MapReduce 实战
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce 实战相关的知识,希望对你有一定的参考价值。
MapReduce实战
MapReduce实战
利用MRJob编写和运行MapReduce代码
mrjob 简介
- 使用python开发在Hadoop上运行的程序, mrjob是最简单的方式
- mrjob程序可以在本地测试运行也可以部署到Hadoop集群上运行
- 如果不想成为hadoop专家, 但是需要利用Hadoop写MapReduce代码,mrJob是很好的选择
mrjob 安装
- 使用pip安装
- pip install mrjob
mrjob实现WordCount
from mrjob.job import MRJob
class MRWordFrequencyCount(MRJob):
def mapper(self, _, line):
yield "chars", len(line)
yield "words", len(line.split())
yield "lines", 1
def reducer(self, key, values):
yield key, sum(values)
if __name__ == '__main__':
MRWordFrequencyCount.run()
运行WordCount代码
打开命令行, 找到一篇文本文档, 敲如下命令:
python mr_word_count.py my_file.txt
运行MRJOB的不同方式
1、内嵌(-r inline)方式
特点是调试方便,启动单一进程模拟任务执行状态和结果,默认(-r inline)可以省略,输出文件使用 > output-file 或-o output-file,比如下面两种运行方式是等价的
python word_count.py -r inline input.txt > output.txt
python word_count.py input.txt > output.txt
2、本地(-r local)方式
用于本地模拟Hadoop调试,与内嵌(inline)方式的区别是启动了多进程执行每一个任务。如:
python word_count.py -r local input.txt > output1.txt
3、Hadoop(-r hadoop)方式
用于hadoop环境,支持Hadoop运行调度控制参数,如:
1)指定Hadoop任务调度优先级(VERY_HIGH|HIGH),如:–jobconf mapreduce.job.priority=VERY_HIGH。
2)Map及Reduce任务个数限制,如:–jobconf mapreduce.map.tasks=2 --jobconf mapreduce.reduce.tasks=5
python word_count.py -r hadoop hdfs:///test.txt -o hdfs:///output
mrjob 实现 topN统计(实验)
