逻辑回归算法原理是啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了逻辑回归算法原理是啥?相关的知识,希望对你有一定的参考价值。
逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,测试验证这个求解的模型的好坏。
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)。回归模型中,y是一个定性变量,比如y=0或1,logistic方法主要应用于研究某些事件发生的概率。

Logistic回归模型的适用条件
1、因变量为二分类的分类变量或某事件的发生率,并且是数值型变量。但是需要注意,重复计数现象指标不适用于Logistic回归。
2、残差和因变量都要服从二项分布。二项分布对应的是分类变量,所以不是正态分布,进而不是用最小二乘法,而是最大似然法来解决方程估计和检验问题。
3、自变量和Logistic概率是线性关系。
以上内容参考:百度百科-logistic回归
参考技术A逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,测试验证我们这个求解的模型的好坏。
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)回归模型中,y是一个定性变量,比如y=0或1,logistic方法主要应用于研究某些事件发生的概率。
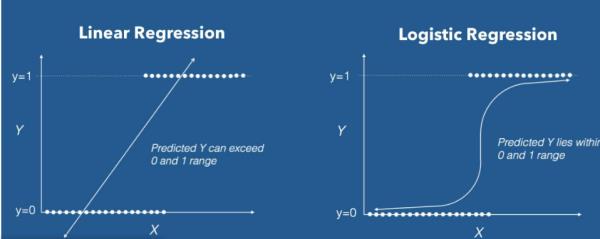
区别:
Logistic回归与多重线性回归实际上有很多相同之处,最大的区别就在于它们的因变量不同,其他的基本都差不多。
正是因为如此,这两种回归可以归于同一个家族,即广义线性模型。
这一家族中的模型形式基本上都差不多,不同的就是因变量不同。这一家族中的模型形式基本上都差不多,不同的就是因变量不同。
参考技术B线性回归要求因变量必须是连续性数据变量;逻辑回归要求因变量必须是分类变量,二分类或者多分类的;
比如要分析性别、年龄、身高、饮食习惯对于体重的影响,如果这个体重是属于实际的重量,是连续性的数据变量,这个时候就用线性回归来做;如果将体重分类,分成了高、中、低这三种体重类型作为因变量,则采用logistic回归。
线性回归的特征:
回归分析中有多个自变量:这里有一个原则问题,这些自变量的重要性,究竟谁是最重要,谁是比较重要,谁是不重要。所以,spss线性回归有一个和逐步判别分析的等价的设置。
原理:是F检验。spss中的操作是“分析”~“回归”~“线性”主对话框方法框中需先选定“逐步”方法~“选项”子对话框。
逻辑回归原理小结
逻辑回归是一个分类算法,它可以处理二元分类以及多元分类。虽然它名字里面有“回归”两个字,却不是一个回归算法。那为什么有“回归”这个误导性的词呢?个人认为,虽然逻辑回归是分类模型,但是它的原理里面却残留着回归模型的影子,本文对逻辑回归原理做一个总结。
1. 从线性回归到逻辑回归
我们知道,线性回归的模型是求出输出特征向量Y和输入样本矩阵X之间的线性关系系数\(\theta\),满足\(\mathbf{Y = X\theta}\)。此时我们的Y是连续的,所以是回归模型。如果我们想要Y是离散的话,怎么办呢?一个可以想到的办法是,我们对于这个Y再做一次函数转换,变为\(g(Y)\)。如果我们令\(g(Y)\)的值在某个实数区间的时候是类别A,在另一个实数区间的时候是类别B,以此类推,就得到了一个分类模型。如果结果的类别只有两种,那么就是一个二元分类模型了。逻辑回归的出发点就是从这来的。下面我们开始引入二元逻辑回归。
2. 二元逻辑回归的模型
上一节我们提到对线性回归的结果做一个在函数g上的转换,可以变化为逻辑回归。这个函数g在逻辑回归中我们一般取为sigmoid函数,形式如下:
\(g(z) = \frac{1}{1+e^{-z}}\)
它有一个非常好的性质,即当z趋于正无穷时,\(g(z)\)趋于1,而当z趋于负无穷时,\(g(z)\)趋于0,这非常适合于我们的分类概率模型。另外,它还有一个很好的导数性质:
\(g^{‘}(z) = g(z)(1-g(z))\)
这个通过函数对\(g(z)\)求导很容易得到,后面我们会用到这个式子。
如果我们令\(g(z)\)中的z为:\({z = x\theta}\),这样就得到了二元逻辑回归模型的一般形式:
\(h_{\theta}(x) = \frac{1}{1+e^{-x\theta}}\)
