KETTLE完全分布式集群搭建和示例
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KETTLE完全分布式集群搭建和示例相关的知识,希望对你有一定的参考价值。
一、Kettle的集群原理
完全分布式即是在该集群环境中所有的kettle服务都是部署在不同的机器上,互相之间没有影响。此处以一个真实环境为例,来介绍kettle完全分布式环境的开发使用。生产环境中kettle服务器都是部署在linux服务器上,在windows本地开发好kettle任务,然后在linux集群环境上运行。
二、完全分布式集群搭建
1.环境规划
该环境模拟一台主服务器,两台从服务器的方式。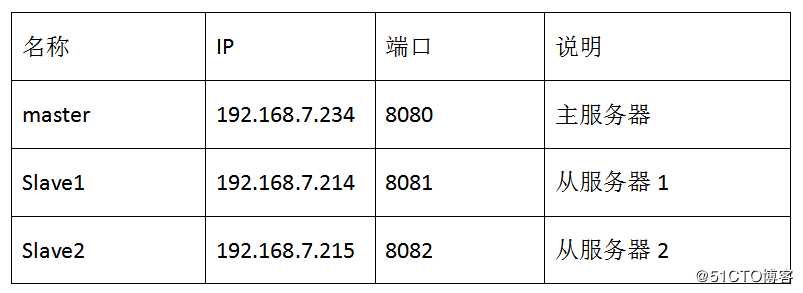
2.环境准备
首先需要先准备三台linux服务器,并且分别在三台机器上安装好jdk和kettle。
(1)JDK安装
此处不做详细介绍,可参考网上安装文档。
(2)Kettle安装
创建一个目,将下载好的kettle解压后放在该文件夹下。
测试安装是否成功
在kettle的data-integration目录中执行kitchen.sh文件,若出现帮助信息,证明安装成功
3.环境配置
和windows环境一样修改kettle配置文件,打开kettle的安装目录,进入到data-integration->pwd目录,找到carte-config-master-8080.xml文件。该文件主要是进行master主机配置,name、hostname、port依次配置名称、主机IP和端口号(如果已经使用可以修改)。
