浅谈Spark中Job-Stage-Task之间的关系
Posted <一蓑烟雨任平生>
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈Spark中Job-Stage-Task之间的关系相关的知识,希望对你有一定的参考价值。
(1)Spark-Job-Stage-Task之间的关系
在开始之前需要先了解Spark中Application,Job,Stage等基本概念,官方给出的解释如下表:
| Term | Meaning |
|---|---|
| Application | 用户编写的Spark应用程序,包括一个Driver和多个executors |
| Driver Program | 运行main()函数并创建SparkContext进程 |
| Cluster manager | 在集群上获取资源的外部服务,如standalone ,yarn,Mesos |
| worker node | 集群中可以运行程序代码的节点(机器) |
| Executor | 运行在worker node上执行具体的计算任务,存储数据的进程 |
| Task | 被分配到一个Executor上的计算单元 |
| Job | 由多个任务组成的并行计算阶段,因RDD的Action产生 |
| Stage | 每个Job被分为小的计算任务组,每组称为一个stage |
| DAGScheduler | 根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler |
| TaskScheduler | 将TaskSet提交给worker运行,每个executor运行什么task在此分配 |
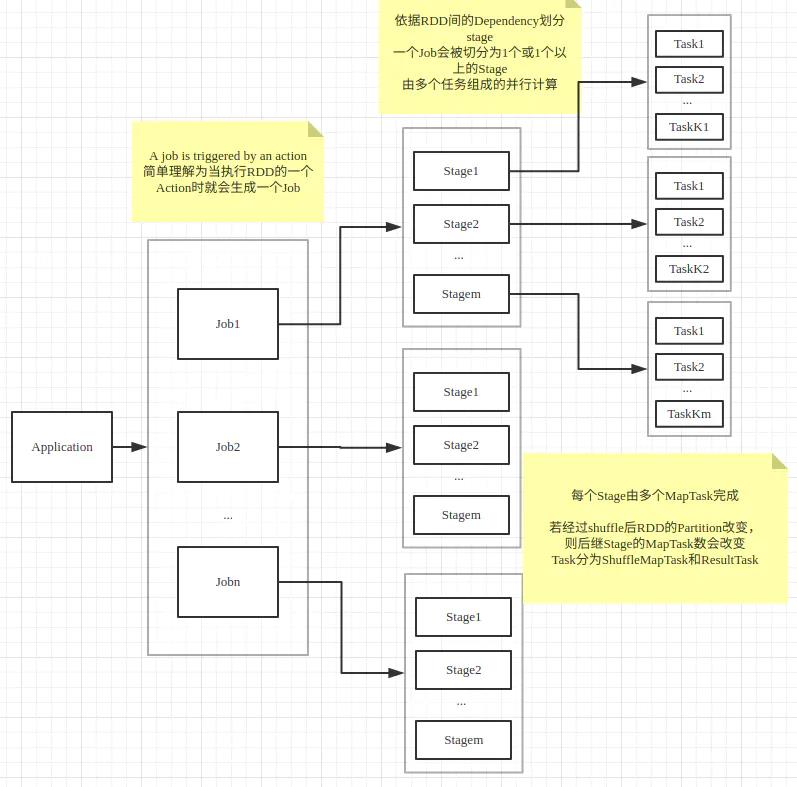
如下图所示,一个Spark程序可以被划分为一个或多个Job,划分的依据是RDD的Action算子,每遇到一个RDD的Action操作就生成一个新的Job。
每个spark Job在具体执行过程中因为shuffle的存在,需要将其划分为一个或多个可以并行计算的stage,划分的依据是RDD间的依赖关系,当遇到宽依赖(Wide Dependency)时因需要进行shuffle操作,这涉及到了不同Partition之间进行数据合并,故以此为界划分不同的Stage。Stage是由Task组组成的并行计算,因此每个stage中可能存在多个Task,这些Task执行相同的程序逻辑,只是它们操作的数据不同。一般RDD的一个Partition对应一个Task,Task可以分为ResultTask和ShuffleMapTask。
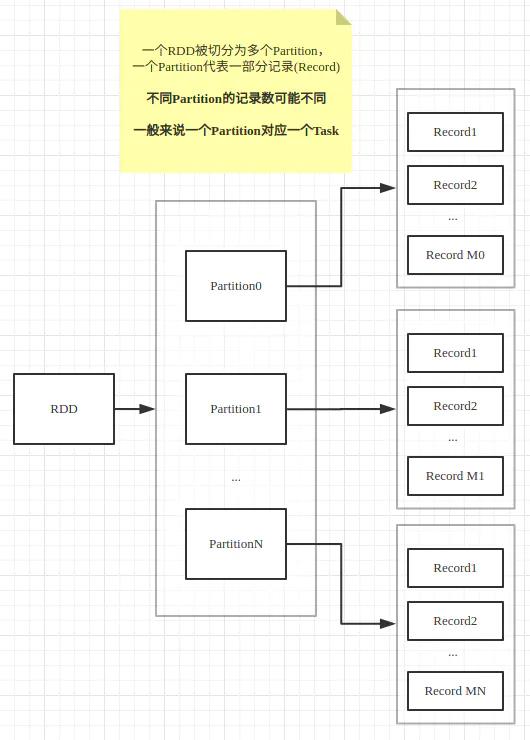
(2)RDD-Partition-Records-Task之间的关系
通常一个RDD被划分为一个或多个Partition,Partition是Spark进行数据处理的基本单位,一般来说一个Partition对应一个Task,而一个Partition中通常包含数据集中的多条记录(Record)。 注意不同Partition中包含的记录数可能不同。Partition的数目可以在创建RDD时指定,也可以通过reparation和coalesce等算子重新进行划分。
通常在进行shuffle的时候也会重新进行分区,这是对于key-value RDD,Spark通常根据RDD中的Partitioner来进行分区,目前Spark中实现的Partitioner有两种:HashPartitioner和RangePartitioner,当然也可以实现自定义的Partitioner,只需要继承抽象类Partitioner并实现numPartitions and getPartition(key: Any)即可。
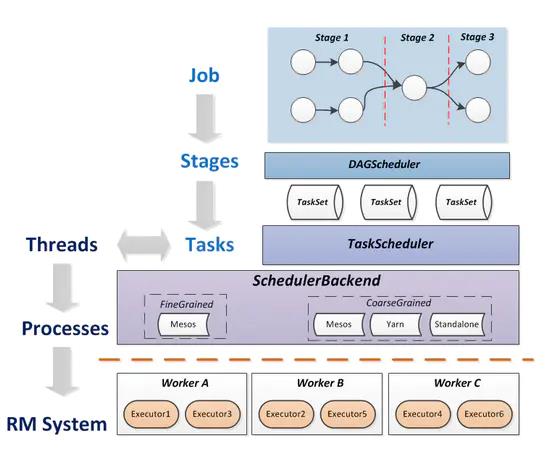
将上面的概念串联起来,可以得到下面的运行层次图:
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!
以上是关于浅谈Spark中Job-Stage-Task之间的关系的主要内容,如果未能解决你的问题,请参考以下文章