fastdfs 有用
Posted shan1393
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了fastdfs 有用相关的知识,希望对你有一定的参考价值。
一、FastDFS解决什么样的问题
1、存储空间可扩展。
2、提供一个统一的访问方式。
使用FastDFS,分布式文件系统。存储空间可以横向扩展,可以实现服务器的高可用。支持每个节点有备份机。
二、什么是FastDFS
FastDFS是用c语言编写的一款开源的分布式文件系统。FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务。
三、FastDFS架构
FastDFS架构包括 Tracker server和Storage server。客户端请求Tracker server进行文件上传、下载,通过Tracker server调度最终由Storage server完成文件上传和下载。
Tracker server作用是负载均衡和调度,通过Tracker server在文件上传时可以根据一些策略找到Storage server提供文件上传服务。可以将tracker称为追踪服务器或调度服务器。
Storage server作用是文件存储,客户端上传的文件最终存储在Storage服务器上,Storage server没有实现自己的文件系统而是利用操作系统 的文件系统来管理文件。可以将storage称为存储服务器。
1、存储空间可扩展。
2、提供一个统一的访问方式。
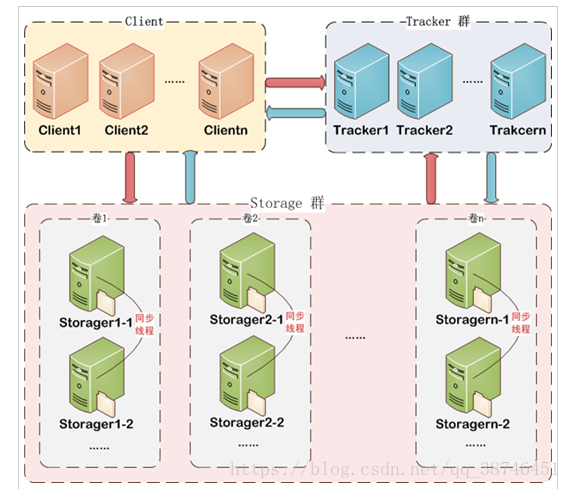
服务端两个角色:
Tracker:管理集群,tracker也可以实现集群。每个tracker节点地位平等。
收集Storage集群的状态。
Storage:实际保存文件
Storage分为多个组,每个组之间保存的文件是不同的。每个组内部可以有多个成员,组成员内部保存的内容是一样的,组成员的地位是一致的,没有主从的概念。
四、上传文件的流程
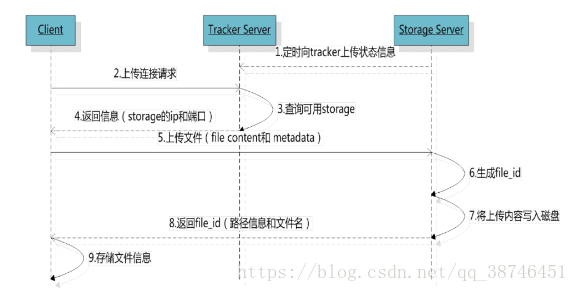
客户端上传文件后存储服务器将文件ID返回给客户端,次文件ID用于以后访问改文件的索引信息。文件索引信息包括:
组名,虚拟磁盘路径,数据两级目录,文件名。
比如:group/M00/02/44/wKqDrE348waaaaaaaaGkEIYJK42378.sh
n 组名:文件上传后所在的storage组名称,在文件上传成功后有storage服务器返回,需要客户端自行保存。
n 虚拟磁盘路径:storage配置的虚拟路径,与磁盘选项store_path*对应。如果配置了store_path0则是M00,如果配置了store_path1则是M01,以此类推。
n 数据两级目录:storage服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件。
n 文件名:与文件上传时不同。是由存储服务器根据特定信息生成,文件名包含:源存储服务器IP地址、文件创建时间戳、文件大小、随机数和文件拓展名等信息。
上传步骤:
1、加载配置文件,配置文件中的内容就是tracker服务的地址。
配置文件内容:tracker_server=192.168.25.121:22122
2、创建一个TrackerClient对象。直接new一个。
3、使用TrackerClient对象创建连接,获得一个TrackerServer对象。
4、创建一个StorageServer的引用,值为null
5、创建一个StorageClient对象,需要两个参数TrackerServer对象、StorageServer的引用
6、使用StorageClient对象上传图片。
7、返回数组。包含组名和图片的路径。
Java测试代码如下:
public class FastDFSTest {
@Test
public void testFileUpload() throws Exception {
// 1、加载配置文件,配置文件中的内容就是tracker服务的地址。
ClientGlobal.init("D:/workspaces/term93/demo-manager-web/src/main/resources/resource/client.conf");
// 2、创建一个TrackerClient对象。直接new一个。
TrackerClient trackerClient = new TrackerClient();
// 3、使用TrackerClient对象创建连接,获得一个TrackerServer对象。
TrackerServer trackerServer = trackerClient.getConnection();
// 4、创建一个StorageServer的引用,值为null
StorageServer storageServer = null;
// 5、创建一个StorageClient对象,需要两个参数TrackerServer对象、StorageServer的引用
StorageClient storageClient = new StorageClient(trackerServer, storageServer);
// 6、使用StorageClient对象上传图片。
//扩展名不带“.”
