Flume+Hadoop+Hive的离线分析系统基本架构
Posted 咕噜大大
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume+Hadoop+Hive的离线分析系统基本架构相关的知识,希望对你有一定的参考价值。
最近在学习大数据的离线分析技术,所以在这里通过做一个简单的网站点击流数据分析离线系统来和大家一起梳理一下离线分析系统的架构模型。当然这个架构模型只能是离线分析技术的一个简单的入门级架构,实际生产环境中的大数据离线分析技术还涉及到很多细节的处理和高可用的架构。这篇文章的目的只是带大家入个门,让大家对离线分析技术有一个简单的认识,并和大家一起做学习交流。
离线分析系统的结构图
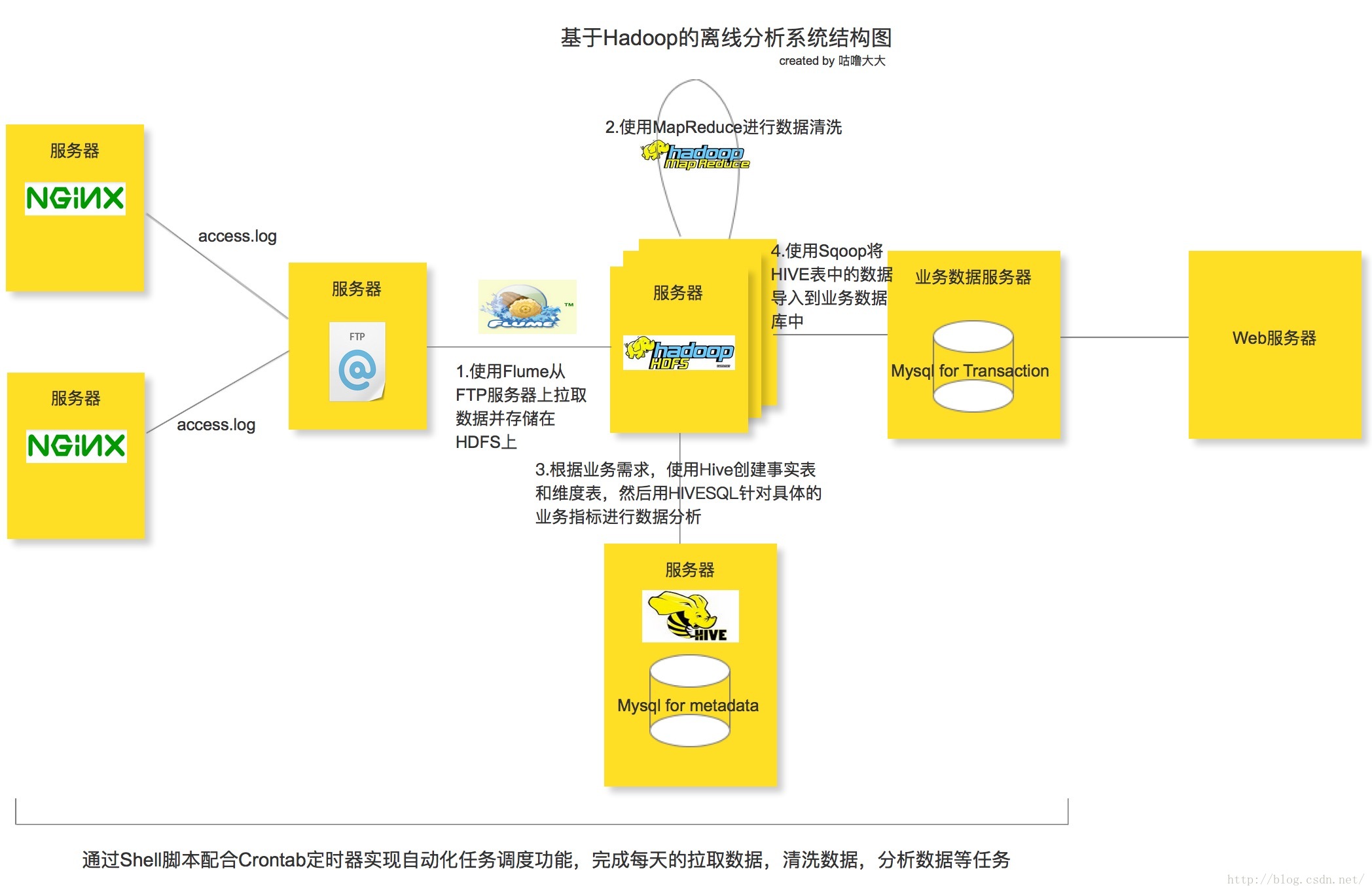
整个离线分析的总体架构就是使用 Flume 从 FTP 服务器上采集日志文件,并存储在 Hadoop HDFS 文件系统上,再接着用 Hadoop 的 mapreduce 清洗日志文件,最后使用 HIVE 构建数据仓库做离线分析。任务的调度使用 Shell 脚本完成,当然大家也可以尝试一些自动化的任务调度工具,比如说 AZKABAN 或者 OOZIE 等。 分析所使用的点击流日志文件主要来自nginx的access.log日志文件,需要注意的是在这里并不是用Flume直接去生产环境上拉取nginx的日志文件,而是多设置了一层FTP服务器来缓冲所有的日志文件,然后再用Flume监听FTP服务器上指定的目录并拉取目录里的日志文件到HDFS服务器上(具体原因下面分析)。从生产环境推送日志文件到FTP服务器的操作可以通过Shell脚本配合Crontab定时器来实现。
网站点击流数据
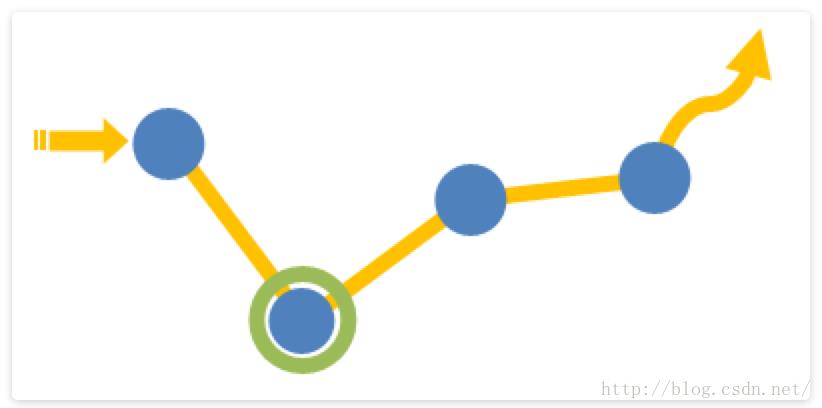
图片来源:http://webdataanalysis.net/data-collection-and-preprocessing/weblog-to-clickstream/#comments
一般在 WEB 系统中,用户对站点的页面的访问浏览,点击行为等一系列的数据都会记录在日志中,每一条日志记录就代表着上图中的一个数据点;而点击流数据关注的就是所有这些点连起来后的一个完整的网站浏览行为记录,可以认为是一个用户对网站的浏览 session 。比如说用户从哪一个外站进入到当前的网站,用户接下来浏览了当前网站的哪些页面,点击了哪些图片链接按钮等一系列的行为记录,这一个整体的信息就称为是该用户的点击流记录。这篇文章中设计的离线分析系统就是收集 WEB 系统中产生的这些数据日志,并清洗日志内容存储分布式的 HDFS 文件存储系统上,接着使用离线分析工具 HIVE 去统计所有用户的点击流信息。
本系统中我们采用Nginx的access.log来做点击流分析的日志文件。access.log日志文件的格式如下: 样例数据格式: 124.42.13.230 - - [18/Sep/2013:06:57:50 +0000] "GET /shoppingMall?ver=1.2.1 HTTP/1.1" 200 7200 "http://www.baidu.com.cn" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; BTRS101170; InfoPath.2; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727)" 格式分析: 1、 访客ip地址:124.42.13.230 2 、访客用户信息: - - 3、请求时间: [18/Sep/2013:06:57:50 +0000] 4 、请求方式:GET 5、请求的url: /shoppingMall ?ver=1.10.2 6 、请求所用协议:HTTP/1.1 7、响应码:200 8 、返回的数据流量:7200 9 、访客的来源url:http://www.baidu.com.cn 10、访客所用浏览器:Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; BTRS101170; InfoPath.2; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727)
收集用户数据
网站会通过前端 JS 代码或服务器端的后台代码收集用户浏览数据并存储在网站服务器中。一般运维人员会在离线分析系统和真实生产环境之间部署 FTP 服务器,并将生产环境上的用户数据每天定时发送到 FTP 服务器上,离线分析系统就会从 FTP 服务上采集数据而不会影响到生产环境。
采集数据的方式有多种,一种是通过自己编写 shell 脚本或 Java 编程采集数据,但是工作量大,不方便维护,另一种就是直接使用第三方框架去进行日志的采集,一般第三方框架的健壮性,容错性和易用性都做得很好也易于维护。本文采用第三方框架 Flume 进行日志采集, Flume 是一个分布式的高效的日志采集系统,它能把分布在不同服务器上的海量日志文件数据统一收集到一个集中的存储资源中, Flume 是 Apache 的一个顶级项目,与 Hadoop 也有很好的兼容性。不过需要注意的是 Flume 并不是一个高可用的框架,这方面的优化得用户自己去维护。
Flume 的 agent 是运行在 JVM 上的,所以各个服务器上的 JVM 环境必不可少。每一个 Flume agent 部署在一台服务器上, Flume 会收集 web server 产生的日志数据,并封装成一个个的事件发送给 Flume Agent 的 Source , Flume Agent Source 会消费这些收集来的数据事件并放在 Flume Agent Channel , Flume Agent Sink 会从 Channel 中收集这些采集过来的数据,要么存储在本地的文件系统中要么作为一个消费资源分发给下一个装在分布式系统中其它服务器上的 Flume 进行处理。 Flume 提供了点对点的高可用的保障,某个服务器上的 Flume Agent Channel 中的数据只有确保传输到了另一个服务器上的 Flume Agent Channel 里或者正确保存到了本地的文件存储系统中,才会被移除。 