大数据离线开发8.3 Hive的数据模型
Posted 小孙仗剑走天涯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据离线开发8.3 Hive的数据模型相关的知识,希望对你有一定的参考价值。
8.4 Hive的数据模型
Hive的数据存储
- 基于HDFS
- 没有专门的数据存储格式
- 存储结构主要包括:数据库、文件、表、视图
- 可以直接加载文本文件(.txt文件)
- 创建表时,指定Hive数据的列分隔符与行分隔符
8.4.1 内部表
- hive 的内部表类似 mysql、Oracle中的表
- 每一个 Table 在 Hive 中都有一个相应的目录存储数据
- 所有的 Table 数据(不包括 External Table)都保存在这个目录中
- 删除表时,元数据与数据都会被删除
hive 默认表的分隔符是 tab 键
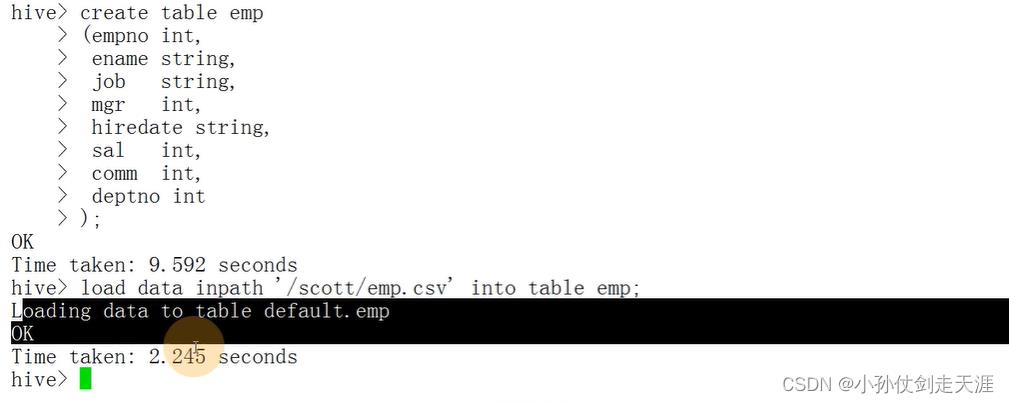
举例:创建一个员工表emp表
HDFS上查询到员工表数据:hdfs dfs -cat /scott/emp.csv
数据 7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
启动hive,执行下述语句,上述表保存到数据库里,hdfs目录(游览器ip:50070)上也有保存表
