《LD:Localization Distillation for Object Detection》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《LD:Localization Distillation for Object Detection》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:LD
1. 概述
导读:这篇文章研究的是检测场景下的知识蒸馏方案。在该场景下的蒸馏有采取直接将对应特征图匹配到对应维度之后做特征图差异最小化,也有使用Teacher输出的GT作为引导排除大量背景等无关信息的。在这篇文章中参考和借鉴了在原分类网络中做蒸馏的思想,也就是在网络输出概率分布软化之后做蒸馏。因而这篇文章就使用到GFocal的边界框回归方案,这样就可以直接在输出的概率分布上做蒸馏,从而避免了Teacher和Student网络结构不对应带来的匹配问题,因此更加灵活。在实际进行蒸馏的时候文章指出直接将大小模型进行蒸馏其实是次优的策略,因而提出了一种渐进蒸馏的方案。除了传统上将大小模型进行蒸馏,文章也指出可以使用Self-Distillation的方法实现更加稳定的训练和达到更好的结果。
在检测场景下会遇到一些边界模糊的场景,如下图中红色的虚线圈处:

直接使用传统的只是蒸馏策略是很难显式捕获到这些信息的,需要对其进行建模,而GFocal正是完成此项任务的,因而这篇文章就是在GFocal输出概率分布基础上实现蒸馏。
2. 方法设计
2.1 Localization Distillation(LD)
在GFocal中边界框的输出是区间上概率分布,每条边的回归值可以描述为离散积分的形式(具体请参考GFocal论文):
e
^
=
e
T
p
=
∑
i
=
1
n
e
i
P
r
(
e
i
)
,
e
∈
l
,
r
,
b
,
t
\\hate=e^Tp=\\sum_i=1^ne_iPr(e_i),\\ e\\in\\l,r,b,t\\
e^=eTp=i=1∑neiPr(ei), e∈l,r,b,t
