LOCALIZATION, DETECTION AND TRACKING OF MULTIPLE MOVING SOUND SOURCES WITH A CONVOLUTIONAL RECURRENT
Posted minyuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LOCALIZATION, DETECTION AND TRACKING OF MULTIPLE MOVING SOUND SOURCES WITH A CONVOLUTIONAL RECURRENT相关的知识,希望对你有一定的参考价值。
摘要
本文研究了使用卷积递归神经网络对声音事件进行联合定位、检测和跟踪。我们使用先前提出的用于定位和检测静止源的CRNN,并且表明当使用动态场景训练时,递归层能够实现运动源的空间跟踪。将该神经网络的跟踪性能与结合了多源(波达方向)估计器和粒子滤波器的独立跟踪方法进行了比较。它们各自的性能在各种声学条件下进行评估,如消声和混响场景、不同角速度下的固定和移动声源以及不同数量的重叠声源。结果表明,在各种声学场景下,CRNN能够比参数方法更一致地跟踪多个声源,但代价是定位误差更大。
关键词:多目标跟踪、递归神经网络、声音事件检测、声音定位
1.介绍
声音事件定位、检测和跟踪(SELDT)是识别潜在时间重叠的声音事件的时间开始和偏移,识别它们的类别,并在它们活动时跟踪它们各自的空间轨迹的综合任务。成功地执行SELDT提供了声学场景的自动描述,机器可以使用该描述来与它们的环境自然地交互。电话会议系统和机器人等应用可以利用这些信息来跟踪感兴趣的声音事件[1–6]。此外,智能城市和智能家庭可以将其用于音频监控[7–9]。
利用不同的参数[5,8,10,11]和基于深度神经网络(DNN)[12]的方法,研究了空间静止源静态场景中的定位和检测。然而,这些方法不使用任何时间建模所需的跟踪运动源在动态场景。最近,我们提出了一种卷积循环神经网络(SELDnet),它被证明比目前唯一的基于dnn的方法[12]具有更好的定位和检测性能。在匹配和不匹配的声学条件下,SELDnet在全方位和高度定位事件的能力,并且不依赖于依赖于特定麦克风阵列的特征,在[13]中进行了研究和展示。然而,[13]只研究静态场景。
另一方面,基于空间信息[14-20]、附加光谱信息[21,22]或与视觉信息[23]相结合的静态和移动源的独立跟踪方法已经得到广泛研究。这些参数的方法通常需要手动调整与场景组成和动态相对应的多个参数,并且必须针对不同的声音场景手动识别新的参数集。此外,跟踪通常侧重于识别源轨迹,而不考虑源信号内容。在时间重叠轨迹的情况下,轨迹标识被分配给单个轨迹,但这些标识不依赖于源,并且通常被重复用于音频录音中来自不同源的轨迹。在大多数情况下,一致关联和定位之间的平衡决定了跟踪器的性能。或者,像在提议的seldnet中,先检测后跟踪的方法,通过首先检测活动的声音事件,然后为每个检测到的事件分配一个音轨,绕过了关联问题。只要该系统能够对时刻变化的条件作出反应,同时具有来自静止源和运动源的时间和空间重叠的声音事件,它也能够检测和跟踪感兴趣的声音事件。
