hadoop完全分布式集群搭建(超详细)-大数据集群搭建
Posted beixi@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop完全分布式集群搭建(超详细)-大数据集群搭建相关的知识,希望对你有一定的参考价值。
hadoop完全分布式集群搭建
本次搭建完全分布式集群用到的环境有:
jdk1.8.0
hadoop-2.7.7
本次搭建集群所需环境也给大家准备了,下载链接地址:https://share.weiyun.com/dk7WgaVk
密码:553ubk
本次完全分布式集群搭建需要提前建立好三台虚拟机,我分别把它们的主机名命名为:master,slave1,slave2
一.配置免密登陆
首先我们要实现三台虚拟机之间相互的ssh免密登陆
在master虚拟机上进行操作:
1. 创建ssh秘钥,输入如下命令,生成公私密钥,下方三个红框内都按回车键
ssh-keygen -t rsa
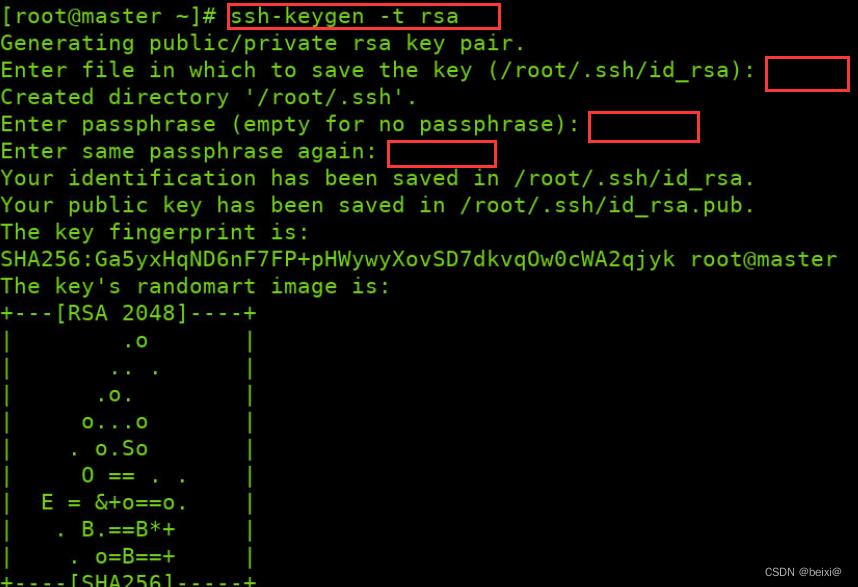
2.将公钥拷贝到本机实现免密登录,第一个红框位置输入yes,第二个红输位置输入自己虚拟机的登陆密码
ssh-copy-id master
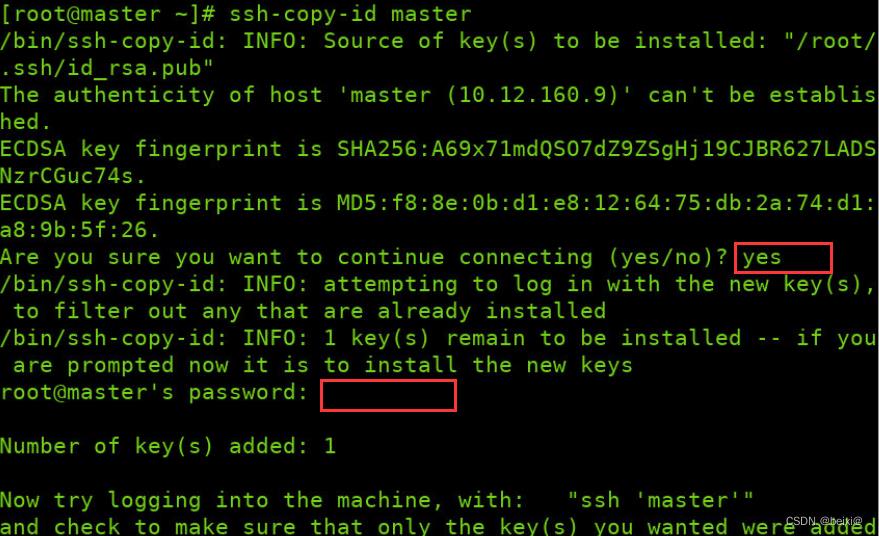
跟上面的操作一样,我们在master中实现master对slave1,slave2的免密登录
ssh-copy-id slave1
ssh-copy-id slave2
同理,我们分别进入到slave1,slave2虚拟机中,进行以上同样的操作
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
三台虚拟机一共要执行3*3=9次的免密登录操作
然后我们对master虚拟机上的/etc/hosts文件进行更改,设置IP映射
vi /etc/hosts
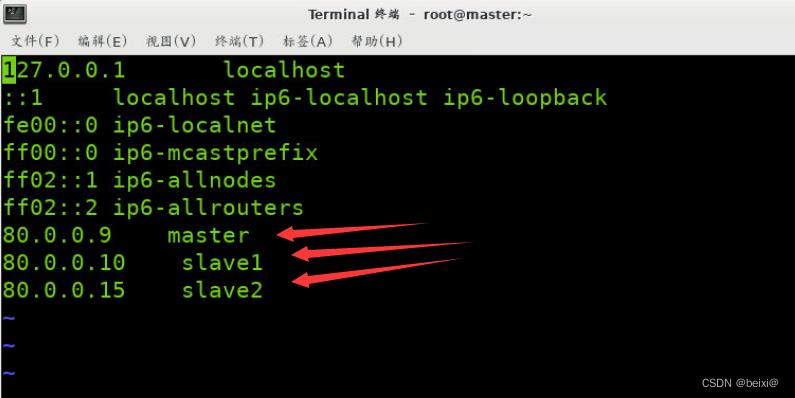
我们将三台虚拟机的ip地址,主机名如图所示进行添加,并键入:wq 保存并退出】
同理,我们切换到slave1,slave2虚拟机中对/etc/hosts文件进行同样的修改,保存并退出
二.配置java环境
1.我们在master主机上进行java环境的配置
首先,先把虚拟机环境中的jdk压缩文件解压到/opt目录下
