[模型优化]模型欠拟合及过拟合判断优化方法
Posted ljt1412451704
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[模型优化]模型欠拟合及过拟合判断优化方法相关的知识,希望对你有一定的参考价值。
[模型优化]模型欠拟合及过拟合判断、优化方法
一、模型欠拟合及过拟合简介
模型应用时发现效果不理想,有多种优化方法,包含:
-
- 添加新特征
- 增加模型复杂度
- 减小正则项权重
- 获取更多训练样本
- 减少特征数目
- 增加正则项权重
具体采用哪种方法,才能够有效地提高模型精度,我们需要先判断模型是欠拟合,还是过拟合,才能确定下一步优化方向。
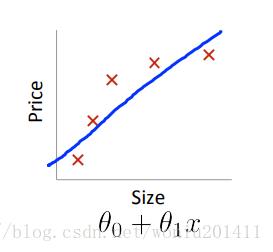
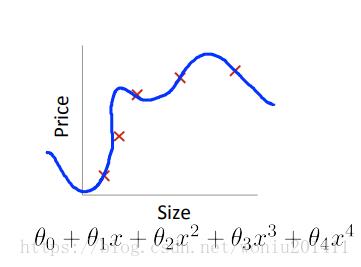
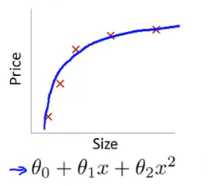
图1
模型欠拟合,即高偏差(high bias),是指模型未训练出数据集的特征,导致模型在训练集、测试集上的精度都很低。如图1左图所示。
模型过拟合,即高方差(high variance),是指模型训练出包含噪点在内的所有特征,导致模型在训练集的精度很高,但是应用到新数据集时,精度很低。如图1右图所示。
二、模型欠拟合及过拟合判断
1、数据集划分
数据集划分为训练集(Training set 80%)、测试集集(Test set 20%),损失函数定义为:
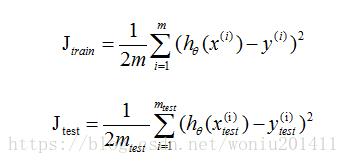
2、绘制损失函数随数据集增加的学习曲线
随着训练集样本的增加(m=1,2,3,....),训练集和测试集的损失函数变化趋势,如下图2所示:
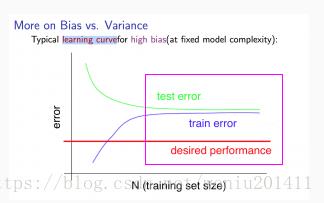
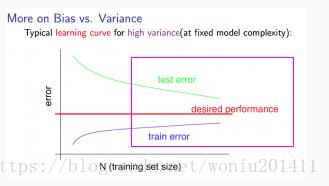
图2
模型欠拟合(高偏差),如图2左图所示,拥有足够的训练样本时,训练误差和测试误差都很高,并且训练误差约等于测试误差。
模型过拟合(高方差),如图2右图所示,随着训练样本的增加,训练误差在增加,测试误差在减少,但训练误差远远小于测试误差,J(train)<< J(test)。
注:准备几个不同时间窗口、不同范围的训练集和测试集,然后在不同数据集里分别对模型进行交叉验证,这是工业界判断模型欠拟合或过拟合的最常用方法。
三、模型欠拟合与过拟合的优化方法
1、模型欠拟合
1)添加新特征
从业务思路上构造新特征是最重要的优化措施!!这个思路对于模型效用的提升是根本性的,是源头上的突破。衍生变量的构建,可以从以下两个方面考虑:
有没有更加明显且直观的规则、指标可以代替复杂的建模;
有没有一些明显的业务逻辑在前期的建模阶段被忽视。
2)模型优化:提升模型复杂度
模型算法,不同的建模算法针对不同的业务场景有不同的表现,尝试不同的建模算法,从中比较,择优者而用之。
细分群体,建立多个模型,一一对应不同的核心客户群体。
3)减少正则项权重
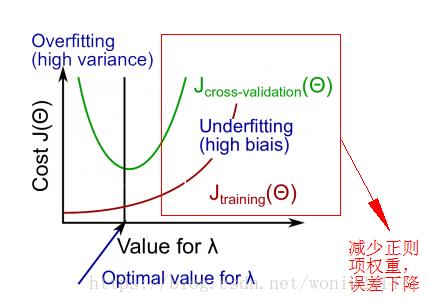
2、模型过拟合
1)重新清洗数据,导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
2)获取更多的训练样本,
由于模型训练了包含噪音在内的所有特征,导致模型过拟合,通过获取更多的训练样本,可以衰减噪音权重。
3)减少特征数目
特征共线性检查,利用Pearson相关系数计算变量之间的线性相关性,如果自变量中属于中度以上线性相关的多个变量,只需要保留一个就可以。
重要特征筛选,利用决策树模型,筛选出重要特征。
数据降维,主成分分析,保留特征变量重要差异。
4)增加正则项权重
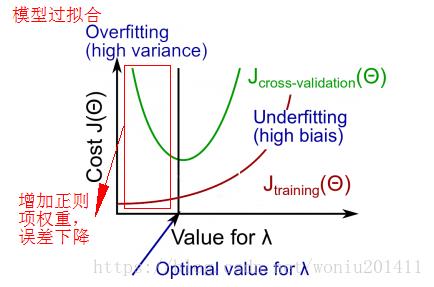
参考资料:
1、斯坦福大学,machie learning课程
https://www.coursera.org/learn/machine-learning/resources/LIZza
2、《数据挖掘与数据化运营实战》,第8章,常见的数据处理技巧
以上是关于[模型优化]模型欠拟合及过拟合判断优化方法的主要内容,如果未能解决你的问题,请参考以下文章