20172328 2018-2019《Java软件结构与数据结构》第八周学习总结
Posted lxy462283007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了20172328 2018-2019《Java软件结构与数据结构》第八周学习总结相关的知识,希望对你有一定的参考价值。
20172328 2018-2019《Java软件结构与数据结构》第八周学习总结
概述 Generalization
| 本周学习了二叉树的另一种有序扩展?是什么呢?你猜对了!ヾ(?°?°?)??就是堆。本章将讲解堆的链表实现and数组实现,以及往堆中添加元素或从堆中删除元素的算法;还将介绍对的一些用途,包括基本使用和优先队列。 |
教材学习内容总结 A summary of textbook
- 堆(heap)就是具有两个附加属性的一颗二叉树:
- 第一点:它是一颗完全二叉树 ,即叶子节点都在最后一层靠左侧。
- 第二点:对每一结点,它小于(大于)或等于其左孩子和右孩子。
- 第二点中满足大于的条件下形成的是一个最大堆(大顶堆),反之则为最小堆(小顶堆)。
- 最小堆将其最小元素存储在该二叉树的根处,且其跟的两个孩子同样还是最小堆。
堆中的操作:

- addElement操作:
addElement方法将给定的Comparable元素添加到堆的恰当位置处,且维持该堆的完全性属性和有序属性。
- Little Tip:完全树你还记得吗?完全二叉树就是所有叶子都位于h或者h-1层,其中h为log2(n),且n为树中的元素数目,h层的所有叶子都位于该树的左边,那么该树被认为是完全的。
- 堆就是一棵完全的二叉树,所以对于插入的新结点只存在一个正确的位置。要么是h层左边的下一个空位置,要么是h+1层左边的第一个位置(如果h层为满的话)。
- 将新结点定位到正确的位置后,我们就必须对这个堆进行排序来保持其有序属性。方法就是对树中的最末一片叶子进行跟踪记录,在一个addElement方法后,最末结点就被设定为插入结点。也就是通过上溯树来保证树的有序性.
- removeMin操作:
- removeMin方法将删除最小堆中的最小元素并返回它,由于最小元素是存储在最小堆的根处,所以我们需要返回储存在根处的元素并用堆中的另一元素替换它。
- 要维持该树的完全性,就是把储存在树中最末一片叶子上的元素用来替换根元素。
- 将存储在最末一片叶子上的元素移动到根处,就必须对该堆进行重新排序来维持该堆的排序属性。
- 要维持该堆的排序属性,就要从根结点下溯树。具体过程是将该新根元素与其较小的孩子进行比较,且如果孩子更小就将它们互换,沿着树向下继续这一过程,直至该元素要么位于某一叶子中,要么比它的两个孩子都小。
- findMin操作:
- findMin将返回一个指向最小堆中最小元素的引用,由于最小堆的最小元素就在根处,所以直接返回存储在根处的元素即可。
- 使用堆——堆排序heapSort:
- 堆排序是对简单选择排序的一种改进。
- 改进着眼点:如何减少关键字的比较次数
- 简单选择排序在一趟排序中仅选出最小关键字,但是没有把一趟比较结果保存下来,因而比较次数较多。
- 堆排序在选出最小关键字同时,也找出较小的关键字,从而减少了后面选择中的比较次数,提高了整个排序效率。
- 左右子树都是大顶堆,如何调整根结点,使得整棵树成为一个堆?
