ECCV 2018 | UBC&腾讯AI Lab提出首个模块化GAN架构,搞定任意图像PS组合
Posted Alan_Fire
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ECCV 2018 | UBC&腾讯AI Lab提出首个模块化GAN架构,搞定任意图像PS组合相关的知识,希望对你有一定的参考价值。
通常的图像转换模型(如 StarGAN、CycleGAN、IcGAN)无法实现同时训练,不同的转换配对也不能组合。在本文中,英属哥伦比亚大学(UBC)与腾讯 AI Lab 共同提出了一种新型的模块化多域生成对抗网络架构——ModularGAN,生成的结果优于以上三种基线结果。该架构由几个可重复利用和可组合的模块组成。不同的模块可以在测试时轻松组合,以便在不同的域中高效地生成/转换图像。研究者称,这是首个模块化的 GAN 架构。 据了解,腾讯 AI Lab 共有 19 篇论文入选 ECCV 2018。

图1:ModularGAN在多领域图像到图像转换任务的生成结果(CelebA数据集)。
近年来,随着变分自编码器、生成式对抗网络的引入,图像生成变得越来越流行。许多研究致力于基于图像生成的任务,包括属性到图像的生成、文本到图像的生成或图像到图像的转换。这些任务在广义上都可以归为条件图像生成,分别采用属性向量、文本描述或一幅图像作为条件输入,并输出一幅图像。现有的多数条件图像生成模型都是从输入中学习一个直接的映射,其中,输入可能包含一幅图像或一个随机噪声向量及目的条件,以使用神经网络输出一幅包含目标属性的图像。
每个条件或条件类型有效地定义了一种生成或图像到图像的输出域(如人脸图像的表情域(笑)或性别域(男/女))。对于实际任务,我们希望控制数量巨大、可变的条件(如:生成微笑的人或棕色头发微笑的人的图像)。创建一个函数求解条件数目达到指数级的域非常困难。当下很多惊艳的图像转换方法只能将图像从一个域转换到另一个域。多域设定存在很多缺陷:(1)需要学习指数级的成对转换函数,计算成本很高并且在很多实际情况下并不可行;(2)在学习一个特定的成对映射时不可能利用其它域的数据;(3)成对的转换函数可能非常复杂,以建模差异巨大的域之间的转换。为了解决(1)和(2)中的问题,最近人们引入了多域图像(及语言)转换模型。代表源/目标域信息的固定向量可以用来作为单一模型的条件,以指导转换过程。然而,域间的信息分享在很大程度上是隐含的,函数映射变得极度复杂。
本文研究者假设将图像生成的过程分为几个较为简单的生成步骤可以让模型学习的过程变得更加容易、鲁棒。他们训练的既不是成对的映射,也不是复杂的模型,而是少数几个简单的生成模块,这些模块可以组合成复杂的生成过程。试想将一幅图像从 A 域(男性皱眉)转换到 C 域(女性微笑):DA → DC。这一过程是可能的,首先变换原始图像的性别为女性,相较于直接从 A 域变换到 C 域,这种做法会使微笑(DA 女性 ?????→ DB 微笑 ?????→ DC)更加鲁棒,原因分为两个方面:(1)单个变换更简单,空间上更局域化;(2)根据定义,与女性微笑最终域相比,中间女性的数据量及微笑域更大。换句话说,在本例中,研究者利用更多数据来学习更简单的转换函数。这种直觉与最近介绍的模块化网络相一致,本文在概念上采用并扩展了这种网络,用于生成图像任务。
为了实现这一增量图像生成过程并使其定型,研究者提出了模块化的生成对抗网络 ModularGAN。该网络包含几种不同的模块,包括生成器、编码器、重构器、转换器和判别器,这几种模块联合训练。每个模块拥有特定的功能。用在图像生成任务中的生成器模块从随机噪声中生成潜在的图像表征及一个(最优的)条件向量。用于图像到图像转换的编码器模块将输入图像编码为潜在表征。由生成器或编码器生成的潜在表征由转换器模块根据给定的条件进行控制。之后重构器模块重新构建转换的图像(看起来或真或假),并分类图像的属性。重要的是,不同的转换器模块在测试时可以以任意顺序动态组合,形成应用特征转换序列的生成网络,以得到更复杂的映射和生成过程。
本文的贡献是多方面的:
- 提出了 ModularGAN——一种新型的模块化多域生成对抗网络架构。ModularGAN 由几个可重复利用和可组合的模块组成。不同的模块可以在测试时轻松组合,以便在不同的域中高效地生成/转换图像。据研究者称,这是首个模块化的 GAN 架构。
- 提供了一种端到端联合训练所有模块的有效方法。新模块可以很容易地添加到本文提出的 ModularGAN 中,现有模块的子集也可以升级而不影响其它模块。
- 演示了如何成功地组合不同的(转换器)模块,以便将图像转换到不同的领域。研究者在转换器模块中利用掩码预测来确保仅变换特征图的局部区域;保持其它区域不变。
- 实验证明本文的方法在图像生成(ColorMNIST 数据集)和图像到图像转换(面部属性转移)任务上的有效性。与当前最佳的 GAN 模型的定性和定量比较展示了 ModularGAN 获得的显著改进。
论文:Modular Generative Adversarial Networks

