Holt-Winters模型原理分析
Posted bonelee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Holt-Winters模型原理分析相关的知识,希望对你有一定的参考价值。
Holt-Winters模型原理分析及代码实现(python)
引言
最近实验室老师让我去预测景区内代步车辆的投放量,于是乎,本着“一心一意地输出年富力强的劳动力”这份初心,我就屁颠屁颠地去找资料,然后发现了Holt-Winters模型 , 感觉这个模型可以有,于是就去研究一番,并总结成这篇博客了。
原理分析
移动平均(The simple moving average (SMA))
直观上,最简单的平滑时间序列的方法是实现一个无权重的移动平均,目前已知的方法是用窗口函数,平滑统计量 St就是最近k个观察值的均值。公式如下: 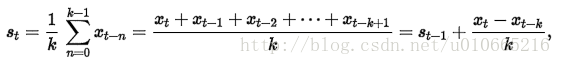
这样的方法存在明显的缺陷,当k比较小时,预测的数据平滑效果不明显,而且突出反映了数据最近的变化;当k较大时,虽然有较好的平滑效果,但是预测的数据存在延迟。而且最少需要k个值(窗口有限)。
加权移动平均
一种稍微复杂的方法是先选择一组权重因子来计算加权移动平均 
然后用这些权重来计算这些平滑统计量: 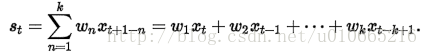
在实践中,通常在选择权重因子时,赋予时间序列中的最新数据更大的权重,并减少对旧数据的权重。这个方法也需要最少k个值,并且计算复杂。
简单指数平滑法
幸运地是有一种方法可以避免上述问题,它叫做指数平滑法。最简单的指数平滑法如下: 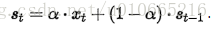
其中α是平滑因子,0 < α < 1。换句话说,平滑统计值St是当前统计值Xt与上一时间平滑值St-1的加权平均。这个简单指数平滑是很容易被应用的,因为只要有两个观察值就能计算了。这里α的选取,我们可以采用最小二乘来决定α(最小化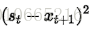
为什么被称为“指数”平滑法
从它的递推公式就能发现: 
简单指数平滑法适用于没有总体趋势的时间序列。如果用来处理有总体趋势的序列,平滑值将往往滞后于原始数据,除非α的值接近1,但这样一来就会造成不够平滑。
二次指数平滑
为了解决上述问题,于是引出了二次指数平滑,能够保留总体趋势信息。因为将指数平滑应用了两次,所以被称为二次指数平滑。与简单指数平滑相比,二次指数平滑加入了时间趋势统计量bt,公式如下: 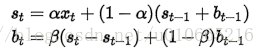
若要预测Xt后m天,公式如下:
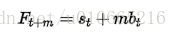
三次指数平滑
三次指数平滑将时间序列的季节性这一特征也考虑进去了。
季节性被定义为时间序列数据的趋势,它表现出每一个周期重复自身的行为,就像任何周期函数一样。“季节”这个词用来表示行为每隔时间段L就开始自我重复。在自然界中有不同类型的季节性“累加性”(additive)和“累乘性“(multiplicative),就像加法和乘法是数学的基本运算。
如果每个12月都比每个11月多卖出1000套公寓,我们就说这样的季节趋势是“累加性”的。可以用绝对增长来表示。如果我们在夏季比冬季多卖出10%的公寓,那么季节趋势在自然中是“累乘性”的。
累乘性公式如下: 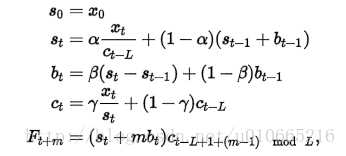
其中 α是数据平滑因子, 0 < α < 1;β是趋势平滑因子,0 < β < 1; γ是季节改变平滑因子0 < γ < 1。
初始化趋势估计b0的公式为: 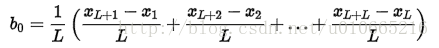
累加性公式如下: 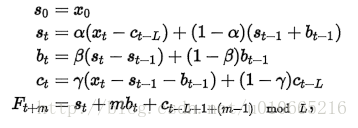
对三次指数平滑法而言,我们必须初始化一个完整的“季节”Ci的值,不过我们可以简单地设置为全1(针对累乘式)或全0(针对累加式)。只有当序列的长度较短时,我们才需要慎重考虑初始值的选取。
我们这里讲的Holt-Winters模型就是三次指数平滑法。哇,终于切入正题了。
所有的指数平滑法都要更新上一时间步长的计算结果,并使用当前时间步长的数据中包含的新信息。它们通过“混合”新信息和旧信息来实现,而相关的新旧信息的权重由一个可调整的拌和参数来控制。各种方法的不同之处在于它们跟踪的量的个数和对应的拌和参数的个数。三次指数平滑法,功能最强大,既能体现趋势性又能体现季节性,所以三次指数平滑法的参数最多,有三个。
以上是关于Holt-Winters模型原理分析的主要内容,如果未能解决你的问题,请参考以下文章
Holt-Winters -- Kibana5.4时间序列分析