注意:username和password并不是指主机的登陆账号和密码,是集群的账号密码,该账号密码是集群连接的依据,账号密码是通过混淆的方式保存在pwd文件,kettle默认的账号密码是cluster/cluster,所以,在本机开发的时候,为了方便,账号密码都不用修改,都使用cluster即可。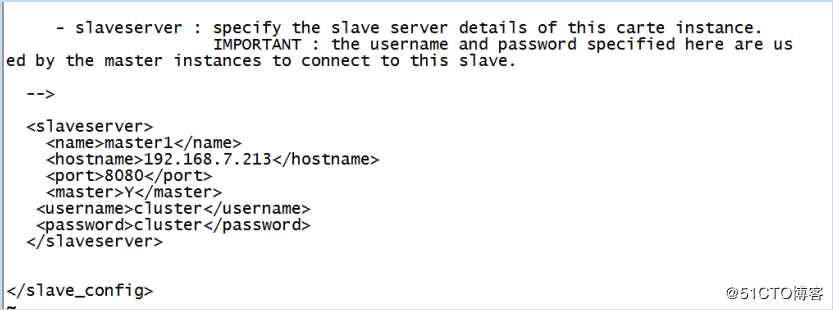
carte-config-8081.xml文件是从服务器1的配置文件。打开该文件,如下图。其中masters中,name、hostname、port需要和carte-config-master-8080.xml中完全一致。然后,同样修改carte-config-8082.xml文件。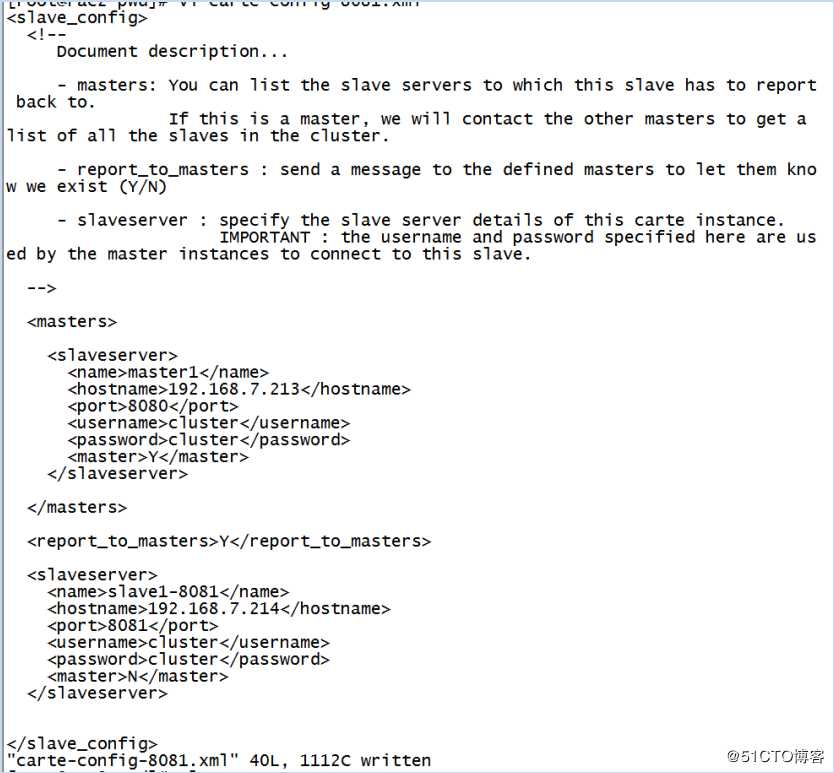
至此配置完毕,可以启动集群环境了。
4.启动集群
进入到data-integration目录下,运行./carte.sh 192.168.7.234 8080,启动master节点。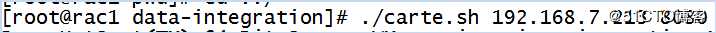
出现以下日志代表启动成功。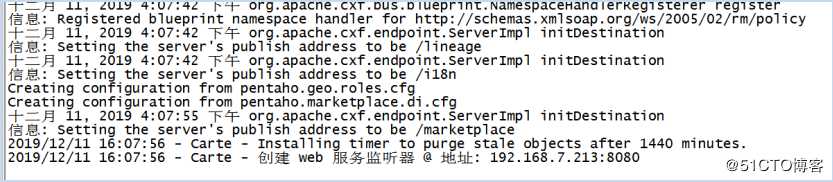
然后,切换到slave1上,进入到data-integration目录下,运行./carte.sh 192.168.7.214 8081,则启动8081端口的子服务器。切换到slave2上,重复动作,启动8082端口的子服务器。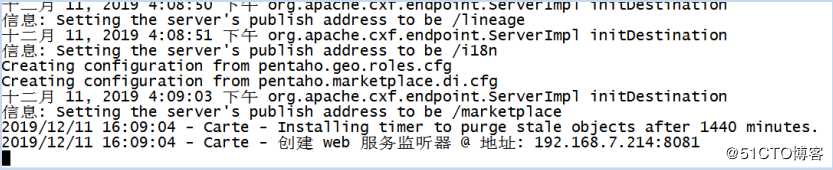

在启动了三台集群服务器之后,在浏览器中输入192.168.7.234:8080,输入cluster/cluster,进入到页面如下: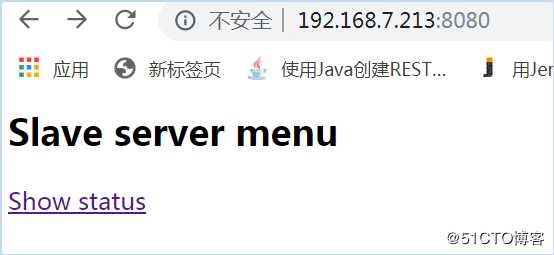