在这项工作中,我们研究了基于我们最近提出的SELDnet[13]的检测和定位系统的多源跟踪能力。我们表明,使用动态场景数据训练SELDnet除了可以实现定位和检测外,还可以实现跟踪。这种跟踪能力是由SELDnet的循环层实现的,它可以将空间参数的演化建模为给定序列特征及其空间轨迹信息的序列预测任务。我们证明了循环层对于跟踪是至关重要的,与独立的跟踪器相比,它们额外执行检测。与前面讨论的参数跟踪方法不同,递归层是一种通用的跟踪方法,它直接从数据中学习,不需要人工跟踪工程。最后,通过对5个数据集的评估,SELDnet的跟踪性能与独立参数跟踪方法具有可比性,这些数据集分别代表了不同角速度的静止源和运动源、消声和混响环境以及不同数量重叠源的场景。该方法和所有研究的数据集都是公开的。
2.方法
一个声学场景,例如一个公园,其特征在于其中的声音事件,如狗叫和鸟叫,由它们各自的来源狗和鸟产生。在SELDT任务中,我们旨在声学上检测声音事件的时间活动,并进一步定位空间中产生声音事件的源并跟踪它们的运动。当激活时,检测任务产生每个声音事件类的开始和偏移时间。类似地,当声音事件活动时,跟踪产生声源运动的空间轨迹。
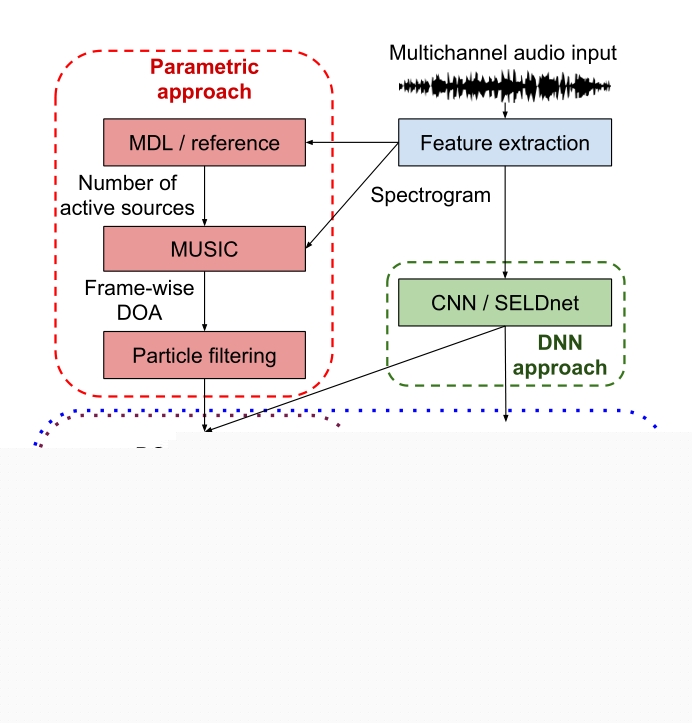
图1:参数跟踪和基于DNN的SELDT方法的工作流程。这里显示跟踪任务的声音类着色和命名只是为了更好地可视化概念。在实践中,跟踪方法不会产生如图3所示的声音类标签。
SELDnet [13]基于卷积递归神经网络架构,其中当声音事件被检测为活动时,以回归方式估计声音事件的到达方向(DOA)。如图1所示,SELDnet的输入是多声道音频记录,特征提取模块从中提取频谱图的相位和幅度分量。SELDnet将声谱图映射到两个输出——声音事件检测和跟踪;它们一起产生SELDT输出。检测为数据集中存在的声音类别产生时间活动。当跟踪处于活动状态时,它只为每个声音类别产生一个波达方向轨迹,即,如果同一声音类别的多个实例在时间上重叠,SELDnet只跟踪一个或在多个实例之间振荡。
我们使用在[13]中提出的SELDnet体系结构,三个卷积层各有64个滤波器,然后是两层128节点门控递归单元。循环层的输出被馈送到密集层的两个分支,每个分支具有产生检测和跟踪估计的128个单元。SELDnet中的卷积层被用作特征提取器,以产生用于检测和跟踪的鲁棒特征。给定T帧的谱图输入,卷积层产生长度为T的帧方向特征。这些特征被映射到两个长度为T的帧方向输出,即检测和跟踪,使用共享递归层。