则这里的概率分布就可以套用在分类中的蒸馏,直接加上软化因子进行概率分布上的蒸馏,避免了需要网络维度适配的问题。其蒸馏的示意图如下:
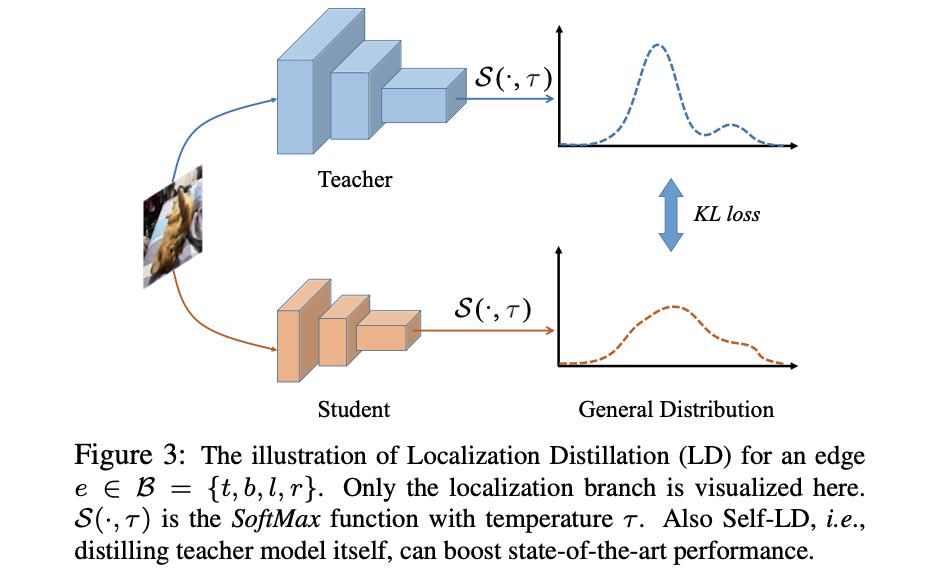
上文中提到的软化因子
τ
\\tau
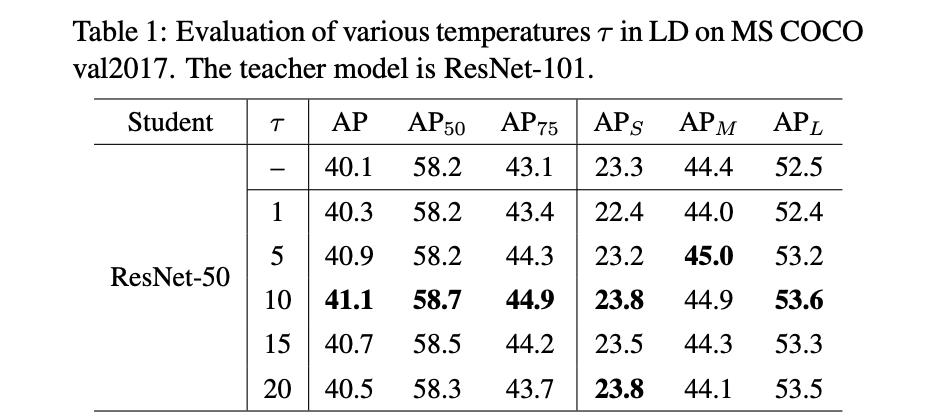
τ对蒸馏网络性能的影响如下:
2.2 Teacher Assistant Strategy
文章指出直接将大小模型进行蒸馏其结果是次优的,对此可以在大小模型中间线性划分出几个不同大小的模型(也就是Teacher Assistant),之后从大模型沿着这些设计出来的模型逐渐进行蒸馏,但是这样的操作会消耗很多的时间和算力。也就是看下图的形式,从模型T到S设计出从大到小变化的一些网络
A
1
,
A
2
,
…
,
A
m
\\A_1,A_2,\\dots,A_m\\
A1,A2,…,Am,然后从
A
1
A_1
A1到
A
m
A_m
Am逐渐蒸馏。
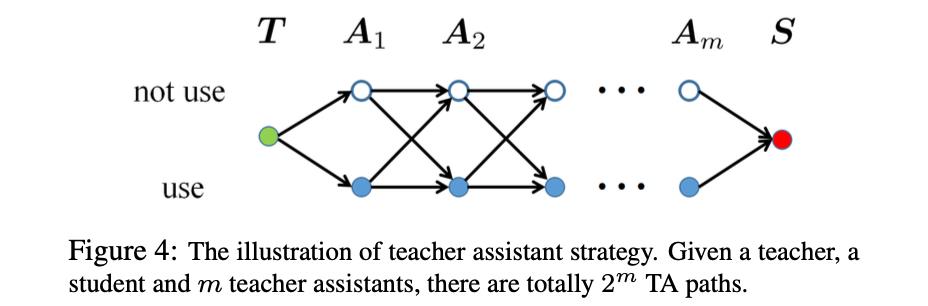
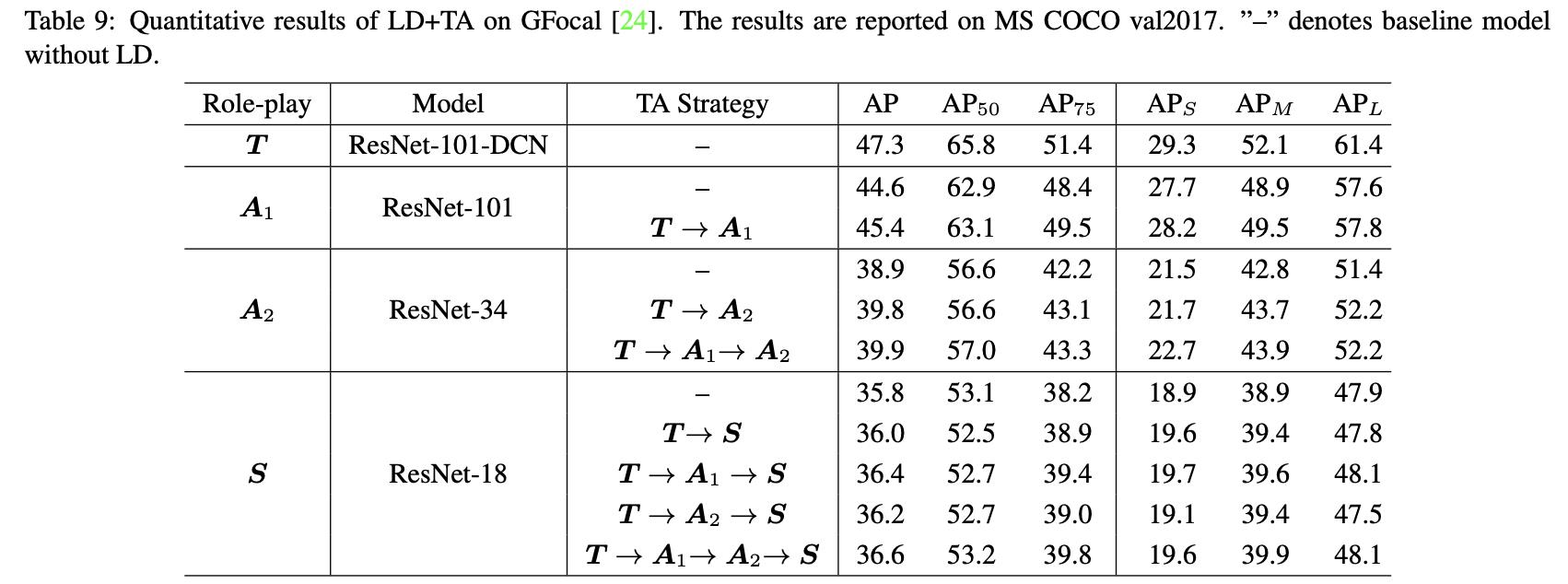
下表展示了逐渐蒸馏与直接进行蒸馏得到的结果对比:
2.3 Self-LD
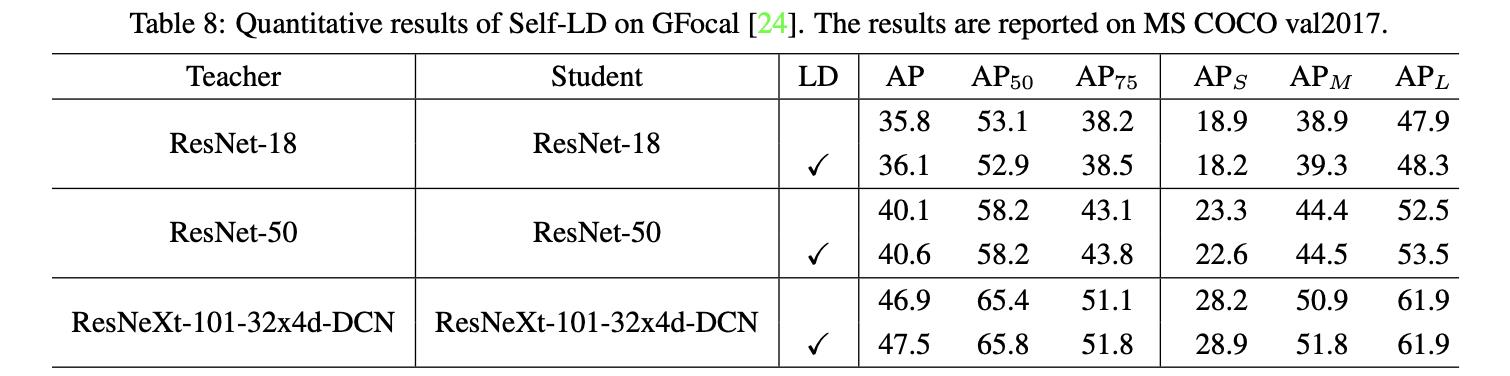
除了实现大小模型上的蒸馏,其实还可以使用自我蒸馏的方式。这样做的好处是可以得到更加稳定的蒸馏结果和更好的性能。在下面给出这方面的一些文章以方便理解:
REF1:微调预训练模型的新姿势——自集成和自蒸馏
Improving BERT Fine-Tuning via Self-Ensemble and Self-Distillation
该提出了两种自蒸馏的方式:Self-Distillation-Averaged(SDA)和Self-Distillation-Voted(SDV)。在SDA中,首先计算出过去K个time step参数的平均值作为Teacher Model。在SDV中,将过去K个time step的参数视为K个Teacher Model。SDA的目标函数计算方式如下:
L
θ
(
x
,
y
)
=
C
E
(
B
E
