如何手动优化神经网络模型
Posted 清青大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何手动优化神经网络模型相关的知识,希望对你有一定的参考价值。
来源:数据派THU(ID:DatapiTHU)
▔
翻译:陈丹
校对:车前子
深度学习的神经网络是采用随机梯度下降优化算法对训练数据进行拟合。
利用误差反向传播算法对模型的权值进行更新。优化和权值更新算法的组合是经过仔细挑选的,是目前已知的最有效的拟合神经网络的方法。
然而,也可以使用交替优化算法将神经网络模型拟合到训练数据集。这是一个有用的练习,可以了解更多关于神经网络的是如何运转的,以及应用机器学习时优化的中心性。具有非常规模型结构和不可微分传递函数的神经网络,也可能需要它。
在本教程中,您将了解如何手动优化神经网络模型的权重。
如何从头开始开发神经网络模型的正向推理通路。
如何优化二值分类感知器模型的权值。
如何利用随机爬山算法优化多层感知器模型的权值。

教程概述
优化神经网络
它们是受大脑结构和功能的启发而来的,由节点和层次组成的模型。神经网络模型的工作原理是将给定的输入向量传播到一个或多个层,以产生可用于分类或回归预测建模的数值输出。
通过反复将模型暴露在输入和输出示例中,并调整权重以使模型输出相对于期望输出的误差最小来训练模型。这就是所谓的随机梯度下降优化算法。模型的权值是使用微积分中的一个特定规则来调整的,即将误差按比例分配给网络中的每个权重。这被称为反向传播算法。
利用反向传播进行权值更新的随机梯度下降优化算法是训练神经网络模型的最佳方法。然而,这并不是训练神经网络的唯一方法。
也就是说,我们可以定义一个神经网络模型结构,并使用给定的优化算法为模型找到一组权重,从而使预测误差最小或分类精度达到最大。
交替优化算法通常来说比反向传播的随机梯度下降算法效率更低。然而,在某些特定情况下,它可能更有效,例如非标准网络体系结构或不可微分的传递函数。
在训练机器学习的算法中,特别是神经网络中,展示优化的中心性是一个有趣的练习。
接下来,让我们探索如何使用随机爬山算法训练一个称为感知器模型的简单单节点神经网络。