create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal int,
comm int,
deptno int
);
导入数据
-
insert语句
-
load语句:相当于crtl+x
- 导入HDFS的语句:load data inpath ‘/scott/emp.csv’ into table emp;
- 直接导入本地Linux数据:load data local inpath ‘/root/tmp/emp.csv’ into table emp1;

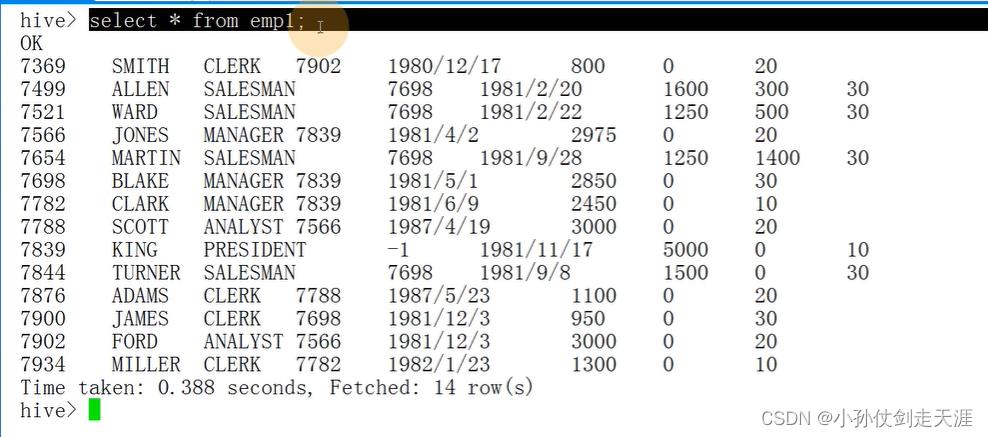
默认表的分隔符是tab键,重新创建emp1表,格式化表的分隔符为逗号

客户端的静默模式:hive -S
执行的sql如果是一个MapReduce的话,sql语句就会在yarn后台运行,然后打印在屏幕上
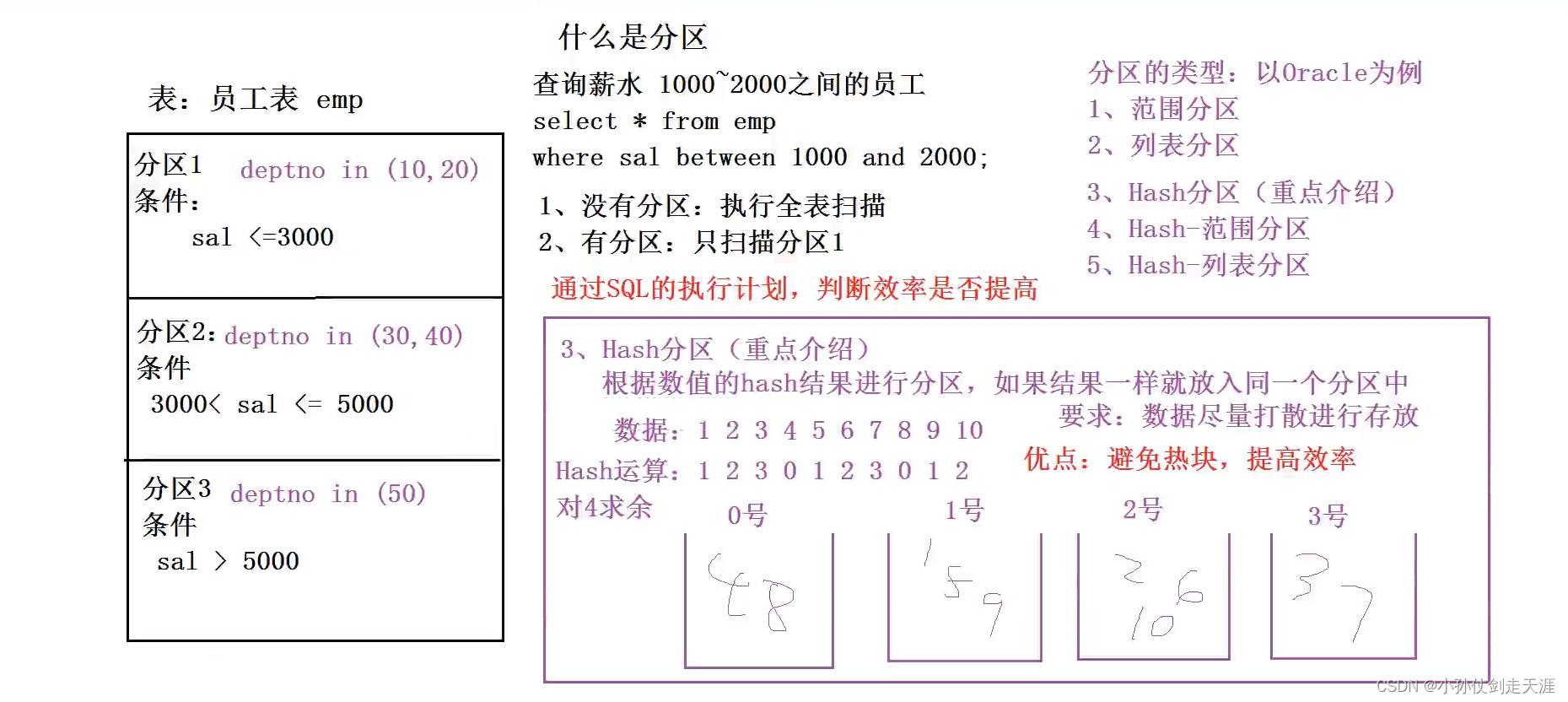
8.4.2 分区表
- Partition 对应于数据库的 Partition 列的密集索引
- 在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中
分区表:提高性能
举例:创建一个分区表,根据部门号deptno
