如何抓取微信所有公众号最新文章
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何抓取微信所有公众号最新文章相关的知识,希望对你有一定的参考价值。
经常有朋友需要帮忙做公众号文章爬取,这次来做一个各种方法的汇总说明。
目前爬取微信公众号的方法主要有3种:
通过爬取第三方的公众号文章聚合网站
通过微信公众平台引用文章接口
通过抓包程序,分析微信app访问公众号文章的接口
通过第三方的公众号文章聚合网站爬取
微信公众号文章一直没有提供一个对外的搜索功能,直到2013年微信投资搜狗之后,搜狗搜索接入微信公众号数据,从此使用搜狗搜索就可以浏览或查询到相关公众号以及文章。
域名是: https://weixin.sogou.com/
可以直接搜索公众号或者文章的关键字,一些热门的公众号更新还是很及时的,几乎做到了和微信同步。
所以,爬一些热门公众号可以使用搜狗微信的接口来做,但是一些小众公众号是搜索不到的,而且搜狗的防爬机制更新的比较勤,获取数据的接口变化的比较快,经常两三个月就有调整,导致爬虫很容易挂,这里还是建议使用 selenium爬比较省心。另外搜狗对每个ip也有访问限制,访问太频ip会被封禁24小时,需要买个ip池来做应对。
还有一些其他公众号文章聚合网站(比如传送门)也都存在更新不及时或者没有收录的问题,毕竟搜狗这个亲儿子都不行。
通过微信公众平台引用文章接口
这个接口比较隐蔽而且没法匿名访问,所有得有一个公众号,建议新注册一个公众号比较好,免得被封。
下面开始具体步骤:首先登录自己的微信公众号,在进去的首页选择 新建群发,然后再点击 自建图文,在文章编辑工具栏中找到 超链接,如下图:

点击这个超链接按钮,就会弹出一个对话框,链接输入方式这一项选中 查找文章,如下图:

到这里就可以输入公众号的名字,回车之后微信就会返回相匹配的公众号列表,接着点击你想抓取的公众号,就会显示具体的文章列表了,已经是按时间倒序了,最新的文章就是第一条了。
微信的分页机制比较奇怪,每个公众号的每页显示的数据条数是不一样的,分页爬的时候要处理一下。
通过chrome分析网络请求的数据,我们想要的数据已经基本拿到了,文章链接、封面、发布日期、副标题等,如
由于微信公众平台登录验证比较严格,输入密码之后还必须要手机扫码确认才能登录进去,所以最好还是使用 selenium做自动化比较好。具体微信接口的分析过程我就不列了,直接贴代码了:
import re
import time
import random
import traceback
import requests
from selenium import webdriver
class Spider(object):
'''
微信公众号文章爬虫
'''
def __init__(self):
# 微信公众号账号
self.account = '286394973@qq.com'
# 微信公众号密码
self.pwd = 'lei4649861'
def create_driver(self):
'''
初始化 webdriver
'''
options = webdriver.ChromeOptions()
# 禁用gpu加速,防止出一些未知bug
options.add_argument('--disable-gpu')
# 这里我用 chromedriver 作为 webdriver
# 可以去 http://chromedriver.chromium.org/downloads 下载你的chrome对应版本
self.driver = webdriver.Chrome(executable_path='./chromedriver', chrome_options=options)
# 设置一个隐性等待 5s
self.driver.implicitly_wait(5)
def log(self, msg):
'''
格式化打印
'''
print('------ %s ------' % msg)
def login(self):
'''
登录拿 cookies
'''
try:
self.create_driver()