优化感知器模型
感知器算法
(https://machinelearningmastery.com/implement-perceptron-algorithm-scratch-python/)
是最简单的人工神经网络。
它是一个单神经元模型,可用于两类分类问题,为以后开发更大的网络提供了基础。
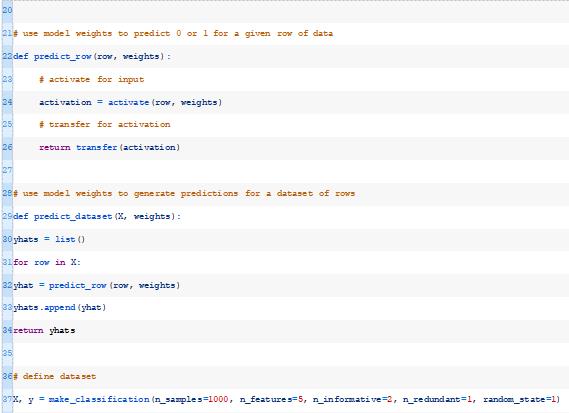
首先,让我们定义一个综合二进制分类问题,我们可以用它作为优化模型的焦点。
我们可以使用make_classification()
(https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html)
函数定义一个包含1000行和5个输入变量的二分类问题。
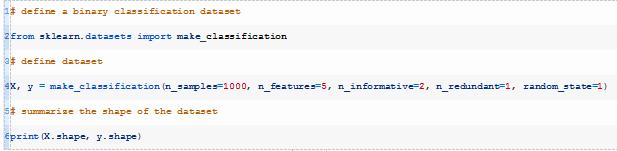
运行上述示例,打印出所创建数据集的形状,以确定符合我们的预期。

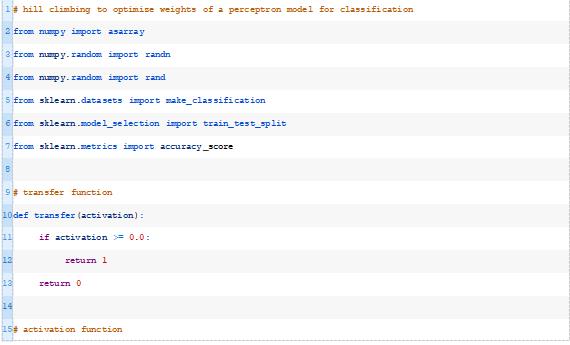
感知器模型有一个节点,它对数据集中的每一列都有一个输入权重。
每个输入值乘以其相应的权重得到一个加权和,然后添加一个偏差权重,就像回归模型中的截距系数一样。这个加权和称为活性值。最后,对活性值进行解释并用于预测类标签,1表示正激活,0表示负激活。
在优化模型权重之前,我们必须建立模型并相信它的运作方式。
这被称为激活函数,或传递函数;后一个名称更传统,是我的首选。
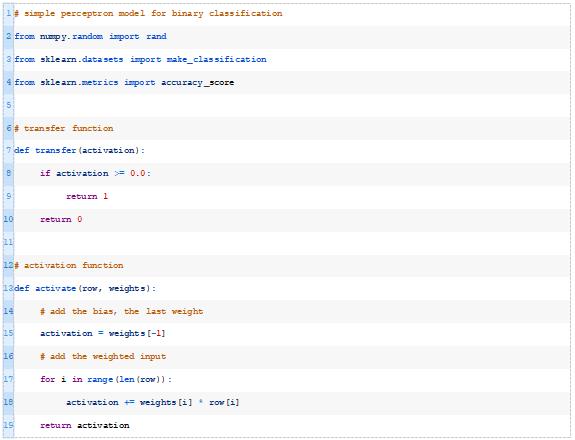
下面的transfer()函数接受模型的激活并返回一个类标签,class=1表示正激活或零激活,class=0表示负激活。这称为阶跃函数。
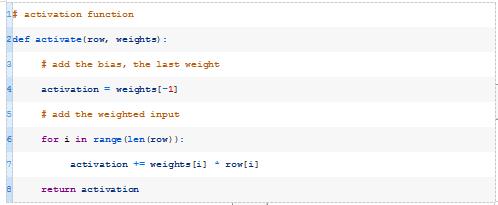
接下来,我们可以开发一个函数,该函数计算来自数据集的给定输入行的模型活性值。
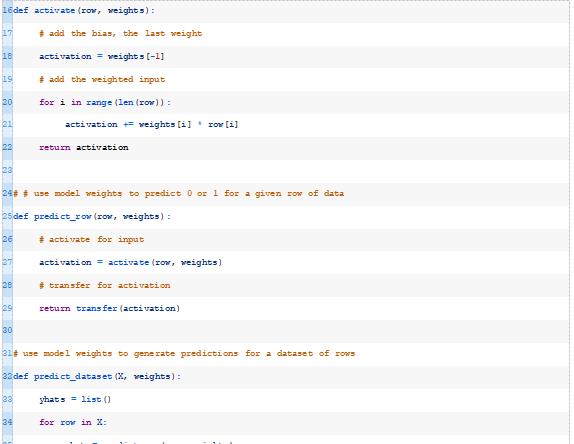
此函数将获取模型的数据行和权重,并计算输入的加权和以及偏差权重。下面的activate()函数实现了这一点。