tar -zxvf ~/ruanjian/jdk1.8.0_221.tar.gz -C /opt
进入/opt目录,将解压文件改名为java
cd /opt
mv jdk1.8.0_221 java
接下来修改环境变量
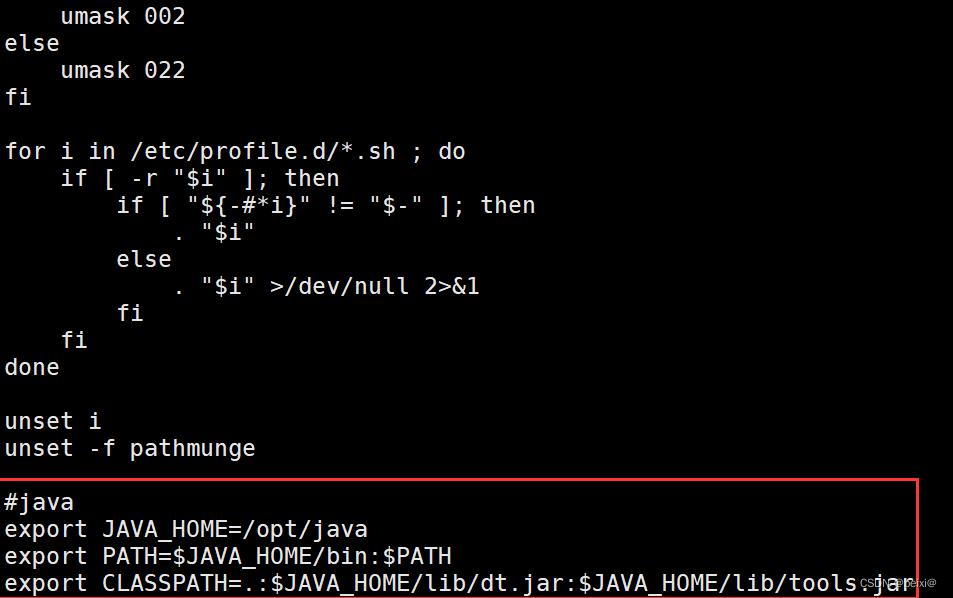
vi /etc/profile
进入文件按下GG进入配置文件最后一行,添加如下信息:
export JAVA_HOME=/opt/java #你java路径是啥这里就填啥
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
:wq保存配置信息
然后我们生效配置信息
source /etc/profile
最后验证一下java环境是否配置成功
java -version
如图所示,正确地显示了java的版本号,就配置成功啦~

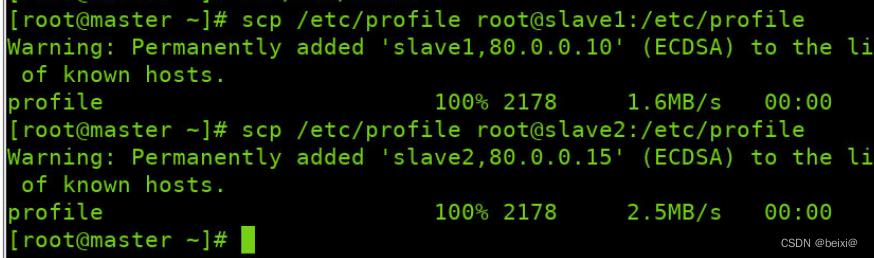
然后我们通过命令将java环境分发给slave1,slave2虚拟机中
scp /etc/profile root@slave1:/etc/profile
scp /etc/profile root@slave2:/etc/profile
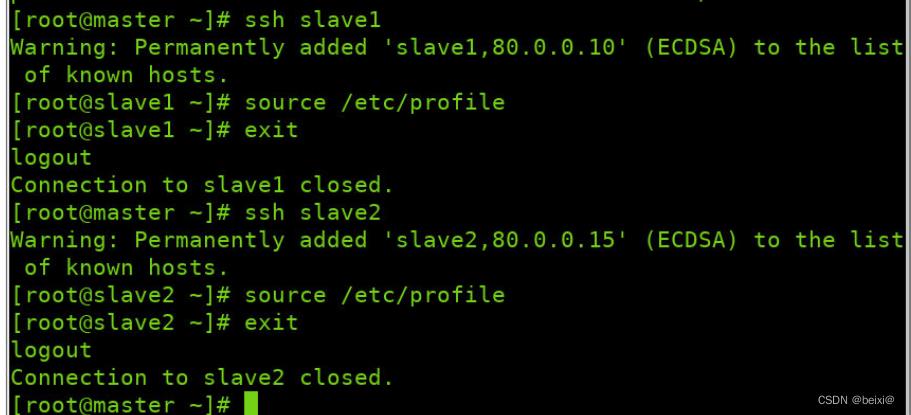
分别在slave1,slave2虚拟机中进行生效配置
ssh slave1
source /etc/profile
exit
ssh slave2
source /etc/profile
exit
三.hadoop的安装
1. 将/root/runajian下的hadoop-2.7.7.tar.gz压缩包解压到/opt目录下,并将解压文件改名为hadoop
tar -zvxf /root/ruanjian/hadoop-2.7.7.tar.gz -C /opt
mv hadoop-2.7.7 hadoop

2.修改环境变量
vim /etc/profile
3.按键Shift+g键定位到最后一行,按键 i 切换到输入模式下,添加如下代码:
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
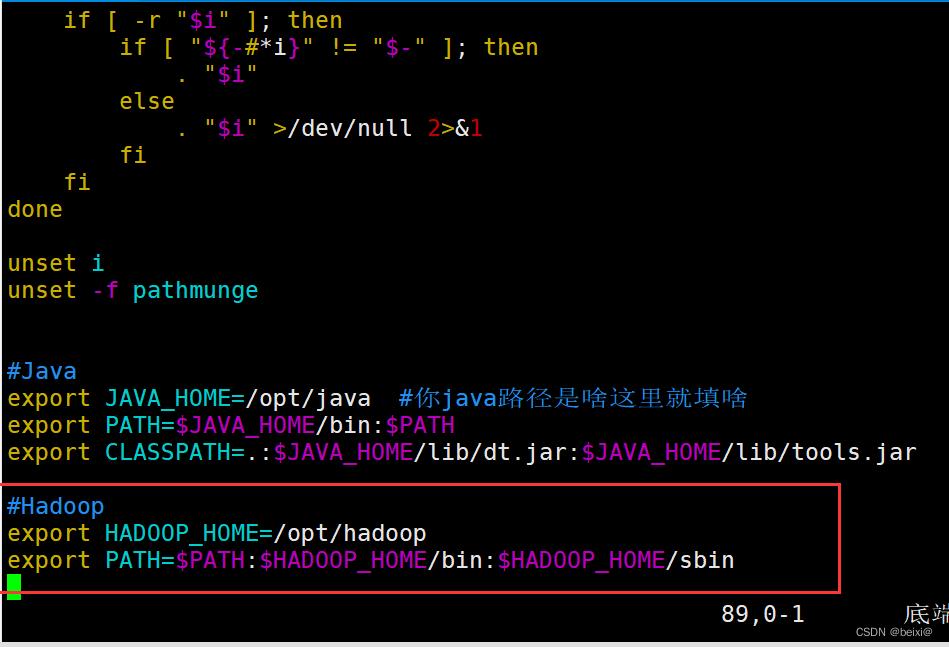