create table emp_part(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal int,
comm int,
)partitioned by (deptno int)
row format delimited fileds terminated by ',';
插入数据:往分区中插入数据,子查询
insert into table emp_part partition(deptno=10) selecet empno,ename,job,mgr,hiredate,sal,comm from emp1 where deptno = 10;
insert into table emp_part partition(deptno=20) selecet empno,ename,job,mgr,hiredate,sal,comm from emp1 where deptno = 20;
insert into table emp_part partition(deptno=30) selecet empno,ename,job,mgr,hiredate,sal,comm from emp1 where deptno = 30;
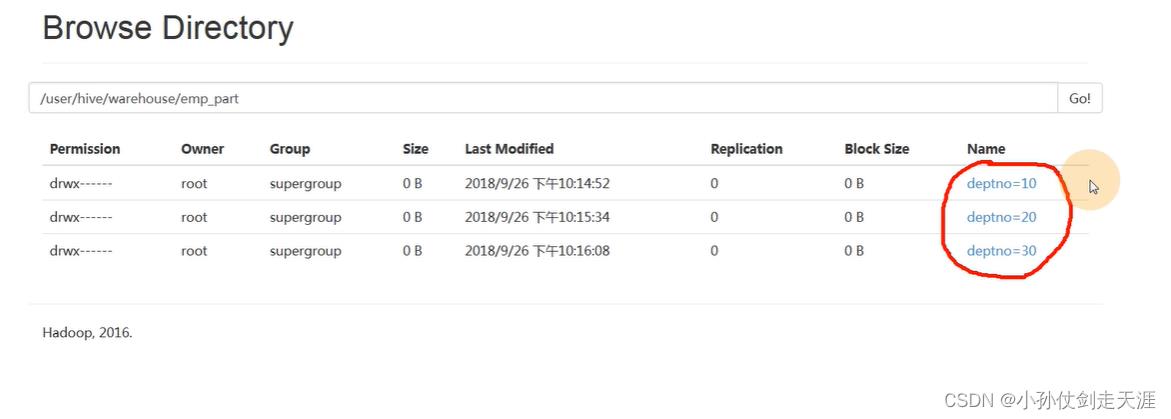
补充:如何判断提高了性能——SQL执行计划