其中x为样本输入,\(h_{\theta}(x)\)为模型输出,可以理解为某一分类的概率大小。而\(\theta\)为分类模型的要求出的模型参数。对于模型输出\(h_{\theta}(x)\),我们让它和我们的二元样本输出y(假设为0和1)有这样的对应关系,如果\(h_{\theta}(x) >0.5\) ,即\(x\theta > 0\), 则y为1。如果\(h_{\theta}(x) < 0.5\),即\(x\theta < 0\), 则y为0。y=0.5是临界情况,此时\(x\theta = 0\)为, 从逻辑回归模型本身无法确定分类。
\(h_{\theta}(x)\)的值越小,而分类为0的的概率越高,反之,值越大的话分类为1的的概率越高。如果靠近临界点,则分类准确率会下降。
此处我们也可以将模型写成矩阵模式:
\(h_{\theta}(X) = \frac{1}{1+e^{-X\theta}}\)
其中\(h_{\theta}(X)\)为模型输出,为 mx1的维度。X为样本特征矩阵,为mxn的维度。\(\theta\)为分类的模型系数,为nx1的向量。
理解了二元分类回归的模型,接着我们就要看模型的损失函数了,我们的目标是极小化损失函数来得到对应的模型系数\(\theta\)。
3. 二元逻辑回归的损失函数
回顾下线性回归的损失函数,由于线性回归是连续的,所以可以使用模型误差的的平方和来定义损失函数。但是逻辑回归不是连续的,自然线性回归损失函数定义的经验就用不上了。不过我们可以用最大似然法来推导出我们的损失函数。
我们知道,按照第二节二元逻辑回归的定义,假设我们的样本输出是0或者1两类。那么我们有:
\(P(y=1|x,\theta ) = h_{\theta}(x)\)
\(P(y=0|x,\theta ) = 1- h_{\theta}(x)\)
把这两个式子写成一个式子,就是:
\(P(y|x,\theta ) = h_{\theta}(x)^y(1-h_{\theta}(x))^{1-y}\)
其中y的取值只能是0或者1。
用矩阵法表示,即为:
\(P(Y|X,\theta ) = h_{\theta}(X)^Y(E-h_{\theta}(X))^{1-Y}\),其中E为单位矩阵。
得到了y的概率分布函数表达式,我们就可以用似然函数最大化来求解我们需要的模型系数\(\theta\)。
为了方便求解,这里我们用对数似然函数最大化,对数似然函数取反即为我们的损失函数\(J(\theta\))。其中:
似然函数的代数表达式为:
\(L(\theta) = \prod\limits_{i=1}^{m}(h_{\theta}(x^{(i)}))^{y^{(i)}}(1-h_{\theta}(x^{(i)}))^{1-y^{(i)}}\)
其中m为样本的个数。
对似然函数对数化取反的表达式,即损失函数表达式为:
\(J(\theta) = -lnL(\theta) = -\sum\limits_{i=1}^{m}(y^{(i)}log(h_{\theta}(x^{(i)}))+ (1-y^{(i)})log(1-h_{\theta}(x^{(i)})))\)
损失函数用矩阵法表达更加简洁:
\(J(\theta) = -Y\bullet logh_{\theta}(X) - (E-Y)\bullet log(E-h_{\theta}(X))\)
其中E为单位矩阵,\(\bullet\)为内积。
4. 二元逻辑回归的损失函数的优化方法
对于二元逻辑回归的损失函数极小化,有比较多的方法,最常见的有梯度下降法,坐标轴下降法,等牛顿法等。这里推导出梯度下降法中\(\theta\)每次迭代的公式。由于代数法推导比较的繁琐,我习惯于用矩阵法来做损失函数的优化过程,这里给出矩阵法推导二元逻辑回归梯度的过程。
对于\(J(\theta) = -Y\bullet logh_{\theta}(X) - (1-Y)\bullet log(E-h_{\theta}(X))\),我们用\(J(\theta)\)对\(\theta\)向量求导可得:
\(\frac{\partial}{\partial\theta}J(\theta) = -Y \bullet X^T\frac{1}{h_{\theta}(X)}h_{\theta}(X)(1-h_{\theta}(X)) + (E-Y)\bullet X^T\frac{1}{1-h_{\theta}(X)}h_{\theta}(X)(1-h_{\theta}(X))\)
这一步我们用到了矩阵求导的链式法则,和下面三个矩阵求导公式:
\(\frac{\partial}{\partial X}logX = 1/X\)
\(\frac{\partial}{\partial z}g(z) = g(z)(1-g(z)) (g(z)为sigmoid函数) \)
\(\frac{\partial}{\partial\theta}X\theta = X^T\)
