逻辑回归基础梳理
Posted sugar-chl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了逻辑回归基础梳理相关的知识,希望对你有一定的参考价值。
1.逻辑回归
逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏。
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)
回归模型中,y是一个定性变量,比如y=0或1,logistic方法主要应用于研究某些事件发生的概率
2.预测函数
在逻辑回归中,我们一般取用Sigmoid函数,函数形式为:
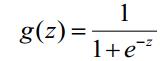
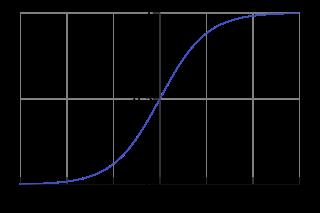
对于线性边界的情况,边界形式如下: 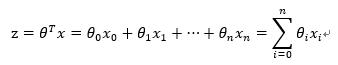
其中,训练数据为向量 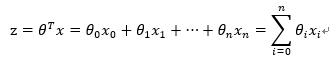
最佳参数 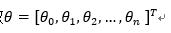
构造预测函数为: 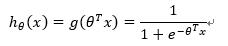
3.损失函数
- 假设sigmoid函数φ(z)表示属于1类的概率,于是做出如下的定义:

两个式子综合来,可以改写为下式

上式将分类为0和分类和1的概率计算公式合二为一。假设分类器分类足够准确,此时对于一个样本,如果它是属于1类,分类器求出的属于1类的概率应该尽可能大,即p(y=1lx)尽可能接近1;如果它是0类,分类器求出的属于0类的概率应该尽可能大,即p(y=0lx)尽可能接近1。
通过上述公式对二类分类的情况分析,可知我们的目的是求取参数w和b,使得p(ylx)对0类和1类的分类结果尽可能取最大值,然而实际上我们定义的损失函数的是求最小值,于是,很自然的,我们想到对p(ylx)式子加一个负号,就变成了求最小值的问题,这就得到了逻辑回归中的损失函数。
不过,为了计算方便,我们通常对上述式子取log,因而得到下式:
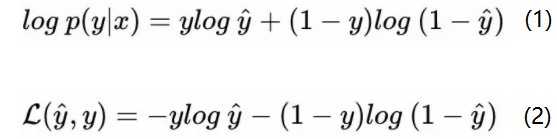
- 根据损失函数是单个样本的预测值和实际值的误差,而成本函数是全部样本的预测值和实际值之间的误差,于是对所有样本的损失值取平均数,得到我们的成本函数:

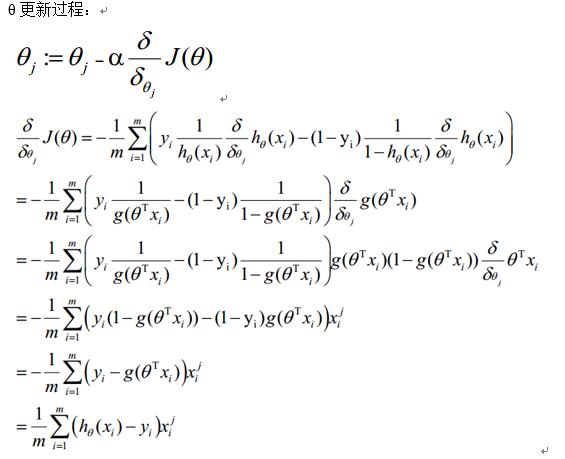
θ更新过程可以写成: 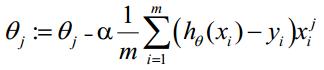
4.正则化

5.模型评估
(1)真正类(True Positive , TP):被模型预测为正类的正样本
(2)假正类(False Positive , FP):被模型预测为正类的负样本
(3)假负类(False Negative , FN):被模型预测为负类的正样本
(4)真负类(True Negative , TN):被模型预测为负类的负样本
(1)真正类率(True Positive Rate , TPR)【灵敏度(sensitivity)】:TPR = TP /(TP + FN) ,即正样本预测结果数/正样本实际数
(2)假负类率(False Negative Rate , FNR) :FNR = FN /(TP + FN) ,即被预测为负的正样本结果数/正样本实际数
(3)假正类率(False Positive Rate , FPR) :FPR = FP /(FP + TN) ,即被预测为正的负样本结果数/负样本实际数
(4)真负类率(True Negative Rate , TNR)【特指度(specificity)】:TNR = TN /(TN + FP) ,即负样本预测结果数/负样本实际数
准确率=正确预测正负的个数/总个数(这个指标在python中的交叉验证时可以求准确率)
覆盖率(也叫作召回率)=正确预测正的个数/实际正的个数 (当然也可以是负覆盖率)
命中率=正确预测正的个数/预测正的个数
6.类别不平衡问题
类别数据不均衡是分类任务中一个典型的存在的问题。简而言之,即数据集中,每个类别下的样本数目相差很大。例如,在一个二分类问题中,共有100个样本(100行数据,每一行数据为一个样本的表征),其中80个样本属于class 1,其余的20个样本属于class 2,class 1:class2=80:20=4:1,这便属于类别不均衡。当然,类别不均衡问同样会发生在多分类任务中。
解决方法
1.扩大数据集
当遇到类别不均衡问题时,首先应该想到,是否可能再增加数据(一定要有小类样本数据),更多的数据往往战胜更好的算法。因为机器学习是使用现有的数据多整个数据的分布进行估计,因此更多的数据往往能够得到更多的分布信息,以及更好分布估计。即使再增加小类样本数据时,又增加了大类样本数据,也可以使用放弃一部分大类数据(即对大类数据进行欠采样)来解决。
2.对数据集进行重采样
可以使用一些策略该减轻数据的不平衡程度。该策略便是采样(sampling),主要有两种采样方法来降低数据的不平衡性。
对小类的数据样本进行采样来增加小类的数据样本个数,即过采样(over-sampling ,采样的个数大于该类样本的个数)。