循环层利用当前输入帧以及从先前输入帧中学习的信息来产生当前帧的输出。这个过程类似于粒子滤波器,粒子滤波器是一种流行的独立参数跟踪器,在本文中也用作基线(参见第3.3节)。当前时间范围内的粒子滤波预测受到前一个时间范围内累积的知识和当前时间范围内的知识的影响。对于本文的跟踪任务,粒子滤波器需要声音场景的特定知识,例如声音事件的空间分布、它们在活动时各自的速度范围以及它们的出生和死亡概率。
这样的概念并没有在SELDnet中使用的递归层中显式建模,而是直接从开发数据集中输入卷积层特征和相应目标输出中学习等效信息。事实上,循环层已经被证明可以作为通用跟踪器[24],它可以从任何连续输入特征中学习目标源的时间关联。与仅使用概念表示(如用于跟踪的逐帧多波达方向)的粒子滤波器不同,循环层与概念表示和潜在表示(如卷积层特征)都无缝工作。
最后,通过使用从检测和跟踪计算的损失来训练SELDnet中的循环层,循环层学习来自对应于相同声音类别的相邻帧的波达方向之间的关联,并因此产生SELDT结果。一般来说,与参数跟踪器不同,循环层除了检测它们相应的声音类别之外,还执行类似的帧方向波达方向跟踪。此外,循环层不需要参数跟踪器所需的复杂的特定问题跟踪器或特征工程。文献[25]中提出了循环层和粒子滤波之间的理论关系。
3.评估过程
3.1数据集

SELDnet的性能是在表1中总结的五个数据集上评估的。我们继续使用我们以前工作[13]中的固定源数据集来评估[13]中缺失的参数跟踪器的跟踪性能,并与SELDnet进行比较。此外,我们创建了ANSYN和REAL数据集的移动源版本来评估移动源的性能。所研究的数据集是使用合成和真实生活脉冲响应合成的,用于消声和混响场景。所有数据集的记录都是30秒长,并以四通道一阶环境声学格式捕获[26]。每个数据集有三个子集,没有时间重叠的源O1、最多两个O2和最多三个时间重叠的源O3。这些子集的每一个都有三个交叉验证分割,240个记录用于开发,60个用于评估。所有的合成脉冲响应数据集都有来自11个级别和DOAs的声音事件,全方位距离和仰角距离∈[- 60,60]。真实的脉冲响应数据集有8个声音事件类别和全方位范围和仰角范围∈[- 40,40]的DOAs。在合成过程中,静止源数据集中的所有声音事件都被放置在一个10?方位角和仰角分辨率的空间网格中。有关这些数据集的更多细节,请参阅[13]。
消声移动源数据集MANSYN具有与ANSYN相同的声音事件类别,合成如下。每个事件都被分配一个空间轨迹,该轨迹在一个弧上,与麦克风的距离恒定(在1-10米的范围内),并且在其持续时间内以恒定的角速度移动。由于选择了ambisonic双声波空间记录格式,在远场中平面波源或点源的引导矢量是频率无关的。因此,当源移动时,不需要时变卷积或脉冲响应插值方案;对单声道信号的空间编码采用瞬时ambisonic编码向量对运动源的各自DOA进行逐次采样。在MANSYN中合成的轨迹在方位角和仰角都有变化,并且被模拟为具有恒定的角速度,在射程∈[?90?,90?]/s和10步/s。同样,MREAL数据集合成了真实生活的脉冲响应,从[13]采样在1?分辨率沿方方位仅。因此,与MANSYN不同的是,MREAL中的声音事件(与REAL相同)仅沿方位角运动,且角速度恒定,其范围为∈[?90?,90?]/s和10步/s。