注意:
我们特意使用简单的Python列表和命令式编程风格,而不是NumPy的数组或列表压缩,是为了让Python初学者更易读懂。您可以随意优化它,并在下面的注释中发布您的代码。
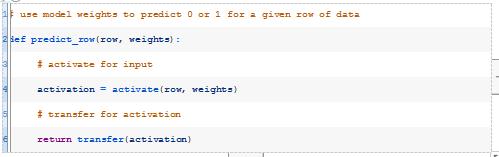
接下来,我们可以一起使用activate()和transfer()函数来生成给定数据行的预测。下面的predict_row()函数实现了这一点。
接下来,我们可以为给定数据集中的每一行调用predict_row()函数。下面的predict_dataset()函数实现了这一点。
同样,我们有意使用简单的命令式编码方式来提高可读性,而不是列表压缩。

最后,我们可以使用该模型对我们的合成数据集进行预测,以确认它都是正确工作的。
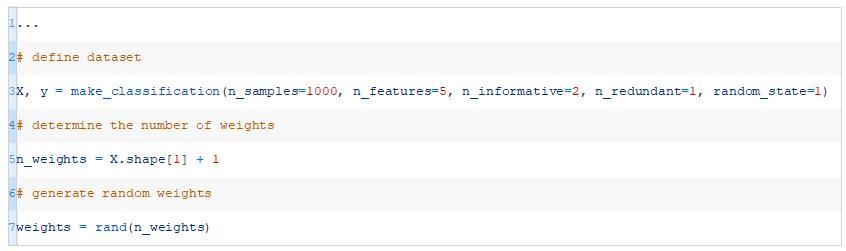
我们可以使用rand()函数生成一组随机的模型权重。
回想一下,我们需要为每个输入赋予一个权重(在这个数据集中有五个输入),再加上一个额外的权重作为偏移权重。
然后我们可以将这些权重与数据集一起使用来进行预测。


我们可以将所有这些整理在一起,并演示用我们的简单感知器模型进行分类。下面列出了完整的示例。
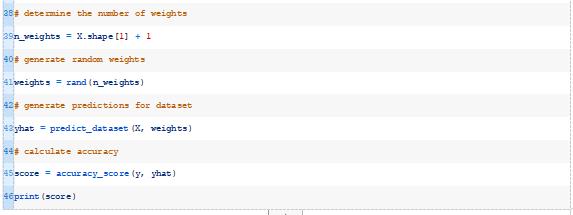
运行该示例将为训练数据集中的每个示例生成一个预测,然后打印出分类预测的准确度。
注意:
您的结果可能会因为算法或评估过程的随机性或数值精度的差异而有所不同
(https://machinelearningmastery.com/different-results-each-time-in-machine-learning/)
。考虑运行该示例几次并比较平均结果。
如果给定一组随机权重和一个每类中有相同数量示例的数据集,我们期望大约50%的准确率,这与我们在本例中看到的差不多。

现在,我们可以优化数据集的权重,以获得该数据集的良好准确度。
首先,我们需要将数据集分成训练集和测试集。重要的是要保留一些未用于优化模型的数据,以便在对新数据进行预测时,我们可以对模型的性能进行合理的估计。