# 访问微信公众平台
self.driver.get('https://mp.weixin.qq.com/')
# 等待网页加载完毕
time.sleep(3)
# 输入账号
self.driver.find_element_by_xpath("./*//input[@name='account']").clear()
self.driver.find_element_by_xpath("./*//input[@name='account']").send_keys(self.account)
# 输入密码
self.driver.find_element_by_xpath("./*//input[@name='password']").clear()
self.driver.find_element_by_xpath("./*//input[@name='password']").send_keys(self.pwd)
# 点击登录
self.driver.find_elements_by_class_name('btn_login')[0].click()
self.log("请拿手机扫码二维码登录公众号")
# 等待手机扫描
time.sleep(10)
self.log("登录成功")
# 获取cookies 然后保存到变量上,后面要用
self.cookies = dict([[x['name'], x['value']] for x in self.driver.get_cookies()])
except Exception as e:
traceback.print_exc()
finally:
# 退出 chorme
self.driver.quit()
def get_article(self, query=''):
try:
url = 'https://mp.weixin.qq.com'
# 设置headers
headers =
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
# 登录之后的微信公众号首页url变化为:https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=1849751598,
# 从这里获取token信息
response = requests.get(url=url, cookies=self.cookies)
token = re.findall(r'token=(\\d+)', str(response.url))[0]
time.sleep(2)
self.log('正在查询[ %s ]相关公众号' % query)
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
# 搜索微信公众号接口需要传入的参数,
# 有三个变量:微信公众号token、随机数random、搜索的微信公众号名字
params =
'action': 'search_biz',
'token': token,
'random': random.random(),
'query': query,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'begin': '0',
'count': '5'
# 打开搜索微信公众号接口地址,需要传入相关参数信息如:cookies、params、headers
response = requests.get(search_url, cookies=self.cookies, headers=headers, params=params)
time.sleep(2)
# 取搜索结果中的第一个公众号
lists = response.json().get('list')[0]
# 获取这个公众号的fakeid,后面爬取公众号文章需要此字段
fakeid = lists.get('fakeid')
nickname = lists.get('nickname')
# 微信公众号文章接口地址
search_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