String[] strings = storageClient.upload_file("D:/Documents/Pictures/images/200811281555127886.jpg", "jpg", null);
// 7、返回数组。包含组名和图片的路径。
for (String string : strings) {
System.out.println(string);
}
}
}
五、文件下载
文件下载和文件上传原理差不多
另一篇
功能简介
FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
主页地址:https://github.com/happyfish100/fastdfs
FastDFS从2008年7月发布至今,已推出31个版本,后续完善和优化工作正在持续进行中。目前已有多家公司在生产环境中使用FastDFS。
FastDFS是一款类Google FS的开源分布式文件系统,它用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX系统。它只能通过专有API对文件进行存取访问,不支持POSIX接口方式,不能mount使用。准确地讲,Google FS以及FastDFS、mogileFS、HDFS、TFS等类Google FS都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
FastDFS的设计理念
FastDFS是为互联网应用量身定做的分布式文件系统,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标。和现有的类Google FS分布式文件系统相比,FastDFS的架构和设计理念有其独到之处,主要体现在轻量级、分组方式和对等结构三个方面。
- 轻量级
FastDFS只有两个角色:Tracker server和Storage server。Tracker server作为中心结点,其主要作用是负载均衡和调度。Tracker server在内存中记录分组和Storage server的状态等信息,不记录文件索引信息,占用的内存量很少。另外,客户端(应用)和Storage server访问Tracker server时,Tracker server扫描内存中的分组和Storage server信息,然后给出应答。由此可以看出Tracker server非常轻量化,不会成为系统瓶颈。
FastDFS中的Storage server在其他文件系统中通常称作Trunk server或Data server。Storage server直接利用OS的文件系统存储文件。FastDFS不会对文件进行分块存储,客户端上传的文件和Storage server上的文件一一对应。
众所周知,大多数网站都需要存储用户上传的文件,如图片、视频、电子文档等。出于降低带宽和存储成本的考虑,网站通常都会限制用户上传的文件大小,例如图片文件不能超过5MB、视频文件不能超过100MB等。我认为,对于互联网应用,文件分块存储没有多大的必要。它既没有带来多大的好处,又增加了系统的复杂性。FastDFS不对文件进行分块存储,与支持文件分块存储的DFS相比,更加简洁高效,并且完全能满足绝大多数互联网应用的实际需要。
在FastDFS中,客户端上传文件时,文件ID不是由客户端指定,而是由Storage server生成后返回给客户端的。文件ID中包含了组名、文件相对路径和文件名。
Storage server可以根据文件ID直接定位到文件。因此FastDFS集群中根本不需要存储文件索引信息,这是FastDFS比较轻量级的一个例证。
而其他文件系统则需要存储文件索引信息,这样的角色通常称作NameServer。其中mogileFS采用MySQL数据库来存储文件索引以及系统相关的信息,其局限性显而易见,mysql将成为整个系统的瓶颈。
FastDFS轻量级的另外一个体现是代码量较小。包括了C客户端API、FastDHT客户端API和PHPextension等,代码行数不到5.2万行。
- 分组方式
类Google FS都支持文件冗余备份,例如Google FS、TFS的备份数是3。一个文件存储到哪几个存储结点,通常采用动态分配的方式。采用这种方式,一个文件存储到的结点是不确定的。举例说明,文件备份数是3,集群中有A、B、C、D四个存储结点。文件1可能存储在A、B、C三个结点,文件2可能存储在B、C、D三个结点,文件3可能存储在A、B、D三个结点。