本系统中每一个 FTP 服务器以及 Hadoop 的 name node 服务器上都要部署一个 Flume Agent ; FTP 的 Flume Agent 采集 Web Server 的日志并汇总到 name node 服务器上的 Flume Agent ,最后由 hadoop name node 服务器将所有的日志数据下沉到分布式的文件存储系统 HDFS 上面。 需要注意的是Flume的Source在本文的系统中选择的是Spooling Directory Source,而没有选择Exec Source,因为当Flume服务down掉的时候Spooling Directory Source能记录上一次读取到的位置,而Exec Source则没有,需要用户自己去处理,当重启Flume服务器的时候如果处理不好就会有重复数据的问题。当然Spooling Directory Source也是有缺点的,会对读取过的文件重命名,所以多架一层FTP服务器也是为了避免Flume“污染”生产环境。Spooling Directory Source另外一个比较大的缺点就是无法做到灵活监听某个文件夹底下所有子文件夹里的所有文件里新追加的内容。关于这些问题的解决方案也有很多,比如选择其它的日志采集工具,像logstash等。
FTP 服务器上的 Flume 配置文件如下:
agent.channels = memorychannel
agent.sinks = target
agent.sources.origin.type = spooldir
agent.sources.origin.spoolDir = /export/data/trivial/weblogs
agent.sources.origin.channels = memorychannel
agent.sources.origin.deserializer.maxLineLength = 2048
agent.sources.origin.interceptors = i2
agent.sources.origin.interceptors.i2.type = host
agent.sources.origin.interceptors.i2.hostHeader = hostname
agent.sinks.loggerSink.type = logger
agent.sinks.loggerSink.channel = memorychannel
agent.channels.memorychannel.type = memory
agent.channels.memorychannel.capacity = 10000
agent.sinks.target.type = avro
agent.sinks.target.channel = memorychannel
agent.sinks.target.hostname = 172.16.124.130
agent.sinks.target.port = 4545需要特别注意的是 FTP 上放入 Flume 监听的文件夹中的日志文件不能同名,不然 Flume 会报错并停止工作,最好的解决方案就是为每份日志文件拼上时间戳。
在 Hadoop 服务器上的配置文件如下:
agent.sources = origin
agent.channels = memorychannel
agent.sinks = target
agent.sources.origin.type = avro
agent.sources.origin.channels = memorychannel
agent.sources.origin.bind = 0.0.0.0
agent.sources.origin.port = 4545
#agent.sources.origin.interceptors = i1 i2
#agent.sources.origin.interceptors.i1.type = timestamp
#agent.sources.origin.interceptors.i2.type = host
#agent.sources.origin.interceptors.i2.hostHeader = hostname
agent.sinks.loggerSink.type = logger
agent.sinks.loggerSink.channel = memorychannel
agent.channels.memorychannel.type = memory
agent.channels.memorychannel.capacity = 5000000
agent.channels.memorychannel.transactionCapacity = 1000000
agent.sinks.target.type = hdfs
agent.sinks.target.channel = memorychannel
agent.sinks.target.hdfs.path = /flume/events/%y-%m-%d/%H%M%S
agent.sinks.target.hdfs.filePrefix = data-%hostname
agent.sinks.target.hdfs.rollInterval = 60
agent.sinks.target.hdfs.rollSize = 1073741824
agent.sinks.target.hdfs.rollCount = 1000000
agent.sinks.target.hdfs.round = true
agent.sinks.target.hdfs.roundValue = 10
agent.sinks.target.hdfs.roundUnit = minute
agent.sinks.target.hdfs.useLocalTimeStamp = true
agent.sinks.target.hdfs.minBlockReplicas=1
agent.sinks.target.hdfs.writeFormat=Text
agent.sinks.target.hdfs.fileType=DataStreamround, roundValue,roundUnit 三个参数是用来配置每 10 分钟在 hdfs 里生成一个文件夹保存从 FTP 服务器上拉取下来的数据。