对于刚才的求导公式我们进行化简可得:
\(\frac{\partial}{\partial\theta}J(\theta) = X^T(h_{\theta}(X) - Y )\)
从而在梯度下降法中每一步向量\(\theta\)的迭代公式如下:
\(\theta = \theta - \alpha X^T(h_{\theta}(X) - Y )\)
其中,\(\alpha\)为梯度下降法的步长。
实践中,我们一般不用操心优化方法,大部分机器学习库都内置了各种逻辑回归的优化方法,不过了解至少一种优化方法还是有必要的。
5. 二元逻辑回归的正则化
逻辑回归也会面临过拟合问题,所以我们也要考虑正则化。常见的有L1正则化和L2正则化。
逻辑回归的L1正则化的损失函数表达式如下,相比普通的逻辑回归损失函数,增加了L1的范数做作为惩罚,超参数\(\alpha\)作为惩罚系数,调节惩罚项的大小。
二元逻辑回归的L1正则化损失函数表达式如下:
\(J(\theta) = -Y\bullet logh_{\theta}(X) - (E-Y)\bullet log(1-h_{\theta}(X)) + \alpha||\theta||_1\)
其中\(||\theta||_1\)为\(\theta\)的L1范数。
逻辑回归的L1正则化损失函数的优化方法常用的有坐标轴下降法和最小角回归法。
二元逻辑回归的L2正则化损失函数表达式如下:
\(J(\theta) = -Y\bullet logh_{\theta}(X) - (E-Y)\bullet log(1-h_{\theta}(X)) + \frac{1}{2}\alpha||\theta||_2^2\)
其中\(||\theta||_2\)为\(\theta\)的L2范数。
逻辑回归的L2正则化损失函数的优化方法和普通的逻辑回归类似。
6. 二元逻辑回归的推广:多元逻辑回归
前面几节我们的逻辑回归的模型和损失函数都局限于二元逻辑回归,实际上二元逻辑回归的模型和损失函数很容易推广到多元逻辑回归。比如总是认为某种类型为正值,其余为0值,这种方法为最常用的one-vs-reset,简称OvR.
回顾下二元逻辑回归。
\(P(y=1|x,\theta ) = h_{\theta}(x) = \frac{1}{1+e^{-x\theta}} = \frac{e^{x\theta}}{1+e^{x\theta}}\)
\(P(y=0|x,\theta ) = 1- h_{\theta}(x) = \frac{1}{1+e^{x\theta}}\)
其中y只能取到0和1。则有:
\(ln\frac{P(y=1|x,\theta )}{P(y=0|x,\theta)} = x\theta\)
如果我们要推广到多元逻辑回归,则模型要稍微做下扩展。
我们假设是K元分类模型,即样本输出y的取值为1,2,。。。,K。
根据二元逻辑回归的经验,我们有:
\(ln\frac{P(y=1|x,\theta )}{P(y=K|x,\theta)} = x\theta_1\)
\(ln\frac{P(y=2|x,\theta )}{P(y=K|x,\theta)} = x\theta_2\)
...
\(ln\frac{P(y=K-1|x,\theta )}{P(y=K|x,\theta)} = x\theta_{K-1}\)
上面有K-1个方程。
加上概率之和为1的方程如下:
\(\sum\limits_{i=1}^{K}P(y=i|x,\theta ) = 1\)
从而得到K个方程,里面有K个逻辑回归的概率分布。
解出这个K元一次方程组,得到K元逻辑回归的概率分布如下:
\(P(y=k|x,\theta ) = e^{x\theta_k} \bigg/ 1+\sum\limits_{t=1}^{K-1}e^{x\theta_t}\) k = 1,2,...K-1
\(P(y=K|x,\theta ) = 1 \bigg/ 1+\sum\limits_{t=1}^{K-1}e^{x\theta_t}\)
多元逻辑回归的损失函数推导以及优化方法和二元逻辑回归类似,这里就不累述。
7.小结
逻辑回归尤其是二元逻辑回归是非常常见的模型,训练速度很快,虽然使用起来没有支持向量机(SVM)那么占主流,但是解决普通的分类问题是足够了,训练速度也比起SVM要快不少。如果你要理解机器学习分类算法,那么第一个应该学习的分类算法个人觉得应该是逻辑回归。理解了逻辑回归,其他的分类算法再学习起来应该没有那么难了。
(欢迎转载,转载请注明出处。欢迎沟通交流: [email protected])
以上是关于逻辑回归算法原理是啥?的主要内容,如果未能解决你的问题,请参考以下文章