ECCV 2018 | 给Cycle-GAN加上时间约束,CMU等提出新型视频转换方法Recycle-GAN
Posted alan-blog-tsinghua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ECCV 2018 | 给Cycle-GAN加上时间约束,CMU等提出新型视频转换方法Recycle-GAN相关的知识,希望对你有一定的参考价值。
CMU 和 Facebook 的研究者联合进行的一项研究提出了一种新型无监督视频重定向方法 Recycle-GAN,该方法结合了时间信息和空间信息,可实现跨域转换,同时保留目标域的风格。相较于只关注空间信息的Cycle-GAN,在视频转换中Recycle-GAN的过渡效果更加自然。
项目展示:http://www.cs.cmu.edu/~aayushb/Recycle-GAN/
该研究提出一种用于视频重定向的无监督数据驱动方法,该方法能够在保持目标域风格不变的基础上,将一个域的连续内容迁移到另一个域中。这样的内容转换(content translation)和风格保存(style preservation)任务有很多应用,包括人体动作和人脸转换(face translation)、教机器人模仿人类,或者将黑白视频转换为彩色。这项研究还可用来创建在现实世界中难以捕捉或标注的视觉内容,例如:对齐虚拟世界中两个人的肢体动作和面部数据,或者为自动驾驶汽车标注夜间数据。最重要的是,内容转换和风格保存的概念超越了从像素到像素的操作,成为更加语义化和抽象化的概念,更方便人类理解。
目前重定向的方法大致可分为三类。第一类是专门为人脸设计的 [5,41,42]。虽然这些方法在人脸完全可视的条件下表现很好,但不适于面部有遮挡的情况(虚拟现实),并且缺乏向其他域泛化的能力。(第二类)虽然成对图像转换的研究 [23] 试图实现跨域泛化,但也需要对标注和对齐进行人工监督,而很多领域无法实现手动校对或标记。第三类方法尝试无监督和非成对的图像转换 [26 ,53]。他们对非成对的 2D 图像执行循环一致性(cyclic consistency),并学习从一个域到另一个域的转换。然而,非成对的 2D 图像不足以实现视频重定向。首先,它不能充分约束优化,常常会导致极差的局部极小值或感知模式崩溃,难以在目标域中生成所需的输出。第二,只利用 2D 图像的空间信息很难学习到特定域的风格,因为风格信息也需要时间信息。
研究者在该研究中做了两项观察:(1)时间信息的利用为优化从一个域到另一个域的转换提供了更多的约束,有助于得到更好的局部极小值;(2)时间和空间约束的结合有助于学习到给定域的风格特征。重要的是,时间信息在视频中是可以免费获取的(在网页中可以获得大量此类信息),因此无需人工监督。图 1 显示了人脸和花朵的转换示例。在没有任何人工监督和特定域知识的情况下,该方法通过使用网页上来自两个域的公共视频数据,学习到了从一个域到另一个域的重定向。

图 1:本研究提出的视频重定向方法应用于人脸和花朵的示例。第一行展示了从 John Oliver 到 Stephen Colbert 的转换。第二行展示了合成的花朵跟随输入花朵绽放的过程。
该研究的贡献:介绍了一种新方法,将时空线索与条件生成对抗网络 [15] 结合起来应用于视频重定向。作者展示了在不同条件下,时空约束相比于图像到标签和标签到图像的空间约束的优势。然后,研究者展示了学习两个域之间更好关联的方法,以及它对视觉数据的自监督内容对齐的重要性。受时空恒久存在的启发,研究者定性地展示了该方法对于各种自然过程的有效性,例如人脸转换、花朵转换、合成云与风、对齐日出和日落等。
论文:Recycle-GAN: Unsupervised Video Retargeting

论文链接:https://arxiv.org/abs/1808.05174
摘要:本研究介绍了一种用于无监督视频重定向的数据驱动方法,该方法将一个域的内容转换到另一个域,同时保留目标域的原本风格,例如将 John Oliver 的演讲内容转换到 Stephen Colbert,则生成的内容/演讲应该是 Stephen Colbert 的风格。该方法结合了空间和时间信息以及内容转换和风格保存方面的对抗损失。在这项研究中,我们首先证明了使用时空约束比只使用空间约束在重定位中更具优势。然后展示了如何利用该方法处理具备时空信息的问题,例如人脸转换、花朵转换、风云合成和日出日落等。

