对WX公众号文章的爬取分析
Posted eeyhan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对WX公众号文章的爬取分析相关的知识,希望对你有一定的参考价值。
声明:请勿用于商业用途,以下只是个人兴趣分析以及技术分享,请各位自行斟酌处理,否则后果自负
这篇文章很简短,主要的理论分析操作
0.工具准备:
- 微信号
- 关注好目标公众号
- charles
1).准备一个微信号,建议不要用刚注册的微信号来操作,容易被封号,微信内部是有一套反爬系统的,你运气不好就会触发到
2).关注好你需要爬取的公众号,因为要关注了,你才可以打开这个公众号的历史消息,不然的话,你只能看到最近的几篇文章,说白了就是看不全,搜狗搜索针对微信公众号的搜索我没猜错就是这样,所以只能看前几条信息,并且我发现搜狗搜索已经不好使了
3).charles就是抓包工具,这个网上很多资源,配置步骤也有很多,这个就自行查看配置了,记得要装上ssl证书,配置好ssl的代理。
那么有朋友要问,可以用fiddler替代charles吗?
其他地方不出意外是可以的,但是这里,针对微信的还真的要用到charles,因为fiddler我试了,抓不到包,当然也可能是我用的fiddler版本问题,这个就自行选择吧,我个人建议还是用charles
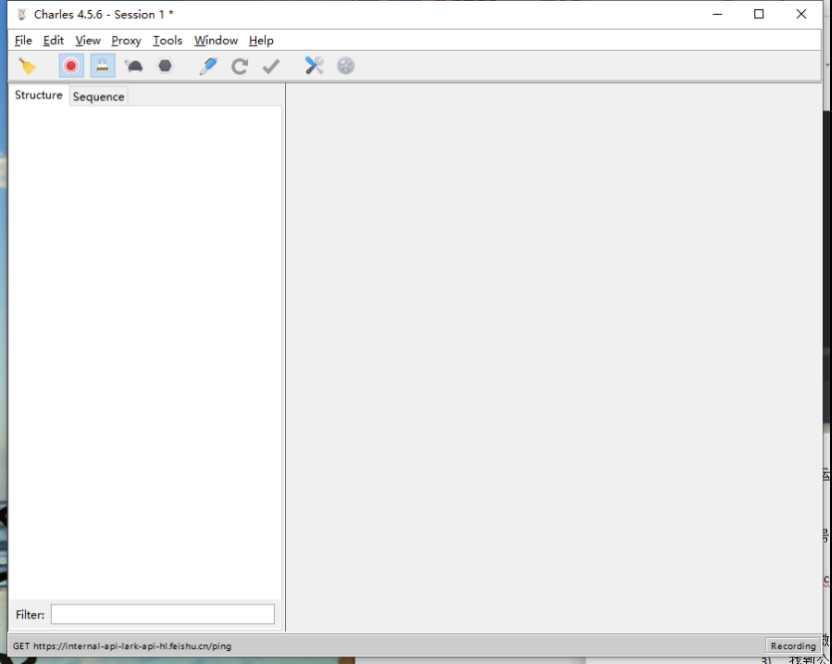
1.打开charles
要先打开抓包工具,这样抓包工具才能嗅探到数据接口
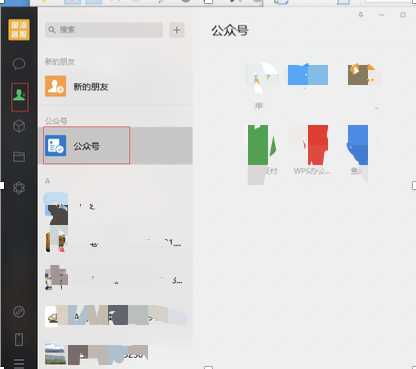
2.打开pc端微信,找到公众号
登录pc端微信,然后打开公众号那一栏
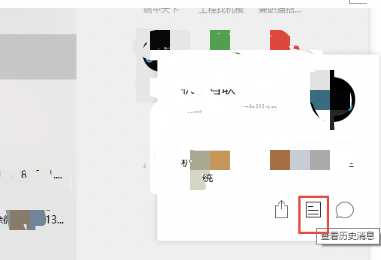
3. 找到目标公众号文章列表,获取链接
找到目标公众号,然后点击一下,再点【查看历史消息】
然后会从pc端的微信里打开一个页面,如下:
4.用charles获取链接
回到charles工具,此时已经嗅探到了数据接口,找到mp.weixin.qq.com的组合,从该组里找到profile_ext开头的第一个链接
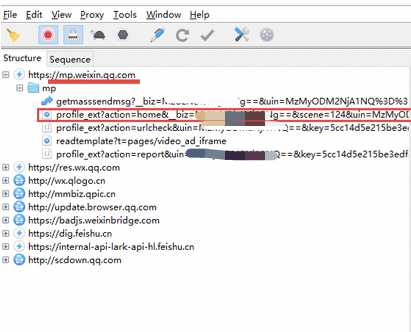
5.复制并拼接链接
把上面获取到的链接,拿下来分析
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=保密==&scene=124&uin=保密%3D%3D&key=5cc14d5e215be3edfddab345c1e7d1545790a5d5106ac566ca33c21751c8578150126ebd750daa11336a1b536880ad8a814eb7be46e0e87e59f6c53828a3598637f04c6e8f8ebceb27fe27ed90797757&devicetype=Windows+10+x64&version=62090070&lang=zh_CN&a8scene=7&pass_ticket=lhCQ79EkT0QdVeeyIOeLJKN5WNTdCHysp252vVp7H4qdBHq5iSNThsQgO7qvPqul&winzoom=1
这里面的参数看起来很复杂,其实主要的就是那几个
根据我的分析发现,那个biz参数的值唯一,不同公众号有不同的值,且这个值是用base64转码过,反解回去是公众号id
uin就是微信个人号的id然后base64转码过,这个值也是唯一的,一个号一个值
key的值就是微信客户端本地自己生成的,这个就很难破解了,且这个key有30分钟时效性,如果超时的话,用charles重新获取下链接即可,并且根据我的分析得出,其实我觉得这30分钟是稳稳的够了的
然后,上面打开的历史信息,其实是可以转成json格式,然后更利于我们写代码处理
在那个公众号位置,就是有双等号的位置,添加以下字段