Troubleshooting 使用Flume拉取文件到HDFS中会遇到将文件分散成多个1KB-5KB的小文件的问题 需要注意的是如果遇到Flume会将拉取过来的文件分成很多份1KB-5KB的小文件存储到HDFS上,那么 很可能 是HDFS Sink的配置不正确,导致系统使用了默认配置。spooldir类型的source是将指定目录中的文件的每一行封装成一个event放入到channel中,默认每一行最大读取1024个字符。在HDFS Sink端主要是通过rollInterval(默认30秒), rollSize(默认1KB), rollCount(默认10个event)3个属性来决定写进HDFS的分片文件的大小。 rollInterval表示经过多少秒后就将当前.tmp文件(写入的是从channel中过来的events)下沉到HDFS文件 系统 中, rollSize表示一旦.tmp文件达到一定的size后,就下沉到HDFS文件 系统 中,rollCount表示.tmp文件一旦写入了指定数量的events就下沉到HDFS文件系统中。
使用Flume拉取到HDFS中的文件格式错乱 这是因为HDFS Sink的配置中,hdfs.writeFormat属性默认为“Writable”会将原先的文件的内容序列化成HDFS的格式,应该手动设置成hdfs.writeFormat=“text”; 并且hdfs.fileType默认是“SequenceFile”类型的,是将所有event拼成一行,应该该手动设置成hdfs.fileType=“DataStream”,这样就可以是一行一个event,与原文件格式保持一致
使用Mapreduce清洗日志文件 当把日志文件中的数据拉取到HDFS文件系统后,使用Mapreduce程序去进行日志清洗 第一步,先用Mapreduce过滤掉无效的数据
package com.guludada.clickstream;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.StringTokenizer;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.guludada.dataparser.WebLogParser;
public class logClean
public static class cleanMap extends Mapper<Object,Text,Text,NullWritable>
private NullWritable v = NullWritable.get();
private Text word = new Text();
WebLogParser webLogParser = new WebLogParser();
public void map(Object key,Text value,Context context)
//将一行内容转成string
String line = value.toString();
String cleanContent = webLogParser.parser(line);
if(cleanContent != "")
word.set(cleanContent);
try
context.write(word,v);
catch (IOException e)
// TODO Auto-generated catch block
e.printStackTrace();
catch (InterruptedException e)
// TODO Auto-generated catch block
e.printStackTrace();
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://ymhHadoop:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(logClean.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(cleanMap.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//指定job的输入原始文件所在目录
Date curDate = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yy-MM-dd");
String dateStr = sdf.format(curDate);
FileInputFormat.setInputPaths(job, new Path("/flume/events/" + dateStr + "/*/*"));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path("/clickstream/cleandata/"+dateStr+"/"));
//将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
package com.guludada.dataparser;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import com.guludada.javabean.WebLogBean;
/**
* 用正则表达式匹配出合法的日志记录
*
*
*/
public class WebLogParser
public String parser(String weblog_origin)
WebLogBean weblogbean = new WebLogBean();
// 获取IP地址
Pattern IPPattern = Pattern.compile("\\\\d+.\\\\d+.\\\\d+.\\\\d+");
Matcher IPMatcher = IPPattern.matcher(weblog_origin);
if(IPMatcher.find())
String IPAddr = IPMatcher.group(0);
