Hadoop新MapReduce框架Yarn详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop新MapReduce框架Yarn详解相关的知识,希望对你有一定的参考价值。
简介
本文介绍了Hadoop自0.23.0版本后新的MapReduce框架(Yarn)原理,优势,运行机制和配置方法等,着重介绍新的yarn框架相对于原框架的差异及改进,并通过Demo示例详细介绍了在新的Yarn框架下搭建和开发Hadoop程序的方法。读者通过本文中新旧Hadoop MapReduce框架的对比,更深刻理解新的yarn框架技术与那里和设计思想,文中的Demo代码经过微小修改既可用于用户基于Hadoop新框架的实际生产环境。
Hadoop MapReduceV2(Yarn)框架简介
原Hadoop MapReduce框架的问题
对于业界的大数据存储及分布式处理系统来说,Hadoop是耳熟能详的卓越开源分布式文件系统及处理框架,对于Hadoop框架的介绍在此就不再赘述。使用和学习过老Hadoop框架(0.20.0及之前版本)的同仁应该很熟悉如下的MapReduce框架图:
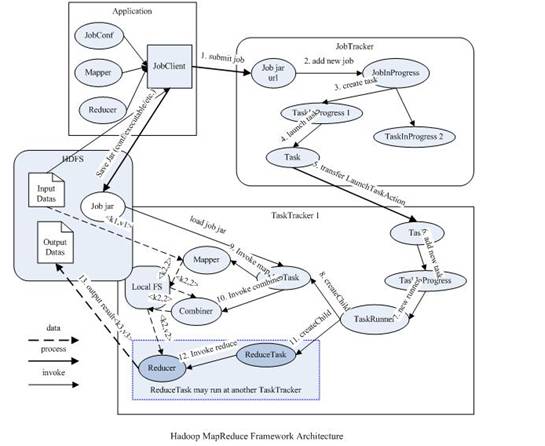
从上图中可以清楚的看出原MapReduce程序的流程及设计思路:
1.首先用户程序(JobClient)提交了一个Job,Job的信息会发送到JobTracker中,JobTracker是MapReduce框架的中心,它需要与集群中的机器定时通信(通过心跳机制),需要管理哪些程序应该跑在哪些机器上,需要管理所有Job失败、重启等操作。
2.TaskTracker是MapReduce集群中每台机器都有的一个部分,它做的事情主要是监视自己所在机器的资源情况。
3.TaskTracker同时监视当前机器的tasks运行状况。TaskTracker需要把这些信息通过Heartbeat发送给JobTracker,JobTracker会搜集这些信息以给新提交的Job分配运行在哪些机器上。上图虚线箭头就是表示消息的发送-接收过程。
可以看出原来的MapReduce框架是简单明了的,在最初推出的几年,也得到了众多的成功案例,获得业界广泛的支持和肯定,但随着分布式系统集群的规模和其工作负荷的增长,原框架的问题逐渐浮出水面,主要的问题集中如下:
1.JobTracker是MapReduce的集中处理点,存在单点故障。
2.JobTracker完成了太多的任务,造成了过多的资源消耗,当MapReduce Job非常多的时候,会造成很大的内存开销,潜在来说,也增加了JobTracker fail的风险,业界普遍总结出老Hadoop的MapReduce只能支持4000节点主机的上线。
3.在TaskTracker端,以MapReduce task的数目作为资源的表示过于简单,没有考虑到CPU内存的占用情况,如果两个大内存消耗的task被调度到了一块,很容易出现OOM。
4.在TaskTracker端,把资源强制划分为Map task slot和reduce task slot,如果当系统中只有map task或者只有reduce task的时候,会造成资源的浪费,也就是前面提到过的集群资源利用的问题。
5.源代码层面分析的时候,会发现代码非常的难读,常常因为一个class做了太多的事情,代码量达到了3000多行,造成class的任务不清晰,增加bug修复和版本维护的难度。
6.从操作的角度来看,现在Hadoop MapReduce框架在任何重要或者不重要的变化(例如bug修复,性能提升和特性化)时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应用程序是不是使用新的Hadoop版本而浪费大量时间。
新Hadoop Yarn框架原理及运行机制
从业界使用分布式系统的变化趋势和Hadoop框架长远发展来看,MapReduce的JobTracker和TaskTracker机制需要大规模的调整来修复它在可扩展性,内存消耗,线程模型,可靠性和性能上的缺陷。在过去的几年中,Hadoop开发团队做了一些bug的修复,但是最近这些修复的成本越来越高,这表明对原来框架做出改变的难度越来越大。
为从根本上解决旧MapReduce框架的性能瓶颈,促进Hadoop框架更长远发展,从0.23.0版本开始,Hadoop的MapReduce框架完全重构,发生了根本的变化。新的Hadoop MapReduce框架命名为MapReduceV2或者叫Yarn,其架构图如下所示:
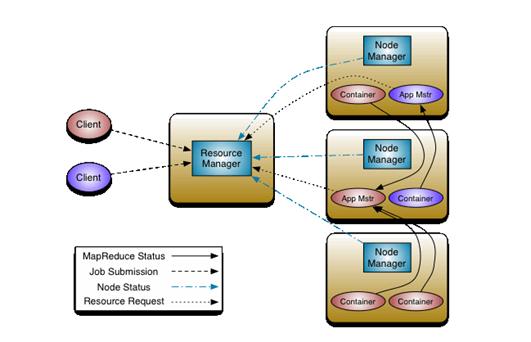
重构的根本思想是将JobTracker两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度/监控。新的资源管理器全局管理所有应用程序计算资源的分配,每一个应用的ApplicationMaster负责调度和协调。一个应用程序无非是一个单独的传统的MapReduce任务或者是一个DAG(有向无环图)任务。ResourceManager和每一台机器的节点管理服务器能够管理用户在那台机器上的进程并能对计算进行组织。
事实上,每一个应用的ApplicationMaster是一个详细的框架库,它结合从ResourceManager获得的资源和NodeManager协同工作来运行监控任务。