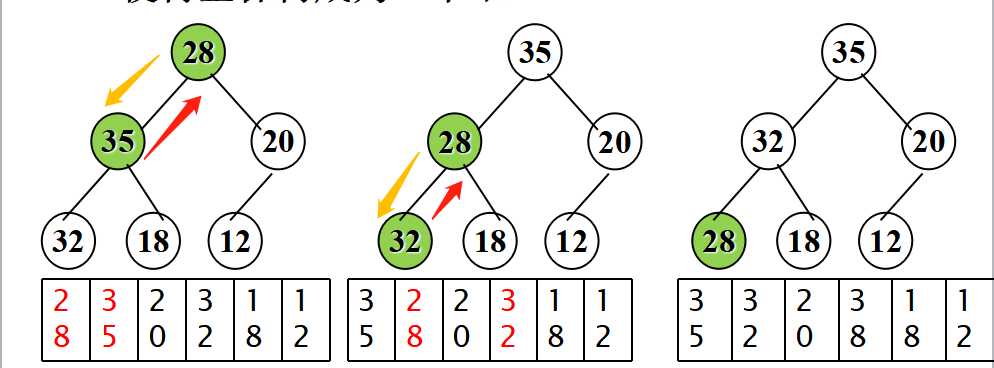
- 堆调整 —— 筛选过程
- 调整过程中,总是将根结点(被调整结点)与左右孩子比较;
- 不满足堆条件时,将根结点与左右孩子中较大者交换;
- 这个调整过程一直进行到所有子树都是堆或者交换到叶子为止。
- 这个从堆顶到叶子的调整过程称为“筛选”。
- 对堆进行筛选完毕之后我们就要为保持其有序性而开始排序。
- 堆排序-排序过程
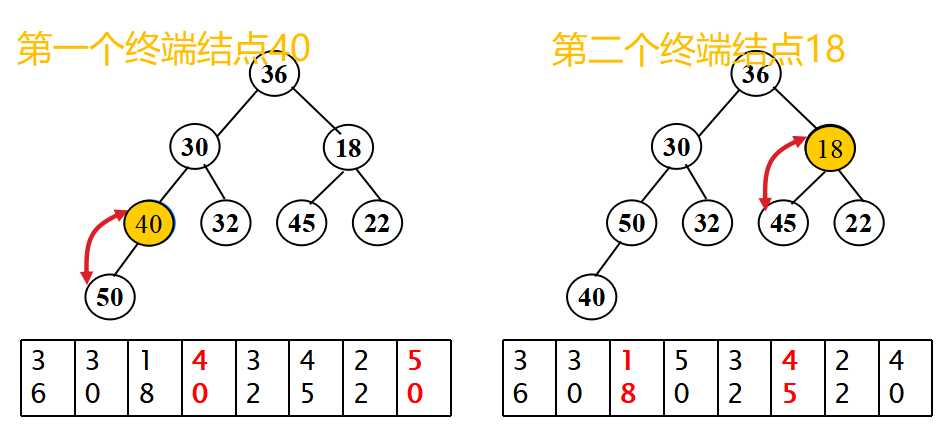
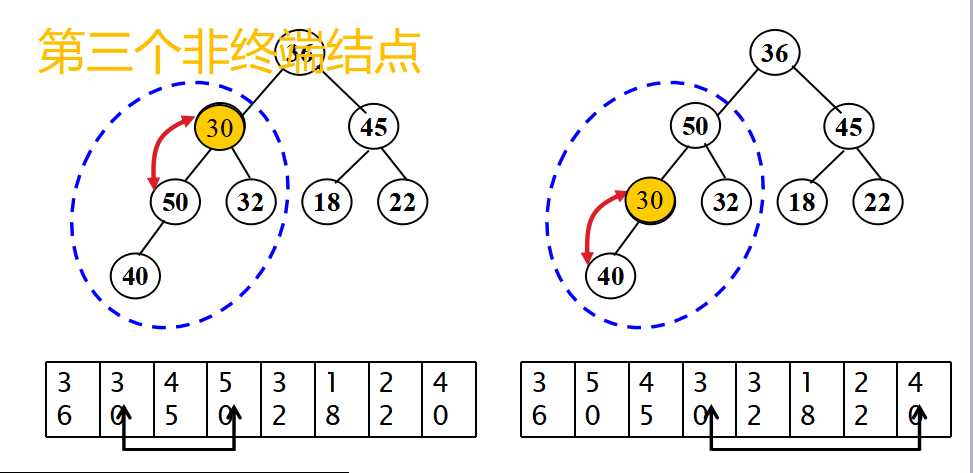
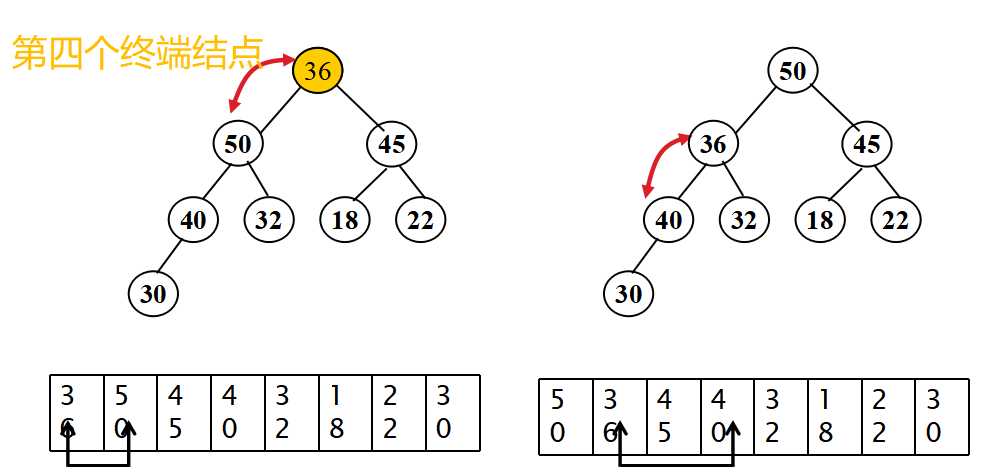
- 从无序序列的第[n/2]个元素开始(对应于完全二叉树的最后一个非终端结点)进行筛选;
- 当解决一个非终端结点(非叶子结点)的有序问题后,把此非终端结点看做一个叶子,然后继续上溯,找到倒数第二个非终端结点,继续进行有序替换,知道整个堆有序为止。
- heapSort的复杂度为O(nlogn)
- 使用堆:优先级队列
- 优先级队列(Priority queue)就是遵循两个排序规则的集合。
- 首先,具有更高优先级的项目在先。
其次,具有相同优先级的项目使用先进先出方法来确定其排序。
