MapReduce详解
Posted cnblogs-syui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce详解相关的知识,希望对你有一定的参考价值。
MapReduce概述
一:mapTask阶段
a):默认通过TextInputFormat组件调用RecoredReader的read()方法读取指定路径的文件,返回K-V,读取一行调用一次map()方法
二:shuffler机制
a):mapTask中通过OutputCollector将结果写入环形缓冲区
b):环形缓冲区中通过HashPartitioner对结果分区,通过KeyComparTo对结果排序,通过Combiner对环形缓冲区溢写的小文件进行局部汇总,相同Key的Value相加以减少网络I/O
c):当mapTask跑完后,进行一次全局的merge(归并排序),得到每个mapTask的最终结果文件
三:reduceTask节点
a):每个reduceTask对应一个分区,reduce阶段先将对应分区的mapTask结果分解下载到reduceTask的本地
b):进行业务逻辑处理后默认通过TextOutputFormat组件调用RecoredWriter的Write(Key,Value)将结果写入指定路径
流程图

例一,自定义InputFormat实现小文件合并
a):CustomInputFormat
public class CustomInputFormat extends FileInputFormat<NullWritable, BytesWritable> { //直接返回false表示文件不可切分,保证一个小文件是完整的一行 @Override protected boolean isSplitable(JobContext context, Path filename) { return false; } //获取RecordReader组件,以便在runner调用自定义inputformat时有相应的recordreader @Override public RecordReader createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException { CustomRecordReader customRecordReader = new CustomRecordReader(); //调用一次init方法,将inputSplit,taskAttemptContext传给CustomRecordReader customRecordReader.initialize(inputSplit,taskAttemptContext); return customRecordReader; } }
b):CustomRecoredReader
/** * RecordReader的核心工作机制: * 通过nextKeyValue()读取数据构造将返回的key value * 通过getCurrentKey和getCurrentValue返回上面构造好的key value */ public class CustomRecordReader extends RecordReader<NullWritable, BytesWritable> { //准备value2进行返回 BytesWritable bytesWritable = new BytesWritable(); //切片 private FileSplit fileSplit; //Configuration,只能在runner new,可以通过上下文对象获取 private Configuration configuration; //判断文件是否读取成功的状态 private boolean processed = false; /** * 初始化方法,带了两个参数 * 1,InputSplit:文件的切片,拿到了文件的切片,就相当于拿到了文件内容 * 2,taskAttemptContext,上下文对象,可以拿到configuration,有了configuration就可以拿到FileSystem * 相当于拿到了文件系统,可以任意操作文件 * @param inputSplit * @param taskAttemptContext * @throws IOException * @throws InterruptedException */ @Override public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException { this.fileSplit = (FileSplit) inputSplit; this.configuration = taskAttemptContext.getConfiguration(); } /** * 这个方法决定了是否继续往下读key value,如果返回true表示文件读完,返回false表示没有读完继续往下读 * @return * @throws IOException * @throws InterruptedException */ @Override public boolean nextKeyValue() throws IOException, InterruptedException { if(!processed){ Path path = fileSplit.getPath(); //获取文件系统 FileSystem fileSystem = path.getFileSystem(configuration); //获取输入流,转换成二进制的字节数组 FSDataInputStream inputStream = fileSystem.open(path); //定义一个字节数组,该字节数组的容量就是文件切片的大小 byte [] bytes = new byte[(int) fileSplit.getLength()]; //将流的数据读入字节数组 IOUtils.readFully(inputStream,bytes,0, (int) fileSplit.getLength()); //将字节数组的数据封装到BytesWritable bytesWritable.set(bytes,0, (int) fileSplit.getLength()); //判断文件读取成功并将processed置为true processed = true; //关闭资源 fileSystem.close(); IOUtils.closeStream(inputStream); return true; } return false; } /** *返回key1 * @return * @throws IOException * @throws InterruptedException */ @Override public NullWritable getCurrentKey() throws IOException, InterruptedException { return null; } /** * 返回value1 * @return * @throws IOException * @throws InterruptedException * 二进制的字节数组装整个文件的数据,且数据是二进制 */ @Override public BytesWritable getCurrentValue() throws IOException, InterruptedException { //nextKeyValue方法已读取文件内容并放在了bytesWritable中,直接返回 return bytesWritable; } /** * 读取的进度 * @return * @throws IOException * @throws InterruptedException */ @Override public float getProgress() throws IOException, InterruptedException { return processed?1.0f:0.0f; } /** *需要关闭的资源在这里释放 * @throws IOException */ @Override public void close() throws IOException { } }
c):map/runner