上图中ResourceManager支持分层级的应用队列,这些队列享有集群一定比例的资源。从某种意义上讲他就是一个纯粹的调度器,它在执行过程中不对应用进行监控和状态跟踪。同样,它也不能重启因应用失败或者硬件错误而运行失败的任务。
ResourceManager是基于应用程序对资源的需求进行调度的,每一个应用程序需要不同类型的资源因此就需要不同的容器PU,。资源包括:内存,C磁盘,网络等等。可以看出,这同现MapReduce固定类型的资源使用模型有显著的区别,它给集群的使用带来了负面的影响。资源管理器提供一个调度策略的插件,它负责将集群资源分配给多个队列和应用程序。调度插件可以基于现有的能力调度和公平调度模型。
上图中NodeManager是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况(CPU,内存,硬盘,网络)并且向调度器会报。
每一个应用的ApplicationMaster的职责有:想调度器所要适当的资源容器,运行任务,跟踪应用程序的状态和监控他们的进程,处理任务的失败原因。
新旧Hadoop MapReduce框架对比
让我们来对新旧MapReduce框架做详细的分析和对比,可以看到有一下几点显著变化:
首先客户端不变,其调用API及接口大部分兼容,这也是为了对开发使用者透明化,使其不必对原有代码做大的改变,但是原框架中核心的JobTracker和TaskTracker不见了,取而代之的是ResourceManager,ApplicationMaster和NodeManager三个部分。
我们来详细解释这三个部分,首先ResourceManager是一个中心的服务,它做的事情是调度、启动每一个Job所属的ApplicationMaster、另外监控ApplicationMaster的存在情况。细心的读者会发现:Job里面所在的task的监控、重启等等内容不见了。这就是AppMst存在的原因。ResourceManager负责作业与资源的调度。接收JobSubmitter提交的作业,按照作业的上下文(Context)信息,以及从NodeManager收集来的状态信息,启动调度过程,分配一个Container作为AppMstr
NodeManager功能比较专一,就是负责Container状态的维护,并向RM保持心跳。
ApplicationMaster负责一个Job声明周期的所有工作,类似老的框架中JobTracker。但注意每一个Job(不是每一种)都有一个ApplicationMaster,它可以运行在ResourceManager以外的机器上。
Yarn框架相对于老的MapReduce框架有什么优势呢?我们可以看到:
1.这个设计大大减小了JobTracker(也就是现在的ResourceManager)的资源消耗,并且让监测每一个Job子任务(task)状态的程序分布式化了,更安全、更优美。
2.在新的Yarn中,ApplicationMaster是一个可变更的部分,用户可以对不同的编程模型写自己的AppMst,让更多类型的编程模型能够跑在Hadoop集群中。
3.对于资源的表示以内存为单位,比之前以剩余slot数目更合理。
4.老的框架中,JobTracker一个很大的负担就是监控Job下的task的运行状况,现在,这个部分就扔个ApplicationMaster做了,而ResourceManager中有一个模块叫做ApplicationMasters(注意不是ApplicationMaster),它是监测ApplicationMaster的运行状况,如果出问题,会将其在其他机器上重启。
5.Container是Yarn为了将来做资源隔离而提出的一个框架。这一点应该借鉴了Mesos的工作,目前是一个框架,仅仅提供java虚拟机内存的隔离,Hadoop团队的设计思路应该后续能支持更多的资源调度和控制,既然资源表示内存量,那就没有了之前的Map slot和reduce slot分开造成集群资源闲置的尴尬情况。
新的Yarn框架相对于旧MapReduce框架而言,其配置文件,启停脚本及全局变量等也发生了一些变化,主要的的改变如下:
| 改变项 | 原框架中 | 新框架中(Yarn) | 备注 |
|---|---|---|---|
| 配置文件位置 | ${hadoop_home_dir}/conf | ${hadoop_home_dir}/etc/hadoop/ | Yarn 框架也兼容老的 ${hadoop_home_dir}/conf 位置配置,启动时会检测是否存在老的 conf 目录,如果存在将加载 conf 目录下的配置,否则加载 etc 下配置 |
| 启停脚本 | ${hadoop_home_dir}/bin/start(stop)-all.sh | ${hadoop_home_dir}/sbin/start(stop)-dfs.sh ${hadoop_home_dir}/bin/start(stop)-all.sh |
新的 Yarn 框架中启动分布式文件系统和启动 Yarn 分离,启动 / 停止分布式文件系统的命令位于 ${hadoop_home_dir}/sbin 目录下,启动 / 停止 Yarn 框架位于 ${hadoop_home_dir}/bin/ 目录下 |
| JAVA_HOME 全局变量 | ${hadoop_home_dir}/bin/start-all.sh 中 | ${hadoop_home_dir}/etc/hadoop/hadoop-env.sh ${hadoop_home_dir}/etc/hadoop/Yarn-env.sh |