统计数据中出现次数最多的前n个数据
import sys
from mrjob.job import MRJob,MRStep
import heapq
class TopNWords(MRJob):
def mapper(self, _, line):
if line.strip() != "":
for word in line.strip().split():
yield word,1
#介于mapper和reducer之间,用于临时的将mapper输出的数据进行统计
def combiner(self, word, counts):
yield word,sum(counts)
def reducer_sum(self, word, counts):
yield None,(sum(counts),word)
#利用heapq将数据进行排序,将最大的2个取出
def top_n_reducer(self,_,word_cnts):
for cnt,word in heapq.nlargest(2,word_cnts):
yield word,cnt
#实现steps方法用于指定自定义的mapper,comnbiner和reducer方法
def steps(self):
return [
MRStep(mapper=self.mapper,
combiner=self.combiner,
reducer=self.reducer_sum),
MRStep(reducer=self.top_n_reducer)
]
def main():
TopNWords.run()
if __name__=='__main__':
main()
MRJOB 文件合并
需求描述
- 两个文件合并 类似于数据库中的两张表合并
uid uname
01 user1
02 user2
03 user3
uid orderid order_price
01 01 80
01 02 90
02 03 82
02 04 95
mrjob 实现
实现对两个数据表进行join操作,显示效果为每个用户的所有订单信息
"01:user1" "01:80,02:90"
"02:user2" "03:82,04:95"
from mrjob.job import MRJob
import os
import sys
class UserOrderJoin(MRJob):
SORT_VALUES = True
# 二次排序参数:http://mrjob.readthedocs.io/en/latest/job.html
def mapper(self, _, line):
fields = line.strip().split('\\t')
if len(fields) == 2:
# user data
source = 'A'
user_id = fields[0]
user_name = fields[1]
yield user_id,[source,user_name] # 01 [A,user1]
elif len(fields) == 3:
# order data
source ='B'
user_id = fields[0]
order_id = fields[1]
price = fields[2]
yield user_id,[source,order_id,price] #01 ['B',01,80]['B',02,90]
else :
pass
def reducer(self,user_id,values):
'''
每个用户的订单列表
"01:user1" "01:80,02:90"
"02:user2" "03:82,04:95"
:param user_id:
:param values:[A,user1] ['B',01,80]
:return:
'''
values = [v for v in values]
if len(values)>1 :
user_name = values[0][1]
order_info = [':'.join([v[1],v[2]]) for v in values[1:]] #[01:80,02:90]
yield ':'.join([user_id,user_name]),','.join(order_info)
def main():
UserOrderJoin.run()
if __name__ == '__main__':
main()
实现对两个数据表进行join操作,显示效果为每个用户所下订单的订单总量和累计消费金额
"01:user1" [2, 170]
"02:user2" [2, 177]
from mrjob.job import MRJob
import os
import sys
class UserOrderJoin(MRJob):
# 二次排序参数:http://mrjob.readthedocs.io/en/latest/job.html
SORT_VALUES = True
def mapper(self, _, line):
fields = line.strip().split('\\t')
if len(fields) == 2:
# user data
source = 'A'
user_id = fields[0]
user_name = fields[1]
yield user_id,[source,user_name]
elif len(fields) == 3:
# order data
source ='B'
user_id = fields[0]
order_id = fields[1]
price = fields[2]
yield user_id,[source,order_id,price]
else :
pass
def reducer(self,user_id,values):
'''
统计每个用户的订单数量和累计消费金额
:param user_id:
:param values:
:return:
'''
values = [v for v in values]
user_name = None