- 关系型数据库(Oracle)
- Hive类型方式
Oracle 中的 SQL 的执行计划
-
oracle数据库的优化器
- RBO:基于规则的优化器
- CBO:基本上都是CBO,基于成本(cost)的优化器
-
oracle中的索引的类型
- B树索引:默认
- 位图索巧
案例:查询10号部门的员工
情况一:
生成执行计划:explain plan for select * from emp where deptno=10;
打印执行计划:select * from table(dbms xplan.display);
情况二:
创建索引:create index myindex on emp(deptno);
打印执行计划:select * from table(dbms xplan.display);
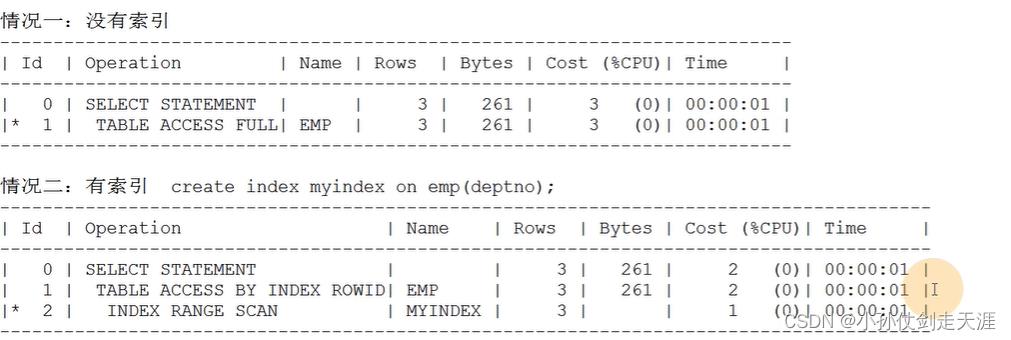
结论:情况一的 cost(成本)比情况二的 cost 高
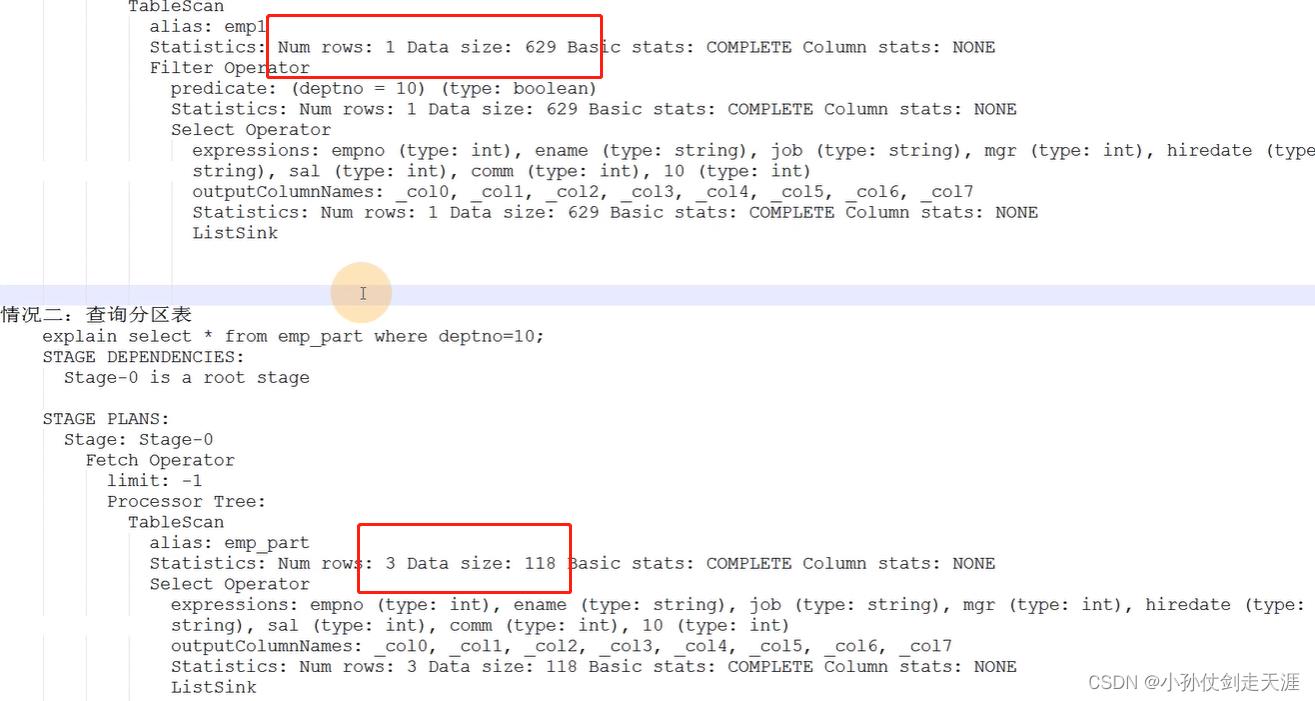
HIve 中的 SQL 的执行计划
案例:查询10号部门的员工
情况一:
生成执行计划:explain select * from emp1 where deptno=10;
情况二:
生成执行计划:explain select * from emp_part where deptno=10;
8.4.3 外部表
外部表:只定义表结构,数据保存在HDFS的某个目录下
- 指向已经在 HDFS 中存在的数据,可以创建 Partition
- 它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异
- 外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅删除该链接
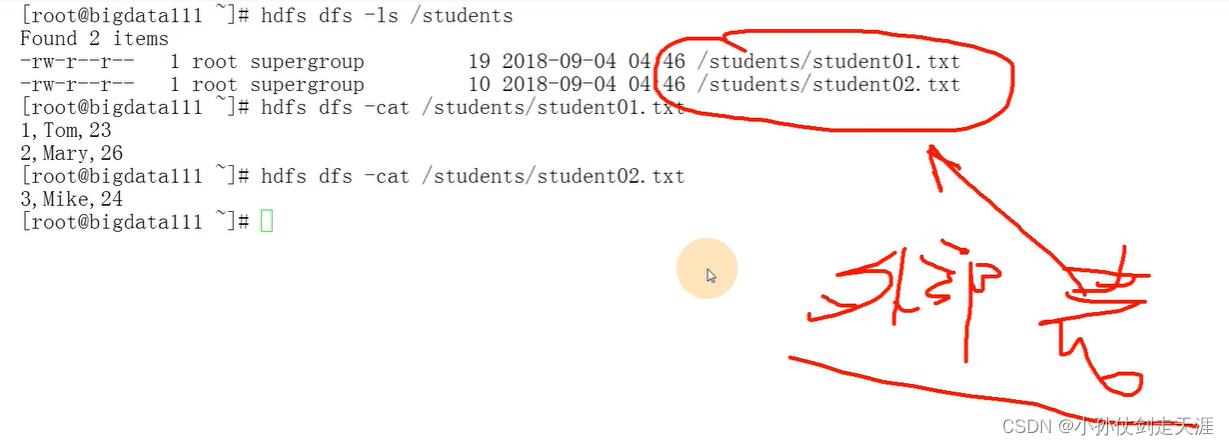
案例:创建外部表指定hdfs的student目录
create external table ext_student
(sid int,sname string,age int)
row format delimited fields terminated by ','
location '/students' ;

8.4.4 桶表
桶表:类似Hash。桶表是对数据进行哈希取值,然后放到不同文件中存储。
案例:根据员工的职位job简历桶表
创建桶表
create table emp_bucket(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal int,
comm int,
deptno int