# 搜索文章需要传入几个参数:登录的公众号token、要爬取文章的公众号fakeid、随机数random
params =
'action': 'list_ex',
'token': token,
'random': random.random(),
'fakeid': fakeid,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'begin': '0', # 不同页,此参数变化,变化规则为每页加5
'count': '5',
'query': '',
'type': '9'
self.log('正在查询公众号[ %s ]相关文章' % nickname)
# 打开搜索的微信公众号文章列表页
response = requests.get(search_url, cookies=self.cookies, headers=headers, params=params)
time.sleep(2)
for per in response.json().get('app_msg_list', []):
print('title ---> %s' % per.get('title'))
print('link ---> %s' % per.get('link'))
# print('cover ---> %s' % per.get('cover'))
except Exception as e:
traceback.print_exc()
if __name__ == '__main__':
spider = Spider()
spider.login()
spider.get_article('python')
代码只是作为学习使用,没有做分页查询之类。实测过接口存在访问频次限制,一天几百次还是没啥问题,太快或者太多次访问就会被封24小时。
参考技术A 用Python自己写抓取规则。不会的话,也可以去网上找接口。反正,人才多得很。[Python爬虫] 之十五:Selenium +phantomjs根据微信公众号抓取微信文章
借助搜索微信搜索引擎进行抓取
抓取过程
1、首先在搜狗的微信搜索页面测试一下,这样能够让我们的思路更加清晰
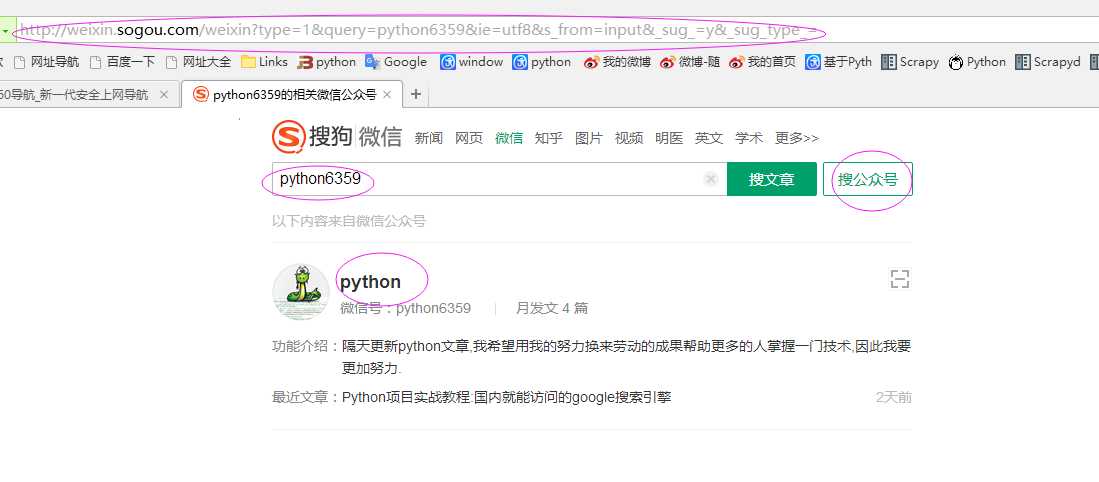
在搜索引擎上使用微信公众号英文名进行“搜公众号”操作(因为公众号英文名是公众号唯一的,而中文名可能会有重复,同时公众号名字一定要完全正确,不然可能搜到很多东西,这样我们可以减少数据的筛选工作,
只要找到这个唯一英文名对应的那条数据即可),即发送请求到‘http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&_sug_=n&_sug_type_= ‘ % ‘Python‘,并从页面中解析出搜索结果公众号对应的主页跳转链接。
在抓取过程中用到了pyquery 也可以用xpath
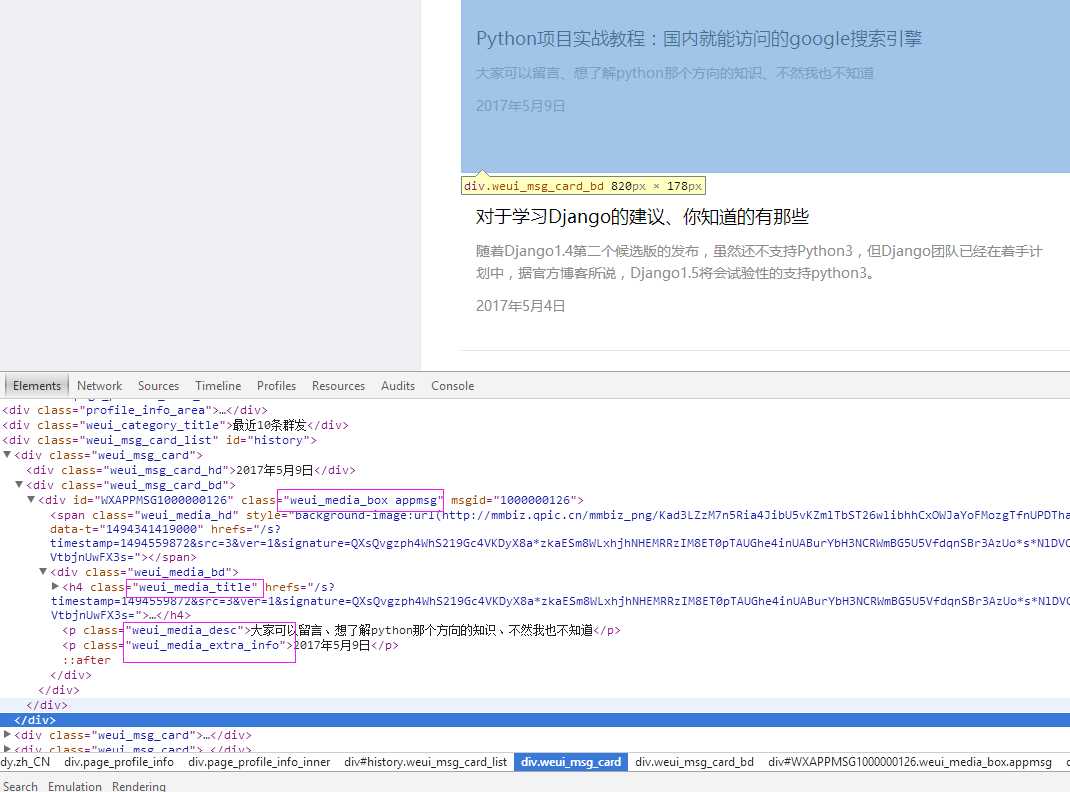
文件保存:
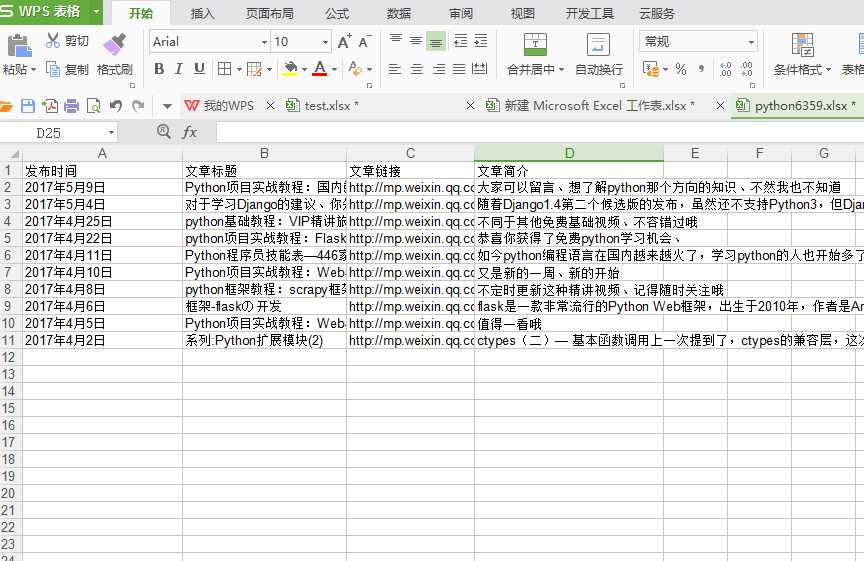
完整代码如下:
# coding: utf-8
# 这三行代码是防止在python2上面编码错误的,在python3上面不要要这样设置
import sys
reload(sys)
sys.setdefaultencoding(‘utf-8‘)
from urllib import quote
from pyquery import PyQuery as pq
from selenium import webdriver
from pyExcelerator import * # 导入excel相关包
import requests
import time
import re
import json
import os
class wx_spider:
def __init__(self,Wechat_PublicID):
‘‘‘
构造函数,借助搜狗微信搜索引擎,根据微信公众号获取微信公众号对应的文章的,发布时间、文章标题, 文章链接, 文章简介等信息