图 2:空间循环一致性并不足够:我们展示了两个示例来说明为什么空间循环一致性不足以进行优化。(a)展示了将 Cycle-GAN [53] 应用于由特朗普到奥巴马的转换时出现感知模式崩溃的例子。第一行是输入的特朗普图像,第二行显示生成的输出。第三行显示以第二行作为输入的重输出。尽管输入不同,但第二行的几幅图像看起来很相似;第三行输出与第一行类似。经过仔细观察,我们发现第二行中只有几个像素是不同的(但看起来并不明显),而这就足以得到完全不同的重构结果;(b)图像到标签和标签到图像的例子。虽然在这两种情况下,生成器都不能为给定输入生成期望输出,但它仍能完美地重构输入。这两个例子表明,空间循环损失无法保证在另一个域中得到期望输出,因为全局优化的重点是重构输入。然而,如 (c) 和 (d) 所示,我们的方法结合空间和时间约束,得到了更好的输出。
实验
我们现在研究时空约束对空间循环约束的影响。由于我们的关键技术贡献是在学习非成对图像映射时引入时间约束,所以自然基线是 CycleGAN [53],这是一种广泛采用的方法,仅利用空间循环一致性进行非成对图像转换。我们首先在输入和输出视频之间的真值对应已知(如视频中每个帧对应一个语义标签图)的域上展示了定量结果。重要的是,该对应配对不适用于 Cycle-GAN 或 Recycle-GAN,仅用于评估。然后,我们在一组对应关系未知的视频上展示了定性结果,包括不同人脸的视频转换和自然界中的长时事件(鲜花盛开、日出/日落、随时间流逝的天气变化)。
定量分析

表 1:图像到标签(语义分割):我们使用 Viper [36] 数据集来评估使用时空约束而非空间循环一致性 [53] 时的性能改进。结果使用三种标准来判定:(1) 平均像素精度 (MP);(2) 平均分类精度 (AC);(3) IoU(Intersection over union)。可以发现,该方法比以前的研究有更好的性能,二者结合会取得更好的性能。

表 2:标签到图像的归一化 FCN 分数:我们在 Viper 数据集上使用一个预训练的 FCN-style 模型来评估合成图像的质量。在此标准上的更高性能表明特定方法生成的输出图像更接近真实图像。
定性分析

图 5:人脸到人脸转换:最上面一行展示了使用我们的方法对 John Oliver 和 Stephen Colbert 进行人脸转换的多个示例。最下面的一行是从 John Oliver 到卡通人物、从奥巴马到特朗普、从马丁?路德?金到奥巴马的人脸转换示例。没有任何输入对齐或手动监督,该方法可以捕捉到这些公众人物的面部特征。比如 John Oliver 微笑时的酒窝、特朗普特别的嘴型,以及 Stephen Colbert 的嘴型和微笑。

图 6:花到花的转换:展示了花朵转换的两个例子。从左到右的过渡非常自然。

图 8:日出和日落:我们使用该方法来处理和对齐日出和日落的视频。顶行显示日落视频的示例帧。我们基于日出的视频数据(第二行),使用我们的方法学习两个域之间的转换。第三行是新合成的日出视频的示例帧。底行展示了不同日出和日落视频中输入-输出对的随机示例。
方法

图 3:我们将这项研究与图像转换中的两个优秀方法做了对比。(a)Pix2Pix [23]:使用用成对数据。通过回归学习一个简单的函数 (Eq. 1),以映射 X → Y。(b)Cycle-GAN:使用非成对数据。Zhu 等人 [53] 提出使用循环一致性损失 (Eq. 3) 来处理非成对数据的问题。(c)Recycle-GAN:目前的方法都只考虑了独立的 2D 图像。假设我们可以获取非成对但有序的数据流 (x_1, x_2, . . . , x_t, . . .) 和 (y_1, y_2 . . . , y_s, . . .),我们提出一种结合时间与空间约束的方法 (Eq. 5)。

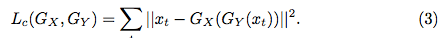


图 4:我们对比了我们的方法和 Cycle-GAN 在 image2label 和 labels2image 上的性能,实验在 Viper 数据集的留出数据上进行。
以上是关于ECCV 2018 | 给Cycle-GAN加上时间约束,CMU等提出新型视频转换方法Recycle-GAN的主要内容,如果未能解决你的问题,请参考以下文章
ECCV 2018 | 旷视科技提出GridFace:通过学习局部单应变换实现人脸校正
ECCV 2018 | UBC&腾讯AI Lab提出首个模块化GAN架构,搞定任意图像PS组合
Shangbang Long_ECCV2018_TextSnake_A Flexible Representation for Detecting Text of Arbitrary Shapes(示