我们将使用67%的数据进行培训,剩下的33%作为测试集来评估模型的性能。

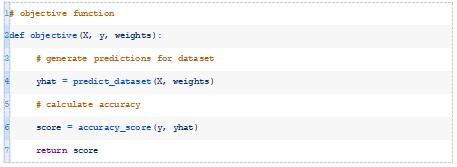
优化算法需要一个目标函数来优化。它必须取一组权重,并返回一个与更好的模型相对应的最小化或最大化的分数。
在这种情况下,我们将使用一组给定的权重来评估模型的准确性,并返回分类精度,这必须使其最大化。
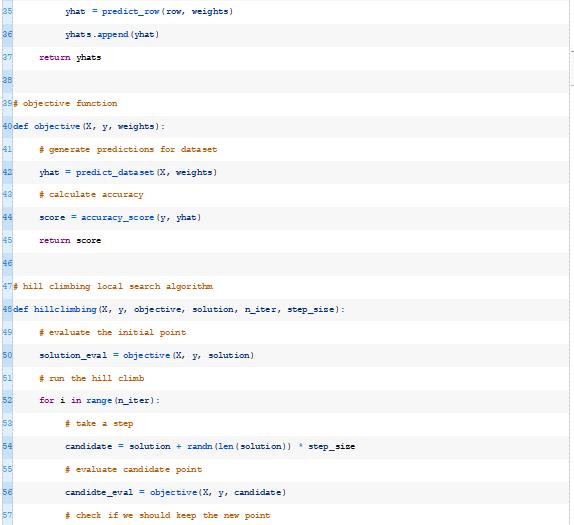
下面的objective()函数通过给定数据集和一组权重来实现这一点,并返回模型的精度。
接下来,我们可以定义随机爬山算法
(https://machinelearningmastery.com/stochastic-hill-climbing-in-python-from-scratch/)
。
该算法需要一个初始解(例如随机权重),并且会不断地对解进行小的修改,并检查它是否会产生一个性能更好的模型。对当前解决方案所做的更改量由“步长”超参数控制。此过程将持续固定次数的迭代,也作为超参数提供。
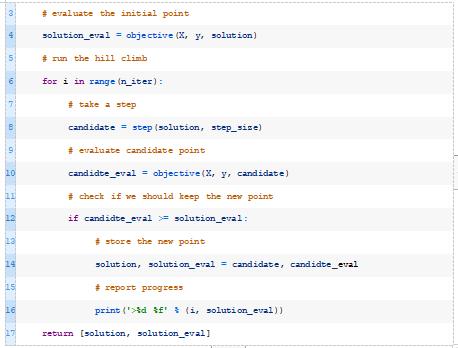
下面的hillclimbing()函数实现了这一点,它将数据集、目标函数、初始解和超参数作为参数,并返回找到的最佳权重集和估计的性能。
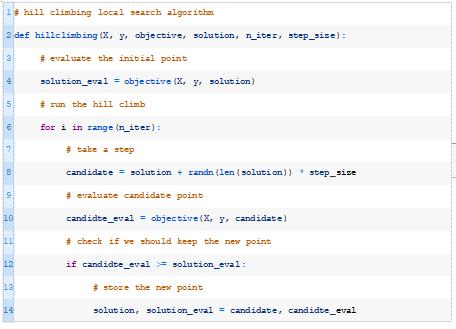

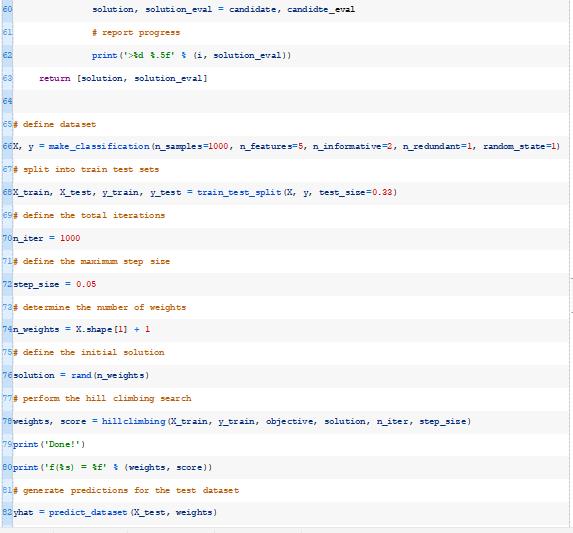
然后我们可以调用这个函数,传入一组权重作为初始解,将训练数据集作为优化模型的数据集。
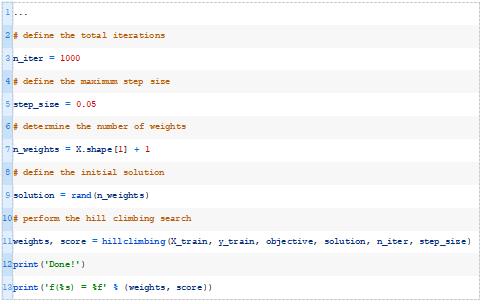
最后,我们可以在测试数据集上评估最佳模型并报告性能。
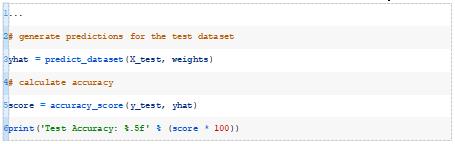
结合这一点,下面列出了在合成二进制优化数据集上优化感知器模型权重的完整示例。


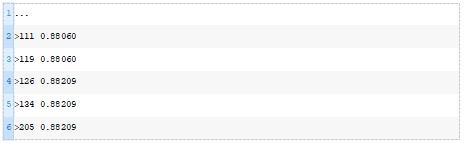
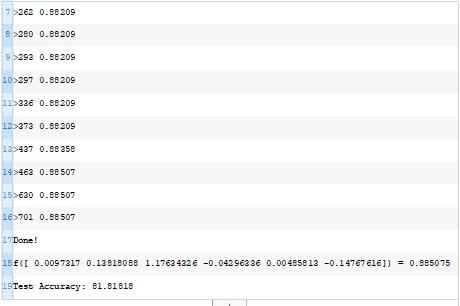