order_cnt = 0
order_sum = 0
if len(values)>1:
for v in values:
if len(v) == 2 :
user_name = v[1]
elif len(v) == 3:
order_cnt += 1
order_sum += int(v[2])
yield ":".join([user_id,user_name]),(order_cnt,order_sum)
def main():
UserOrderJoin().run()
if __name__ == '__main__':
main()
MapReduce原理详解
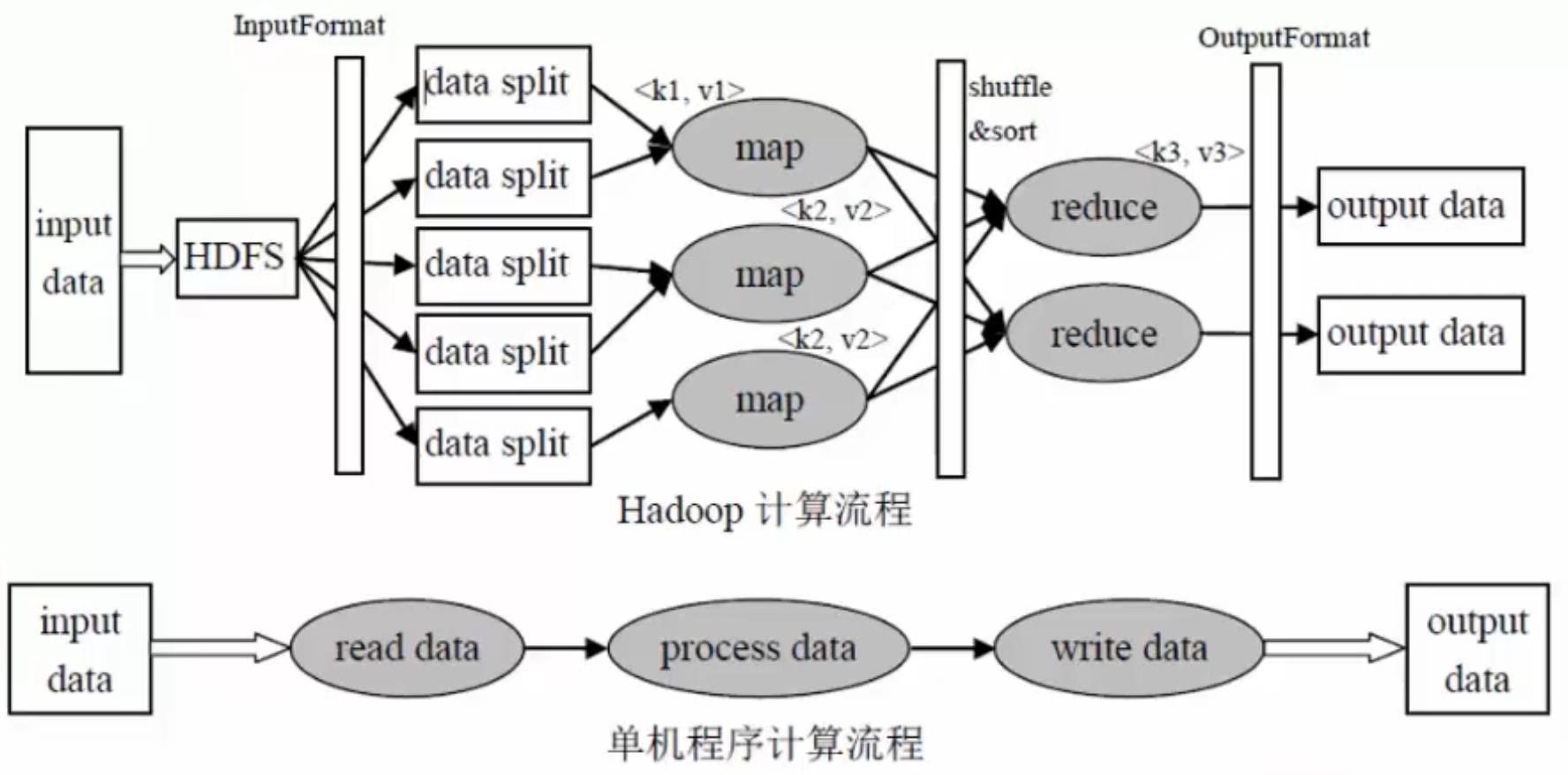
单机程序计算流程
输入数据—>读取数据—>处理数据—>写入数据—>输出数据
Hadoop计算流程
input data:输入数据
InputFormat:对数据进行切分,格式化处理
map:将前面切分的数据做map处理(将数据进行分类,输出(k,v)键值对数据)
shuffle&sort:将相同的数据放在一起,并对数据进行排序处理
reduce:将map输出的数据进行hash计算,对每个map数据进行统计计算
OutputFormat:格式化输出数据
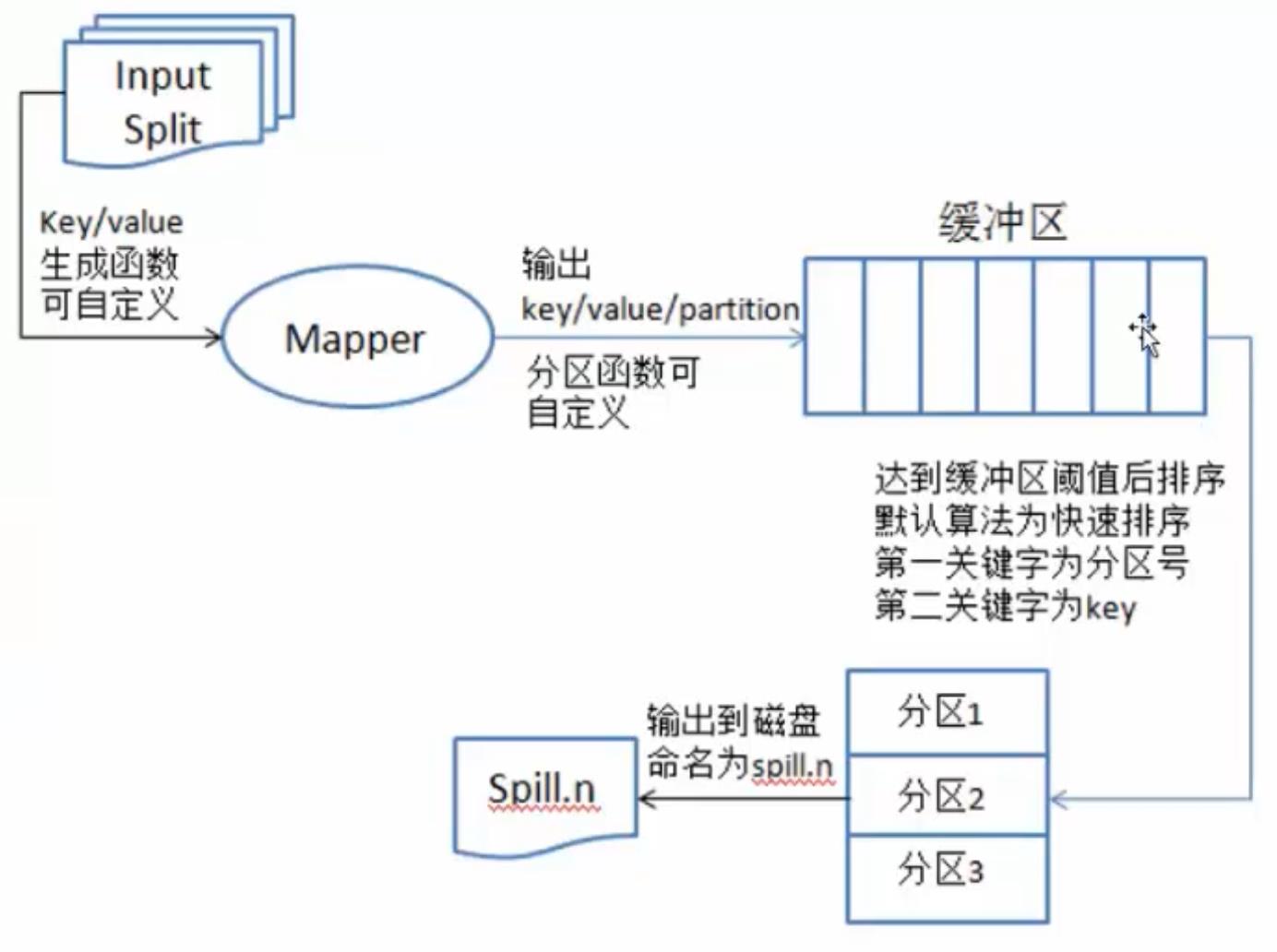
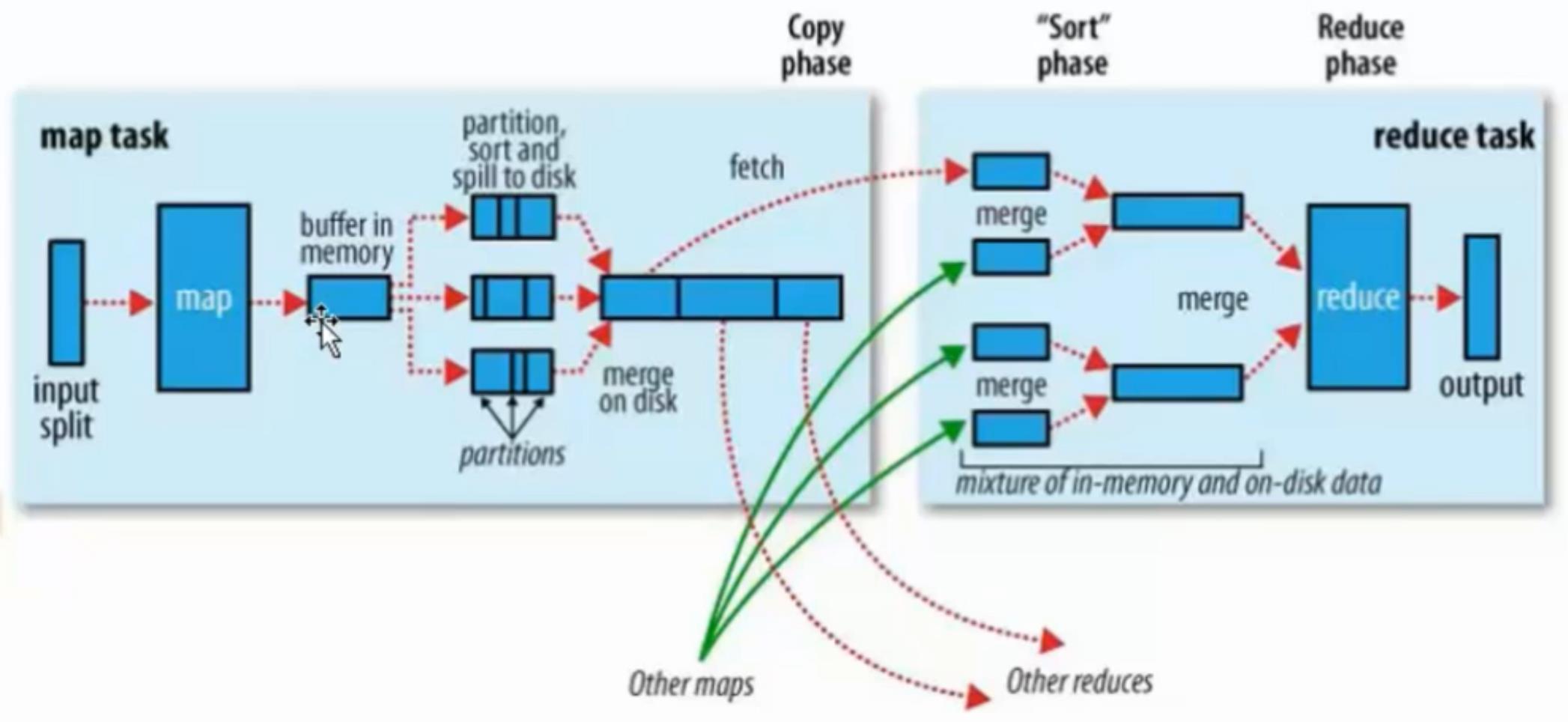
map:将数据进行处理