4.按键ESC,按键:wq 保存并退出
5.生效刚刚的配置
source /etc/profile
6.同理将master的配置文件分发到slave1,slave2中
ssh slave1
source /etc/profile
exit
ssh slave2
source /etc/profile
exit
四.hadoop的配置
在/opt/hadoop/etc/hadoop里面,有六个需要配置的文件,分别为:
hadoop-env.sh
core-site.xml
yarn-site.xml
hdfs-site.xml
mapred-site.xml
slaves
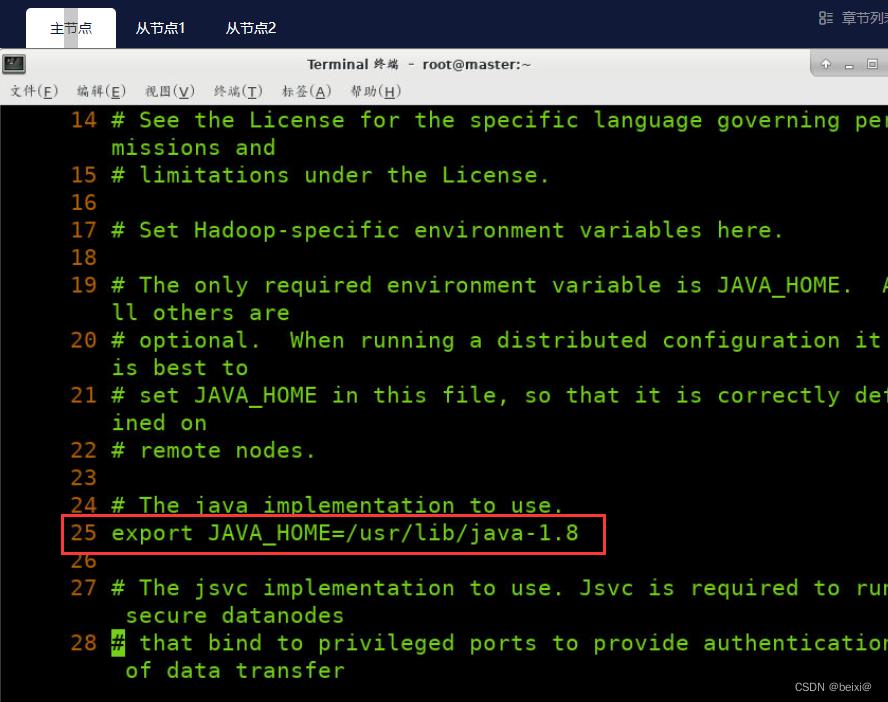
1.首先在master虚拟机中,对hadoop-env.sh文件进行操作
vi /opt/hadoop/etc/hadoop/hadoop-env.sh
在配置文件中,输入25gg定位到25行,修改java环境为自己配置的java环境路径,键入:wq保存并退出
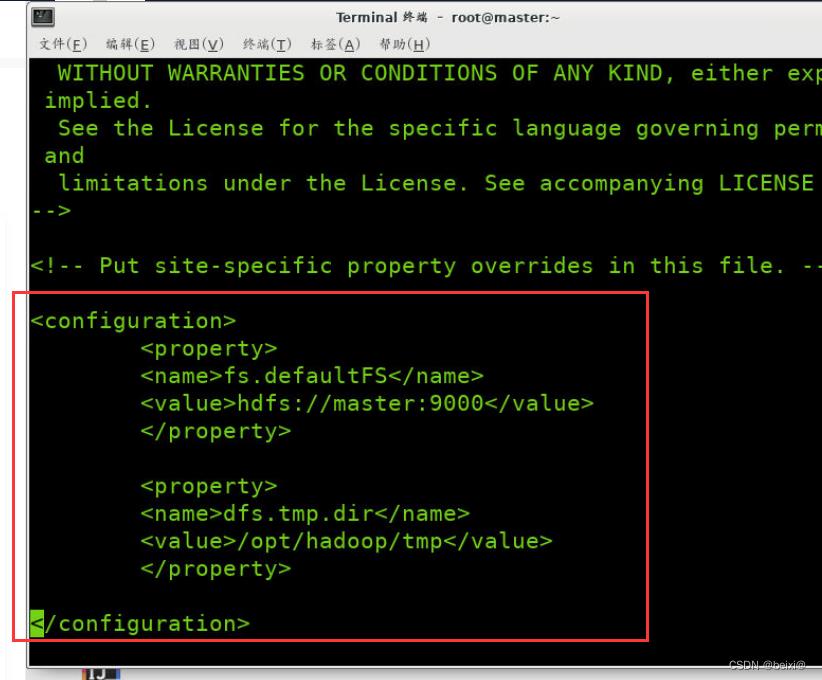
2.修改core-site.xml文件
vi /opt/hadoop/etc/hadoop/core-site.xml
进入配置文件,键入G定位到最后一行,在configuration标签内输入i命令添加以下代码:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
</configuration>
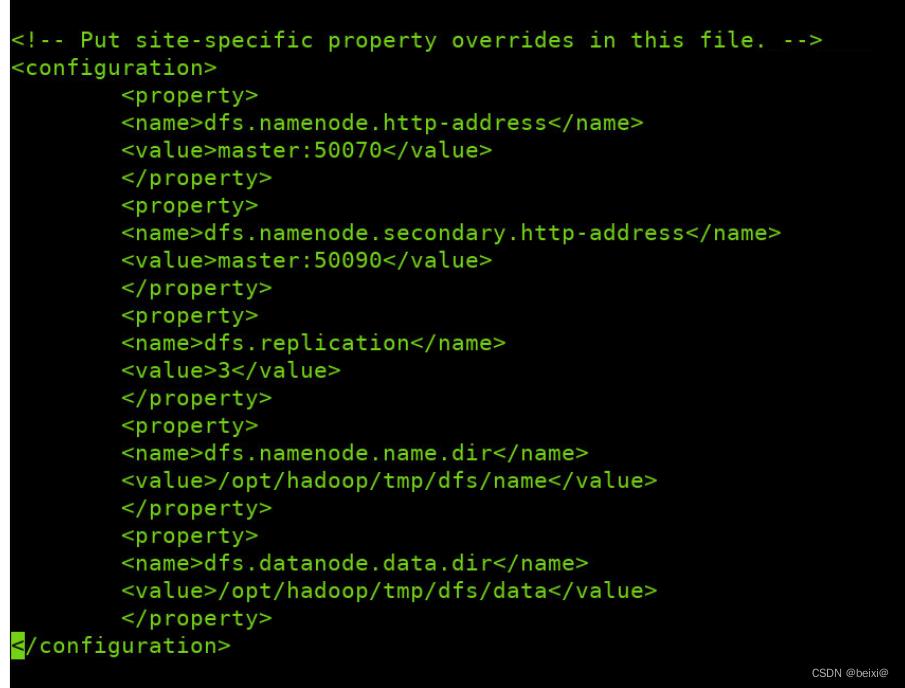
3.修改hdfs-site.xml文件
vi /opt/hadoop/etc/hadoop/hdfs-site.xml
进入配置文件,键入G定位到最后一行,在configuration标签内输入i命令添加以下代码:
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/tmp/dfs/data</value>
</property>
</configuration>
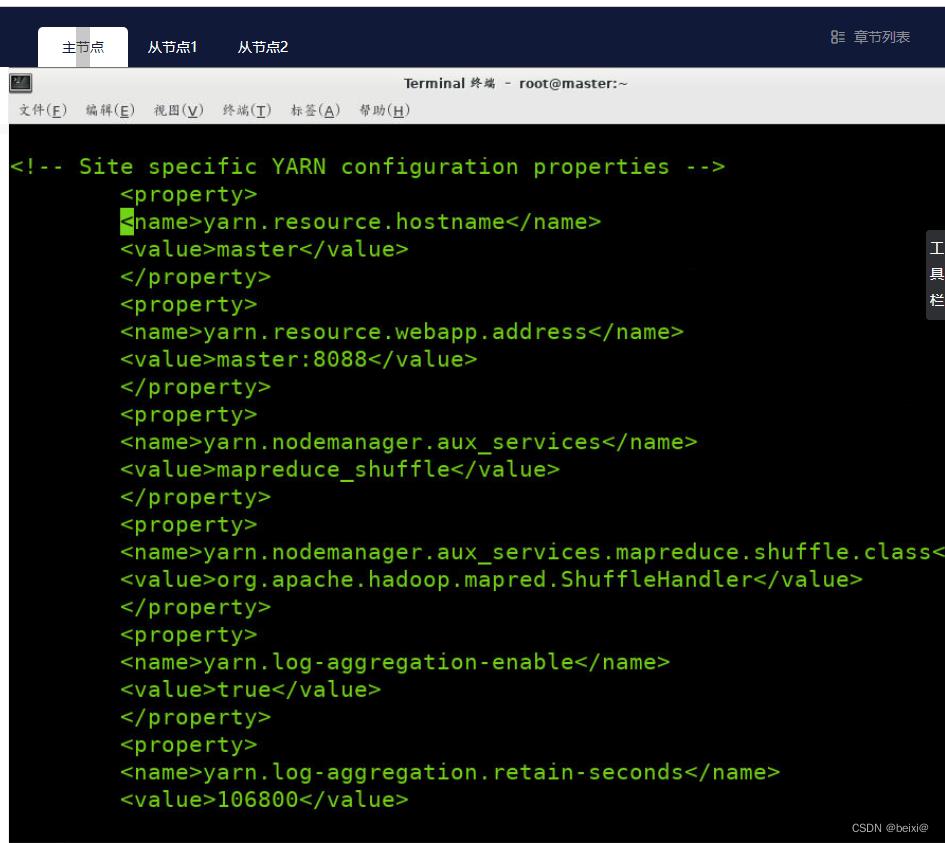
4.修改yarn-site.xml文件
vi /opt/hadoop/etc/hadoop/yarn-site.xml