Yarn 框架中由于启动 hdfs 分布式文件系统和启动 MapReduce 框架分离,JAVA_HOME 需要在 hadoop-env.sh 和 Yarn-env.sh 中分别配置 |
| HADOOP_LOG_DIR 全局变量 | 不需要配置 | ${hadoop_home_dir}/etc/hadoop/hadoop-env.sh | 老框架在 LOG,conf,tmp 目录等均默认为脚本启动的当前目录下的 log,conf,tmp 子目录 Yarn 新框架中 Log 默认创建在 Hadoop 用户的 home 目录下的 log 子目录,因此最好在 ${hadoop_home_dir}/etc/hadoop/hadoop-env.sh 配置 HADOOP_LOG_DIR,否则有可能会因为你启动 hadoop 的用户的 .bashrc 或者 .bash_profile 中指定了其他的 PATH 变量而造成日志位置混乱,而该位置没有访问权限的话启动过程中会报错 |
由于新的Yarn框架和原Hadoop MapReduce框架相比变化比较大,核心的配置文件中很多项在新框架中已经废弃,详细请参考:新老配置属性的对比
Hadoop Yarn框架Demo示例
Demo场景介绍:Weblogic应用服务器日志分析
了解了Hadoop新的Yarn框架的架构和思路后,我们用一个Demo示例来检验新Yarn框架下MapReduce程序的开发部署。
我们考虑如下应用场景:用户在生产系统由多台Weblogic应用服务器组成,每天需要对每台应用服务器的日志内容进行检查,统计日志级别和日志模块的总数。
WebLogic的日志范例如下图所示:
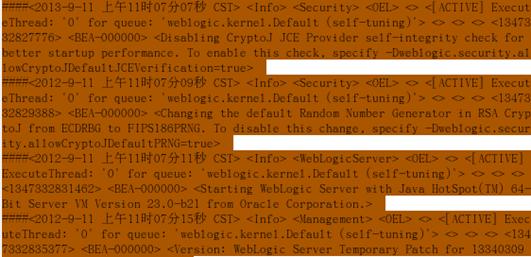
如上图所,<Info>为weblogic的日志级别,<Security>,<Management>为Weblogic的日志模块,我们主要分析loglevel和logmodule这两个温度分别在Weblogic日志中出现的次数,每天需要统计出loglevel和logmodule分别出现的次数总数。
Demo 测试环境 Yarn 框架搭建
由于 Weblogic 应用服务器分布于不同的主机,且日志数据量巨大,我们采用 hadoop 框架将 WebLogic 各个应用服务器主机上建立分布式目录,每天将 WebLogic 日志装载进 hadoop 分布式文件系统,并且编写基于 Yarn 框架的 MapReduce 程序对日志进行处理,分别统计出 LogLevel 和 Logmodule 在日志中出现的次数并计算总量,然后输出到分布式文件系统中,输出目录命名精确到小时为后缀以便区分每次 Demo 程序运行的处理结果。
我们搭建一个 Demo 测试环境以验证 Yarn 框架下分布式程序处理该案例的功能,以两台虚拟机作为该 Demo 的运行平台,两机均为 Linux 操作系统,机器 hostname 为 OEL 和 Stephen,OEL 作为 NameNode 和 ResouceManager 节点主机,64 位,Stephen 作为 DataNode 和 NodeManager 节点主机,32 位(Hadoop 支持异构性), 具体如下:
Demo测试环境表
| 主机名 | 角色 | 备注 |
|---|---|---|
| OEL(192.168.137.8) | NameNode 节点主机 ResourceManager 主机 |
linux 操作系统 32bit |
| Stephen(192.168.l37.2) | DataNode 节点主机 NodeManager 主机 |
linux 操作系统 64bit |
我们把 hadoop 安装在两台测试机的 /hadoop 文件系统目录下,安装后的 hadoop 根目录为:/hadoop/hadoop-0.23.0,规划分布式文件系统存放于 /hadoop/dfs 的本地目录,对应分布式系统中的目录为 /user/oracle/dfs
我们根据 Yarn 框架要求,分别在 core-site.xml 中配置分布式文件系统的 URL,详细如下:
core-site.xml配置:
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://192.168.137.8:9100</value>
- </property>
- </configuration>
在hdfs-site.xml中配置NameNode,DataNode的本地目录信息,详细如下:
hdfs-site.xml配置:
- <configuration>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>/hadoop/dfs/name</value>
- <description> </description>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>/hadoop/dfs/data</value>
- <description> </description>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>2</value>
- </property>
- </configuration>
在mapred-site.xml中配置其使用yarn框架处理程序,详细如下:
mapred-site.xml配置:
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>Yarn</value>
- </property>
- </configuration>
最后在Yarn-site.xml中配置ResourceManager,NodeManager的通信端口,Web监控端口等,详细如下:
yarn-site.xml配置:
- <?xml version="1.0"?>
- <configuration>
- <!-- Site specific YARN configuration properties -->
- <property>
- <name>Yarn.nodemanager.aux-services</name>
- <value>mapreduce.shuffle</value>
- </property>
- <property>
- <description>The address of the applications manager interface in the RM.</description>
- <name>Yarn.resourcemanager.address</name>
- <value>192.168.137.8:18040</value>
- </property>
- <property>
- <description>The address of the scheduler interface.</description>
- <name>Yarn.resourcemanager.scheduler.address</name>
- <value>192.168.137.8:18030</value>
- </property>
- <property>
- <description>The address of the RM web application.</description>
- <name>Yarn.resourcemanager.webapp.address</name>
- <value>192.168.137.8:18088</value>
- </property>
- <property>
- <description>The address of the resource tracker interface.</description>
- <name>Yarn.resourcemanager.resource-tracker.address</name>
- <value>192.168.137.8:8025</value>
- </property>
- </configuration>
Demo代码开发及详解
以下我们详细介绍一下新的yarn框架下针对该应用场景的Demo代码的开发,在Demo程序的每个类都有详细的注释说明,yarn开发为了兼容老版本的,API变化不大。
在Map程序中,我们以行号为key,行文本内容为value读取每一行Weblogic日志输入,将loglevel和logmodule的值读出作为Map处理后新的Key值,由于一行中loglevel和logmodule的出现次数应该唯一,所以经Map程序处理后的新的Record记录的value应该都为1。
Map业务逻辑
- public static class MapClass extends Mapper<Object, Text, Text, IntWritable>
- {
- private Text record = new Text();
- private static final IntWritable recbytes = new IntWritable(1);
- public void map(Object key, Text value,Context context)
- throws IOException,InterruptedException {
- String line = value.toString();
- // 没有配置 RecordReader,所以默认采用 line 的实现,
- //key 就是行号,value 就是行内容,
- // 按行 key-value 存放每行 loglevel 和 logmodule 内容
- if (line == null || line.equals(""))
- return;
- String[] words = line.split("> <");
- if (words == null || words.length < 2)
- return;
- String logLevel = words[1];
- String moduleName = words[2];
- record.clear();
- record.set(new StringBuffer("logLevel::").append(logLevel).toString());
- context.write(record, recbytes);
- // 输出日志级别统计结果,通过 logLevel:: 作为前缀来标示。
- record.clear();
- record.set(new StringBuffer("moduleName::").append(moduleName).toString());
- context.write(record, recbytes);