3.2评估
SELDT性能的评估是使用与[13]相同的单独检测和跟踪指标完成的。作为检测指标,我们使用在没有重叠的一秒钟的片段中计算的分数和错误率[27]。一种理想的检测方法的F值为1,错误率为零。作为跟踪度量,我们使用两个逐帧度量:帧召回率和波达方向误差。帧召回给出了预测的DOAs数量与引用数量相等的帧的百分比。DOA误差以预测DOA与参考DOA之间的角度(以度数为单位)计算。为了将多个估计的波达方向与参考相关联,我们使用匈牙利算法[28]来识别最小的平均角距离,并将其用作波达方向误差。理想的跟踪方法是帧召回率为1,DOA错误为0(详见[13])。
3.3基线方法
作为基线方法,我们结合使用MUSIC[29]和RBMCDA粒子滤波器[30]来获得与[15]相似的跟踪结果。基线方法的工作流如图1所示。MUSIC是一种广泛使用的基于[13,31]子空间的高分辨率波达方向估计方法,可以检测多个窄带源。它依赖于从多通道谱图计算的窄带空间协方差矩阵的特征分解,并且它还需要源号估计,以便在信号和噪声子空间之间进行区分。这里,活动源的数量取自数据集的参考。为了获得宽带波达方向估计,窄带协方差矩阵在从50赫兹到8千赫兹的三个连续帧和频率仓中进行平均。我们在2D角网格上生成的合成MUSIC伪谱上执行2D球形峰值发现,在方位角和仰角上,静止源的分辨率为10,运动源的分辨率为1。MUSIC MU SGT的最终输出是一个帧方向的波达方向列表,对应于每个帧中活动源数量的最高峰值。
第二阶段产生的参数方法涉及一个粒子滤波跟踪结果通过处理MUSIC MU SGT的帧方向波达方向信息来产生跟踪结果。粒子滤波器假设每个时间帧的源数量未知,并使用固定数量的粒子相对于时间来跟踪它们。在每个时间帧,粒子滤波器接收多个波达方向,并基于从先前时间帧积累的知识,将每个新的波达方向分配给现有轨迹、杂波(噪声)或新生源之一。此外,它还决定是否有任何现有的轨道已经死亡。粒子滤波器的最终输出MU SPFGT产生每个活动声音事件的时间起始偏移和波达方向轨迹。本文中使用的跟踪器实现已公开发布。有关此方法的详细信息,请读者参阅[30]。
3.4实验
在我们所有的实验中,SELDnet的基线粒子滤波器参数和输入谱图的序列长度都是使用各自子集的开发集进行调整的。在子集的评估集上测试了优化后的方法的性能,并对子集的三种跨验证划分进行了详细的报告。