weblogbean.setIP_addr(IPAddr);
else
return ""
// 获取时间信息
Pattern TimePattern = Pattern.compile("\\\\[(.+)\\\\]");
Matcher TimeMatcher = TimePattern.matcher(weblog_origin);
if(TimeMatcher.find())
String time = TimeMatcher.group(1);
String[] cleanTime = time.split(" ");
weblogbean.setTime(cleanTime[0]);
else
return "";
//获取其余请求信息
Pattern InfoPattern = Pattern.compile(
"(\\\\\\"[POST|GET].+?\\\\\\") (\\\\d+) (\\\\d+).+?(\\\\\\".+?\\\\\\") (\\\\\\".+?\\\\\\")");
Matcher InfoMatcher = InfoPattern.matcher(weblog_origin);
if(InfoMatcher.find())
String requestInfo = InfoMatcher.group(1).replace('\\"',' ').trim();
String[] requestInfoArry = requestInfo.split(" ");
weblogbean.setMethod(requestInfoArry[0]);
weblogbean.setRequest_URL(requestInfoArry[1]);
weblogbean.setRequest_protocol(requestInfoArry[2]);
String status_code = InfoMatcher.group(2);
weblogbean.setRespond_code(status_code);
String respond_data = InfoMatcher.group(3);
weblogbean.setRespond_data(respond_data);
String request_come_from = InfoMatcher.group(4).replace('\\"',' ').trim();
weblogbean.setRequst_come_from(request_come_from);
String browserInfo = InfoMatcher.group(5).replace('\\"',' ').trim();
weblogbean.setBrowser(browserInfo);
else
return "";
return weblogbean.toString();
package com.guludada.javabean;
public class WebLogBean
String IP_addr;
String time;
String method;
String request_URL;
String request_protocol;
String respond_code;
String respond_data;
String requst_come_from;
String browser;
public String getIP_addr()
return IP_addr;
public void setIP_addr(String iP_addr)
IP_addr = iP_addr;
public String getTime()
return time;
public void setTime(String time)
this.time = time;
public String getMethod()
return method;
public void setMethod(String method)
this.method = method;
public String getRequest_URL()
return request_URL;
public void setRequest_URL(String request_URL)
this.request_URL = request_URL;
public String getRequest_protocol()
return request_protocol;
public void setRequest_protocol(String request_protocol)
this.request_protocol = request_protocol;
public String getRespond_code()
return respond_code;
public void setRespond_code(String respond_code)
this.respond_code = respond_code;
public String getRespond_data()
return respond_data;
public void setRespond_data(String respond_data)
this.respond_data = respond_data;
public String getRequst_come_from()
return requst_come_from;
public void setRequst_come_from(String requst_come_from)
this.requst_come_from = requst_come_from;
public String getBrowser()
return browser;
public void setBrowser(String browser)
this.browser = browser;
@Override
public String toString()
return IP_addr + " " + time + " " + method + " "
