> kmeansRes <- kmeans(hlzj.matrix,k) #k是聚类数
> mode(kmeansRes)#kmeansRes的内容
[1]"list"
> names(kmeansRes)
[1]"cluster" "centers" "totss" "withinss"
[5]"tot.withinss" "betweenss" "size" "iter"
[9]"ifault"
> head(kmeansRes$cluster,10)
1 2 3 4 5 6 7 8 9 10
1 1 1 2 1 5 2 1 1 5
> kmeansRes$size #每个类别下有多少条数据
[1] 327 1159 63 63 27
>hlzj.kmeansRes <- list(content=hlzj,type=kmeansRes$cluster)
> write.csv(hlzj.kmeansRes,"hlzj_kmeansRes.csv")
> fix(hlzj.kmeansRes)
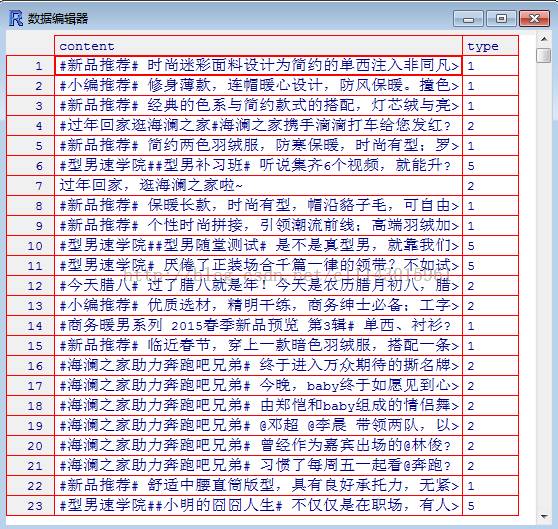
2. hclust()。
方法详细介绍,过程不再细说http://blog.sina.com.cn/s/blog_615770bd01018dnj.html,这个方法可以用plot()来查看聚类结果图,但是在数据量挺多的时候,图的上面的内容都挤在一起看不清楚了,这种情况下,还是直接查看聚类结果比较好。同样,将原始数据hlzj和分类结果放在一起hlzj.hclustRes来看。可以看出类跟kmeans的聚类结果有些接近,说明微博的特征还是挺明显的。
> d <- dist(hlzj.matrix,method="euclidean")
> hclustRes <- hclust(d,method="complete")
> hclustRes.type <- cutree(hclustRes,k=5) #按聚类结果分5个类别
> length(hclustRes.type)
[1] 1639
> hclustRes.type[1:10]
1 2 3 4 5 6 7 8 9 10
1 1 1 2 1 2 3 1 1 2
> hlzj.hclustRes <- list(content=hlzj,type=hclustRes.type)
> hlzj.hclustRes <- as.data.frame(hlzj.hclustRes)
>fix(hlzj.hclustRes)
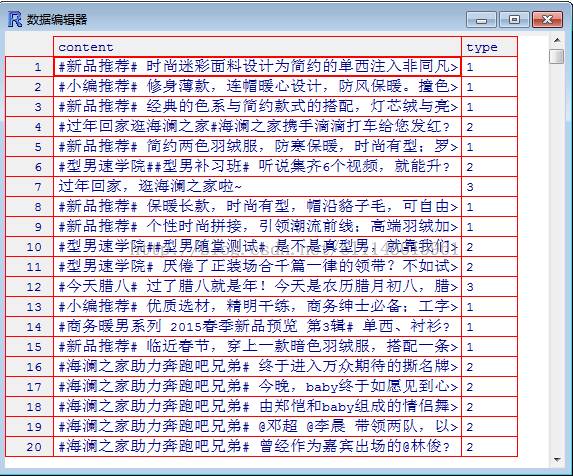
3. kernel聚类,方法specc()
> stringkern <-stringdot(type="string")
> kernelRes <-specc(hlzj.matrix,centers=5,kernel=stringkern)
> mode(kernelRes)
[1] "numeric"
> length(kernelRes)
[1] 1639
> kernelRes[1:10]
1 2 3 4 5 6 7 8 9 10
4 4 4 4 4 4 4 4 4 4
> table(kernelRes)
kernelRes
1 2 3 4 5
135 55 24 1402 23
>temp <-t(kernelRes) #行列转换
> hlzj.kernelRes<-list(cotent=hlzj,type=temp[1:1639]
> hlzj.kernelRes <-as.data.frame(hlzj.kernelRes)
> fix(hlzj. kernelRes)
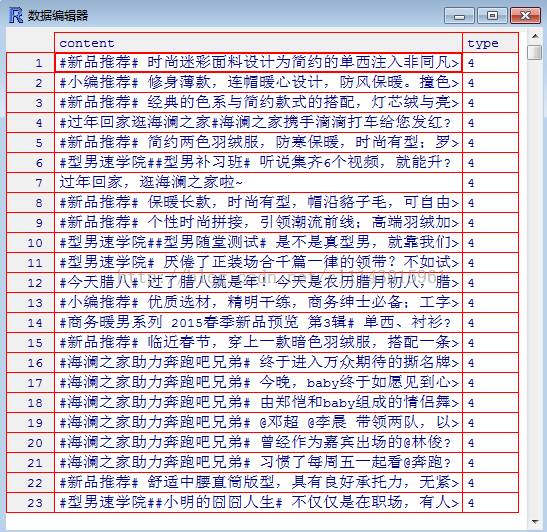
4. 除此之外
fpc软件包中的dbscan()方法可以实现dbscan聚类,还有其他的聚类方法,就不一一介绍了,优劣取舍要在实际应用中去控制了。
Part4 文本分类
Part3文本聚类里讲到过,分类跟聚类的简单差异。所以要做分类我们需要先整理出一个训练集,也就是已经有明确分类的文本;测试集,可以就用训练集来替代;预测集,就是未分类的文本,是分类方法最后的应用实现。
1. 数据准备
训练集准备是一个很繁琐的功能,暂时没发现什么省力的办法,根据文本内容去手动整理。这里还是使用的某品牌的官微数据,根据微博内容,我将它微博的主要内容分为了:促销资讯(promotion)、产品推介(product)、公益信息(publicWelfare)、生活鸡汤(life)、时尚资讯(fashionNews)、影视娱乐(showbiz),每个分类有20-50条数据,如下可看到训练集下每个分类的文本数目,训练集分类名为中文也没问题。
训练集为hlzj.train,后面也会被用作测试集。
预测集就是Part2里面的hlzj。
> hlzj.train <-read.csv("hlzj_train.csv",header=T,stringsAsFactors=F)
> length(hlzj.train)
[1] 2
> table(hlzj.train$type)
fashionNews life product
27 34 38
promotion publicWelfare showbiz
45 22 36
> length(hlzj)
[1] 1639
2. 分词处理