与基于DNN的方法不同,参数方法需要关于每帧活动源数量的附加信息来估计相应的波达方向。但是,SELDnet从数据本身获取这些信息。为了有一个公平的比较,我们使用最小描述长度(MDL) [32]原理从输入谱图中估计源的数量,并将其与MUSIC一起使用,产生MU SM DL的MUSIC输出和MU SPF M DL的相应粒子滤波输出。
最后,我们研究了递归层对于SELDT任务的重要性,方法是将它们从SELDnet中移除,并评估只包含卷积层和密集层的模型,以下称为CNN。跨数据集的最佳CNN架构有五个卷积层,每个层有64个滤波器。
4.结果和讨论
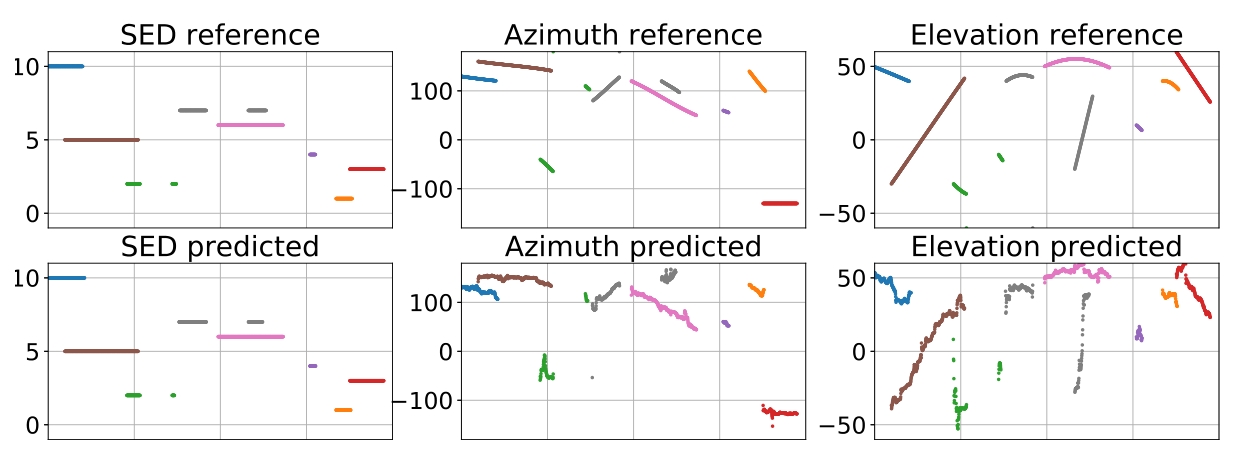
图2:SELDnet预测及其对MANSYN O2数据集记录的各自引用的可视化。所有子图的水平轴表示相同的时间帧。垂直轴代表探测副图的声音事件分类指数,其余副图的DOA方位角和仰角以度数表示。
在调整SELDnet的输入序列长度时,我们发现256帧的序列在混响数据集中得分最高,而在消声数据集中得分最高的是512帧。SELDnet的预测和相应的参考在图2中显示,分别来自MANSYN O2数据集的1000帧测试序列。每个声音类在次要情节中都用一种独特的颜色表示。我们看到,探测到的声音事件是准确的比较参考。DOA的预测可以看到在参考轨迹周围有一个小的偏差。这说明SELDnet能够成功地跟踪和识别多个重叠的移动源。
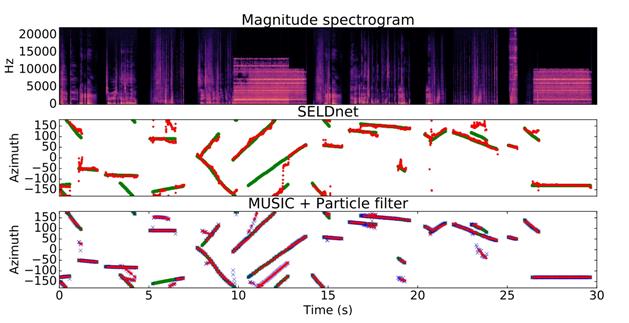
图3:对于MANSYN O2数据集记录,这两种被提议的方法的跟踪结果是可视化的。上图为输入谱图。中间和底部的图用红
色显示SELDnet和MU SPF GT跟踪的输出,分类准确性用绿色显示。底部图中的蓝色叉表示音乐的帧DOA输出
图3可视化展示了SELDnet和基线方法MU SPF GT的跟踪预测和各自的参考。一般来说,两种方法的性能在视觉上是可以比较的。这两种方法在类似的情况下经常被混淆,例如在4-5秒、10-13秒和23-25秒的间隔。
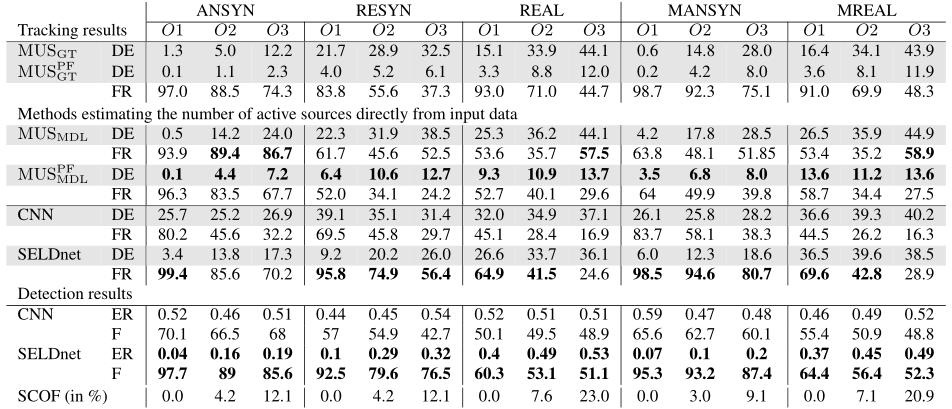
表2:不同数据集的评价结果。DE: DOA错误,FR:帧召回,F: F-score, SCOF:同一类重叠帧
根据设计,SELDnet被限制为只能识别给定声音类的一个DOA。但在现实生活中,同一类声音可能同时出现多个实例。这在研究的数据集中也可以看到,表2中的最后一行(SCOF)显示了同一类与自身重叠的帧的百分比。相比之下,参数化方法在设计上没有这样的限制,并且在这些帧中可能比SELDnet表现得更好(尽管来自不同DOAs的高度相关的声音事件很容易降低参数化方法(如MUSIC)的性能)。在图3的10-13 s区间内可以观察到这两种方法在这种场景中的性能。SELDnet只跟踪两个源中的一个,而参数化方法跟踪两个重叠的源,并在两个轨迹之间引入额外的假轨迹。