FastDFS采用了分组存储方式。集群由一个或多个组构成,集群存储总容量为集群中所有组的存储容量之和。一个组由一台或多台存储服务器组成,同组内的多台Storage server之间是互备关系,同组存储服务器上的文件是完全一致的。文件上传、下载、删除等操作可以在组内任意一台Storage server上进行。
类似木桶短板效应,一个组的存储容量为该组内存储服务器容量最小的那个,由此可见组内存储服务器的软硬件配置最好是一致的。
采用分组存储方式的好处是灵活、可控性较强。比如上传文件时,可以由客户端直接指定上传到的组。一个分组的存储服务器访问压力较大时,可以在该组增加存储服务器来扩充服务能力(纵向扩容)。
当系统容量不足时,可以增加组来扩充存储容量(横向扩容)。采用这样的分组存储方式,可以使用FastDFS对文件进行管理,使用主流的Web server如Apache、nginx等进行文件下载。
- 对等结构
FastDFS集群中的Tracker server也可以有多台,Tracker server和Storage server均不存在单点问题。Tracker server之间是对等关系,组内的Storage server之间也是对等关系。
传统的Master-Slave结构中的Master是单点,写操作仅针对Master。如果Master失效,需要将Slave提升为Master,实现逻辑会比较复杂。和Master-Slave结构相比,对等结构中所有结点的地位是相同的,每个结点都是Master,不存在单点问题。
2 系统结构
2.1跟踪器与存储结点
FastDFS服务端有两个角色:跟踪器(tracker)和存储节点(storage)。
跟踪器主要做调度工作,在访问上起负载均衡的作用。
存储节点存储文件,完成文件管理的所有功能:存储、同步和提供存取接口,FastDFS同时对文件的meta data进行管理。所谓文件的meta data就是文件的相关属性,以键值对(key value pair)方式表示,如:width=1024,其中的key为width,value为1024。文件meta data是文件属性列表,可以包含多个键值对。
FastDFS系统结构如下图所示:

为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。
一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。
当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。FastDFS中的文件标识分为两个部分:卷名和文件名,二者缺一不可。
- Tracker server之间相互独立,不存在直接联系
- 客户端和Storage server主动连接Tracker server。Storage server主动向Tracker server报告其状态信息
- 一个组包含的Storage server不是通过配置文件设定的,而是通过Tracker server获取到的
- 不同组的Storage server之间不会相互通信,同组内的Storage server之间会相互连接进行文件同步
- 一个组的存储容量为该组内存储服务器容量最小的那个
上传流程:
1. Client询问Tracker server应上传到哪个Storage server;
2. Tracker server返回一台可用的Storage server,返回的数据为该Storage server的IP地址和端口;
3. Client直接和该Storage server建立连接,进行文件上传,Storage server返回新生成的文件ID,文件上传结束。


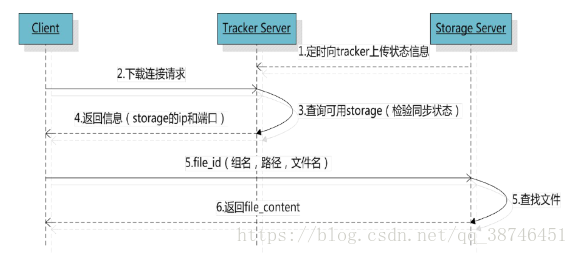
下载流程:
1. Client询问Tracker server可以下载指定文件的Storage server,参数为文件ID(包含Volume号和文件名);
2. Tracker server返回一台可用的Storage server;
3. Client直接和该Storage server建立连接,完成文件下载。


4.生成文件名
当文件存储到某个子目录后,即认为该文件存储成功,接下来会为该文件生成一个文件名,文件名由group、存储目录、两级子目录、fileid、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。

5.文件同步