public class CustomInputRunner extends Configured implements Tool { public static void main(String[] args) throws Exception { int run = ToolRunner.run(new Configuration(),new CustomInputRunner(),args); System.exit(run); } class CustomInputMap extends Mapper<NullWritable, BytesWritable, Text,BytesWritable> { //map阶段将文件进行合并,将文件名称作为mapOutKey以做标识,mapOutValue就是字节数组 @Override protected void map(NullWritable key, BytesWritable value, Context context) throws IOException, InterruptedException { //获取文件名,只做文件合并不需要reduce FileSplit fileSplit = (FileSplit) context.getInputSplit(); String name = fileSplit.getPath().getName(); System.out.println(name); context.write(new Text(name),value); } } @Override public int run(String[] strings) throws Exception { Job job = Job.getInstance(super.getConf(),"customInput"); job.setInputFormatClass(CustomInputFormat.class); CustomInputFormat.addInputPath(job,new Path("file:///F:\\小文件合并\\input")); job.setMapperClass(CustomInputMap.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(BytesWritable.class); //没有reduce类也要定义reduce的输出key value类型,改变其默认的LongWritable成想要的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(BytesWritable.class); job.setOutputFormatClass(SequenceFileOutputFormat.class); SequenceFileOutputFormat.setOutputPath(job,new Path("file:///F:\\小文件合并\\output")); boolean b = job.waitForCompletion(true); return b?0:1; } }
例二,自定义分区
a):CustomPartitioner
public class MyPartitioner extends Partitioner<Text, NullWritable> { @Override public int getPartition(Text text, NullWritable nullWritable, int i) { String result = text.toString().split(" ")[5]; if (Integer.parseInt(result) < 15){ return 1; }else { return 0; } } }
b):runner,本地跑好像会出错,没仔细弄过,直接在集群跑了
public class PartitionerRunner extends Configured implements Tool { public static void main(String[] args) throws Exception { int run = ToolRunner.run(new Configuration(),new PartitionerRunner(),args); System.exit(run); } static class PartitionerMapper extends Mapper<LongWritable, Text, Text, NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(value,NullWritable.get()); } } static class PartitionerReducer extends Reducer<Text, NullWritable,Text,NullWritable> { @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key,NullWritable.get()); } } @Override public int run(String[] strings) throws Exception { Job job = Job.getInstance(super.getConf(),"partitioner"); job.setJarByClass(PartitionerRunner.class); //指定输入组件和输入目录 job.setInputFormatClass(TextInputFormat.class); TextInputFormat.setInputPaths(job,new Path("hdfs://node1:8020/partition/input")); //mapper配置 job.setMapperClass(PartitionerMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); //分区 job.setPartitionerClass(MyPartitioner.class); // reducerTask数要和分区一样 job.setNumReduceTasks(2); //reducer配置 job.setReducerClass(PartitionerReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); //指定输出组件和输出目录 job.setOutputFormatClass(TextOutputFormat.class); TextOutputFormat.setOutputPath(job,new Path("hdfs://node1:8020/partition/output1")); //提交 boolean b = job.waitForCompletion(true); return b?0:1; } }
分区文件

分区1
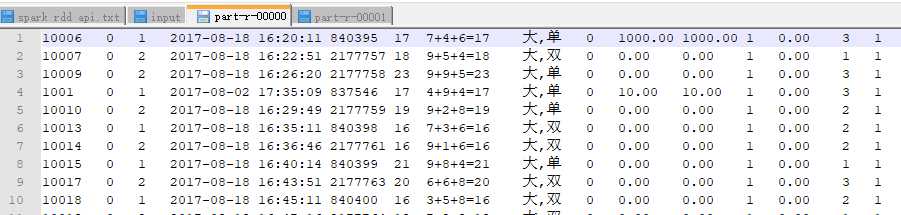
分区2
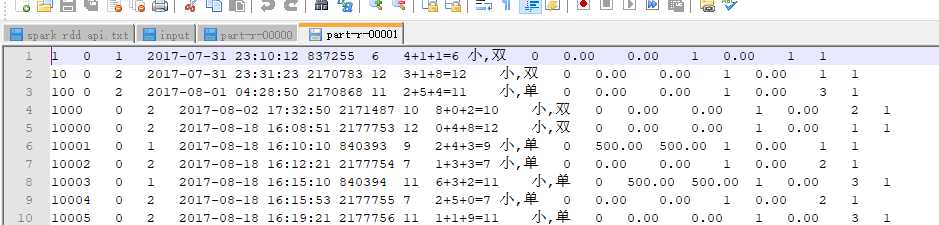
例三,自定义排序

a),SortBean
public class SortBean implements WritableComparable<SortBean> { private String first; private String seconde; public void setFirst(String first) { this.first = first; } public void setSeconde(String seconde) { this.seconde = seconde; } public String getFirst() { return first; } public String getSeconde() { return seconde; } //排序 @Override public int compareTo(SortBean s) { int i = this.first.compareTo(s.first); if(i != 0){ //first不等,直接返回结果 return i; }else { return this.seconde.compareTo(s.seconde); } } //序列化 @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(first); dataOutput.writeUTF(seconde); } //反序列化 @Override public void readFields(DataInput dataInput) throws IOException { this.first = dataInput.readUTF(); this.seconde = dataInput.readUTF(); } }