R
T
(
x
,
θ
)
,
y
)
+
λ
M
S
E
(
B
E
R
T
(
x
,
θ
)
,
B
E
R
T
(
x
,
θ
ˉ
)
)
L_\\theta(x,y)=CE(BERT(x,\\theta),y)+\\lambda MSE(BERT(x,\\theta),BERT(x,\\bar\\theta))
Lθ(x,y)=CE(BERT(x,θ),y)+λMSE(BERT(x,θ),BERT(x,θˉ))
其中,
θ
ˉ
=
1
k
∑
k
=
1
K
θ
t
−
k
\\bar\\theta=\\frac1k\\sum_k=1^K\\theta_t-k
θˉ=k1∑k=1Kθt−k。SDV的目标函数计算方式如下:
L
θ
(
x
,
y
)
=
C
E
(
B
E
R
T
(
x
,
θ
)
,
y
)
+
λ
M
S
E
(
B
E
R
T
(
x
,
θ
)
,
B
E
R
T
(
x
,
1
k
∑
k
=
1
K
B
E
R
T
(
x
,
θ
t
−
k
)
)
)
L_\\theta(x,y)=CE(BERT(x,\\theta),y)+\\lambda MSE(BERT(x,\\theta),BERT(x,\\frac1k\\sum_k=1^KBERT(x,\\theta_t-k)))
Lθ(x,y)=CE(BERT(x,θ),y)+λMSE(BERT(x,θ),BERT(x,k1k=1∑KBERT(x,θt−k)))
REF2:论文串烧:Self-Knowledge Distillation
论文列表:
- Self-Knowledge Distillation: A Simple Way for Better Generalization
- Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
增加了Self-LD与未增加的区别见下表所示:
3. 实验结果
以上是关于《LD:Localization Distillation for Object Detection》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章