对大类的数据样本进行采样来减少该类数据样本的个数,即欠采样(under-sampling,采样的次数少于该类样本的个素)。
??一些经验法则:
考虑对大类下的样本(超过1万、十万甚至更多)进行欠采样,即删除部分样本;
考虑对小类下的样本(不足1为甚至更少)进行过采样,即添加部分样本的副本;
考虑尝试随机采样与非随机采样两种采样方法;
考虑对各类别尝试不同的采样比例,比一定是1:1,有时候1:1反而不好,因为与现实情况相差甚远;
考虑同时使用过采样与欠采样。
3.尝试对模型进行惩罚
??你可以使用相同的分类算法,但是使用一个不同的角度,比如你的分类任务是识别那些小类,那么可以对分类器的小类样本数据增加权值,降低大类样本的权值(这种方法其实是产生了新的数据分布,即产生了新的数据集,译者注),从而使得分类器将重点集中在小类样本身上。一个具体做法就是,在训练分类器时,若分类器将小类样本分错时额外增加分类器一个小类样本分错代价,这个额外的代价可以使得分类器更加“关心”小类样本。
4.尝试不同的分类算法
??强烈建议不要对待每一个分类都使用自己喜欢而熟悉的分类算法。应该使用不同的算法对其进行比较,因为不同的算法使用于不同的任务与数据
7.sklearn参数
sklearn.linear_model.LogisticRegression(penalty=l2, # 惩罚项,可选l1,l2,对参数约束,减少过拟合风险 dual=False, # 对偶方法(原始问题和对偶问题),用于求解线性多核(liblinear)的L2的惩罚项上。样本数大于特征数时设置False tol=0.0001, # 迭代停止的条件,小于等于这个值停止迭代,损失迭代到的最小值。 C=1.0, # 正则化系数λ的倒数,越小表示越强的正则化。 fit_intercept=True, # 是否存在截距值,即b intercept_scaling=1, # class_weight=None, # 类别的权重,样本类别不平衡时使用,设置balanced会自动调整权重。为了平横样本类别比例,类别样本多的,权重低,类别样本少的,权重高。 random_state=None, # 随机种子 solver=’liblinear’, # 优化算法的参数,包括newton-cg,lbfgs,liblinear,sag,saga,对损失的优化的方法 max_iter=100,# 最大迭代次数, multi_class=’ovr’,# 多分类方式,有‘ovr‘,‘mvm‘ verbose=0, # 输出日志,设置为1,会输出训练过程的一些结果 warm_start=False, # 热启动参数,如果设置为True,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化) n_jobs=1 # 并行数,设置为1,用1个cpu运行,设置-1,用你电脑的所有cpu运行程序 )
class sklearn.linear_model.LogisticRegression(penalty=’l2’, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=’liblinear’, max_iter=100, multi_class=’ovr’, verbose=0, warm_start=False, n_jobs=1)
参数:
=> penalty : str, ‘l1’ or ‘l2’
LogisticRegression和LogisticRegressionCV默认就带了正则化项。penalty参数可选择的值为"l1"和"l2",分别对应L1的正则化和L2的正则化,默认是L2的正则化。
在调参时如果我们主要的目的只是为了解决过拟合,一般penalty选择L2正则化就够了。但是如果选择L2正则化发现还是过拟合,即预测效果差的时候,就可以考虑L1正则化。
另外,如果模型的特征非常多,我们希望一些不重要的特征系数归零,从而让模型系数稀疏化的话,也可以使用L1正则化。
penalty参数的选择会影响我们损失函数优化算法的选择。即参数solver的选择,如果是L2正则化,那么4种可选的算法{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’}都可以选择。
但是如果penalty是L1正则化的话,就只能选择‘liblinear’了。这是因为L1正则化的损失函数不是连续可导的,而{‘newton-cg’, ‘lbfgs’,‘sag’}这三种优化算法时都需要损失函数的一阶或者二阶连续导数。而‘liblinear’并没有这个依赖。
=> dual : bool
对偶或者原始方法。Dual只适用于正则化相为l2 liblinear的情况,通常样本数大于特征数的情况下,默认为False
=> tol : float, optional
迭代终止判据的误差范围。
=> C : float, default: 1.0
C为正则化系数λ的倒数,通常默认为1。设置越小则对应越强的正则化。
=> fit_intercept : bool, default: True
是否存在截距,默认存在
=> intercept_scaling : float, default 1.
