《大数据开发》Hive
Posted Steve_Abelieve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《大数据开发》Hive相关的知识,希望对你有一定的参考价值。
Hive
- 是基于 Hadoop 的一个数据仓库工具;
- 提供Sql(hive Sql)查询功能;
- 数据是存储在hdfs上,hive本身不存储数据,构建表的逻辑存在指定数据库(mysql )。
- 本质是将 SQL 语句转换为 MapReduce 任务执行。
- 离线大数据计算。
- 可以将结构化的数据文件映射成为一张数据库表。
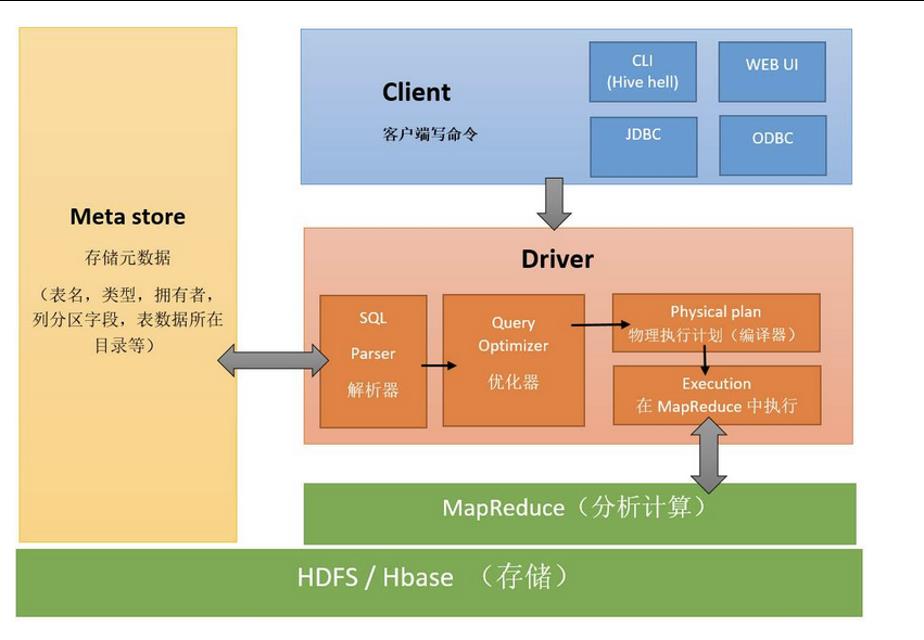
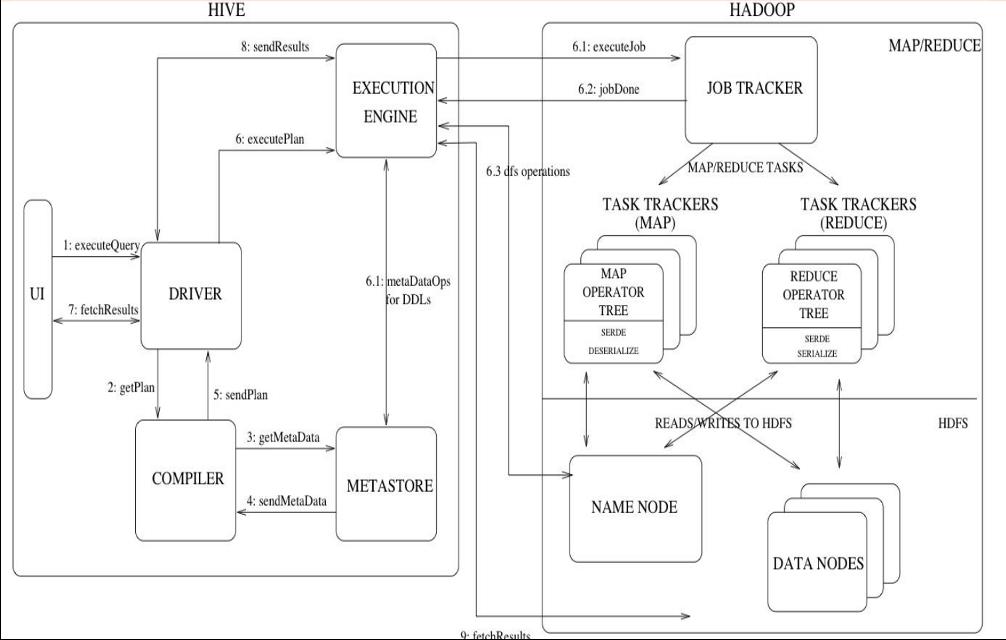
流程图
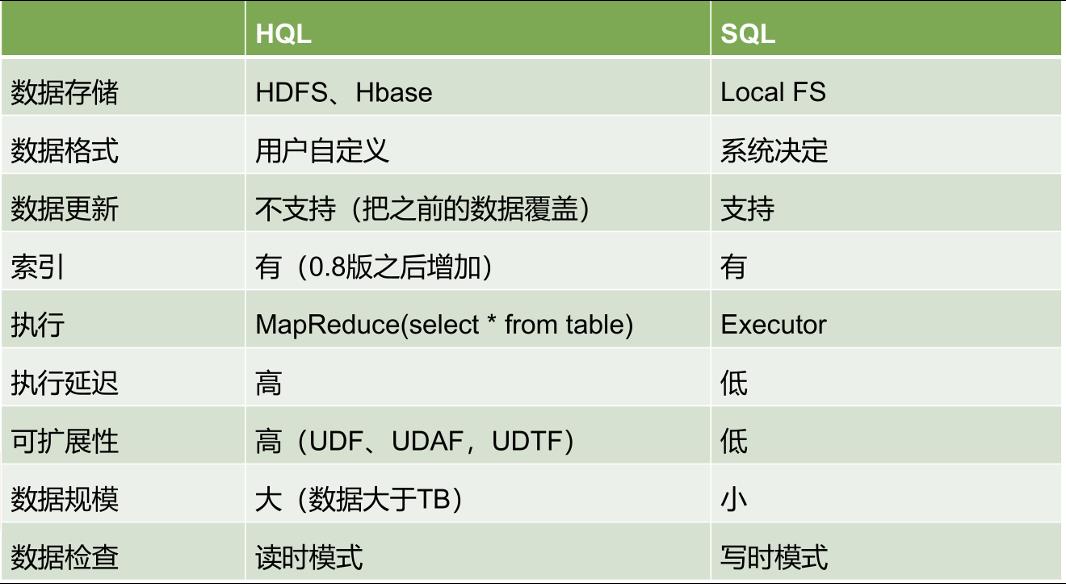
HiveSql与Sql相比
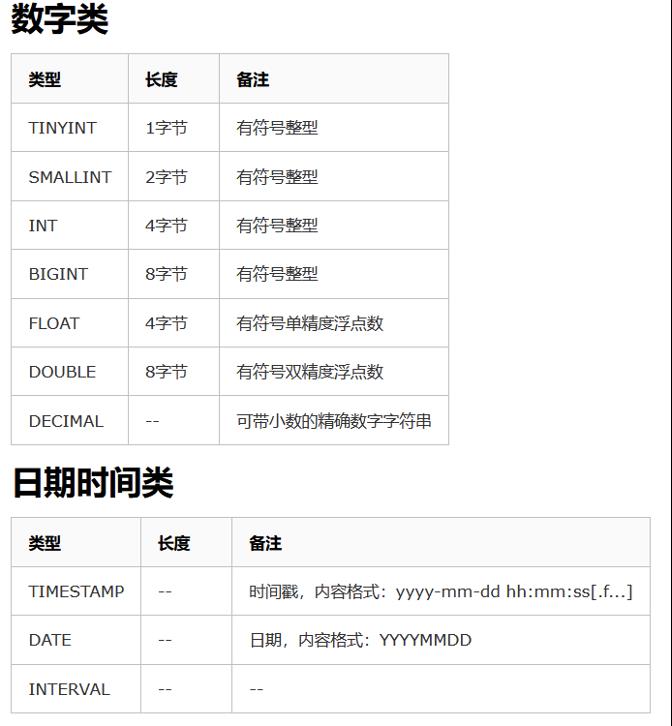
Hive字段类型

1. 建表
三种方式
- 直接建表法:
create table movies (uid string,iid string,score string , ts string)
row format delimited fields terminated by '\\t' tblproperties("skip.header.line.count"="1");
- 查询建表法:
create table movies_select as select * from movies limit 1000;
- like建表法
create table movies_like like movies_select ;
2. 执行顺序
在hive的执行语句当中的执行查询的顺序:这是一条sql:select … from … where … group by … having … order by …
执行顺序:
from … where … select … group by … having … order by …
其实总结hive的执行顺序也是总结mapreduce的执行顺序:MR程序的执行顺序:
map阶段:
1.执行from加载,进行表的查找与加载
2.执行where过滤,进行条件过滤与筛选
3.执行select查询:进行输出项的筛选
4.map端文件合并:
reduce阶段:map端本地溢出写文件的合并操作,每个map最终形成一个临时文件。 然后按列映射到对应的Reduce阶段:
1.group by:对map端发送过来的数据进行分组并进行计算。
2.having:最后过滤列用于输出结果
3.order by排序后进行结果输出到HDFS文件
所以通过上面的例子我们可以看到,在进行select之后我们会形成一张表,在这张表当中做分组排序这些操作。
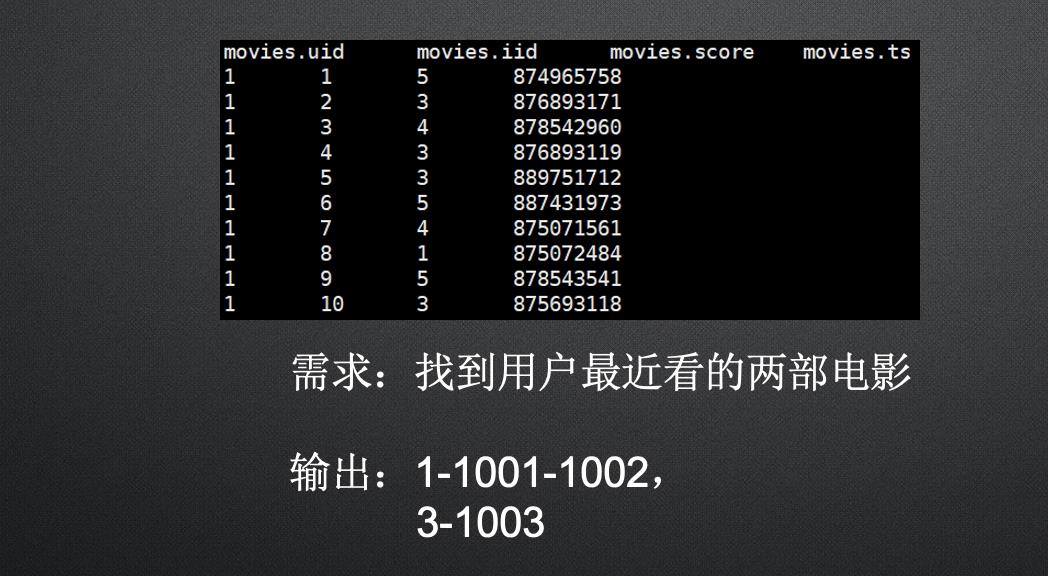
3. 常用解析函数
over(partition by col1 order by col2 asc/desc)
1.Partition by col1 按哪列进行分组,如果不指定,默认全局排序,如果指定一
列,则按照指定列进行分组,然后进行排序
2.Order by 按哪一列进行排序,这个不指定就会报错。
3. asc/desc按升序或者降序进行排序,默认升序。
row_number()
select *, row_number() over(order by score desc) as ra from t1
此处是排序,即使排序的列里面有相同的值,他的排名也会不同。
rank()
select *, rank() over(order by score desc) as ra from t1
此处是排序,排序的列里面有相同的值,他的排名会相同。
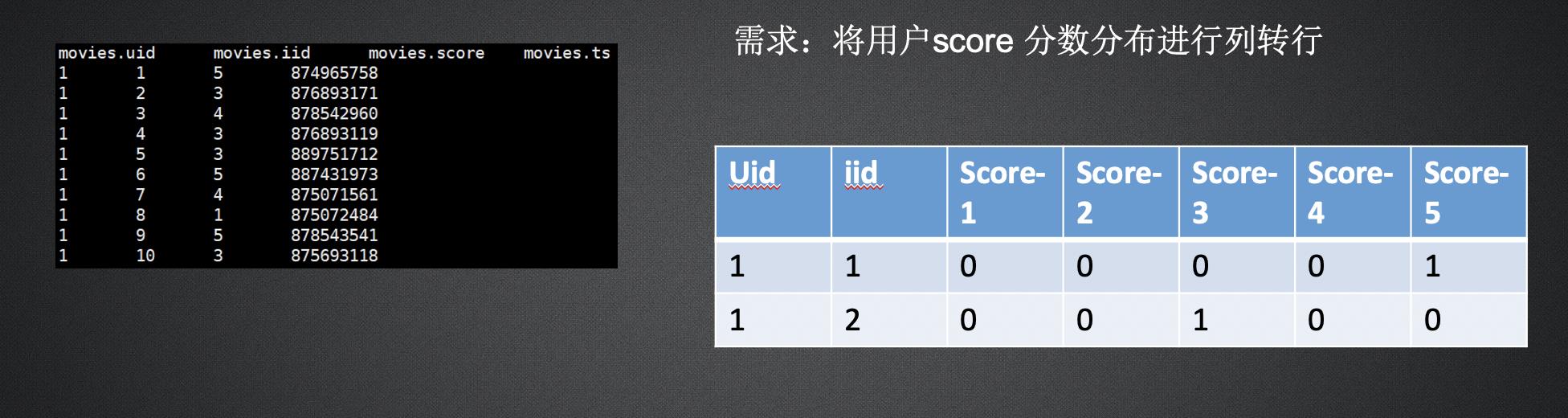
Collect_set() 和 collect_list()
列转行,会将其变为集合或者数组,set会去重,list不会去重