:param Wechat_PublicID: 微信公众号
‘‘‘
self.Wechat_PublicID = Wechat_PublicID
#搜狗引擎链接url
self.sogou_search_url = ‘http://weixin.sogou.com/weixin?type=1&query=%s&ie=utf8&s_from=input&_sug_=n&_sug_type_=‘ % quote(Wechat_PublicID)
# 爬虫伪装头部设置
self.headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.3; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0‘}
# 超时时长
self.timeout = 5
# 爬虫模拟在一个request.session中完成
self.session = requests.Session()
# excel 第一行数据
self.excel_headData = [u‘发布时间‘, u‘文章标题‘, u‘文章链接‘, u‘文章简介‘]
# 定义excel操作句柄
self.excle_Workbook = Workbook()
def log(self, msg):
‘‘‘
日志函数
:param msg: 日志信息
:return:
‘‘‘
print u‘%s: %s‘ % (time.strftime(‘%Y-%m-%d %H-%M-%S‘), msg)
def run(self):
#Step 0 : 创建公众号命名的文件夹
if not os.path.exists(self.Wechat_PublicID):
os.makedirs(self.Wechat_PublicID)
# 第一步 :GET请求到搜狗微信引擎,以微信公众号英文名称作为查询关键字
self.log(u‘开始获取,微信公众号英文名为:%s‘ % self.Wechat_PublicID)
self.log(u‘开始调用sougou搜索引擎‘)
self.log(u‘搜索地址为:%s‘ % self.sogou_search_url)
sougou_search_html = self.session.get(self.sogou_search_url, headers=self.headers, timeout=self.timeout).content
# 第二步:从搜索结果页中解析出公众号主页链接
doc = pq(sougou_search_html)
# 通过pyquery的方式处理网页内容,类似用beautifulsoup,但是pyquery和jQuery的方法类似,找到公众号主页地址
wx_url = doc(‘div[class=txt-box]‘)(‘p[class=tit]‘)(‘a‘).attr(‘href‘)
self.log(u‘获取wx_url成功,%s‘ % wx_url)
# 第三步:Selenium+PhantomJs获取js异步加载渲染后的html
self.log(u‘开始调用selenium渲染html‘)
browser = webdriver.PhantomJS()
browser.get(wx_url)
time.sleep(3)
# 执行js得到整个页面内容
selenium_html = browser.execute_script("return document.documentElement.outerHTML")
browser.close()
# 第四步: 检测目标网站是否进行了封锁
‘ 有时候对方会封锁ip,这里做一下判断,检测html中是否包含id=verify_change的标签,有的话,代表被重定向了,提醒过一阵子重试 ‘
if pq(selenium_html)(‘#verify_change‘).text() != ‘‘:
self.log(u‘爬虫被目标网站封锁,请稍后再试‘)
else:
# 第五步: 使用PyQuery,从第三步获取的html中解析出公众号文章列表的数据
self.log(u‘调用selenium渲染html完成,开始解析公众号文章‘)
doc = pq(selenium_html)
articles_list = doc(‘div[class="weui_media_box appmsg"]‘)
articlesLength = len(articles_list)
self.log(u‘抓取到微信文章%d篇‘ % articlesLength)
# Step 6: 把微信文章数据封装成字典的list
self.log(u‘开始整合微信文章数据为字典‘)
# 遍历找到的文章,解析里面的内容
if articles_list:
index = 0
# 以当前时间为名字建表
excel_sheet_name = time.strftime(‘%Y-%m-%d‘)
excel_content = self.excle_Workbook.add_sheet(excel_sheet_name)
colindex = 0
columnsLength = len(self.excel_headData)
for data in self.excel_headData:
excel_content.write(0, colindex, data)
colindex += 1
for article in articles_list.items():
self.log(‘ ‘ )
self.log(u‘开始整合(%d/%d)‘ % (index, articlesLength))
index += 1
# 处理单个文章
# 获取标题
title = article(‘h4[class="weui_media_title"]‘).text().strip()
self.log(u‘标题是: %s‘ % title)
# 获取标题对应的地址
url = ‘http://mp.weixin.qq.com‘ + article(‘h4[class="weui_media_title"]‘).attr(‘hrefs‘)
self.log(u‘地址为: %s‘ % url)
# 获取概要内容
# summary = article(‘.weui_media_desc‘).text()
summary = article(‘p[class="weui_media_desc"]‘).text()
self.log(u‘文章简述: %s‘ % summary)
# 获取文章发表时间
# date = article(‘.weui_media_extra_info‘).text().strip()
date = article(‘p[class="weui_media_extra_info"]‘).text().strip()
self.log(u‘发表时间为: %s‘ % date)
# # 获取封面图片
# pic = article(‘.weui_media_hd‘).attr(‘style‘)
#
# p = re.compile(r‘background-image:url(.+)‘)
# rs = p.findall(pic)
# if len(rs) > 0:
# p = rs[0].replace(‘(‘, ‘‘)
# p = p.replace(‘)‘, ‘‘)
# self.log(u‘封面图片是:%s ‘ % p)
tempContent = [date, title, url, summary]
for j in range(columnsLength):
excel_content.write(index, j, tempContent[j])
self.excle_Workbook.save(self.Wechat_PublicID + ‘/‘ + self.Wechat_PublicID + ‘.xlsx‘)
self.log(u‘保存完成,程序结束‘)
if __name__ == ‘__main__‘:
wx_spider("python6359").run()
以上是关于如何抓取微信所有公众号最新文章的主要内容,如果未能解决你的问题,请参考以下文章