每次对模型进行改进时,运行示例将报告迭代次数和分类精度。
在搜索的最后,报告了最佳权重集在训练数据集上的性能,并计算和报告了同一模型在测试数据集上的性能。
注意:
您的结果可能会因为算法或评估过程的随机性或数值精度的差异而有所不同
(https://machinelearningmastery.com/different-results-each-time-in-machine-learning/)。
考虑运行该示例几次并比较平均结果。
在这种情况下,我们可以看到优化算法找到了一组权重,在训练数据集上达到了88.5%的准确率,在测试数据集上达到了81.8%的准确率。
现在我们已经熟悉了如何手动优化感知器模型的权重,让我们看看如何扩展示例来优化多层感知器(Multilayer Perceptron,MLP)模型的权重。
优化多层感知器
多层感知器(MLP)模型是一个具有一个或多个层次的神经网络,每一层都有一个或多个节点。
它是感知器模型的扩展,可能是应用最广泛的神经网络(深度学习)模型。
在本节中,我们将在上一节所学的基础上,优化每层具有任意数量层和节点的MLP模型的权重。
首先,我们将开发模型并用随机权重进行测试,然后使用随机爬山算法优化模型权重。
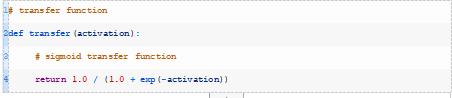
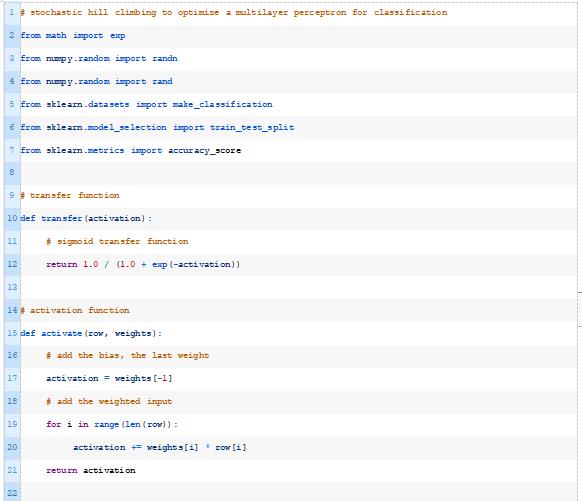
当使用MLPs进行二分类时,通常使用sigmoid变换函数(也称为logistic函数)来代替感知器中使用的阶跃变换函数。
此函数输出0-1之间的实数,表示二项式概率分布
(https://machinelearningmastery.com/discrete-probability-distributions-for-machine-learning/)
,例如一个示例属于1类的概率。下面的transfer()函数实现了这一点。
我们可以使用上一节中相同的activate()函数。在这里,我们将使用它来计算给定层中每个节点的激活。
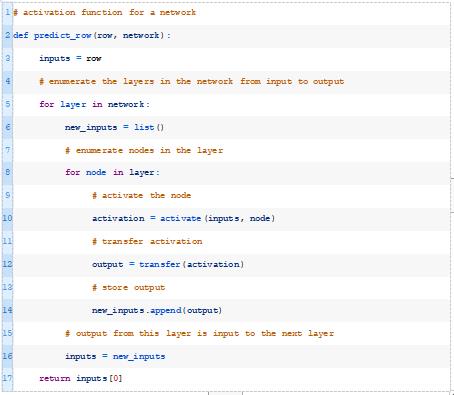