- // 输出模块名的统计结果,通过 moduleName:: 作为前缀来标示
- }
- }
由于有loglevel和logmodule两部分的分析工作,我们设定两个Reduce来分别处理这两部分,loglevel交给reduce1,logmodule交给reduce2.因此我们编写Patitioner类,根据Map传过来的Key中包含的loglevel和moduleName的前缀,来分到不同的reduce。
Patition业务逻辑:
- public static class PartitionerClass extends Partitioner<Text, IntWritable>
- {
- public int getPartition(Text key, IntWritable value, int numPartitions)
- {
- if (numPartitions >= 2)//Reduce 个数,判断 loglevel 还是 logmodule 的统计,分配到不同的 Reduce
- if (key.toString().startsWith("logLevel::"))
- return 0;
- else if(key.toString().startsWith("moduleName::"))
- return 1;
- else return 0;
- else
- return 0;
- }
- }
在Reduce程序中,累加并合并loglevel和logmodule的出现次数。
Reduce业务逻辑:
- public static class ReduceClass extends Reducer<Text, IntWritable,Text, IntWritable>
- {
- private IntWritable result = new IntWritable();
- public void reduce(Text key, Iterable<IntWritable> values,
- Context context)throws IOException,
- InterruptedException {
- int tmp = 0;
- for (IntWritable val : values) {
- tmp = tmp + val.get();
- }
- result.set(tmp);
- context.write(key, result);// 输出最后的汇总结果
- }
- }
以上完成了MapReduce的主要处理逻辑,对于程序入口,我们使用Hadoop提供的Tools工具包方便的进行MapReduce程序的启动和MapReduce对应处理class的配置。
Main执行类:
- import java.io.File;
- import java.io.IOException;
- import java.text.SimpleDateFormat;
- import java.util.Date;
- import java.util.Iterator;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.conf.Configured;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Partitioner;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.Tool;
- import org.apache.hadoop.util.ToolRunner;
- public class LogAnalysiser extends Configured implements Tool {
- public static void main(String[] args)
- {
- try
- {
- int res;
- res = ToolRunner.run(new Configuration(),new LogAnalysiser(), args);
- System.exit(res);
- } catch (Exception e)
- {
- e.printStackTrace();
- }
- }
- public int run(String[] args) throws Exception
- {
- if (args == null || args.length <2)
- {
- System.out.println("need inputpath and outputpath");
- return 1;
- }
- String inputpath = args[0];
- String outputpath = args[1];
- String shortin = args[0];
- String shortout = args[1];
- if (shortin.indexOf(File.separator) >= 0)
- shortin = shortin.substring(shortin.lastIndexOf(File.separator));
- if (shortout.indexOf(File.separator) >= 0)
- shortout = shortout.substring(shortout.lastIndexOf(File.separator));