进入配置文件,键入G定位到最后一行,在configuration标签内输入i命令添加以下代码:
<configuration>
<property>
<name>yarn.resourcemanager.hostsname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/user/container/logs</value>
</property>
</configuration>
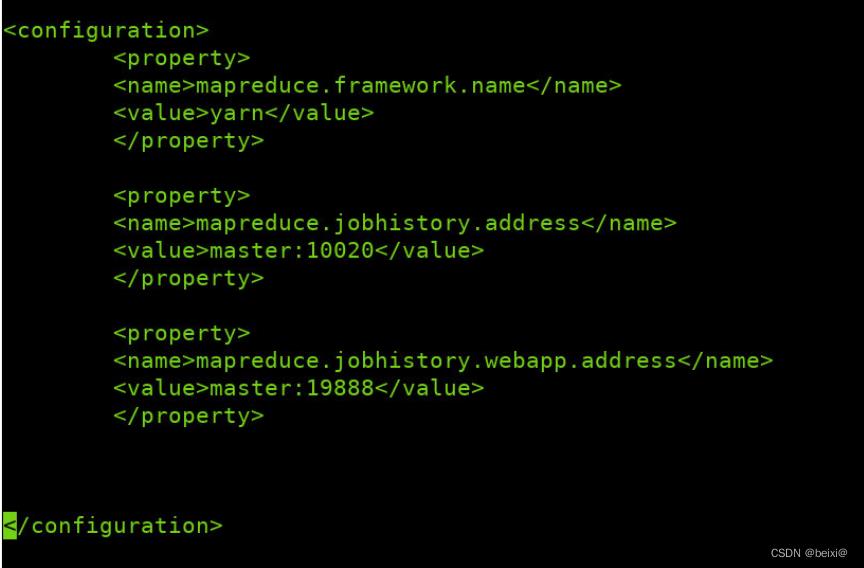
5.在配置文件夹中,将模板文件mapred-site.xml.template复制一份为mapred-site.xml
cp /opt/haoop/etc/hadoop/mapred-site.xml.template /opt/haoop/etc/hadoop/mapred-site.xml
修改mapred-site.xml文件
vi /opt/hadoop/etc/hadoop/mapred-site.xml
进入配置文件,键入G定位到最后一行,在configuration标签内输入i命令添加以下代码:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
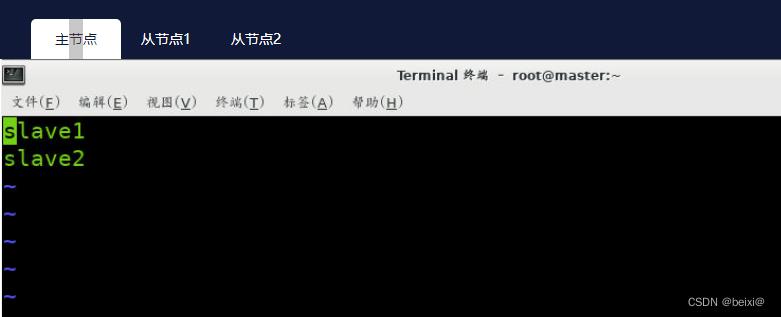
6.修改slaves文件
vi /opt/hadoop/etc/hadoop/slaves
进入配置文件后按dd删除第一行内容,再键入i进入输入模式,输入slave1,sleve2
7.将配置好的hadoop文件分发至slave1,slave2虚拟机中的/opt文件夹下
scp /opt/hadoop root@slave1:/opt/
scp /opt/hadoop root@slave2:/opt/
8.格式化namenode,在master虚拟机中进行
hdfs namenode -format
9.格式化后开启集群
start-all.sh
我们分别在master,slave1,slave2虚拟机中,通过jps命令查询集群是否开启成功
jps
master界面:
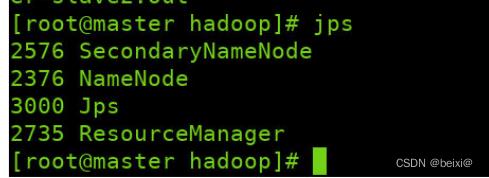
slave1界面:
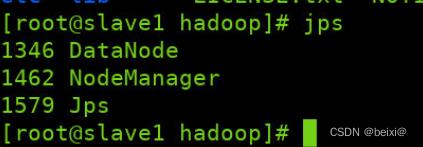
slave2界面:
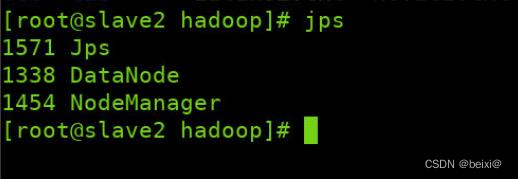
集群开启成功后,节点会如图显示:
Master: NameNode、ResourceManager、SecondaryNameNode
slave1: DataNode、NodeManager
slave2: DataNode、NodeManager
hadoop完全分布式集群搭建到此就完毕了,如果此篇文章对你有帮助或者喜欢,记得点赞关注收藏哦~
大数据技术栈-Hadoop3.3.4-完全分布式集群搭建部署-centos7(完全超详细-小白注释版)虚拟机安装+平台部署
目录
1、安装虚拟机(已安装好虚拟机的可跳转至 一、安装jdk与hadoop)
一、集群前置环境搭建(三台机器分别设置hostname、网卡(ip)配置、ssh免密登录)
(1)首先,查看本机的网卡配置,使用cmd查看ipconfg,找到VMware的虚拟网卡,查看ip
环境条件:
| 设备类型 | 软件类别 | 名称、版本号 |
| PC机(建议内存8GB以上) | 操作系统 | Window10 |
| 软件 | VMware Workstation 17 Player | |
| 虚拟机 | Linux 操作系统 | CentOS 7 |
| 镜像文件与安装包 | CentOS-7-x86_64-DVD-2009.iso | |
| Hadoop3.3.4.tar.gz | ||
| jdk-8u191-linux-x64.tar.gz | ||
| 其他(看个人喜好选用) | 工具 | Xshell 7 |
| Xftp 7 |
1、安装虚拟机(已安装好虚拟机的可跳转至 一、安装jdk与hadoop)
默认VMware已经安装好,打开VMware安装第一台虚拟机
(1)直接新建一台虚拟机
选中 已经下载好的镜像文件 CentOS7-x86_64-DVD-2009.iso
修改机器名称、本机用户与密码,root用户也使用此密码
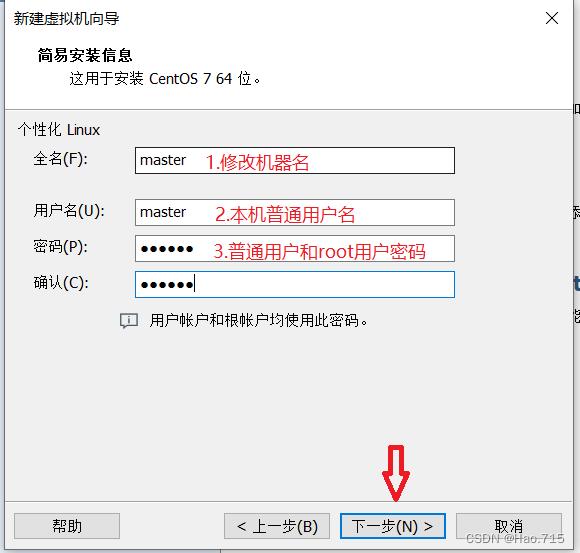
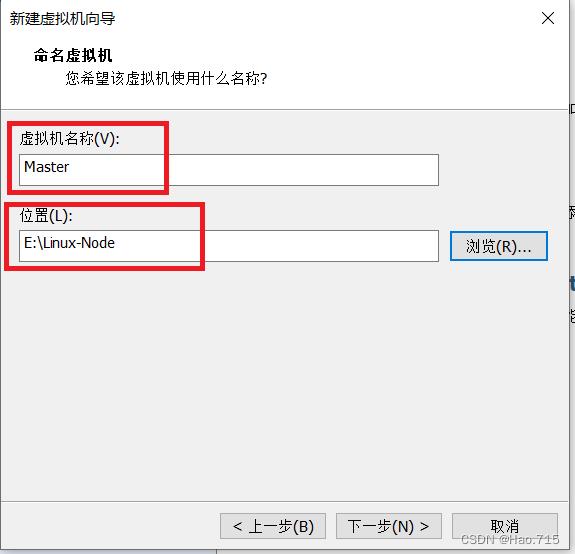
命名虚拟机名称,并设置本虚拟机的位置(建议选择储存空间大的位置,新建文件夹存放)