buffer in memory:达到80%数据时,将数据锁在内存上,将这部分输出到磁盘上
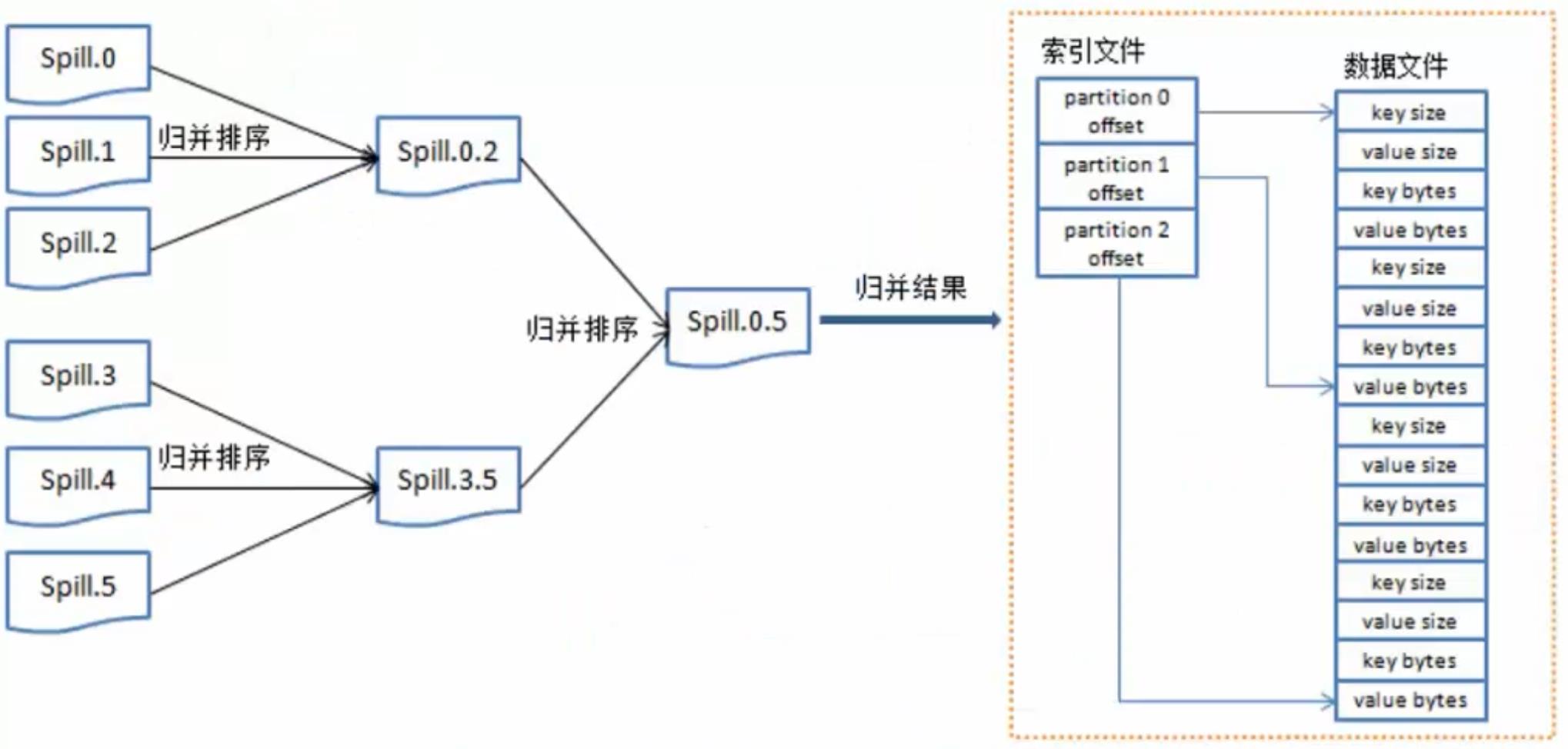
partitions:在磁盘上有很多"小的数据",将这些数据进行归并排序。
merge on disk:将所有的"小的数据"进行合并。
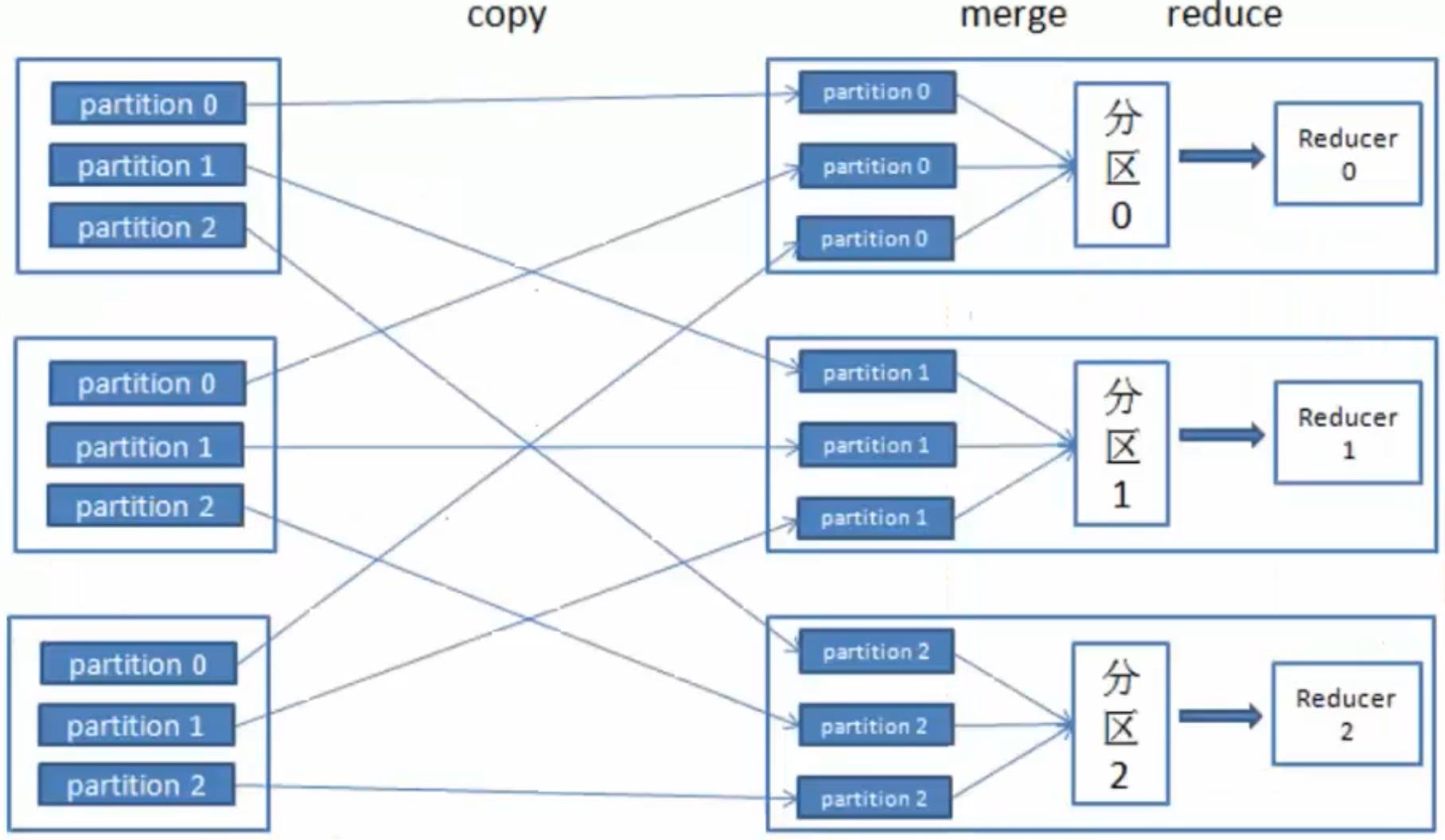
reduce:不同的reduce任务,会从map中对应的任务中copy数据
在reduce中同样要进行merge操作
MapReduce架构
- MapReduce架构 1.X
- JobTracker:负责接收客户作业提交,负责任务到作业节点上运行,检查作业的状态
- TaskTracker:由JobTracker指派任务,定期向JobTracker汇报状态,在每一个工作节点上永远只会有一个TaskTracker
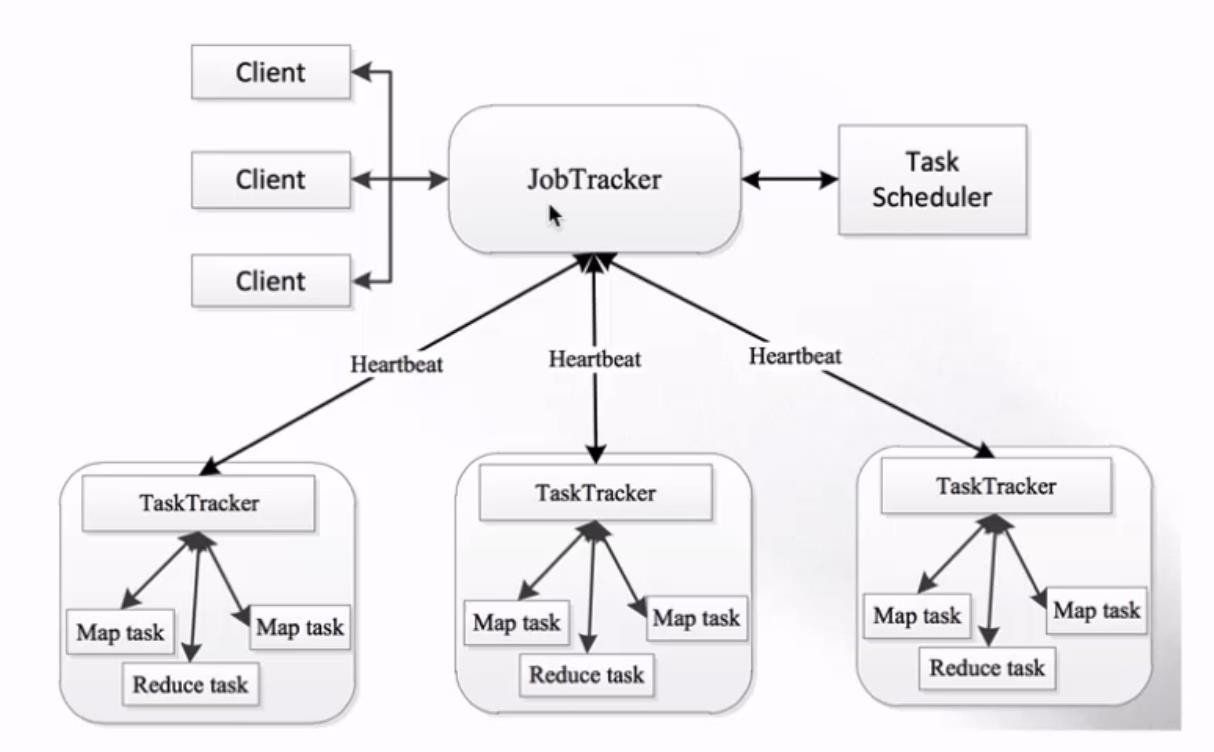
-
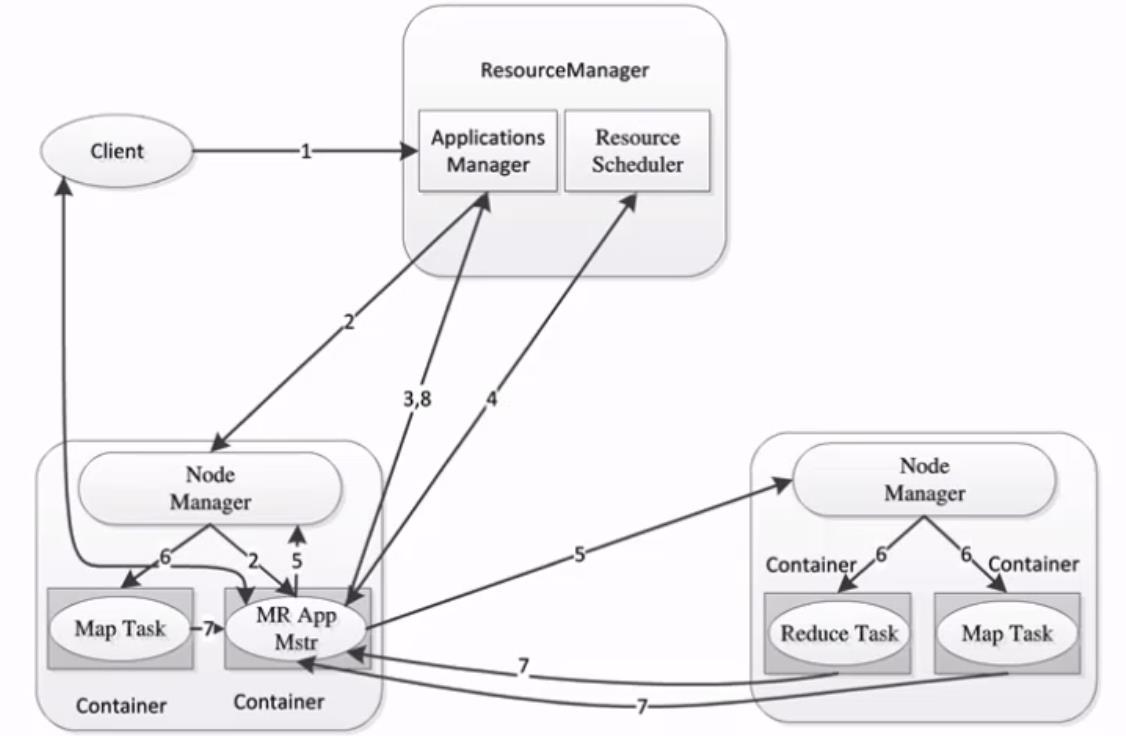
MapReduce2.X架构
- ResourceManager:负责资源的管理,负责提交任务到NodeManager所在的节点运行,检查节点的状态
- NodeManager:由ResourceManager指派任务,定期向ResourceManager汇报状态
加油!
感谢!
努力!
以上是关于MapReduce 实战的主要内容,如果未能解决你的问题,请参考以下文章