仅在正则化项为"liblinear",且fit_intercept设置为True时有用。
=> class_weight : dict or ‘balanced’, default: None
class_weight参数用于标示分类模型中各种类型的权重,可以不输入,即不考虑权重,或者说所有类型的权重一样。如果选择输入的话,可以选择balanced让类库自己计算类型权重,
或者我们自己输入各个类型的权重,比如对于0,1的二元模型,我们可以定义class_weight={0:0.9, 1:0.1},这样类型0的权重为90%,而类型1的权重为10%。
如果class_weight选择balanced,那么类库会根据训练样本量来计算权重。某种类型样本量越多,则权重越低;样本量越少,则权重越高。
当class_weight为balanced时,类权重计算方法如下:n_samples / (n_classes * np.bincount(y))
n_samples为样本数,n_classes为类别数量,np.bincount(y)会输出每个类的样本数,例如y=[1,0,0,1,1],则np.bincount(y)=[2,3] 0,1分别出现2次和三次
那么class_weight有什么作用呢?
在分类模型中,我们经常会遇到两类问题:
第一种是误分类的代价很高。比如对合法用户和非法用户进行分类,将非法用户分类为合法用户的代价很高,我们宁愿将合法用户分类为非法用户,这时可以人工再甄别,但是却不愿将非法用户分类为合法用户。这时,我们可以适当提高非法用户的权重。
第二种是样本是高度失衡的,比如我们有合法用户和非法用户的二元样本数据10000条,里面合法用户有9995条,非法用户只有5条,如果我们不考虑权重,则我们可以将所有的测试集都预测为合法用户,这样预测准确率理论上有99.95%,但是却没有任何意义。
这时,我们可以选择balanced,让类库自动提高非法用户样本的权重。
=> random_state : int, RandomState instance or None, optional, default: None
随机数种子,默认为无,仅在正则化优化算法为sag,liblinear时有用。
=> solver : {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}
solver参数决定了我们对逻辑回归损失函数的优化方法,有4种算法可以选择,分别是:
a) liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
b) lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
c) newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
d) sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候,SAG是一种线性收敛算法,这个速度远比SGD快。
从上面的描述可以看出,newton-cg, lbfgs和sag这三种优化算法时都需要损失函数的一阶或者二阶连续导数,因此不能用于没有连续导数的L1正则化,只能用于L2正则化。而liblinear则既可以用L1正则化也可以用L2正则化。
同时,sag每次仅仅使用了部分样本进行梯度迭代,所以当样本量少的时候不要选择它,而如果样本量非常大,比如大于10万,sag是第一选择。但是sag不能用于L1正则化,所以当你有大量的样本,又需要L1正则化的话就要自己做取舍了
=> max_iter : int, optional
仅在正则化优化算法为newton-cg, sag and lbfgs 才有用,算法收敛的最大迭代次数。
=> multi_class : str, {‘ovr’, ‘multinomial’}, default: ‘ovr’
OvR的思想很简单,无论你是多少元逻辑回归,我们都可以看做二元逻辑回归。具体做法是,对于第K类的分类决策,我们把所有第K类的样本作为正例,除了第K类样本以外的所有样本都作为负例,然后在上面做二元逻辑回归,得到第K类的分类模型。
其他类的分类模型获得以此类推。
而MvM则相对复杂,这里举MvM的特例one-vs-one(OvO)作讲解。如果模型有T类,我们每次在所有的T类样本里面选择两类样本出来,不妨记为T1类和T2类,把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,
得到模型参数。我们一共需要T(T-1)/2次分类。
可以看出OvR相对简单,但分类效果相对略差(这里指大多数样本分布情况,某些样本分布下OvR可能更好)。而MvM分类相对精确,但是分类速度没有OvR快。如果选择了ovr,则4种损失函数的优化方法liblinear,newton-cg,lbfgs和sag都可以选择。
但是如果选择了multinomial,则只能选择newton-cg, lbfgs和sag了。
=> verbose : int, default: 0
=> warm_start : bool, default: False
=> n_jobs : int, default: 1
如果multi_class =‘ovr‘“,并行数等于CPU内核数量。当“solver”设置为“liblinear”时,无论是否指定“multi_class”,该参数将被忽略。如果给定值-1,则使用所有内核。
参考:
https://www.cnblogs.com/MrFiona/p/7920587.html
https://blog.csdn.net/t46414704152abc/article/details/79574003
https://www.cnblogs.com/DjangoBlog/p/7903619.html
https://blog.csdn.net/chibangyuxun/article/details/53148005
以上是关于逻辑回归基础梳理的主要内容,如果未能解决你的问题,请参考以下文章