- 用链表实现堆:
- 因为我们要求在插入元素后能够向上遍历该树,所以堆中的结点必须存储在指向其双亲的指针。所以我们从创建一个HeapNode类开始我们的链表实现,该类对BinaryTreeNode进行了拓展并添加了一个双亲指针。
- 链表实现的实例数据由指向HeapNode且称为lastNode的单个引用组成,这样我们就能够跟踪记录该堆中最末一片叶子。
public HeapNode lastNode; - addElement操作:
- 在恰当的位置添加一个新元素
- 对堆进行重排序以维持其排序属性
- 将lastNode指针重新设定指向新的最末结点
- removeMin操作:
- 用存储在最末结点处的元素替换存储在根处的元素
- 对堆进行重排序
- 返回原始的根元素
- findMin操作:
- 该方法仅仅返回一个指向存储在堆根处元素的引用,因此复杂度为O(1)。
- 用数组实现堆:
- 用数组实现堆不再需要创建一个HeapNode类对,而是通过用数组来保存堆中的数据。
- 在二叉树的数组实现中,树的根位于位置0处,对于每一结点n,n的左孩子将位于数组的2n+1处,右孩子将位于数组的2n+2处。
- addElement操作:
- 在恰当的位置添加一个新元素
- 对堆进行重排序以维持其排序属性
- 将count递增1.