- SimpleDateFormat formater = new SimpleDateFormat("yyyy.MM.dd.HH.mm");
- shortout = new StringBuffer(shortout).append("-")
- .append(formater.format(new Date())).toString();
- if (!shortin.startsWith("/"))
- shortin = "/" + shortin;
- if (!shortout.startsWith("/"))
- shortout = "/" + shortout;
- shortin = "/user/oracle/dfs/" + shortin;
- shortout = "/user/oracle/dfs/" + shortout;
- File inputdir = new File(inputpath);
- File outputdir = new File(outputpath);
- if (!inputdir.exists() || !inputdir.isDirectory())
- {
- System.out.println("inputpath not exist or isn‘t dir!");
- return 0;
- }
- if (!outputdir.exists())
- {
- new File(outputpath).mkdirs();
- }
- // 以下注释的是 hadoop 0.20.X 老版本的 Job 代码,在 hadoop0.23.X 新框架中已经大大简化
- // Configuration conf = getConf();
- // JobConf job = new JobConf(conf, LogAnalysiser.class);
- // JobConf conf = new JobConf(getConf(),LogAnalysiser.class);// 构建 Config
- // conf.setJarByClass(MapClass.class);
- // conf.setJarByClass(ReduceClass.class);
- // conf.setJarByClass(PartitionerClass.class);
- // conf.setJar("hadoopTest.jar");
- // job.setJar("hadoopTest.jar");
- // 以下是新的 hadoop 0.23.X Yarn 的 Job 代码
- job job = new Job(new Configuration());
- job.setJarByClass(LogAnalysiser.class);
- job.setJobName("analysisjob");
- job.setOutputKeyClass(Text.class);// 输出的 key 类型,在 OutputFormat 会检查
- job.setOutputValueClass(IntWritable.class); // 输出的 value 类型,在 OutputFormat 会检查
- job.setJarByClass(LogAnalysiser.class);
- job.setMapperClass(MapClass.class);
- job.setCombinerClass(ReduceClass.class);
- job.setReducerClass(ReduceClass.class);
- job.setPartitionerClass(PartitionerClass.class);
- job.setNumReduceTasks(2);// 强制需要有两个 Reduce 来分别处理流量和次数的统计
- FileInputFormat.setInputPaths(job, new Path(shortin));//hdfs 中的输入路径
- FileOutputFormat.setOutputPath(job,new Path(shortout));//hdfs 中输出路径
- Date startTime = new Date();
- System.out.println("Job started: " + startTime);
- job.waitForCompletion(true);
- Date end_time = new Date();
- System.out.println("Job ended: " + end_time);
- System.out.println("The job took " +
- (end_time.getTime() - startTime.getTime()) /1000 + " seconds.");
- // 删除输入和输出的临时文件
- // fileSys.copyToLocalFile(new Path(shortout),new Path(outputpath));
- // fileSys.delete(new Path(shortin),true);
- // fileSys.delete(new Path(shortout),true);
- return 0;
- }
- }
执行程序!
以上是关于Hadoop新MapReduce框架Yarn详解的主要内容,如果未能解决你的问题,请参考以下文章