Case when (条件) Then () else () end as col1 ,
Explode函数和lateral view函数
Explode:UDTF,一行变多行
lateral view:虚表

Hive中sort by、order by、cluster by、distribute by的区别
1、sort by:不是全局排序,其在数据进入reducer完成排序。
2、order by:会对输入做全局排序,因此只有一个reducer,如果有多个reducer无法保证全局的排序。计算规模较大,时间可能会很长,慎用。
3、cluster by:除了具有distribute by的功能,还具有了sort by的功能select * from t1 cluster by rank 。:cluster_by 是能升
4、distribute by:按照指定的字段对数据进行划分输出到不同的reduce中。distribute by是控制map的输出在reducer是如何划分的。hive会根据distribute by后面列,对应reduce的个数进行分发,默认是采用hash算法。举个例子select * from t1 distribute by rank sort by rank,time desc limit 5;
hive的strict模式
(1) 有partition的表查询需要加上where子句,筛选部分数据实现分区裁剪,即不允许全表全分区扫描,防止数据过大
(2) order by 执行时只产生一个reduce,必须加上limit限制结果的条数,防止数据量过大造成1个reduce超负荷,否则会报错。
(3) join时,如果只有一个reduce,则不支持笛卡尔积查询。也就是说必须要有on语句的关联条件。
group by和order by 同时使用,不会按组进行排序where,group by,having,order by同时使用,执行顺序为
(1)where过滤数据