- removeMin操作:
- 用存储在最末结点处的元素替换存储在根处的元素
- 对堆进行重排序
- 返回原始的根元素
- findMin操作:
- 返回指向存储在堆的根处或数组0位置处的元素。
总结:链表实现和数组实现的addElement方法和removeElement方法时间复杂度都是O(logn)。但是,数组的实现还是更高效一些,因为在addElement操作中数组实现不用去确定插入双亲的结点,在removeElement操作中数组实现不需要确定新的最末一片叶子。
教材学习中的问题和解决过程 Problem and countermeasure
- 问题1:周四晚上看用链表实现堆的添加操作代码。刚刚看懂小伙伴仇夏来找我讨论,讨论了一会瞬间觉得自己没有真正看懂,那段奇妙的代码如下:
private HeapNode<T> getNextParentAdd()
{
HeapNode<T> result = lastNode;
while ((result != root) && (result.getParent().getLeft() != result))
result = result.getParent();
if (result != root)
if (result.getParent().getRight() == null)
result = result.getParent();
else
{
result = (HeapNode<T>)result.getParent().getRight();
while (result.getLeft() != null)
result = (HeapNode<T>)result.getLeft();
}
else
while (result.getLeft() != null)
result = (HeapNode<T>)result.getLeft();
return result;
}这段代码是返回将要插入结点的双亲结点的方法,当时我和仇夏讨论的是有两种情况。因为我们知道插入操作为了保证树的完全性,所以要在h层的从左开始数的第一个空结点插入或者在h+1层的最左边插入(如果树是满的话),但是在循环体中不满足我们的要求。
- 问题1的解决:
问题的重点是“下一个将要插入结点的双亲结点”,之前一直理解的是新插入结点的双亲结点,所以当然不对。在理解正确之后,画出几种插入的可能情况,再跟着上述代码理解几遍,就慢慢清晰明朗了。
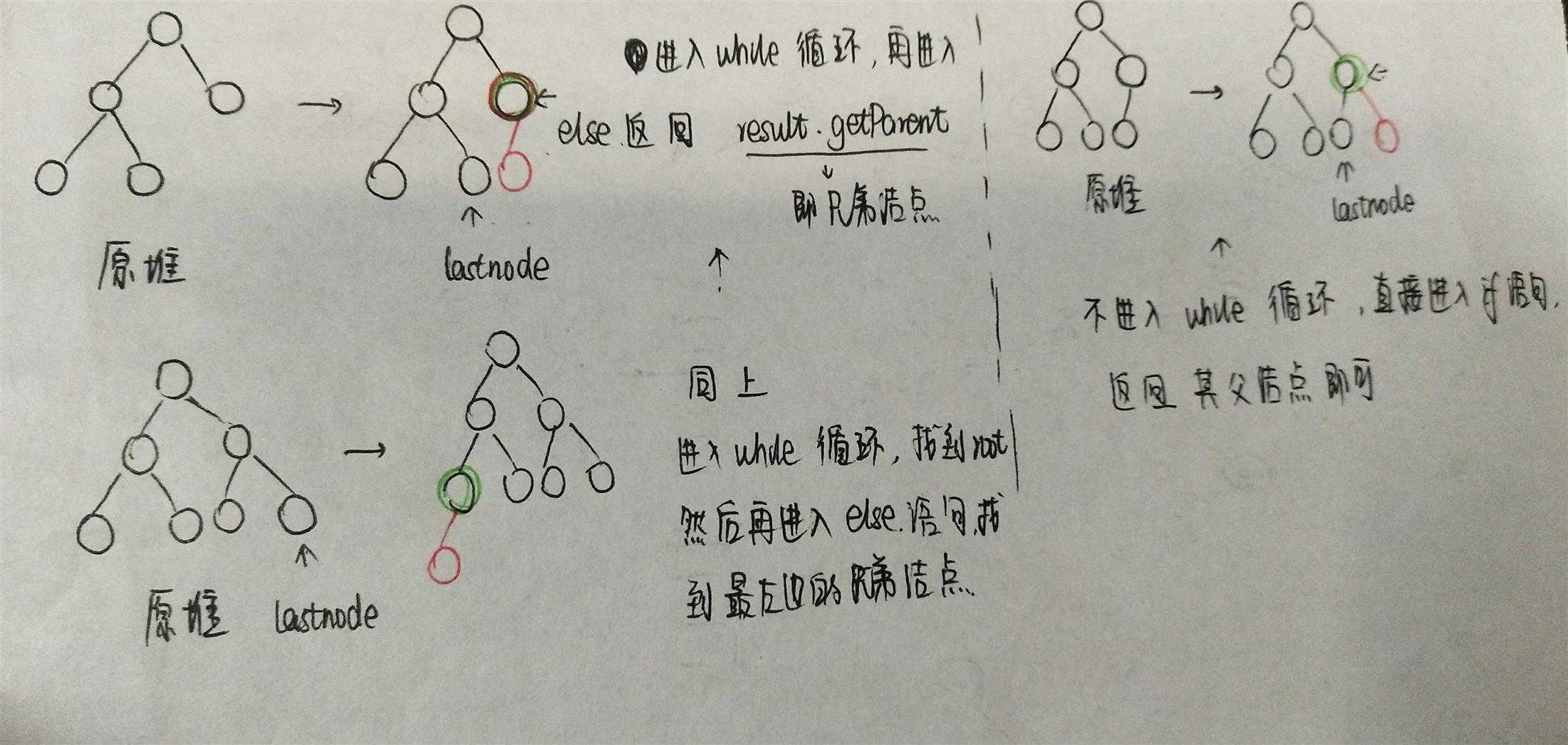
- 问题2:之前在学习栈的时候感觉一直在和堆一起被提起,所以堆和栈之间到底是什么关系?