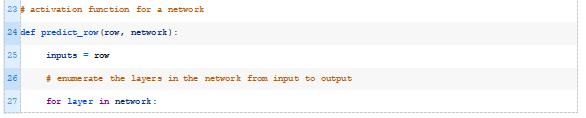
predict_row()函数必须替换为更精细的版本。
我们将把我们的网络定义为一个列表。每个层将是一个节点列表,每个节点将是一个权重列表或数组。
为了计算网络的预测,我们简单地枚举层,然后枚举节点,然后对每个节点的输出进行激活计算和变换。在这种情况下,我们将对网络中的所有节点使用相同的变换函数,尽管这不是必须的。
对于具有多个层的网络,上一层的输出用作下一层中每个节点的输入。然后返回网络中最后一层的输出。
下面的predict_row()函数实现了这一点。
例如,我们可以使用单个隐藏层和单个节点定义MLP,如下所示:

这实际上是一个感知器,尽管它有一个sigmoid变换函数。这很无聊。
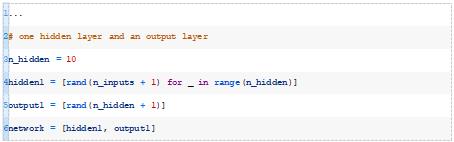
让我们定义一个具有一个隐藏层和一个输出层的MLP。第一个隐藏层将有10个节点,每个节点将从数据集中获取输入模式(例如5个输入)。输出层将有一个节点,从第一个隐藏层的输出接收输入,然后输出预测。

在计算分类精度之前,我们必须将预测四舍五入到分类标签0和1。
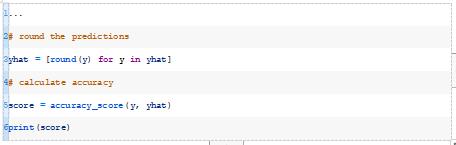
将这些整合在一起,在我们合成的二进制分类数据集上使用随机初始权重来评估MLP的完整示例如下所示。
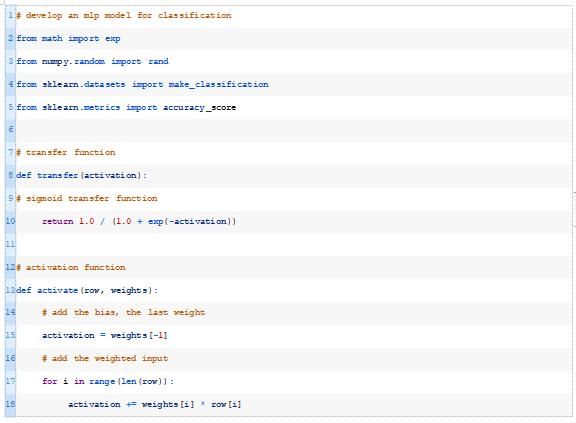
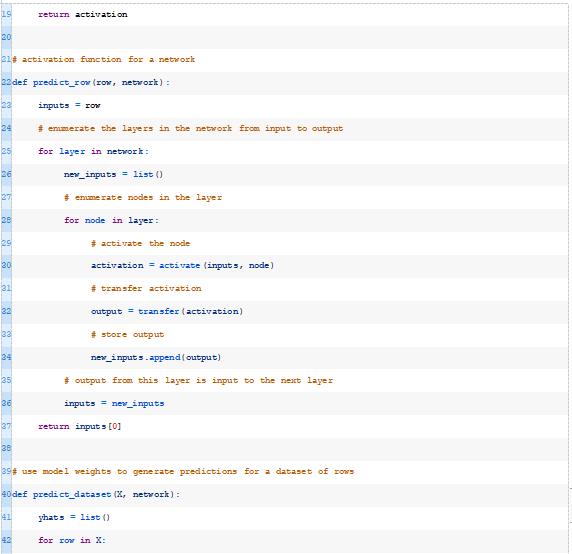
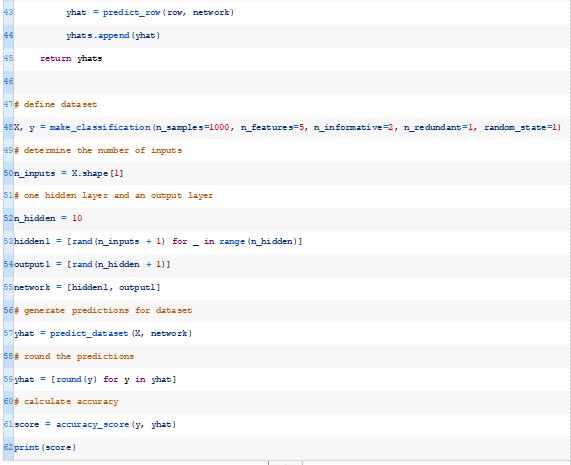
运行该示例将为训练数据集中的每个示例生成一个预测,然后打印预测的分类精度。
注意:
您的结果可能会因为算法或评估过程的随机性或数值精度的差异而有所不同
(https://machinelearningmastery.com/different-results-each-time-in-machine-learning/)
。考虑运行该示例几次并比较平均结果。
同样,我们希望在给定一组随机权重和一个数据集(每个类中有相同数量的示例)的情况下,准确率大约为50%,这与我们在本例中看到的差不多。