+ request_URL + " " + request_protocol + " " + respond_code
+ " " + respond_data + " " + requst_come_from + " " + browser;
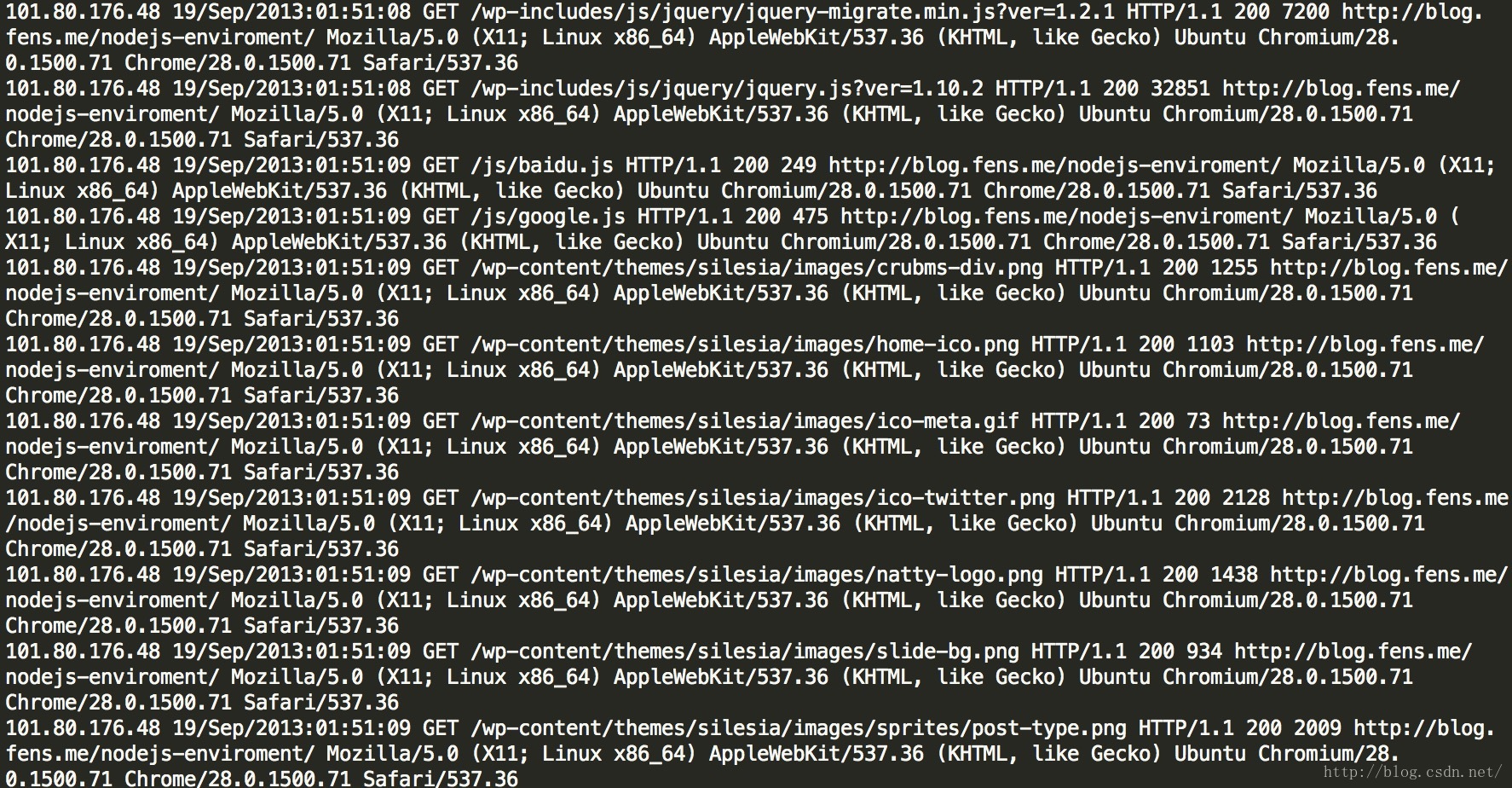
第一次日记清洗后的记录如下图:
第二步,根据访问记录生成相应的Session 信息记录,假设Session的过期时间是30分钟
package com.guludada.clickstream;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.Date;
import java.util.HashMap;
import java.util.Locale;
import java.util.UUID;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.guludada.clickstream.logClean.cleanMap;
import com.guludada.dataparser.SessionParser;
import com.guludada.dataparser.WebLogParser;
import com.guludada.javabean.WebLogSessionBean;
public class logSession
public static class sessionMapper extends Mapper<Object,Text,Text,Text>
private Text IPAddr = new Text();
private Text content = new Text();
private NullWritable v = NullWritable.get();
WebLogParser webLogParser = new WebLogParser();
public void map(Object key,Text value,Context context)
//将一行内容转成string
String line = value.toString();
String[] weblogArry = line.split(" ");
IPAddr.set(weblogArry[0]);
content.set(line);
try
context.write(IPAddr,content);
catch (IOException e)
// TODO Auto-generated catch block
e.printStackTrace();
catch (InterruptedException e)
// TODO Auto-generated catch block
e.printStackTrace();
static class sessionReducer extends Reducer<Text, Text, Text, NullWritable>
private Text IPAddr = new Text();
private Text content = new Text();
private NullWritable v = NullWritable.get();
WebLogParser webLogParser = new WebLogParser();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
SessionParser sessionParser = new SessionParser();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException
Date sessionStartTime = null;
String sessionID = UUID.randomUUID().toString();
//将IP地址所对应的用户的所有浏览记录按时间排序
ArrayList<WebLogSessionBean> sessionBeanGroup = new ArrayList<WebLogSessionBean>();
for(Text browseHistory : values)
WebLogSessionBean sessionBean = sessionParser.loadBean(browseHistory.toString());
sessionBeanGroup.add(sessionBean);
Collections.sort(sessionBeanGroup,new Comparator<WebLogSessionBean>()
public int compare(WebLogSessionBean sessionBean1, WebLogSessionBean sessionBean2)
Date date1 = sessionBean1.getTimeWithDateFormat();
Date date2 = sessionBean2.getTimeWithDateFormat();
if(date1 == null && date2 == null) return 0;
return date1.compareTo(date2);
);
for(WebLogSessionBean sessionBean : sessionBeanGroup)
if(sessionStartTime == null)
//当天日志中某用户第一次访问网站的时间
sessionStartTime = timeTransform(sessionBean.getTime());
content.set(sessionParser.parser(sessionBean, sessionID));
try
context.write(content,v);
catch (IOException e)
// TODO Auto-generated catch block
e.printStackTrace();
catch (InterruptedException e)
// TODO Auto-generated catch block