b),runner
public class SortRunner extends Configured implements Tool { public static void main(String[] args) throws Exception { try { ToolRunner.run(new Configuration(), new SortRunner(), args); } catch (Exception e) { e.printStackTrace(); } } static class SortMapper extends Mapper<LongWritable, Text, SortBean, Text> { SortBean bean = new SortBean(); Text outPutValue = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] words = value.toString().split(" "); bean.setFirst(words[0]); bean.setSeconde(words[1]); outPutValue.set(words[1]); context.write(bean, outPutValue); } } static class SortReducer extends Reducer<SortBean, Text, Text, Text> { Text outPutKey = new Text(); @Override protected void reduce(SortBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text value : values) { outPutKey.set(key.getFirst()); context.write(outPutKey, value); } } } @Override public int run(String[] strings) throws Exception { Job job = Job.getInstance(super.getConf(), "sort"); job.setJarByClass(SortRunner.class); job.setInputFormatClass(TextInputFormat.class); TextInputFormat.setInputPaths(job, new Path("file:///F:\\排序\\input")); job.setMapperClass(SortMapper.class); job.setMapOutputKeyClass(SortBean.class); job.setMapOutputValueClass(Text.class); job.setReducerClass(SortReducer.class); job.setOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputFormatClass(TextOutputFormat.class); TextOutputFormat.setOutputPath(job, new Path("file:///F:\\排序\\output")); boolean b = job.waitForCompletion(true); return b ? 0 : 1; } }
例四,求同一订单的topN
订单数据:
o_id p_id price
Order_0000001 Pdt_01 222.8
Order_0000001 Pdt_05 25.8
Order_0000002 Pdt_03 322.8
Order_0000002 Pdt_04 522.4
Order_0000002 Pdt_05 822.4
Order_0000003 Pdt_01 222.8
a),OrderBean
public class OrderBean implements WritableComparable<OrderBean> { private String id; private Double price; public OrderBean() { super(); } public OrderBean(String s, Double valueOf) { this.id = s; this.price = valueOf; } public String getId() { return id; } public void setId(String id) { this.id = id; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } @Override public String toString() { return id+" "+price; } @Override public int compareTo(OrderBean o) { //先按id排序 int i = this.id.compareTo(o.id); if(i ==0){ //id相同的按金额排序 i = -this.price.compareTo(o.price); } return i; } @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(id); dataOutput.writeDouble(price); } @Override public void readFields(DataInput dataInput) throws IOException { this.id = dataInput.readUTF(); this.price = dataInput.readDouble(); } }
b),customPartition
public class CustomPartition extends Partitioner<OrderBean, Text> { @Override public int getPartition(OrderBean orderBean, Text text, int i) { //相同id去一个区 return (orderBean.getId().hashCode() & Integer.MAX_VALUE)%i; } }
c),customGroupingComparator
public class CustomGroupingComparator extends WritableComparator { /** * 将自定义的OrderBean注册到我们自定义的CustomGroupingComparator当中 * 表示分组器在分组的时候,对OrderBean这一种类型的数据进行分组 * 传入作为key的bean的class类型,以及制定需要让框架做反射获取实例对象 */ public CustomGroupingComparator() { super(OrderBean.class,true); } @Override public int compare(Object a, Object b) { OrderBean first = (OrderBean) a; OrderBean second = (OrderBean) b; return first.getId().compareTo(second.getId()); } }
d),runner