表示主节点已经启动完毕。输入192.168.7.214:8081及192.168.7.215:8082查看子服务器状态。到此,集群部署完毕。
三、完全分布式集群下示例
1.需求说明
读取源数据表中数据到目标数据表中,具体转换过程如下所示: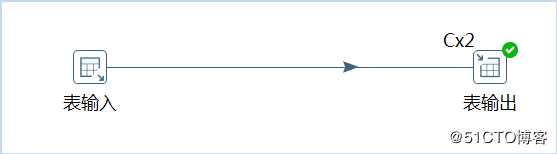
2.启动环境
首先按上面步骤启动集群环境,然后双击双击 Spoon.bat 启动 kettle图形界面工具。
3.环境配置
1)在主对象树中新建子服务器,配置分别如下图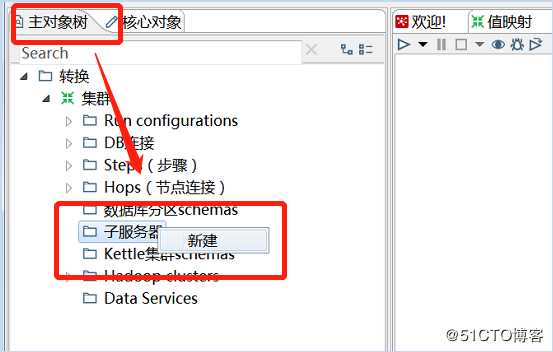
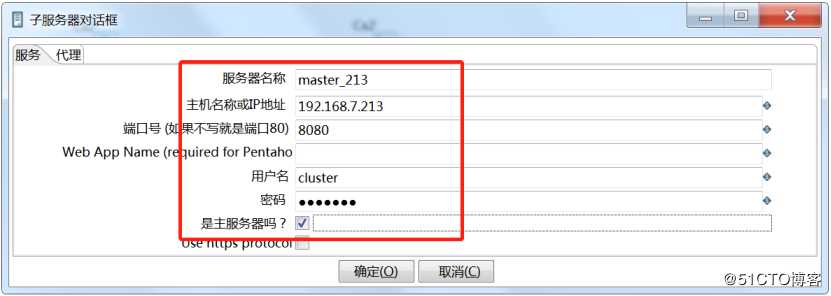
主服务器配置如上所示,记得勾选“是主服务器”。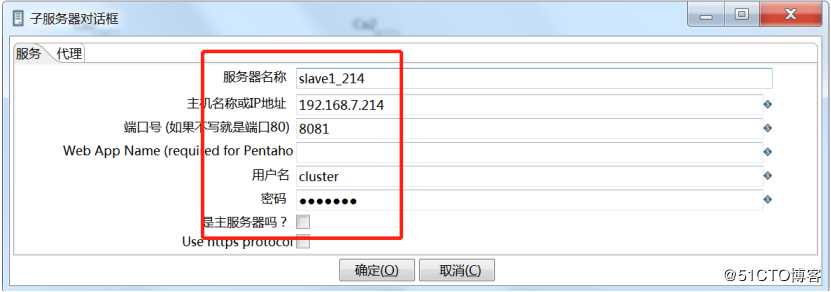
从服务器slave1配置如上所示,slave2也按照上面配置,记得修改端口和名称。
2)在主对象树中,在“kettle集群schmas”中右键,新建,点击“选择子服务器”,添加刚才新建的子服务器,然后确定。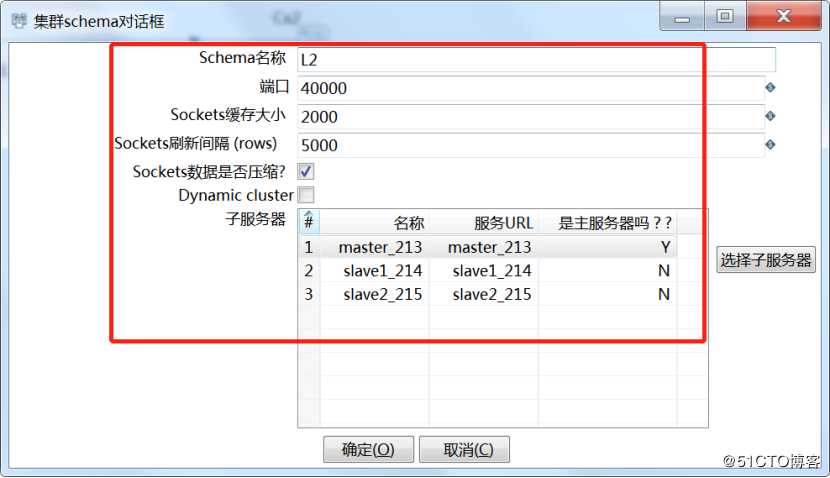
4.设置运行参数
1)在步骤上右击,选择集群,然后会发现排序纪录多出”CX2”,表示有2个子服务器来执行。在一个三个子服务器的集群中,主服务器负责任务分发、结果收集,转换任务由从服务器执行,故只有两个节点执行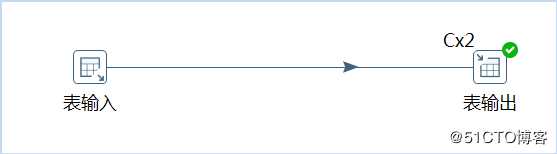