e.printStackTrace();
else
Date sessionEndTime = timeTransform(sessionBean.getTime());
long sessionStayTime = timeDiffer(sessionStartTime,sessionEndTime);
if(sessionStayTime > 30 * 60 * 1000)
//将当前浏览记录的时间设为下一个session的开始时间
sessionStartTime = timeTransform(sessionBean.getTime());
sessionID = UUID.randomUUID().toString();
continue;
content.set(sessionParser.parser(sessionBean, sessionID));
try
context.write(content,v);
catch (IOException e)
// TODO Auto-generated catch block
e.printStackTrace();
catch (InterruptedException e)
// TODO Auto-generated catch block
e.printStackTrace();
private Date timeTransform(String time)
Date standard_time = null;
try
standard_time = sdf.parse(time);
catch (ParseException e)
// TODO Auto-generated catch block
e.printStackTrace();
return standard_time;
private long timeDiffer(Date start_time,Date end_time)
long diffTime = 0;
diffTime = end_time.getTime() - start_time.getTime();
return diffTime;
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://ymhHadoop:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(logClean.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(sessionMapper.class);
job.setReducerClass(sessionReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
Date curDate = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yy-MM-dd");
String dateStr = sdf.format(curDate);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path("/clickstream/cleandata/"+dateStr+"/*"));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path("/clickstream/sessiondata/"+dateStr+"/"));
//将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
package com.guludada.dataparser;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import com.guludada.javabean.WebLogSessionBean;
public class SessionParser
SimpleDateFormat sdf_origin = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss",Locale.ENGLISH);
SimpleDateFormat sdf_final = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public String parser(WebLogSessionBean sessionBean,String sessionID)
sessionBean.setSession(sessionID);
return sessionBean.toString();
public WebLogSessionBean loadBean(String sessionContent)
WebLogSessionBean weblogSession = new WebLogSessionBean();
String[] contents = sessionContent.split(" ");
weblogSession.setTime(timeTransform(contents[1]));
weblogSession.setIP_addr(contents[0]);
weblogSession.setRequest_URL(contents[3]);
weblogSession.setReferal(contents[7]);
return weblogSession;
private String timeTransform(String time)
Date standard_time = null;
try
standard_time = sdf_origin.parse(time);
catch (ParseException e)
// TODO Auto-generated catch block
e.printStackTrace();
return sdf_final.format(standard_time);