)clustered by (job) into 4 buckets
row format delimited fileds terminated by ',';
设置设置环境变量
set hive.enforce.bucketing = true;
插入数据
insert into table emp_bucket select * from emp1;

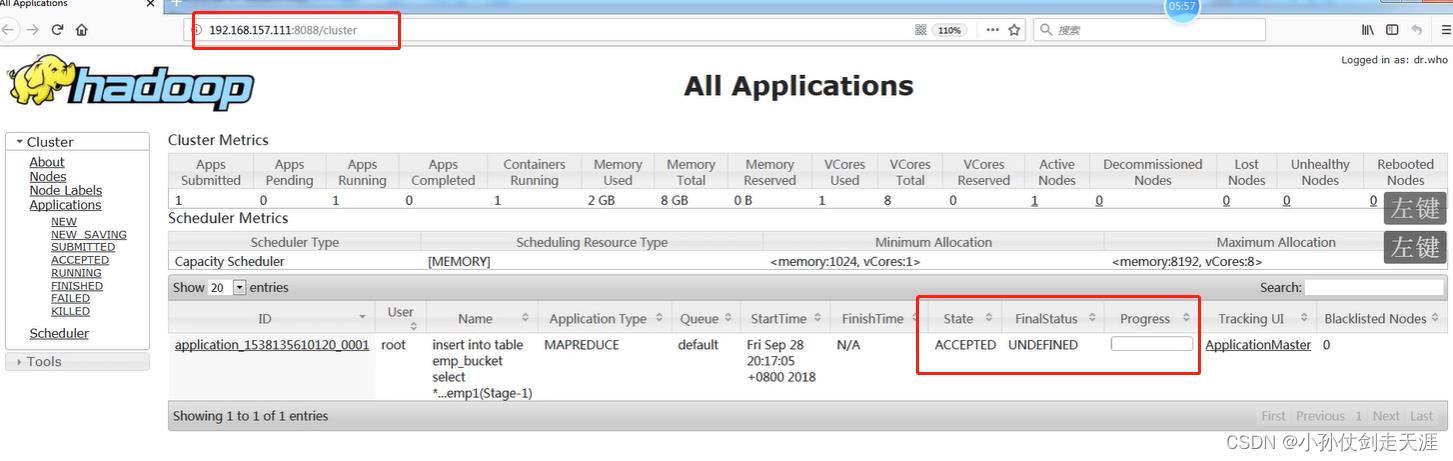
插入语句速度比较慢,可以在网页版查看进度
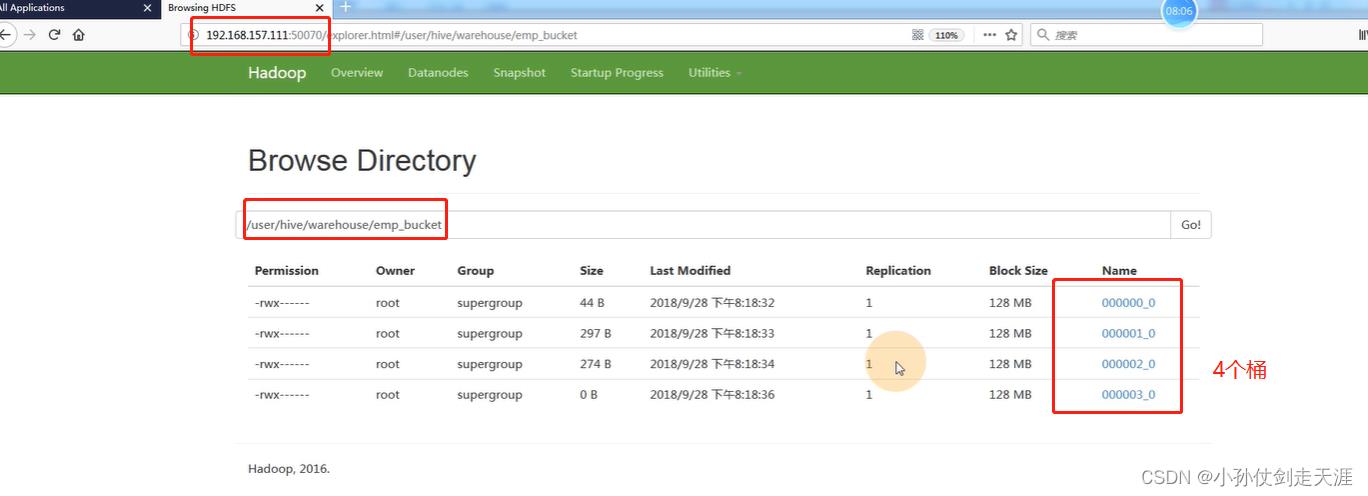
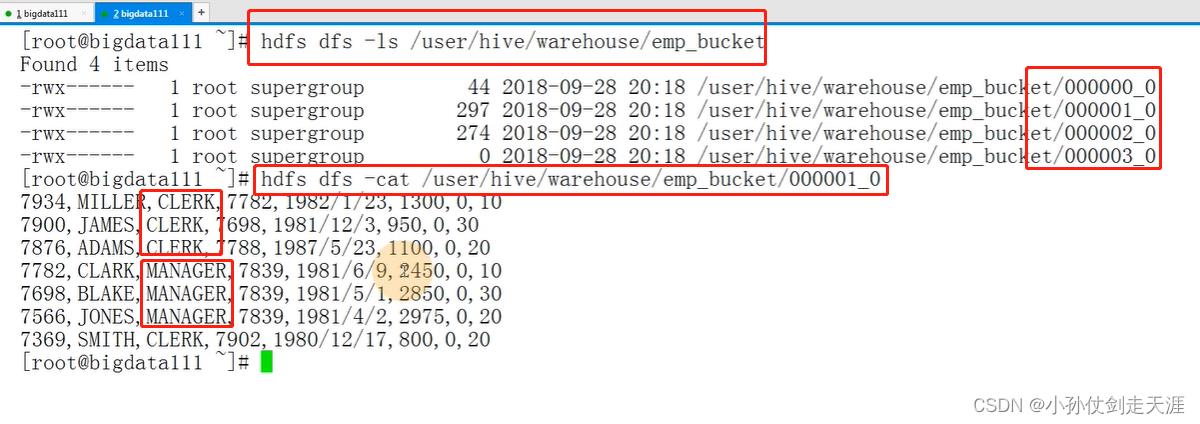
当执行完成之后,可以在yarn:50070网页查看桶表信息,也可以用hdfs以命令行的方式进行查看
8.4.5 视图
- 视图是一种虚表(不保存数据),是一个逻辑概念;可以跨越多张表
- 视图建立在已有表的基础上, 视图赖以建立的这些表称为基表
- 视图的作用:可以简化复杂的查询
创建视图
create view view10
as select * from emp1 where deptno=10;
查询视图
select * from view10;
以上是关于大数据离线开发8.3 Hive的数据模型的主要内容,如果未能解决你的问题,请参考以下文章