public class CustomGroupRunner extends Configured implements Tool { public static void main(String[] args) throws Exception { int run = ToolRunner.run(new Configuration(),new CustomGroupRunner(),args); System.exit(run); } static class CustomGroupMap extends Mapper<LongWritable, Text,OrderBean, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split(" "); OrderBean orderBean = new OrderBean(split[0], Double.valueOf(split[2])); context.write(orderBean,value); } } static class CustomGroupReduce extends Reducer<OrderBean, Text,NullWritable,Text> { @Override protected void reduce(OrderBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException { int i = 0; for (Text value : values) { context.write(NullWritable.get(),value); i ++; //top2 if(i >= 2){ break; } } } } @Override public int run(String[] strings) throws Exception { Job job = Job.getInstance(new Configuration(),"customGroup"); job.setJarByClass(CustomGroupRunner.class); job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("hdfs://node1:8020/group/input")); job.setMapperClass(CustomGroupMap.class); job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(Text.class); //分区 job.setPartitionerClass(CustomPartition.class); //reduceTask数 job.setNumReduceTasks(3); //分组 job.setGroupingComparatorClass(CustomGroupingComparator.class); job.setReducerClass(CustomGroupReduce.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); job.setOutputFormatClass(TextOutputFormat.class); TextOutputFormat.setOutputPath(job,new Path("hdfs://node1:8020/group/output")); boolean b = job.waitForCompletion(true); return b?0:1; } }
例五,自定义OutputFormat
a),customOuptFormat
public class CustomOutputFormat extends FileOutputFormat<Text, NullWritable> { @Override public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException { FileSystem fs = FileSystem.get(taskAttemptContext.getConfiguration()); //路径1 Path enhancePath = new Path("file:///F:\\自定义outputformat\\out1"); //路径2 Path toCrawPath = new Path("file:///F:\\自定义outputformat\\out2"); //获取流对象 FSDataOutputStream enhanceOut = fs.create(enhancePath); FSDataOutputStream toCrawOut = fs.create(toCrawPath); return new CustomOutputRecordWriter(enhanceOut,toCrawOut); } }
b),CustomOuputFormatRecoredWirter
public class CustomOutputRecordWriter extends RecordWriter<Text, NullWritable> { FSDataOutputStream enhanceOut = null; FSDataOutputStream toCrawlOut = null; //构造器 public CustomOutputRecordWriter(FSDataOutputStream enhanceOut,FSDataOutputStream toCrawlOut) { this.enhanceOut = enhanceOut; this.toCrawlOut = toCrawlOut; } @Override public void write(Text text, NullWritable nullWritable) throws IOException, InterruptedException { /** * 自定义写入哪个路径 * 第十个字段为0的写入路径1,其他的写入路径2 */ if(text.toString().split(" ")[9].equals("0")){ toCrawlOut.write(text.toString().getBytes()); //换行 toCrawlOut.write(" ".getBytes()); }else{ enhanceOut.write(text.toString().getBytes()); //换行 enhanceOut.write(" ".getBytes()); } } @Override public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException { if(toCrawlOut!=null){ toCrawlOut.close(); } if(enhanceOut!=null) { enhanceOut.close(); } } }
c),runner
public class CustomOutputRunner extends Configured implements Tool { public static void main(String[] args) throws Exception { int run = ToolRunner.run(new Configuration(),new CustomOutputRunner(),args); System.exit(run); } static class CustomOutputMap extends Mapper<LongWritable, Text,Text, NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split(" "); String commentStatus = split[9]; context.write(value,NullWritable.get()); } } @Override public int run(String[] strings) throws Exception { Job job = Job.getInstance(super.getConf(),"customOutput"); job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job,new Path("file:///F:\\自定义outputformat\\input")); job.setMapperClass(CustomOutputMap.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setOutputFormatClass(CustomOutputFormat.class); /* 设置的这个输出目录会生成一个success的成功的标识文件,真正的结果文件被写入了CustomOutputFormat设置的目录中 */ CustomOutputFormat.setOutputPath(job,new Path("file:///F:\\自定义outputformat\\successOut")); boolean b = job.waitForCompletion(true); return b?0:1; } }
以上是关于MapReduce详解的主要内容,如果未能解决你的问题,请参考以下文章