package com.guludada.javabean;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class WebLogSessionBean
String time;
String IP_addr;
String session;
String request_URL;
String referal;
public String getTime()
return time;
public void setTime(String time)
this.time = time;
public String getIP_addr()
return IP_addr;
public void setIP_addr(String iP_addr)
IP_addr = iP_addr;
public String getSession()
return session;
public void setSession(String session)
this.session = session;
public String getRequest_URL()
return request_URL;
public void setRequest_URL(String request_URL)
this.request_URL = request_URL;
public String getReferal()
return referal;
public void setReferal(String referal)
this.referal = referal;
public Date getTimeWithDateFormat()
SimpleDateFormat sdf_final = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
if(this.time != null && this.time != "")
try
return sdf_final.parse(this.time);
catch (ParseException e)
// TODO Auto-generated catch block
e.printStackTrace();
return null;
@Override
public String toString()
return time + " " + IP_addr + " " + session + " "
+ request_URL + " " + referal;
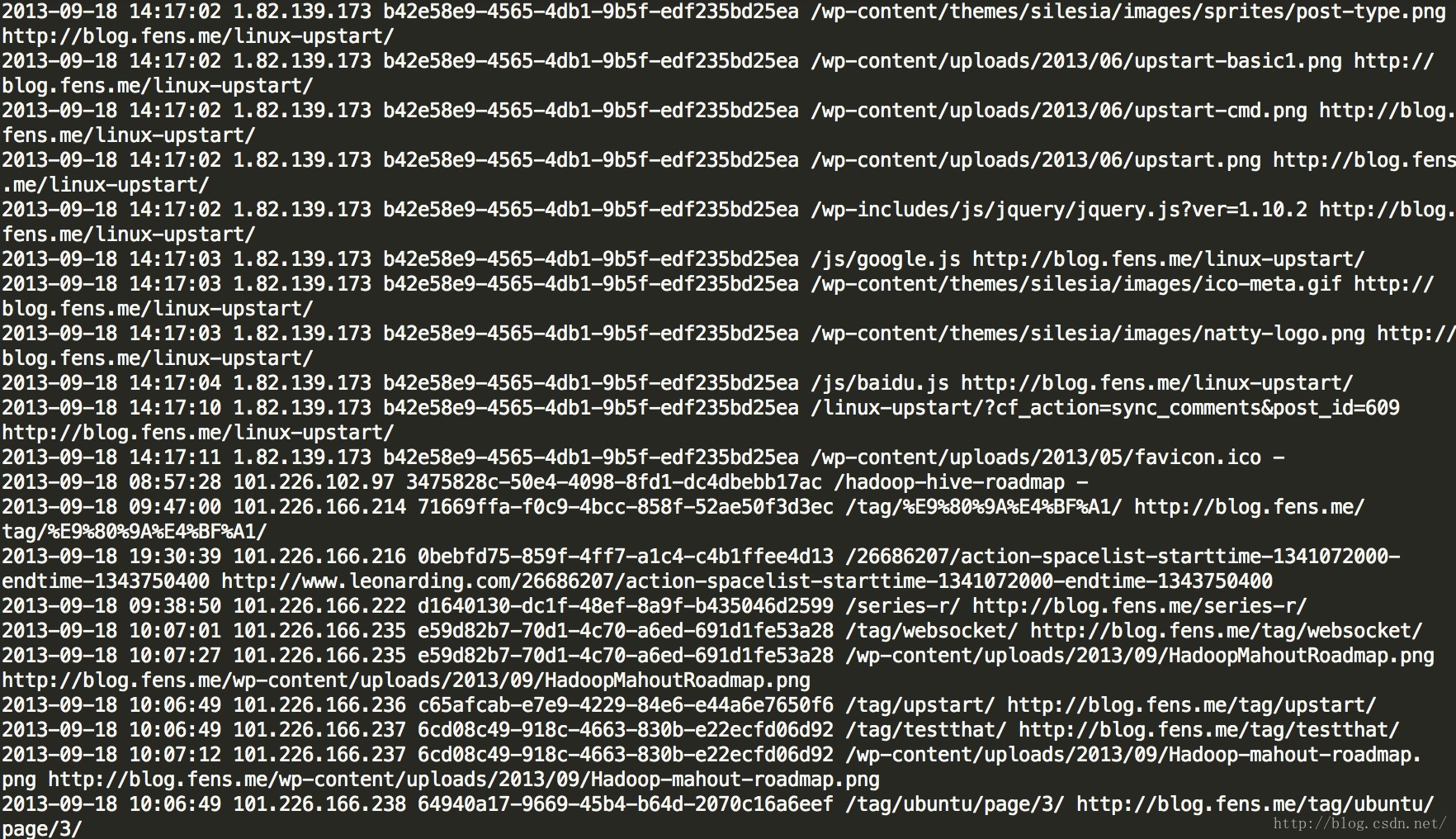
第二次清理出来的Session信息结构如下:
| 时间 | IP | SessionID | 请求页面URL | Referal URL |
| 2015-05-30 19:38:00 | 192.168.12.130 | Session1 | /blog/me | www.baidu.com |
| 2015-05-30 19:39:00 | 192.168.12.130 | Session1 | /blog/me/details | www.mysite.com/blog/me |
| 2015-05-30 19:38:00 | 192.168.12.40 | Session2 | /blog/me | www.baidu.com |
第三步,清洗第二步生成的Session信息,生成PageViews信息表
package com.guludada.clickstream;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.Date;
import java.util.HashMap;
import java.util.Locale;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.guludada.clickstream.logClean.cleanMap;
import com.guludada.clickstream.logSession.sessionMapper;
import com.guludada.clickstream.logSession.sessionReducer;
import com.guludada.dataparser.PageViewsParser;
import com.guludada.dataparser.SessionParser;
import com.guludada.dataparser.WebLogParser;
import com.guludada.javabean.PageViewsBean;
import com.guludada.javabean.WebLogSessionBean;
public class PageViews
public static class pageMapper extends Mapper<Object,Text,Text,Text>
private Text word = new Text();
public void map(Object key,Text value,Context context)
String line = value.toString();
String[] webLogContents = line.split(" ");
//根据session来分组
word.set(webLogContents[2]);
try
context.write(word,value);
catch (IOException e)
// TODO Auto-generated catch block
e.printStackTrace();
catch (InterruptedException e)
// TODO Auto-generated catch block
e.printStackTrace();
public static class pageReducer extends Reducer<Text, Text, Text, NullWritable>
private Text session = new Text();
private Text content = new Text();