论文地址:https://arxiv.org/pdf/1804.03343.pdf
摘要:已有的用于多领域图像到图像转换(或生成)的方法通常尝试直接将一张输入图像映射(随机向量)到输出领域的一张图像。然而,大多数已有方法的可扩展性和鲁棒性有限,因为它们需要为问题中的每对领域构建独立的模型。这导致两个明显的缺陷:(1)训练指数级配对模型的需求,以及(2)训练特定配对映射时,无法利用来自其它领域的数据。受近期模块化网络的研究启发,本文提出了用于多领域图像生成和图像到图像变换的模块化生成对抗网络 ModularGAN。ModularGAN 由几个可重复利用和可组合的分别实现不同功能(例如编码、解码、转换)的模块构成。这些模块可以被同时训练,利用来自所有领域的数据,然后在测试阶段根据特定的图像转换任务,将模块组合起来构建特定的 GAN。这给 ModularGAN 带来了优越的灵活性,可以生成任何所需领域的图像。实验结果表明我们的模型不仅有引人入胜的感知结果,还超越了当前最佳的多领域脸部属性迁移方法。
实验
我们首先在合成的多属性 MNIST 数据集上构建了图像生成实验。接下来,我们将自己的方法与近期的图像到图像的脸部属性迁移方法进行了对比。根据用户研究和属性分类的结果,我们的方法同时实现了定性的和定量的提高。最后,我们构建了控制变量实验来测试模块 T 的掩码预测、cyclic loss 以及多模块 T 的顺序对多领域图像迁移的影响。
在 ColorMNIST 上的实验结果

图 4:图像生成:在 ColorMNIST 数据集上的数字合成结果。注意,(n) 暗含对数字的约束,(c) 暗含颜色,(s) 暗含笔画类型,以及 (b) 暗含背景。由多个字母标记的列说明生成结果依赖于多个属性。例如:(ncs) 包含数字、颜色、笔画的约束。灰度图展示了由 T_i 模块(i∈{c,s,b})内在地生成的掩码。
在 CelebA 上的结果

