使用IDEA开发Spark程序
Posted bigjunoba
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用IDEA开发Spark程序相关的知识,希望对你有一定的参考价值。
一、分布式估算圆周率
1.计算原理
假设正方形的面积S等于x2,而正方形的内切圆的面积C等于Pi×(x/2)2,因此圆面积与正方形面积之比C/S就为Pi/4,于是就有Pi=4×C/S。
可以利用计算机随机产生大量位于正方形内部的点,通过点的数量去近似表示面积。假设位于正方形中点的数量为Ps,落在圆内的点的数量为Pc,则随机点的数量趋近于无穷时,4×Pc/Ps将逼近于Pi。
2.IDEA下直接运行
(1)启动IDEA,Create New Project-Scala-选择JDK和Scala SDK(Create-Browse-/home/jun/scala-2.12.6/lib下的所有jar包)-Finish
(2)右键src-New-Package-输入com.jun-OK
(3)File-Project Structure-Libraries-+Java-/home/jun/spark-2.3.1-bin-hadoop2.7-jars下的所有jar包-OK
(4)右键com.jun - Name(sparkPi)- Kind(Object)- OK,在编辑区写入下面的代码
package com.jun import scala.math.random import org.apache.spark._ object sparkPi { def main(args: Array[String]){ val conf = new SparkConf().setAppName("spark Pi") val spark = new SparkContext(conf) val slices = if (args.length > 0) args(0).toInt else 2 val n = 100000 * slices val count = spark.parallelize(1 to n, slices).map { i => val x = random * 2 - 1 val y = random * 2 - 1 if (x*x + y*y < 1) 1 else 0 }.reduce(_ + _) println("Pi is roughly " + 4.0 * count / n) spark.stop() } }
(5)Run-Edit Configuration-+-Application-写入下面的运行参数配置-OK
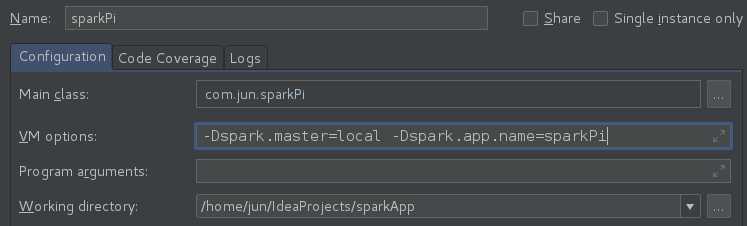
(6)右键单击代码编辑区-Run sparkPi
出现了一个错误,这个问题是因为版本不匹配导致的,通过查看Spark官网可以看到,spark-2.3.1仅支持scala-2.11.x所以要将scala换成2.11版本。
Exception in thread "main" java.lang.NoSuchMethodError: scala.Predef$.refArrayOps([Ljava/lang/Object;)Lscala/collection/mutable/ArrayOps; at org.apache.spark.internal.config.ConfigHelpers$.stringToSeq(ConfigBuilder.scala:48) at org.apache.spark.internal.config.TypedConfigBuilder$$anonfun$toSequence$1.apply(ConfigBuilder.scala:124) at org.apache.spark.internal.config.TypedConfigBuilder$$anonfun$toSequence$1.apply(ConfigBuilder.scala:124) at org.apache.spark.internal.config.TypedConfigBuilder.createWithDefault(ConfigBuilder.scala:142) at org.apache.spark.internal.config.package$.<init>(package.scala:152) at org.apache.spark.internal.config.package$.<clinit>(package.scala) at org.apache.spark.SparkConf$.<init>(SparkConf.scala:668) at org.apache.spark.SparkConf$.<clinit>(SparkConf.scala) at org.apache.spark.SparkConf.set(SparkConf.scala:94) at org.apache.spark.SparkConf$$anonfun$loadFromSystemProperties$3.apply(SparkConf.scala:76) at org.apache.spark.SparkConf$$anonfun$loadFromSystemProperties$3.apply(SparkConf.scala:75) at scala.collection.TraversableLike$WithFilter.$anonfun$foreach$1(TraversableLike.scala:789) at scala.collection.immutable.HashMap$HashMap1.foreach(HashMap.scala:231) at scala.collection.immutable.HashMap$HashTrieMap.foreach(HashMap.scala:462) at scala.collection.immutable.HashMap$HashTrieMap.foreach(HashMap.scala:462) at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:788) at org.apache.spark.SparkConf.loadFromSystemProperties(SparkConf.scala:75) at org.apache.spark.SparkConf.<init>(SparkConf.scala:70) at org.apache.spark.SparkConf.<init>(SparkConf.scala:57) at com.jun.sparkPi$.main(sparkPi.scala:8) at com.jun.sparkPi.main(sparkPi.scala) Process finished with exit code 1
Spark官网在spark2.3.1版本介绍中有这么一段说明,于是将scala版本换成2.11.8,然而又由于idea和scala插件版本不对应,最后决定采取联网安装scala插件的办法。
Spark runs on Java 8+, Python 2.7+/3.4+ and R 3.1+. For the Scala API, Spark 2.3.1 uses Scala 2.11. You will need to use a compatible Scala version (2.11.x).
将scala版本换成2.11.8,然后更改spark环境变量,然后再执行
3.分布式运行
二、基于Spark MLlib的贷款风险预测
以上是关于使用IDEA开发Spark程序的主要内容,如果未能解决你的问题,请参考以下文章
安装 IDEA 安装 Scala 插件以及导入 Spark 源码