private NullWritable v = NullWritable.get();
PageViewsParser pageViewsParser = new PageViewsParser();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//上一条记录的访问信息
PageViewsBean lastStayPageBean = null;
Date lastVisitTime = null;
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException
//将session所对应的所有浏览记录按时间排序
ArrayList<PageViewsBean> pageViewsBeanGroup = new ArrayList<PageViewsBean>();
for(Text pageView : values)
PageViewsBean pageViewsBean = pageViewsParser.loadBean(pageView.toString());
pageViewsBeanGroup.add(pageViewsBean);
Collections.sort(pageViewsBeanGroup,new Comparator<PageViewsBean>()
public int compare(PageViewsBean pageViewsBean1, PageViewsBean pageViewsBean2)
Date date1 = pageViewsBean1.getTimeWithDateFormat();
Date date2 = pageViewsBean2.getTimeWithDateFormat();
if(date1 == null && date2 == null) return 0;
return date1.compareTo(date2);
);
//计算每个页面的停留时间
int step = 0;
for(PageViewsBean pageViewsBean : pageViewsBeanGroup)
Date curVisitTime = pageViewsBean.getTimeWithDateFormat();
if(lastStayPageBean != null)
//计算前后两次访问记录相差的时间,单位是秒
Integer timeDiff = (int) ((curVisitTime.getTime() - lastVisitTime.getTime())/1000);
//根据当前记录的访问信息更新上一条访问记录中访问的页面的停留时间
lastStayPageBean.setStayTime(timeDiff.toString());
//更新访问记录的步数
step++;
pageViewsBean.setStep(step+"");
//更新上一条访问记录的停留时间后,将当前访问记录设定为上一条访问信息记录
lastStayPageBean = pageViewsBean;
lastVisitTime = curVisitTime;
//输出pageViews信息
content.set(pageViewsParser.parser(pageViewsBean));
try
context.write(content,v);
catch (IOException e)
// TODO Auto-generated catch block
e.printStackTrace();
catch (InterruptedException e)
// TODO Auto-generated catch block
e.printStackTrace();
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://ymhHadoop:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(PageViews.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(pageMapper.class);
job.setReducerClass(pageReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
Date curDate = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yy-MM-dd");
String dateStr = sdf.format(curDate);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path("/clickstream/sessiondata/"+dateStr+"/*"));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path("/clickstream/pageviews/"+dateStr+"/"));
//将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
package com.guludada.dataparser;
import com.guludada.javabean.PageViewsBean;
import com.guludada.javabean.WebLogSessionBean;
public class PageViewsParser
/**
* 根据logSession的输出数据加载PageViewsBean
*
* */
public PageViewsBean loadBean(String sessionContent)
PageViewsBean pageViewsBean = new PageViewsBean();
String[] contents = sessionContent.split(" "以上是关于Flume+Hadoop+Hive的离线分析系统基本架构的主要内容,如果未能解决你的问题,请参考以下文章