- 问题2的解决:
- 简单的说: Java把内存划分成两种:一种是栈内存,一种是堆内存。
- 在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。 当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
- 堆内存用来存放由new创建的对象和数组。在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
- 堆和栈的区别比较:
- 1.栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
- 2.栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享,详见第3点。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
- 3.Java中的数据类型有两种。 一种是基本类型(primitive types), 共有8种,即int, short, long, byte, float, double, boolean, char(注意,并没有string的基本类型)。这种类型的定义是通过诸如
int a = 3;long b = 255L;的形式来定义的,称为自动变量。值得注意的是,自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。
代码实现时的问题作答 Exercise
- 问题1:用堆实现队列?树中给的堆是由数组和链表实现的,那么我们应该用ArrayHeap还是Linkedheap实现呢?又该如何实现?
- 问题1的解决:首先,我们知道在第十章中队列的实现可以由链表或者循环数组实现,并且堆可以由链表和数组实现,因此是否可以推出队列可以由数组实现的堆或者链表实现的堆来实现呢?
首先,我先用链表实现的堆来实现队列。通过在enqueue方法中调用addElement方法,就能够实现队列的入队,但是在入队后进行了堆的插入中的排序?队列是符合先进先出原则的,那么我就修改了堆中的插入方法,将其中的排序删掉。同理,当出队时也不应该去考虑排序的问题。但是当我删除掉删除的排序后,再执行删除队列中前两个元素,我却发现删除的并不一定是队列的前两个值,反而删除掉了最开始跟的值和最末一个叶子,这是由堆的性质决定的。所以想要保持先进先出,我们就要找到堆顶的左孩子然后删除。所以我们需要改变一下堆中的排序方法。链表的实现方法很麻烦,而且要改变删除的排序算法需要考虑很多种情况,在做了两小时还是不能完整正确的情况下,让我们把目光投向数组。
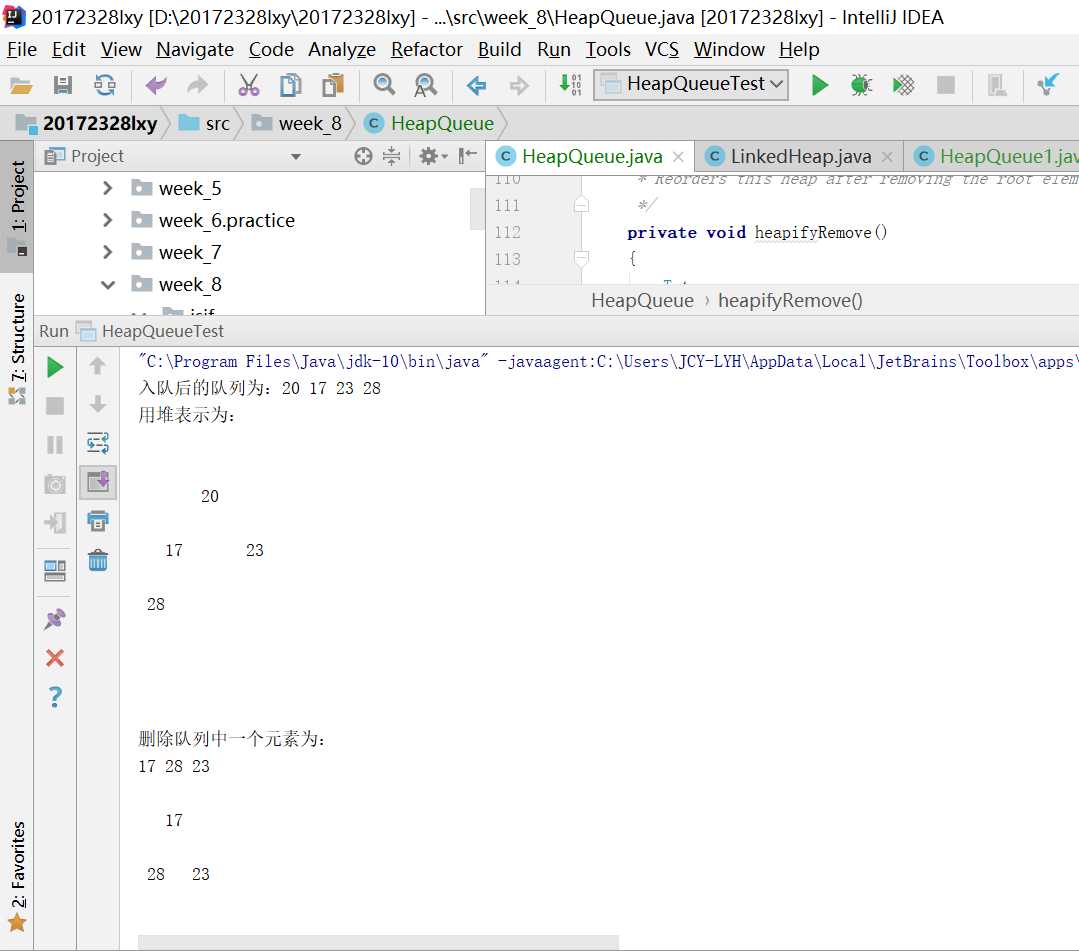
数组中只需要将删除后的最末结点变成null就可以达到效果。
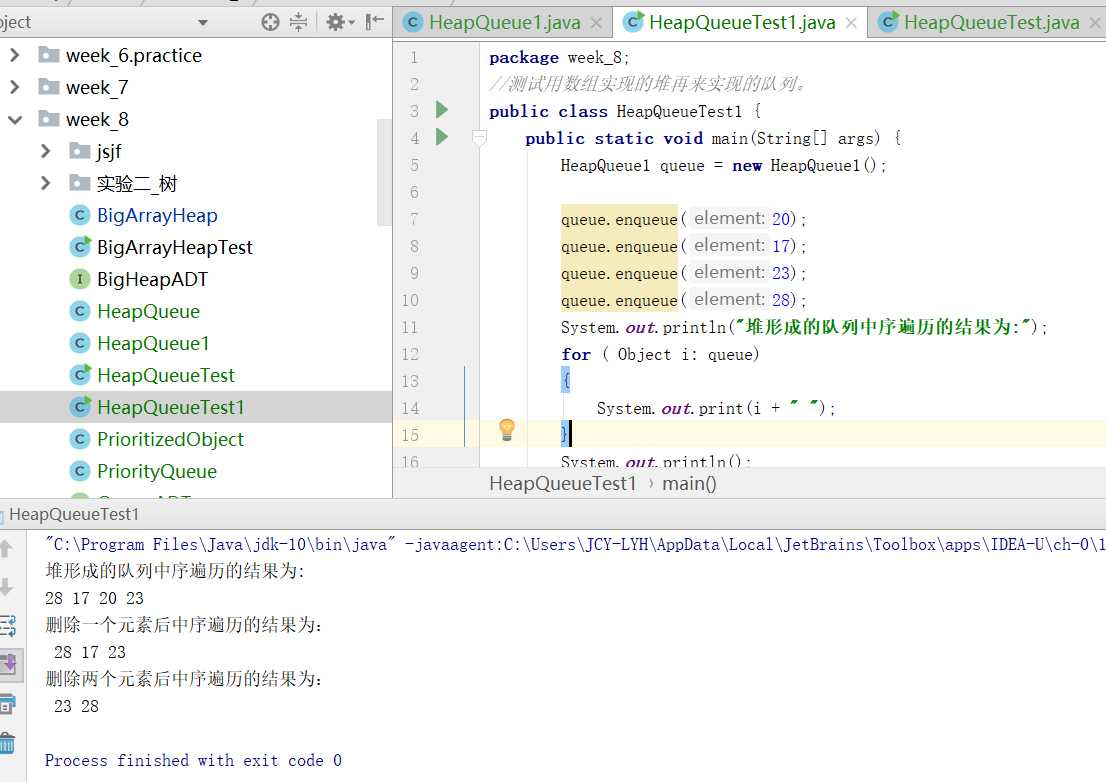
上周测试活动错题改正 Correction
- 1.In removing an element from a binary search tree, another node must be ___________ to replace the node being removed.