训练集、测试集、预测集都需要做分词处理后才能进行后续的分类过程。这里不再详细说明,过程类似于Part2中讲到的。训练集做完分词后hlzjTrainTemp,之前对hlzj文件做过分词处理后是hlzjTemp。然后分别将hlzjTrainTemp和hlzjTemp去除停词。
> library(Rwordseg)
载入需要的程辑包:rJava
# Version: 0.2-1
> hlzjTrainTemp <- gsub("[0-90123456789 < > ~]","",hlzj.train$text)
> hlzjTrainTemp <-segmentCN(hlzjTrainTemp)
> hlzjTrainTemp2 <-lapply(hlzjTrainTemp,removeStopWords,stopwords)
>hlzjTemp2 <-lapply(hlzjTemp,removeStopWords,stopwords)
3. 得到矩阵
在Part3中讲到了,做聚类时要先将文本转换为矩阵,做分类同样需要这个过程,用到tm软件包。先将训练集和预测集去除停词后的结果合并为hlzjAll,记住前202(1:202)条数据是训练集,后1639(203:1841)条是预测集。获取hlzjAll的语料库,并且得到文档-词条矩阵,将其转换为普通矩阵。
> hlzjAll <- character(0)
> hlzjAll[1:202] <- hlzjTrainTemp2
> hlzjAll[203:1841] <- hlzjTemp2
> length(hlzjAll)
[1] 1841
> corpusAll <-Corpus(VectorSource(hlzjAll))
> (hlzjAll.dtm <-DocumentTermMatrix(corpusAll,control=list(wordLengths = c(2,Inf))))
<<DocumentTermMatrix(documents: 1841, terms: 10973)>>
Non-/sparse entries: 33663/20167630
Sparsity : 100%
Maximal term length: 47
Weighting : term frequency (tf)
> dtmAll_matrix <-as.matrix(hlzjAll.dtm)
4. 分类
用到knn算法(K近邻算法),这个算法在class软件包里。矩阵的前202行数据是训练集,已经有分类了,后面的1639条数据没有分类,要根据训练集得到分类模型再为其做分类的预测。将分类后的结果和原微博放在一起,用fix()查看,可以看到分类结果,效果还是挺明显的。
> rownames(dtmAll_matrix)[1:202] <-hlzj.train$type
> rownames(dtmAll_matrix)[203:1841]<- c("")
> train <- dtmAll_matrix[1:202,]
> predict <-dtmAll_matrix[203:1841,]
> trainClass <-as.factor(rownames(train))
> library(class)
> hlzj_knnClassify <-knn(train,predict,trainClass)
> length(hlzj_knnClassify)
[1] 1639
> hlzj_knnClassify[1:10]
[1] product product product promotion product fashionNews life
[8] product product fashionNews
Levels: fashionNews life productpromotion publicWelfare showbiz
> table(hlzj_knnClassify)
hlzj_knnClassify
fashionNews life product promotion publicWelfare showbiz
40 869 88 535 28 79
> hlzj.knnResult <-list(type=hlzj_knnClassify,text=hlzj)
> hlzj.knnResult <-as.data.frame(hlzj.knnResult)
> fix(hlzj.knnResult)
Knn分类算法算是最简单的一种,后面尝试使用神经网络算法(nnet())、支持向量机算法(svm())、随机森林算法(randomForest())时,都出现了电脑内存不够的问题,我的电脑是4G的,看内存监控时能看到最高使用达到3.92G。看样子要换台给力点的电脑了╮(╯▽╰)╭
在硬件条件能达到时,应该实现分类没有问题。相关的算法可以用:??方法名,的方式来查看其说明文档。
5. 分类效果
上面没有讲到测试的过程,对上面的例子来说,就是knn前两个参数都用train,因为使用数据集相同,所以得到的结果也是正确率能达到100%。在训练集比较多的情况下,可以将其随机按7:3或者是8:2分配成两部分,前者做训练后者做测试就好。
在分类效果不理想的情况下,改进分类效果需要丰富训练集,让训练集特征尽量明显,这个在实际问题是一个很繁琐却不能敷衍的过程。
以上是关于详细步骤:用R语言做文本挖掘的主要内容,如果未能解决你的问题,请参考以下文章