spark浅谈:RDD
Posted bigdata-stone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark浅谈:RDD相关的知识,希望对你有一定的参考价值。
一、弹性分布式数据集
1.弹性分布式数据集(RDD)是spark数据结构的基础。它是一个不可变的分布式对象的集合,RDD中的每个数据集都被划分为一个个逻辑分区,每个分区可以在集群上的不同节点上进行计算。RDDs可以包含任何类型的Python,Java或者Scala对象,包括用户自定义的类。
2.正常情况下,一个RDD是一个只读的记录分区集合。RDDs可以通过对稳定存储数据或其他RDDs进行确定性操作来创建。RDD是一个可以在并行操作期间自动容错的元素的集合。发生错误之后可以进行重复的计算
3.创建RDD的方式:(1)在驱动程序中并行化现有的集合;(2)引用外部存储系统中的数据集。例如文件共享系统、HDFS、HBase、或者可以提供Hadoop输入格式的数据源
二、MapReduce的数据共享
1.MapReduce广泛应用于集群上使用分布式的并行算法来处理和生成大型数据集。允许用户使用高级运算符编写代码进行并行计算。而不需要担心工作分布和容错。
2.不幸的是,在最近使用的大多数框架中,在计算资源之间重用数据的唯一方式是将其写入到外部的稳定的存储系统中,,比如HDFS。
3.迭代式开发和交互式应用在并行作业中需要更快的数据共享。数据共享在MapReduce中是比较慢的,主要是因为其副本、串行化和磁盘IO。尽管有存储系统存在,但是大多数的Hadoop应用会划分超过90%的时间来做HDFS的读写操作
三、MapReduce的迭代式操作
1.交互过程
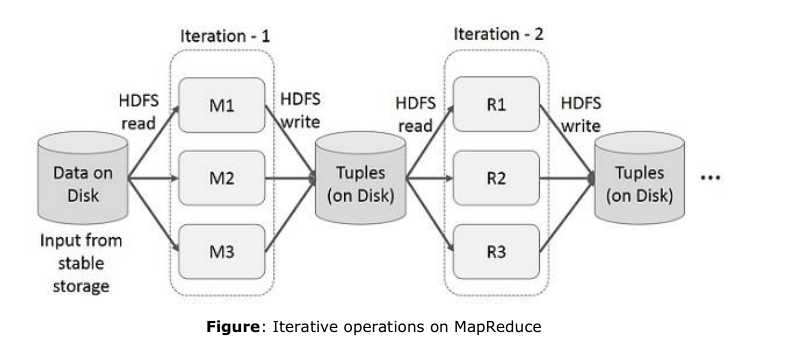
HDFS从稳定的输入流中读取数据,分成3个副本,在Iteration-1过程之后将其写入磁盘,多级MR是hadoop慢的主要原因。
2.使用sparkRDD进行数据共享
在MapReduce上数据共享慢的原因是因为副本,串行化以及磁盘IO。对于大多数Hadoop应用而言,它们花费超过90%的时间在左HDFS读写操作。认识到这个问题之后。研究人员们研发出来一个特殊的框架称之为Apache Spark。spark的核心思想是弹性分布式数据集(Resilient Distributed Datasets 简称RDD)。它支持在内存中进行计算的处理。这意味着它存储内存的状态作为对象,可以在作业之间跨作业和共享的对象。作业共享在内存中要比磁盘块10倍到100倍
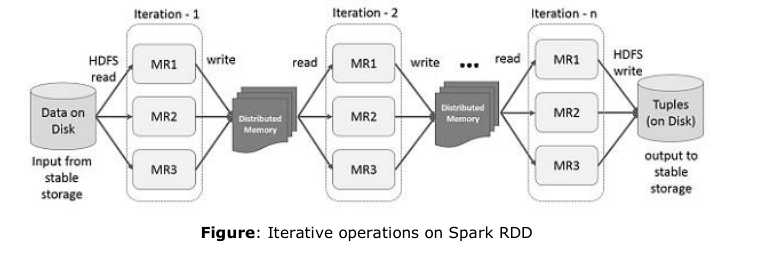
3.在Spark RDD上的迭代式操作
下面的简图展示了在Spark RDD上的迭代式操作,它会存储中间结果在分布式内存而不是稳定的存储设备(比如磁盘)来使得系统更快。注意:如果分布式内存不足以存储中间结果(JOB的工作状态)
4.在Spark RDD上的交互操作
如果不同的查询运行在同一个数据集上,这个特殊的数据可以保存在内存上等待更好的执行时间
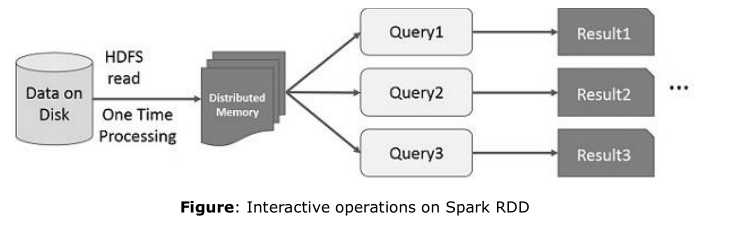
默认情况下,每一个变换的RDD在你运行一个Action的时候可以进行重复计算,你也可以在内存中持久化运算的结果,在这种情况下,Spark会继续在集群上保持元素以得到下次访问更快的处理,也支持在磁盘中持久化数据,或者通过众多的节点来进行复制
以上是关于spark浅谈:RDD的主要内容,如果未能解决你的问题,请参考以下文章