2)在主对象树中,在集群-“Run Configurations”中右键,新建,新增一个参数配置。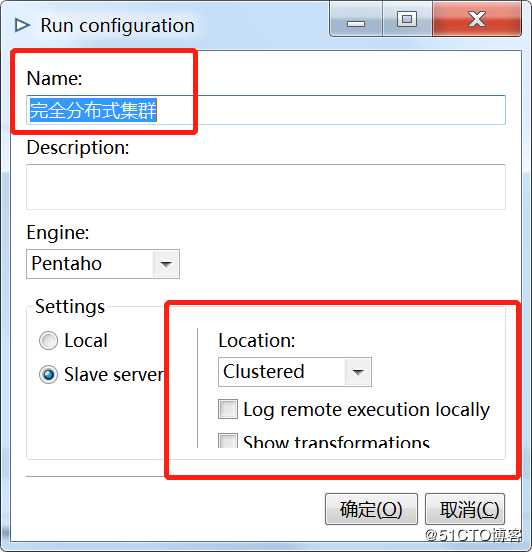
按如上所示进行配置,选择“Settings”-“Slave server”,选择“Clustered”表示采用集群方式运行,还可以选择“master”、“slave1”、“slave2”,则表示在相应的远程服务器上运行。
5.运行用例
点击“运行”,运行配置选择刚刚创建的参数-“伪分布式集群”,点击“启动”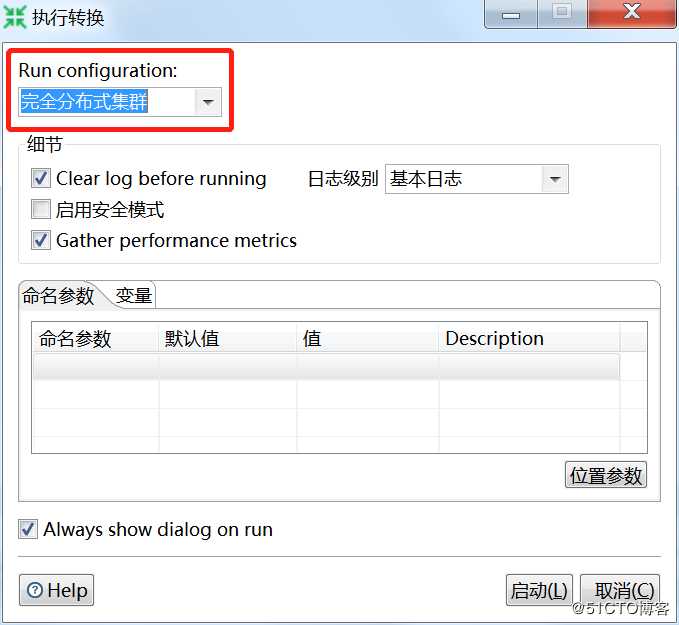
观察slave1和slave2后台日志,发现两个从服务器都在执行转换,主服务器没有日志,因为它只负责分发。
(1)主服务器234上面日志信息,汇总记录总的日志信息,总共读入5条数据,输出5条数据。如下所示:
(2)子服务器214日志信息,该服务器总共读入3条数据,输出3条数据,如下所示:
(3)子服务器215日志信息,该服务器总共读入2条数据,输出2条数据,如下所示:
6.关闭iptables服务和防火墙
如果遇到集群服务器连不上的问题,需要检查一下是否是防火墙需要关闭,centos7使用iptables,可以通过命令/etc/init.d/iptables stop 停止
注意:想要学习通过kettle工具实现hive、hbase数据库抽取输出,和其他更多关于kettle的知识,请扫描以下二维码或者链接获取学习资料。
链接地址:
https://edu.51cto.com/sd/e80d0
二维码地址:
同时也欢迎各位看官关注本人公众号,本人将相关资料和学习视频上传到上面,供大家一起学习讨论:
以上是关于KETTLE完全分布式集群搭建和示例的主要内容,如果未能解决你的问题,请参考以下文章