图 5:在 CelebA 数据集上的脸部属性迁移结果。
定性评估。图 1 和图 5 展示了在 CelebA 数据集上的脸部属性迁移结果,分别使用本文提出的方法和基线方法得到。在图 5 中,迁移过程是在一张拥有中性表情和黑色头发的女性脸部图像到多个属性组合之间进行的。结果证明 IcGAN 的表现最差。虽然生成的模型拥有所需的属性,但脸部的身份特征没有被很好地保留。此外,生成的图像也不具备高锐度的细节,这是由于把图像编码到低维隐向量然后又解码为原图像的过程中信息丢失所导致的。
由 CycleGAN 生成的图像比 IcGAN 更好,但存在一些可见的瑕疵。通过使用循环一致性损失,CycleGAN 保留了输入图像的身份一致性,并且仅改变了脸部的特定区域。StarGAN 生成了比 CycleGAN 更好的图像,因为它是在完整的数据集上训练的,并潜在地利用了来自所有属性领域的图像。我们的方法相比基线方法生成了更好的结果(例如,看看最后一列的微笑或多属性迁移的结果)。它使用了多个转换模块来改变不同的属性,并且每个转换器模块学习一个特定的从一个领域到另一个领域的映射。这和 StarGAN 不同,StarGAN 在一个模型中学习所有的变换。