设置大小,默认为20GB,不用修改
选择 将虚拟磁盘存储为单个文件 然后下一步

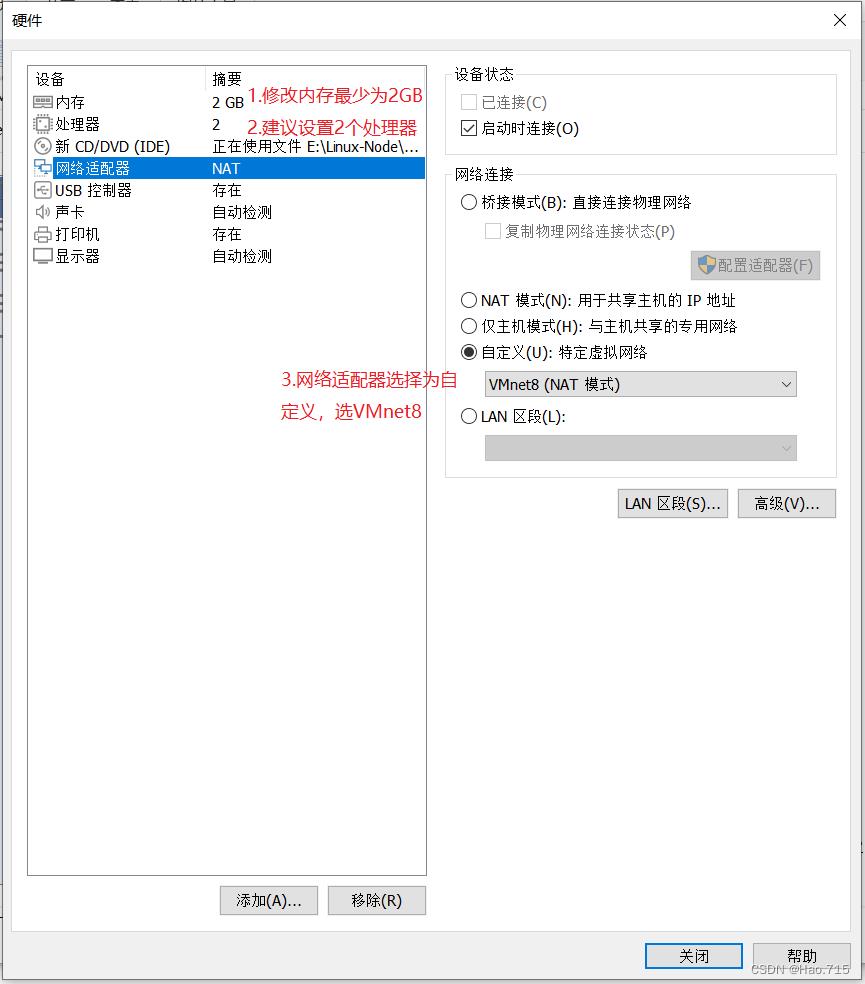
检查虚拟机硬件配置,进行 自定义硬件 进行修改
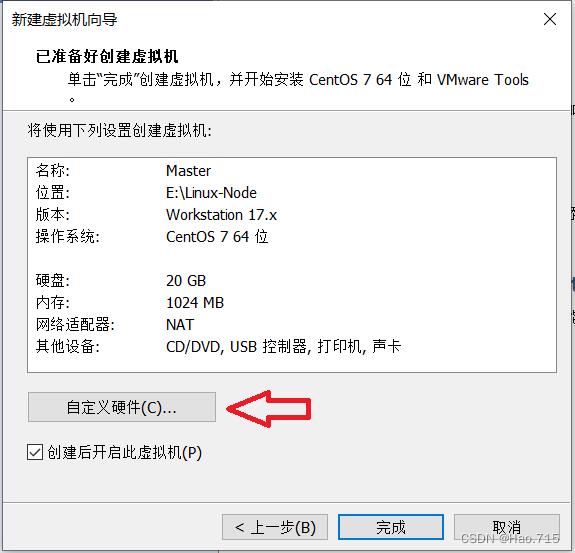
将内存设置为 2GB(最少2GB)
将处理器数量设置为 2个
将网络适配器选择为自定义 选用 VMnet8
至此,虚拟机基本设置完成,点击完成即可。
(2)首次启用虚拟机,进行安装
直接启动

首次启用需等待系统自动下载
然后就进入系统了
注:本次安装过程使用了简易安装,不使用是需要自行选择需要的基本插件和功能
可以直接点击用户名进行普通登录,也可以选择 Not listed? 使用root用户登录
至此,虚拟机的安装就算结束了···
后续所以操作需使用虚拟机的终端进行命令操作
一、集群前置环境搭建(三台机器分别设置hostname、网卡(ip)配置、ssh免密登录)
1、查看一下本机与虚拟机的网卡和ip信息
(1)首先,查看本机的网卡配置,使用cmd查看ipconfg,找到VMware的虚拟网卡,查看ip
win + R 打开 cmd
cmd中使用 ipconfig 进行查看

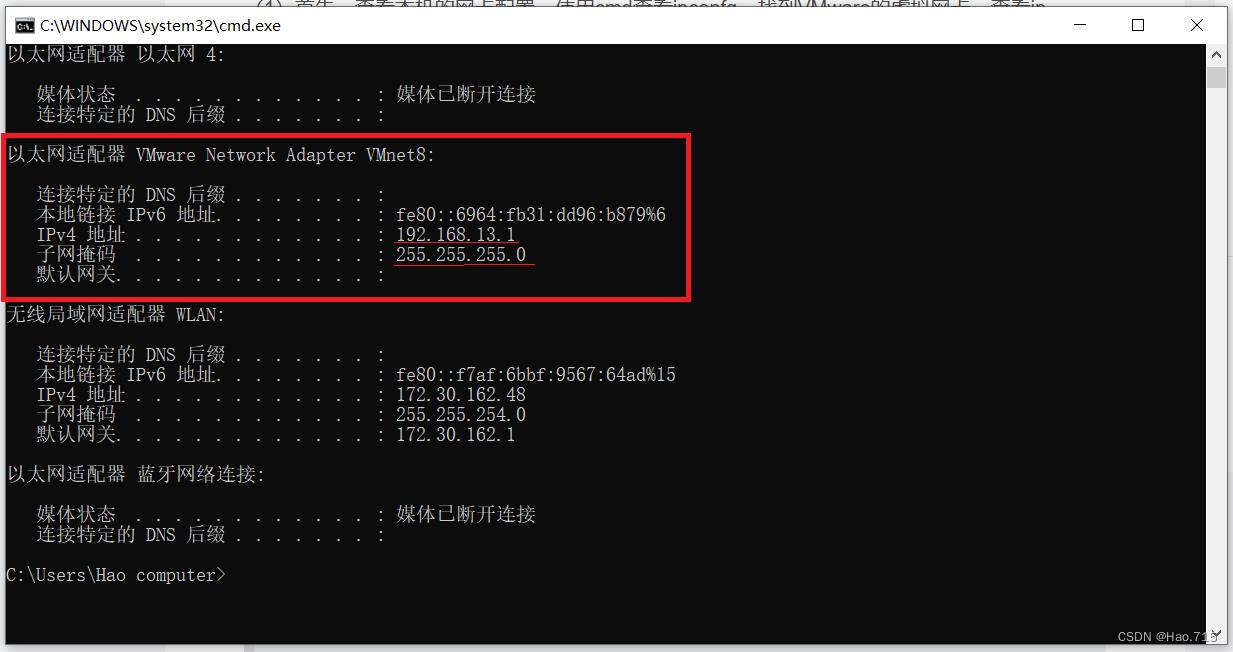
找到 VMnet8 这个虚拟网卡,所有集群的IP需配置在此网段内。例如:192.168.13.20
记住192.168.13.1和255.255.255.0
(2)查看虚拟机的网卡配置和网络信息
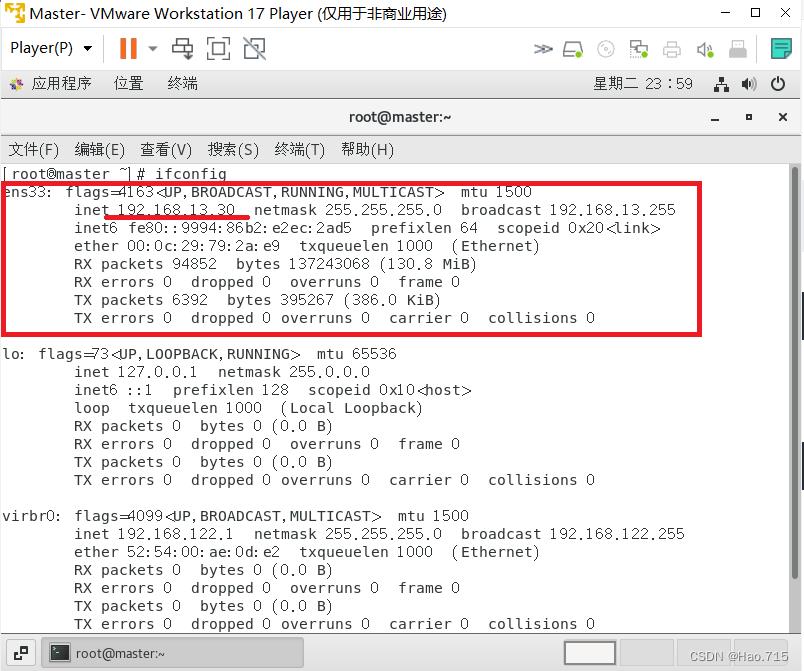
使用 ifconfig 或 ip a 进行查看 两者选一个即可(能看到虚拟机现在的ip和网卡名称即可)
ifconfig
通常出现的第一个此虚拟机使用的虚拟网卡,名称为ens33 对这个网卡的配置文件进行修改
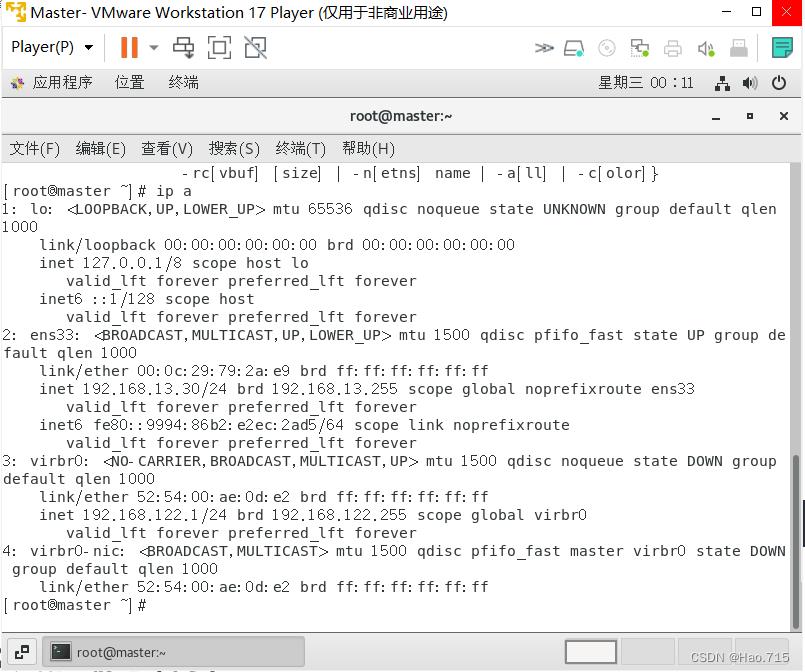
ip a此命令的内容与 ifconfig 大致相同
(3)修改Hostname
方法一:使用 vim/etc/hostname 编辑即可
vim/etc/hostname修改后使用 reboot 重启虚拟机生效
使用命令 hostname 查看
hostname
方法二:使用 hostnamectl 命令