表2给出了研究方法的定量结果。总趋势如下。重叠源个数越多,SELDnet和参数法的跟踪性能越差。在数据集中,使用时间粒子滤波跟踪器可以显著提高DOA误差,但代价是较低的帧回忆率。
使用参数化方法的总体性能降低(MU SPF GT> MU SPF MDL)。这种减少在帧回忆度量中尤其明显,对于混响源和移动源场景数据集显著下降,这表明需要更健壮的源检测和计数方案。
SELDnet的帧回忆率始终优于MU SPF MDL,但对数据集的DOA估计较差。之间的相似关系观察SELDnet 和MU SPF GT采用模拟脉冲响应生成的数据集,而对于现实中的脉冲响应数据帧召回SELDnet比MU SPF GT差。这可能表明需要更广泛的学习对于实际的脉冲响应数据集而言,更大的数据库和更强的模型。
使用循环层肯定有助于SELDT任务。从可视化中可以看出,CNN的跟踪性能很差,DOA轨迹失真且方差大,导致数据集间DOA误差很差,如表2所示。这表明递归层对于SELDT任务是至关重要的,它可以执行类似于RBMCDA粒子过滤器的任务,即识别相关的帧间DOAs,并将这些DOAs在不同的时间帧中对应于相同的声音类。
5. 结论
在本文中,我们提出了第一种基于深度神经网络的方法SELDnet,用于检测动态声学场景中每个声音事件的时间开始和偏移时间,在空间中定位它们并在活动时跟踪它们的位置,以及最终识别声音事件类别的组合任务。SELDnet的性能是在五个不同的数据集上进行评估的,这些数据集包含固定和移动源、消声和混响场景以及不同数量的重叠源。结果表明,SELDnet采用的递归层对跟踪性能至关重要。此外,将SELDnet的跟踪性能与基于多信号分类和粒子滤波的独立参数方法进行了比较。总的来说,SELDnet跟踪性能与参数方法相当,并实现了更高的跟踪帧召回率,但角度误差更大。
以上是关于LOCALIZATION, DETECTION AND TRACKING OF MULTIPLE MOVING SOUND SOURCES WITH A CONVOLUTIONAL RECURRENT的主要内容,如果未能解决你的问题,请参考以下文章
CV 第十一课 Segmentation Localization Detection 下
(Review cs231n) Spatial Localization and Detection(classification and localization)
Constrained Image Splicing Detection and Localization With Attention-Aware Encoder-Decoder and Atrou
Instance Localization for Self-supervised Detection Pretraining 解读
Instance Localization for Self-supervised Detection Pretraining 解读