写文件时,客户端将文件写至group组内一个storage server即认为写文件成功,storage server写完文件后,会由后台线程将文件同步至同group组内其他的storage server。
每个storage写文件后,同时会写一份binlog,binlog里不包含文件数据,只包含文件名等元信息,这份binlog用于后台同步,storage会记录向group内其他storage同步的进度,以便重启后能接上次的进度继续同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有server的时钟保持同步。
storage的同步进度会作为元数据的一部分汇报到tracker上,tracke在选择读storage的时候会以同步进度作为参考。
比如一个group内有A、B、C三个storage server,A向C同步到进度为T1 (T1以前写的文件都已经同步到B上了),B向C同步到时间戳为T2(T2 > T1),tracker接收到这些同步进度信息时,就会进行整理,将最小的那个做为C的同步时间戳,本例中T1即为C的同步时间戳为T1(即所有T1以前写的数据都已经同步到C上了);同理,根据上述规则,tracker会为A、B生成一个同步时间戳。
客户端将一个文件上传到一台Storage server后,文件上传工作就结束了。由该Storage server根据binlog中的上传记录将这个文件同步到同组的其他Storage server。这样的文件同步方式是异步方式.
同步延迟问题:
异步方式带来了文件同步延迟的问题。新上传文件后,在尚未被同步过去的Storage server上访问该文件,会出现找不到文件的现象。FastDFS是如何解决文件同步延迟这个问题的呢?
文件的访问分为两种情况:文件更新和文件下载。
文件更新:包括设置文件附加属性和删除文件。文件的附加属性包括文件大小、图片宽度、图片高度等。FastDFS中,文件更新操作都会优先选择源Storage server,也就是该文件被上传到的那台Storage server。这样的做法不仅避免了文件同步延迟的问题,而且有效地避免了在多台Storage server上更新同一文件可能引起的时序错乱的问题。
文件下载:那么文件下载是如何解决文件同步延迟这个问题的呢?
要回答这个问题,需要先了解文件名中包含了什么样的信息。
Storage server生成的文件名(fileid)中,包含了源Storage server的IP地址和文件创建时间等字段。文件创建时间为UNIX时间戳,后面称为文件时间戳。从文件名或文件ID中,可以反解出这两个字段。
然后我们再来看一下,Tracker server是如何准确地知道一个文件已被同步到一台Storage server上的。前面已经讲过,文件同步采用主动推送的方式。另外,每台storage server都会定时向tracker server报告它向同组的其他storage server同步到的文件时间戳。当tracker server收到一台storage server的文件同步报告后,它会依次找出该组内各个storage server被同步到的文件时间戳最小值,作为storage server的一个属性记录到内存中。
FastDFS对文件同步延迟问题的解决方案
下面我们来看一下FastDFS采取的解决方法。
1.一个最简单的解决办法,和文件更新一样,优先选择源Storage server下载文件即可。这可以在Tracker server的配置文件中设置,对应的参数名为download_server。
2.另外一种选择Storage server的方法是轮流选择(round-robin)。当Client询问Tracker server有哪些Storage server可以下载指定文件时,Tracker server返回满足如下四个条件之一的Storage server:
- 该文件上传到的源Storage server,文件直接上传到该服务器上的;
- 文件创建时间戳 < Storage server被同步到的文件时间戳,这意味着当前文件已经被同步过来了;
- 文件创建时间戳=Storage server被同步到的文件时间戳,且(当前时间—文件创建时间戳) > 一个文件同步完成需要的最大时间(如5分钟);
- (当前时间—文件创建时间戳) > 文件同步延迟阈值,比如我们把阈值设置为1天,表示文件同步在一天内肯定可以完成。
以上是关于fastdfs 有用的主要内容,如果未能解决你的问题,请参考以下文章