Spark2.3.1中用各种模式来跑官方Demo
Posted puppey
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark2.3.1中用各种模式来跑官方Demo相关的知识,希望对你有一定的参考价值。
1 使用单机local模式提交任务
local模式也就是本地模式,也就是在本地机器上单机执行程序。使用这个模式的话,并不需要启动Hadoop集群,也不需要启动Spark集群,只要有一台机器上安装了JDK、Scala、Spark即可运行。
进入到Spark2.1.1的安装目录,命令是:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7
执行命令,用单机模式运行计算圆周率的Demo:
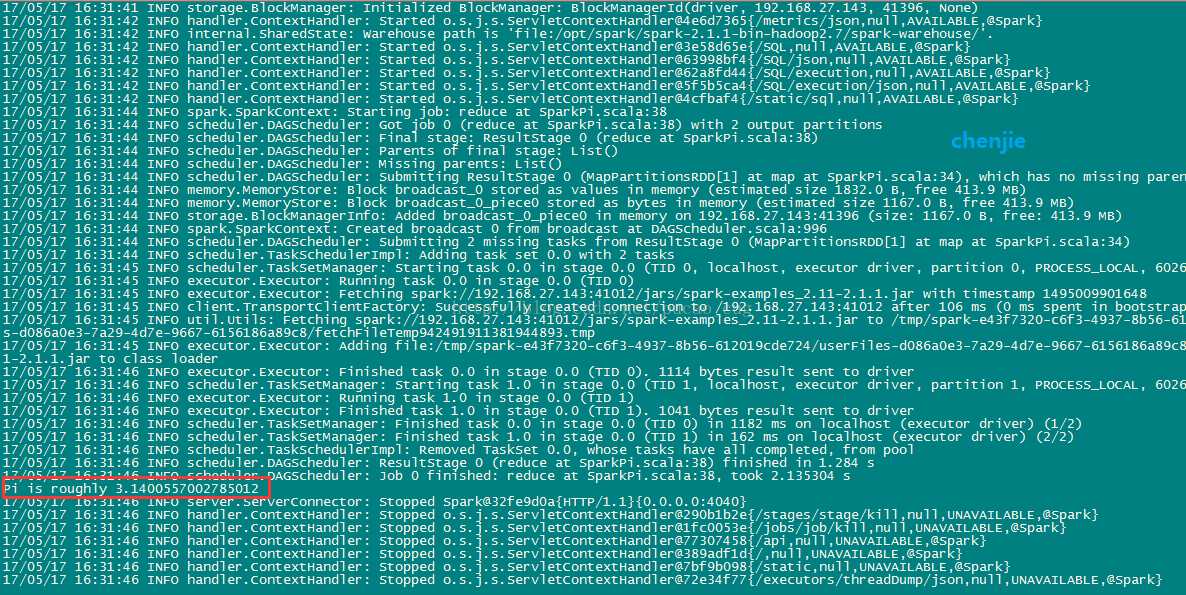
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local examples/jars/spark-examples_2.11-2.1.1.jar
如图:
2 使用独立的Spark集群模式提交任务
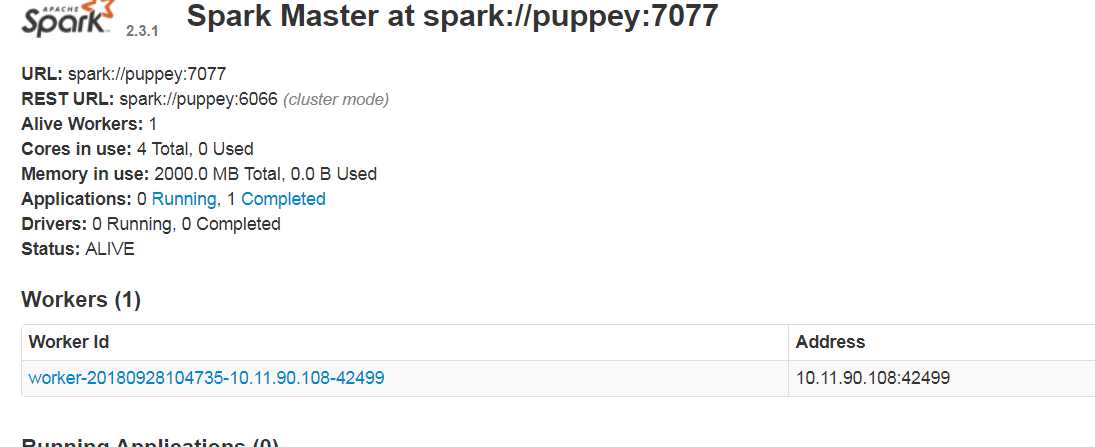
这种模式也就是Standalone模式,使用独立的Spark集群模式提交任务,需要先启动Spark集群,但是不需要启动Hadoop集群。启动Spark集群的方法是进入$SPARK_HOME/sbin目录下,执行start-all.sh脚本,启动成功后,可以访问下面的地址看是否成功:
http://Spark的Marster机器的IP:8080/
如图:
执行命令,用Standalone模式运行计算圆周率的Demo:
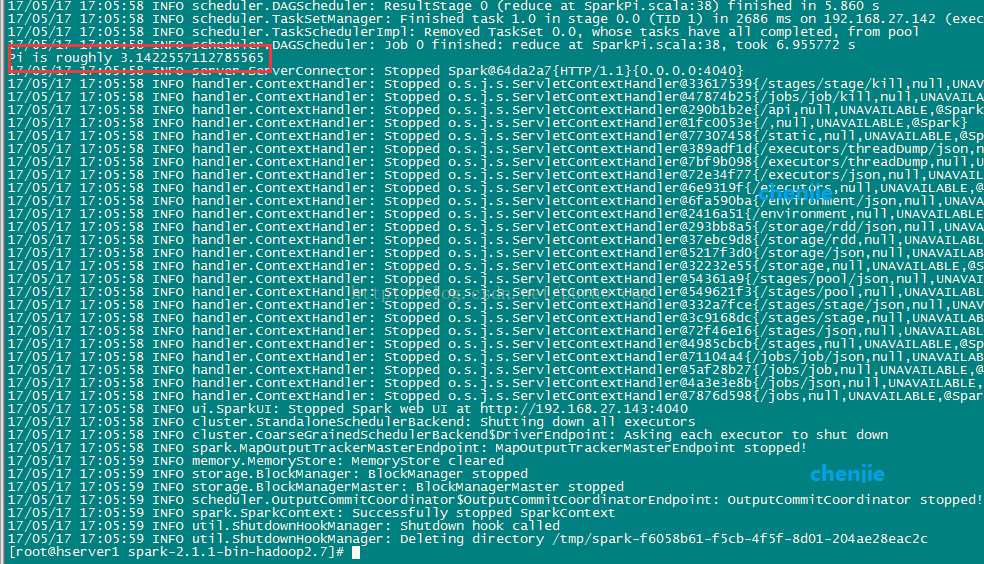
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.27.143:7077 examples/jars/spark-examples_2.11-2.1.1.jar
如图:
以上是关于Spark2.3.1中用各种模式来跑官方Demo的主要内容,如果未能解决你的问题,请参考以下文章
01_PC单机Spark开发环境搭建_JDK1.8+Spark2.3.1+Hadoop2.7.1
大数据技术之_03_Hadoop学习_02_入门_Hadoop运行模式+本地运行模式+伪分布式运行模式+完全分布式运行模式(开发重点)+Hadoop编译源码(面试重点)+常见错误及解决方案(示例代(代