(2)对筛选结果集group by分组,group by 执行顺序是在select 之前的。因此group by中不能使用select 后面字段的别名的。
(3)对每个分组进行select查询,提取对应的列,有几组就执行几次
(4)再进行having筛选每组数据
(5)最后整体进行order by排序
内部表 外部表
Hive建表分为外部表和内部表,语句如下:
内部表:create table [表名] (默认内部表)
外部表:create external table [表名] location ‘hdfs_path ’ (hdfs_path必须是文件夹,否则会报错 )
为什么需要区分内部表、外部表?
1.内部表在构建的时候,其会将数据拉到对应的hive/warehous/xx.db之下,而外部表是在指定的hdfs_path,并未在对应的hive/warehouse上,只不过是mysql保存了外部表的一些元数据。
2.在进行删除表的时候(drop),Hive会把所有的元数据和hdfs上的数据全部删除。而删除外部表的时候,只删除外部表的元数据,数据不删除。
经验: 每天收集到的网站数据,需要做大量的统计数据分析,所以在数据源上可以使用外部表进行存储,方便数据的共享,在做统计分析时候用到的中间表,结果表可以使用内部表,因为这些数据不需要共享,使用内部表更为合适。
Hive表的分区
为什么要分区 :随着MR的任务越来越多,表的数据量会越来越大,而Hive查询数据的数据的时候通常使用的是全表扫描,这样将会导致大量不必要的数据进行扫描,从而查询效率会大大的降低。 从而Hive引进了分区技术,使用分区技术:避免Hive全表扫描,提升查询效率
分区:将整个表的数据在存储时划分成多个子目录来存储(子目录就是以分区名来名称, partitioned by(分区名 数据类型)),比如按星期几进行划分数据data,当然也可以建立多分区:
user/hive/warehouse/xx.db/data/Monday/xxx.dt
user/hive/warehouse/xx.db/data/Tuesday/xxx.dt
.
.
