Bloom Filter解析
Posted jiweilearn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Bloom Filter解析相关的知识,希望对你有一定的参考价值。
布隆过滤器简介:https://www.cnblogs.com/Jack47/p/bloom_filter_intro.html
布隆过滤器详解:原文链接:http://www.cnblogs.com/allensun/archive/2011/02/16/1956532.html
布隆过滤器解析:https://www.cnblogs.com/liyulong1982/p/6013002.html
布隆过滤器 (Bloom Filter)是由Burton Howard Bloom于1970年提出,它是一种space efficient的概率型数据结构,用于判断一个元素是否在集合中。在垃圾邮件过滤的黑白名单方法、爬虫(Crawler)的网址判重模块中等等经常被用到。哈希表也能用于判断元素是否在集合中,但是布隆过滤器只需要哈希表的1/8或1/4的空间复杂度就能完成同样的问题。布隆过滤器可以插入元素,但不可以删除已有元素。其中的元素越多,false positive rate(误报率)越大,但是false negative (漏报)是不可能的。
本文将详解布隆过滤器的相关算法和参数设计,在此之前希望大家可以先通过谷歌黑板报的数学之美系列二十一 - 布隆过滤器(Bloom Filter)来得到些基础知识。
简单的布隆过滤器不支持删除一个元素,因为“漏报”是不允许的。一个元素映射到k位,尽管设置这k位中任意一位为0就能够删除这个元素,但也会导致删除其他可能映射到这个位置的元素。因为没办法决定是否有其他元素也映射到了需要删除的这一位上。
通过好几个哈希函数来共同判断这个元素是否在集合里,比只用一次哈希带来冲突的可能性要低很多。暴雪的MPQ归档文件中使用的哈希算法跟布隆过滤器也有异曲同工之妙。
一个空的布隆过滤器是一个m位的位数组,所有位的值都为0。定义了k个不同的符合均匀随机分布的哈希函数,每个函数把集合元素映射到位数组的m位中的某一位。
添加一个元素:
先把这个元素作为k个哈希函数的输入,拿到k个数组位置,然后把所有的这些位置置为1。
查询一个元素(测试这个元素是否在集合里):
把这个元素作为k个哈希函数的输入,得到k个数组位置。这些位置中只要有任意一个是0,元素肯定不在这个集合里。如果元素在集合里,那么这些位置在插入这个元素时都被置为1了。如果这些位置都是1,那么要么元素在集合里,要么所有这些位置是在其他元素插入过程中被偶然置为1了,导致了一次“误报”。
一个布隆过滤器的例子见下图,代表了集合{x,y,z}。带颜色的箭头表示了集合中每个元素映射到位数组中的位置。元素w不在集合里,因为它哈希后的比特位置中有一个值为0的位置。在这个图里,m=18,k=3。

一个布隆过滤器的例子
简单的布隆过滤器不支持删除一个元素,因为“漏报”是不允许的。一个元素映射到k位,尽管设置这k位中任意一位为0就能够删除这个元素,但也会导致删除其他可能映射到这个位置的元素。因为没办法决定是否有其他元素也映射到了需要删除的这一位上。
通过好几个哈希函数来共同判断这个元素是否在集合里,比只用一次哈希带来冲突的可能性要低很多。暴雪的MPQ归档文件中使用的哈希算法跟布隆过滤器也有异曲同工之妙。
误判率
误判率就是在插入n个元素后,某元素被判断为“可能在集合里”,但实际不在集合里的概率,此时这个元素哈希之后的k个比特位置都被置为1。
假设哈希函数等概率地选择每个数组位置,即哈希后的值符合均匀分布,那么每个元素等概率地哈希到位数组的m个比特位上,与其他元素被哈希到哪些位置无关(独立事件)。设定数组总共有m个比特位,有k个哈希函数。在插入一个元素时,一个特定比特没有被某个哈希函数置为1的概率是:
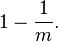
插入一个元素后,这个比特没有被任意哈希函数置为1的概率是:
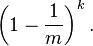
在插入了n个元素后,这个特定比特仍然为0的概率是:
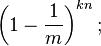
所以这个比特被置为1的概率是:
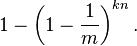
现在检测一个不在集合里的元素。经过哈希之后的这k个数组位置任意一个位置都是1的概率如上。这k个位置都为1的概率是:
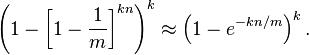
哈希函数个数的最优解
对于给定的m和n,让“误报率”最小的k值为:
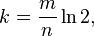
此时“误报率”为:
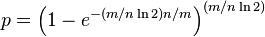
可以简化为:
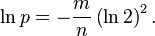
在leveldb中,设定的误判率<=1%,所以m/n是9.6,即10个比特,此时k=6.72,即7bit,即需要7次hash,每个元素占7bit,总共需要m=n*9.6个比特作为布隆过滤器的位数组数据。
优点
- 存储空间和插入/查询时间都是常数,远远超过一般的算法
- Hash函数相互之间没有关系,方便由硬件并行实现
- 不需要存储元素本身,在某些对保密要求非常严格的场合有优势
缺点
- 有一定的误识别率
- 删除困难
应用
- 搜索引擎中的海量网页去重
- leveldb等数据库中快速判断元素是否存在,可以显著减少磁盘访问
下一篇文章会介绍布隆过滤器在leveldb中的实现和应用
回到本系列目录:leveldb源码学习系列
参考资料:
- Bloom Filter
- Whay Bloom filters work the way they do
- BloomFilter–大规模数据处理利器
- Bloom Filter概念和原理
- 海量数据处理之Bloom Filter详解
以上是关于Bloom Filter解析的主要内容,如果未能解决你的问题,请参考以下文章