这与将爬山应用于感知器模型非常相同,只是在这种情况下,一个步骤需要修改网络中的所有权重。
为此,我们将开发一个新功能,创建一个网络副本,并在制作副本时对网络中的每个权重进行变异。
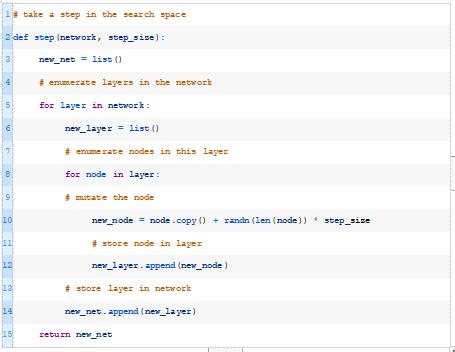
在搜索空间中,一个不那么激进的步骤可能是对模型中的权重子集进行一个小的更改,也许是由一个超参数控制的。这个作为扩展内容。
然后我们可以从hillclimbing()函数调用这个新的step()函数。

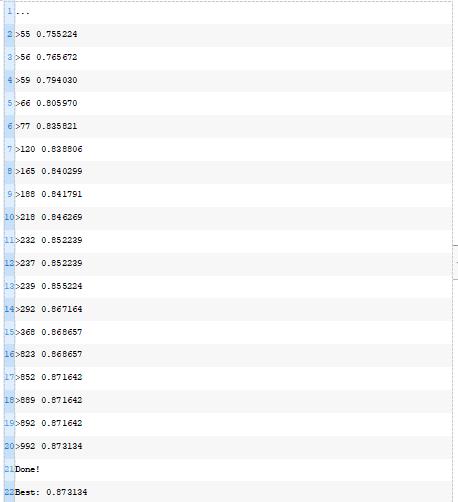
结合这一点,下面列出了应用随机爬山算法优化二分类MLP模型权重的完整示例。
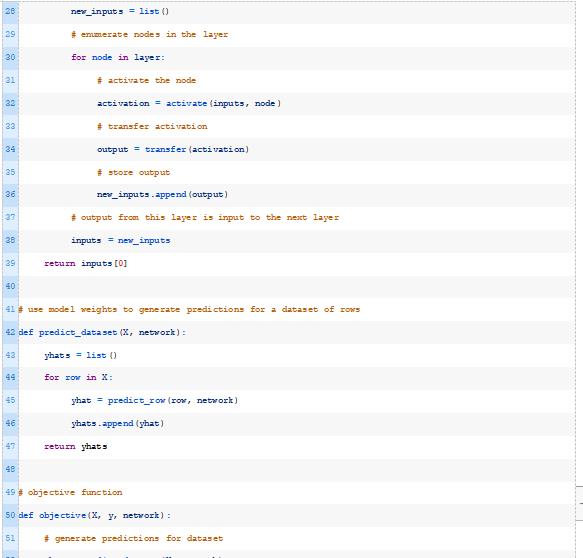
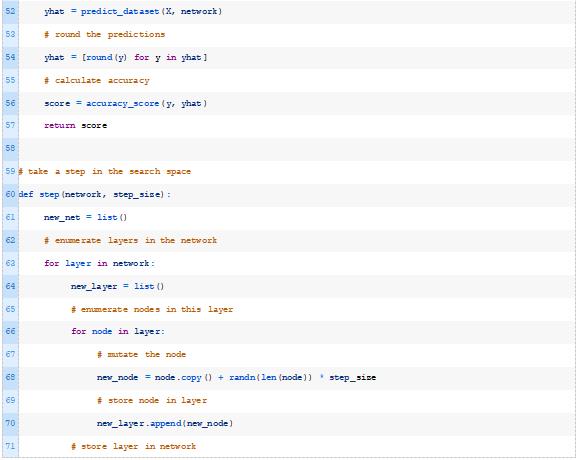
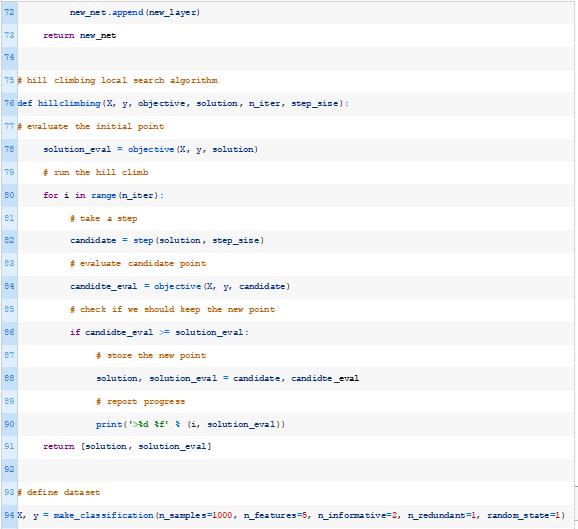
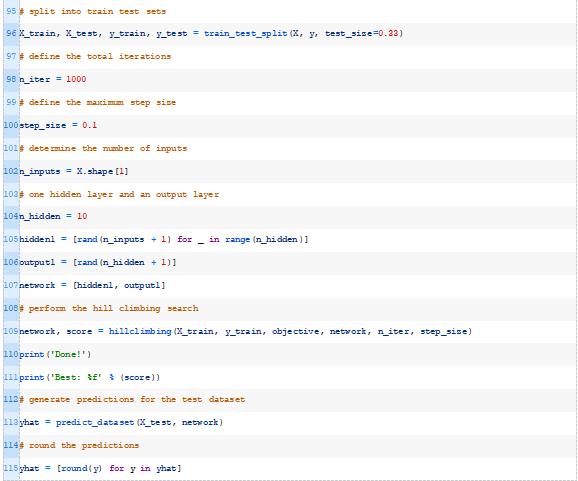

每次对模型进行改进时,运行示例将报告迭代次数和分类精度。
在搜索的最后,报告了最佳权重集在训练数据集上的性能,并计算和报告了同一模型在测试数据集上的性能。
注意:
您的结果可能会因为算法或评估过程的随机性或数值精度的差异而有所不同
(https://machinelearningmastery.com/different-results-each-time-in-machine-learning/)
。考虑运行该示例几次并比较平均结果。
在这种情况下,我们可以看到优化算法找到了一组权重,在训练数据集上达到了87.3%的准确率,在测试数据集上达到了大约85.1%的准确率。

进一步阅读
如果您想深入了解,本节将提供有关该主题的更多资源。
https://machinelearningmastery.com/train-test-split-for-evaluating-machine-learning-algorithms