.
user/hive/warehouse/xx.db/data/Sunday/xxx.dt
Hive表的动态分区
Hive表的动态分区
上述分区都是静态分区,插入的时候知道分区类型,而且每个分区写一个load data,很繁琐。使用动态分区可解决以上问题,其可以根据查询得到的数据动态分配到分区里。其实动态分区与静态分区区别就是不指定分区目录,由系统自己选择。
首先,启动动态分区功能
注意,动态分区不允许主分区采用动态列而副分区采用静态列,这样将导致所有的主分区都要创建副分区静态列所定义的分区。
动态分区可以允许所有的分区列都是动态分区列,但是要设置一个参数:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nostrick;

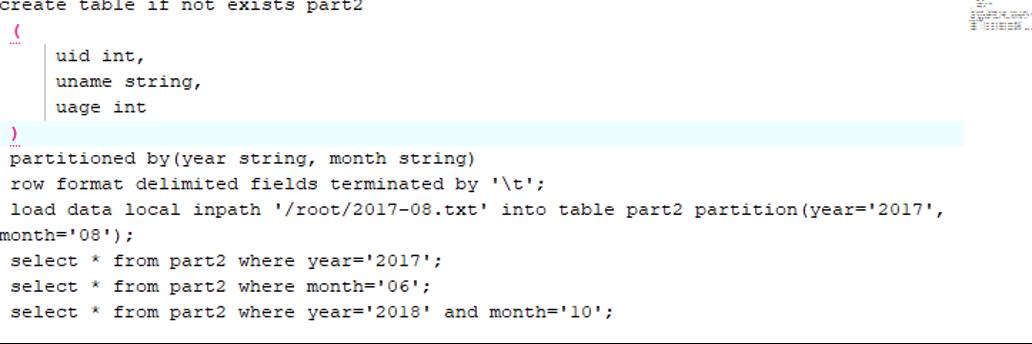
hive的分区使用的是外表字段,并且是一个伪列,可以用于查询过滤条件,但不会存储实际的值
hive的分区名不准使用中文
Hive表的分桶
一、什么是数据分桶?
二、数据分桶的作用
三、如何创建一个分桶表
四、对分桶表进行的数据抽样
一、什么是数据分桶?
Hive是基于Hadoop的一个数据仓库,可将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。Hive的本质是将HiveSQL语句转化成MapReduce任务执行。
Hive中,分区提供了一个隔离数据和优化查询的便利方式,不过并非所有的数据都可形成合理的分区,尤其是需要确定合适大小的分区划分方式(有的数据分区数据过大,有的很少,即我们常说的数据倾斜)
我们可以将Hive中的分桶原理理解成MapReduce中的HashPartitioner的原理。都是基于hash值对数据进行分桶。
MR:按照key的hash值除以reduceTask个数进行取余(reduce_id = key.hashcode % reduce.num)
Hive:按照分桶字段(列)的hash值除以分桶的个数进行取余(bucket_id = column.hashcode % bucket.num)
二、数据分桶的作用
2.1 数据抽样
在处理大规模数据集时,尤其载数据挖掘的阶段,可以用一份数据验证一下,代码是否可以运行成功,进行局部测试,也可以抽样进行一些代表性统计分析。
2.2 map-side join
可以获得更高的查询处理效率。桶为表加上了额外的结构,(利用原有字段进行分桶),Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
查看sampling数据:select * from student tablesample(bucket 1 out of 32 on id);
三、创建分桶表:
- ‘set hive.enforce.bucketing = true’(临时设置,退出终端,再打开就会恢复false)。这个打开后,会自动根据bucket个数自动分配Reduce task个数,reduce个数和buckert个数一样。
2.建表

3.导入数据:insert into test_bucket select * from need_bucket cluster by (id)
4、对分桶表进行的数据抽样

y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了12份,当y=24
时,抽取(64/32=)2个bucket的数据,当y=128时,抽取(641/128=)1/2个bucket的数据。x表示从哪个bucket开始
抽取。例如,table总bucket数为32,tablesample(bucket 2 out of 16),表示总共抽取(32/16=)2个bucket的数
据,分别为第1个bucket和 ]m 第(1+16)17个bucket的数据。 41/32=1/8buckets。
桶的概念就是MapReduce的分区的概念,两者完全相同。物理上每个桶就是目录里的一个文件,一个作业产生的桶(输出文件)数量和reduce任务个数相同。
而分区表的概念,则是新的概念。分区代表了数据的仓库,也就是文件夹目录。每个文件夹下面可以放不同的数据文件。通过文件夹可以查询里面存放的文件。但文件夹本身和数据的内容毫无关系。
桶则是按照数据内容的某个值进行分桶,把一个大文件散列称为一个个小文件。
这些小文件可以单独排序。如果另外一个表也按照同样的规则分成了一个个小文件。两个表join的时候,就不必要扫描整个表,只需要匹配相同分桶的数据即可。效率当然大大提升。
同样,对数据抽样的时候,也不需要扫描整个文件。只需要对每个分区按照相同规则抽取一部分数据即可。
以上是关于《大数据开发》Hive的主要内容,如果未能解决你的问题,请参考以下文章