表 1:AMT 用户研究:更高的值表示结果更佳,并表明了偏好。

表 2:分类误差。更低的值表示结果更佳,表明了更少的属性误差。

图 6:掩码可视化:执行属性迁移时的掩码可视化。当使用多个模块 T 时,我们将不同的掩码相加。
定量评估。我们训练了一个使用 ResNet-18 架构的模型来对 CelebA 数据集的发色、脸部表情和性别 [30] 分类。训练/测试集在其它实验中也是相同的。已训练的模型以 96.5%、97.9% 和 98.3% 的准确率对发色、性别和微笑分类。然后我们把这个已训练的模型应用到转换的图像上,该图像是在测试集上通过不同方法得到的。
如表 2 所示,我们的模型可以在发色分类任务上达到和 StarGAN 相当的分类误差,并在所有其它任务上达到最低的分类误差。表 1 展示了 AMT 实验的结果。该模型在所有任务(除了性别分类)的最佳迁移属性上获得了多数投票。而且我们的性别迁移模型更好地保留了原始的发型,这从模型的角度来说是理想的,但有时候会让挑剔的人感觉不适。
模块化生成对抗网络
网络结构
图像转换。我们首先介绍可执行多领域图像转换的 ModularGAN。在这项任务中使用了四种类型的模块:编码器模块(E),它把一张输入图像编码为一个中间特征图;转换器模块(T),可以修改特征图的一个特定属性;重构模块(R),从一个中间特征图重构图像;以及判别器模块(D),用来确定一张图像的真假,并预测输入图像的属性。
图 2 展示了图像转换模块在训练和测试阶段的完整架构。在训练阶段(图 2,左),编码器 E 和多转换器模块 T_i 连接,每个 T_i 进一步和重构模块 R 连接,以生成转换后的图像。有多个判别器模块 D_i 连接到重构器上,以将生成图像从真实图像中分辨出来,并对相应的属性做出预测。所有的模块拥有相同的接口,即 E 的输出、R 的输入、T_i 的输入和输出有相同的形状和维度。这允许模块进行集成,以在测试时构建更复杂的架构,如图 2 所示。
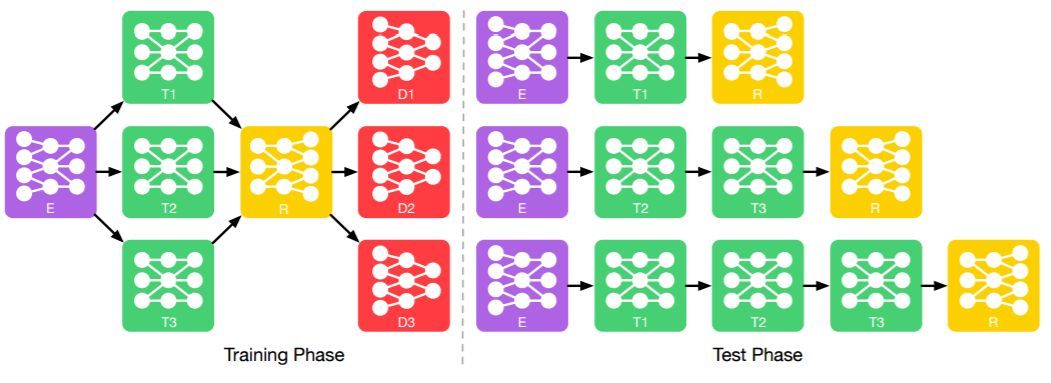
图 2:ModularGAN 架构:测试和训练阶段的多领域图像转换架构。ModularGAN 有四种不同的模块构成:编码器模块 E、转换器模块 T、重构器模块 R 以及判别器 D。这些模块可以同时进行训练,并根据测试阶段的生成任务用于构建不同的生成网络。
在训练阶段,一张输入图像首先由 E 编码,得到中间表征 E(x)。然后不同的转换器模块 T_i 根据预指定的属性 a_i 被用于修改 E(x),得到 T_i(E(x),a_i)。T_i 被设计用来将特定属性 a_i 转换成不同的属性值。例如,将发色从金色变为褐色,或将性别从女性变为男性。重构器模块 R 重构转换后的特征图为输出图像 y=R(T_i(E(x),a_i))。判别器模块 D 被设计用来分辨生成图像 y 和真实图像 x。它还预测了图像 x 或 y 的属性。
在测试阶段(图 2 右),不同的转换器模块可以被动态地组合来构建网络,以按任意的顺序控制任意数量的属性。
图像生成。图像生成任务的模型架构和图像转换任务的架构基本相同。仅有的不同之处在于,编码器模块 E 由一个生成器模块 G 替换,后者从一个随机噪声向量 z 和一个条件向量 a_0(表示辅助信息)生成中间特征图 G(z,a_0)。条件向量 a_0 可以决定图像的整体内容。例如,如果目标是生成数字的图像,a_0 可以被用于控制生成哪个数字,例如数字 7。模块 R 可以类似地重构初始图像 x=R(G(z,a_0)),这是拥有任意属性的数字 7 的图像。剩下的架构部分和图像转换任务中的相同,后者使用一个转换器模块 T_i 的序列来转换初始图像,以更改特定的属性(例如,数字的颜色、笔画类型或背景)。
模块
转换器模块 (T) 是该模型的核心模块。它根据输入条件 a_i 将输入特征表示转换成新的特征表示。转换器模块接收大小为 C×H×W 的特征图 f 和长度为 c_i 的条件向量 a_i。它的输出是大小为 C×H×W 的特征图 f_t。下图展示了模块 T 的结构。长度为 c_i 的条件向量 a_i 被复制到大小为 c_i×H×W 的张量,然后该张量与输入特征图 f 拼接。首先使用卷积层将通道数量从 C + c_i 减少到 C。之后,依次应用几个残差块,其输出用 f‘ 表示。使用变换后的特征图 f‘ 和具有 Tanh 激活函数的附加卷积层来生成尺寸为 H×W 的单通道特征图 g。随后该特征图 g 根据 g‘ = ( 1 + g ) / 2 的比例被重新缩放到范围 (0,1)。预测的 g‘ 就像 alpha 掩码或注意力层:它鼓励模块 T 只变换特征图中与特定属性变换相关的区域。最后,使用掩码 g‘将变换后的特征图 f‘与输入特征图 f 相结合,得到输出 f_t = g‘×f‘ + ( 1-g‘ )×f。

图 3:转换器模块。
以上是关于ECCV 2018 | UBC&腾讯AI Lab提出首个模块化GAN架构,搞定任意图像PS组合的主要内容,如果未能解决你的问题,请参考以下文章
ACM MM & ECCV 2022 | 美团视觉8篇论文揭秘内容领域的智能科技
你没见过的《老友记》镜头,AI给补出来了|ECCV 2022