深度学习之基础篇
Posted dyl222
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习之基础篇相关的知识,希望对你有一定的参考价值。
1、神经网络中损失函数和优化函数的作用
训练出一个网络模型之后如何对模型进行评估?往往是衡量预测值与真实值之间的差异程度,这就是通过损失函数来完成的。另外损失函数也是神经网络中优化的目标函数,神经网络训练或者优化的过程就是最小化损失函数的过程,损失函数越小,说明模型的预测值就越接近真实值,模型的准确性也就越好。那么为了最小化损失函数则需要对网络模型的参数进行更新,确定如何更新参数这时则需要选择合适的优化函数(用以确定对网络模型参数进行更新的方法,步长和方向的确定)。我们都知道,神经网络模型训练得以实现是经过前向传播计算LOSS,根据LOSS的值进行反向推到,进行相关参数的调整。这个过程需要在loss值的指导下进行,因此在优化时需要传入loss值。
2、神经网络中的收敛
一般我们可以设置一个迭代次数阈值,当损失loss的变化小于一个很小的值,或者迭代次数达到阈值上限,那么我们一般就认为模型已经收敛了。
在实际应用中,如果你用的是TensorFlow之类的工具,可以在Tensorboard上看loss的变化情况,如果曲线趋于平的,那么基本就可以认为是收敛了。
另外收敛只看训练集的损失值,与测试集无关。
3、train loss与val loss结果分析
train loss 不断下降,val loss不断下降,说明网络仍在学习;
train loss 不断下降,val loss趋于不变,说明网络过拟合;
train loss 趋于不变,val loss不断下降,说明数据集可能有问题;
train loss 趋于不变,val loss趋于不变,说明学习可能已经收敛;
train loss 不断上升,val loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
4、影响神经网络收敛速度的不同因素
1)对于收敛路径而言,梯度的方向和步长的大小显然是对收敛速度两个最直接的因素。对于网络优化问题来说也是两个角度,一个是学习率衰减,决定了梯度下降的步长,包括AdaGrad、RMSprop、AdaDelta;另一个就是梯度方向,避免陷入局部最优,包括动量法、Nesterov加速梯度、梯度截断等;还包括mini batch方法,引入随机噪声又能平滑梯度,相交于一次性全局梯度和单个样本随机梯度。
2)参数的初始化也很重要,既要避免参数全部一致导致学习特征单一,又要避免激活函数(sigmoid)的净输入陷入饱和区导致梯度为0无法学习。随机初始化包括高斯分布以及Xavier[‘ze?v?r]。
3)数据预处理就是归一化。简单地讲,由于特征量度不同,导致Loss的等高线成为不均匀的椭圆状,在像最优点下降过程中,梯度方向难免出现震荡,使得收敛速度变缓。引入归一化后,使得Loss等高线变为更均匀的圆形,约束梯度下降的方向指向正中圆心最优点,得到最优的收敛路径。归一化方法包括缩放归一化和标准分布归一化。
4)训练过程中,层与层之间输入输出需要保持分布一致性,否则会出现内部协变量偏移,越深的层次,现象越明显。深度神经网络中,误差通过梯度反向传播,分布不一致会导致参数更新不是最优的方向,阻碍了收敛最优点。解决方案是引入输入输出规范化,包括批规范化BN和层规范化LN。
5)残差网络ResNet,ResNet是针对CNN训练中层次过深导致退化问题。简单来说,卷积用来提取目标特征,而越深的卷积层使得提取的特征更加抽象,从而在测试集上得到更好的准确率。同时,层次过深又阻碍了误差反向传播,比如梯度爆炸和梯度弥散,使得参数得不到最优的更新,在训练集合上收敛不到最优。对此引入残差网络,将输入作为旁路恒等映射到输出端,这个映射使得误差反向传播时,保证梯度的稳定。在保持深层次的基础上,使得各层的参数得到很好的更新,有利于模型的收敛。
5、梯度爆炸和梯度消失
写的很好的参照:
https://blog.csdn.net/qq_25737169/article/details/78847691
简单理解,就是在反向传播的算法过程中,由于我们使用了是矩阵求导的链式法则,有一大串连乘,如果连乘的数字在每层都是小于1的,则梯度越往前乘越小,导致梯度消失,而如果连乘的数字在每层都是大于1的,则梯度越往前乘越大,导致梯度爆炸。
比如我们在前一篇反向传播算法里面讲到了δ的计算,可以表示为:
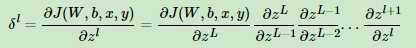
如果不巧我们的样本导致每一层的∂zl+1/∂zl都小于1,则随着反向传播算法的进行,我们的δl会随着层数越来越小,甚至接近越0,导致梯度几乎消失,进而导致前面的隐藏层的W,b参数随着迭代的进行,几乎没有大的改变,更谈不上收敛了。这个问题目前没有完美的解决办法。
导致梯度消失和梯度爆炸的原因:
两种情况下梯度消失经常出现,一是在深层网络中,二是采用了不合适的损失函数,比如sigmoid。梯度爆炸一般出现在深层网络和权值初始化值太大的情况下。梯度消失、爆炸,其根本原因在于反向传播训练法则,属于先天不足。
从深层网络角度来讲,不同层的学习速度差异很大,表现为网络中靠近输出的层学习的情况很好,靠近输入的层学习的很慢,有时甚至训练了很久,前几层的权值和刚开始随机初始化的值差不多。
解决梯度消失和梯度爆炸的方法:
由于导致这两种现象产生的根本原始是反向传播训练法则,所以可以从对w的控制以及激活函数着手。
为了避免梯度爆炸可以通过梯度剪切(这样处理其实并不粗糙,有些论文中也是这样处理的)和正则化的手段,从激活函数的选取方面选用relu激活函数。
通过合理的初始化权重能够减小梯度消失和梯度爆炸的情况,引入batch_norm也能一定程度减小梯度消失和梯度爆炸的情况。
以上是关于深度学习之基础篇的主要内容,如果未能解决你的问题,请参考以下文章
深度学习之初识篇——小白也能跑通的深度学习万能框架交通标识牌检测