hostnamectl set-hostname 新名称修改后使用reboot重启虚拟机
使用hostname查看
hostname
2、配置静态ip网卡
网卡路径 /etc/sysconfig/network-scripts/ifcfg-ens33
使用vim对网卡配置文件进行编辑
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO="static"
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=f605a46e-401e-46bf-98f7-1d9270d29270
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.13.30
NETMASK=255.255.255.0
DNS1=8.8.8.8
DNS2=114.114.114.114
DNS3=192.168.13.1
PREFIX=24
GATEWAY=192.168.13.2
使用ping命令测试网络是否联通
ping -c 4 baidu.com
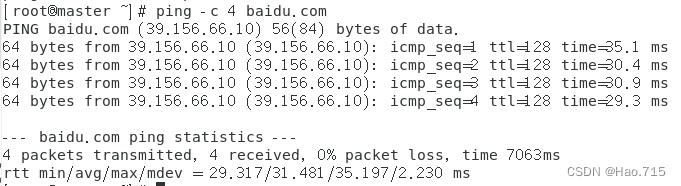
测试成功,按照以上步骤创建 slave1 和 slave2 两台虚拟机
3、配置ssh免密登录
三台机器配置好网络后
(1)修改hosts文件
vim /etc/hosts
#IP + hostname
192.168.13.30 master
192.168.13.31 slave1
192.168.13.32 slave2
三台机器同步进行修改(建议使用xshell进行操作)
后续操作均使用Xshell工具进行,与虚拟机终端进行操作相同
(2)配置ssh
创建.ssh文件夹(三台机器都需要执行)
mkdir .sshll 查看是否创建成功
ll -a
生成密钥(三台机器都需要执行)
ssh-keygen -t rsa回车执行
即为成功

ssh-copy-id 复制到其他主机
ssh-copy-id master ssh-copy-id slave1 ssh-copy-id slave2每台机器都运行一遍
使用ssh进行测试# master 免密登录至slave1节点 ssh slave1
4、hadoop集群规划
| 机器 | ip | 节点分配 |