A .duplicated
B .demoted
C .promoted
D .None of the above - 正确答案选 B。当在二叉查找树上删除一个结点时,后面的结点需要向上移动来补全。当时,以为越靠近根结点说明深度越低,所以是降级了;但是看完答案好像人家的意思是向上补全。题意理解不准确哈哈
- 2.In removing an element from a binary search tree, another node must be demoted to replace the node being removed.
A .True
B .Flase - 正确答案选 A ,和第一题一模一样好吗?哭
- 3.One of the uses of trees is to provide simpler implementations of other collections.
A .True
B .Flase - 正确答案选 B 。这道题确实是我自己不太懂的。通过搜索得知,java中树的应用主要有:菜单树,还有权限树,商品分类列表也是树结构。在这几章的学习中,好像确实没有通过树来简单实现其他集合,树提供的方便性可以用于查找、排序等等。
- 4.Insertion sort is an algorithm that sorts a list of values by repetitively putting a particular value into its final, sorted, position.
A .true
B .false - 正确答案选 B ,我当时选了A。我觉得还是题意理解的问题。我理解的题意是“插入排序是一种重复的将特殊值插入后面,然后排序,然后安置的算法”我觉得插入排序就是这样一个流程,所以我也不知道出现了什么问题。
码云链接
代码量(截图)
结对及互评Group Estimate
点评模板:
- 博客中值得学习的或问题:
- 20172301:
- 20172304:
其他(感悟、思考等,可选)Else
Crossing miles of frustrations and rivers a raging,picking up stones I found along the way.
怕不轻松,怕太轻松。
再也不用觉得工作日长,因为每天好像都是工作日。想忙里偷闲就忙里偷闲,想抓紧做事就抓紧做事。
我将每天告诉自己:请对专业课程更加虔诚一点。
学习进度条Learning List
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | |
|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 |
| 第一周 | 0/0 | 1/1 | 8/8 |
| 第二周 | 621/621 | 1/2 | 12/20 |
| 第三周 | 678/1299 | 1/3 | 10/30 |
| 第四周 | 2734/4033 | 1/4 | 20/50 |
| 第五周 | 1100/5133 | 1/5 | 20/70 |
| 第六周 | 1574/6707 | 2/7 | 15/85 |
| 第七周 | 1803/8510 | 1/8 | 20/105 |
| 第八周 | 2855/11365 | 2/10 | 25/130 |
参考资料Reference
- [Java软件结构与数据结构](第四版)
- 堆这种数据结构
- 让你彻底明白JAVA中堆与栈的区别
- java数据结构:基于树的堆
以上是关于20172328 2018-2019《Java软件结构与数据结构》第八周学习总结的主要内容,如果未能解决你的问题,请参考以下文章
20172328 2018-2019《Java软件结构与数据结构》第九周学习总结
20172328 2018-2019《Java软件结构与数据结构》第八周学习总结
20172328 2018-2019《Java软件结构与数据结构》第六周学习总结