https://machinelearningmastery.com/implement-perceptron-algorithm-scratch-python/
如何用Python编写反向传播的神经网络(从头开始):
https://machinelearningmastery.com/implement-backpropagation-algorithm-scratch-python/
sklearn.datasets.make_classification 接口:
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html
sklearn.metrics.accuracy_score 接口:
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html
https://numpy.org/doc/stable/reference/random/generated/numpy.random.rand.html
在本教程中,您了解了如何手动优化神经网络模型的权重。
如何从头开始开发神经网络模型的正向推理通路。
如何优化二分类感知器模型的权值。
如何利用随机爬山算法优化多层感知器模型的权值。
How to Manually Optimize Neural Network Models
https://machinelearningmastery.com/manually-optimize-neural-networks/
陈丹,复旦大学大三在读,主修预防医学,辅修数据科学。对数据分析充满兴趣,但初入这一领域,还有很多很多需要努力进步的空间。希望今后能在翻译组进行相关工作的过程中拓展文献阅读量,学习到更多的前沿知识,同时认识更多有共同志趣的小伙伴!
以上是关于如何手动优化神经网络模型的主要内容,如果未能解决你的问题,请参考以下文章
梯度下降算法
手写数字识别——利用keras高层API快速搭建并优化网络模型
我应该如何使用预训练模型优化神经网络以进行图像分类
深度学习之基础篇
优化与神经网络
什么是C10K问题,聊聊网络IO模型如何优化该问题