&f=json&offset=0&count=10
如下:
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=保密==&f=json&offset=0&count=10&scene=124&uin=保密%3D%3D&key=5cc14d5e215be3edfddab345c1e7d1545790a5d5106ac566ca33c21751c8578150126ebd750daa11336a1b536880ad8a814eb7be46e0e87e59f6c53828a3598637f04c6e8f8ebceb27fe27ed90797757&devicetype=Windows+10+x64&version=62090070&lang=zh_CN&a8scene=7&pass_ticket=lhCQ79EkT0QdVeeyIOeLJKN5WNTdCHysp252vVp7H4qdBHq5iSNThsQgO7qvPqul&winzoom=1
拼接出来的链接可以用浏览器打开验证下:
这个链接即是程序能处理的链接了,然后里面的文章链接,根据我的发现是永久的,不是临时,所以先爬取一级文章列表页,然后永久存储,然后设置个队列,再随机处理详情页,即我们需要的文章内容即可,同样的,操作也不能过于频繁
如果你要翻页,改下拼接的参数中的offset的值即可,首页就是0,第二页就是10,第三页就是20......
这里我再给几个微信的请求头,一般的浏览器请求头是会被识别屏蔽的,它会提示让你登录手机微信,反正就是打不开
‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.884.400 QQBrowser/9.0.2524.400‘,
‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/605.1.15 (KHTML, like Gecko) MicroMessenger/2.3.30(0x12031e10) MacWechat Chrome/39.0.2171.95 Safari/537.36 NetType/WIFI WindowsWechat MicroMessenger/2.3.30(0x12031e10) MacWechat Chrome/39.0.2171.95 Safari/537.36 NetType/WIFI WindowsWechat‘,
‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1301.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116 Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat‘,
‘Mozilla/5.0 (iPhone; CPU iPhone OS 12_4_4 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/7.0.12(0x17000c2d) NetType/WIFI Language/zh_CN‘
‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36‘
注:操作不能过于频繁,并且我个人建议,每天采集不要都用同一个号来爬取,准备几个号,换着换着来
6.改进
以上的说白了就是半自动的操作,如果你觉得每次还要手动的获取链接,然后拼接很繁琐,其实可以做成全自动的,大概就是用selenium/appium配合即可,网上也有这方面的教程,这里就不展示了,自行选择了
好的,以上就是一些理论操作,具体的代码由于涉及到隐私问题,就不给代码展示了
以上是关于对WX公众号文章的爬取分析的主要内容,如果未能解决你的问题,请参考以下文章