| master | 192.168.13.30 | NameNode、DataNode、NodeManager |
| slave1 | 192.168.13.31 | ResourceManager、DataNode、NodeManager |
| slave2 | 192.168.13.32 | SecondaryNameNode、DataNode、NodeManager |
二、安装jdk与hadoop
1、检查jdk是否安装
使用 java-version 查看Jdk的版本
java -version
这里我用的是jdk1.8.0_191
使用新版jdk,在 /etc/profile 修改jdk环境变量至新版的路径即可
安装包:虚拟机联网后可直接通过浏览器进行下载 若在PC机 则需通过工具上传至虚拟机中 (使用xshell或xftp)
2、安装jdk,配置环境
在/opt目录下创建两个文件夹
mkdir -p software //存放安装包
mkdir -p module //存放解压后的文件
准备好安装包后,使用tar命令解压
mkdir -p /opt/software
mkdir -p /opt/module
ls /opttar -zvxf /目标文件路径 -C /安装路径
tar -zvxf /opt/software/jdk-8u191-linux-x64.tar.gz -C /opt/module解压好后通过mv命令改名
mv /opt/module/解压后文件 /opt/module/改名配置环境 /etc/profile
vim /etc/profile将以下内容写入profile中 (路径需与安装的一致)
#jdk
export JAVA_HOME=/opt/module/jdk1.8.0_191
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$HAVA_HOME/lib/tools.jar修改后使用source命令
source /etc/profile使用命令查看jdk版本,与安装包相符说明配置成功
java -version3、准备Hadoop3.3.4安装包
4、配置Hadoop3.3.4环境变量
以上是关于hadoop完全分布式集群搭建(超详细)-大数据集群搭建的主要内容,如果未能解决你的问题,请参考以下文章