百分点认知智能实验室:NLP模型开发平台在舆情分析中的设计和实践(下)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百分点认知智能实验室:NLP模型开发平台在舆情分析中的设计和实践(下)相关的知识,希望对你有一定的参考价值。
编者按
NLP模型开发平台是以快速打造智能业务为核心目标,无需机器学习专业知识,模型创建-数据上传-数据标注(智能标注、数据扩充)-模型训练-模型发布-模型校验全流程可视化便捷操作,短时间内即可获得高精度NLP模型,真正为业务赋能。
在北京百分点信息科技有限公司的NLP模型开发平台发布后,舆情分析业务中上线了超过200个个性化定制实时预测模型,依靠强大的资源调度和计算平台,每天都会有数十个模型在进行迭代更新和优化,真正实现全流程的数据和模型的闭环。本文主要介绍NLP模型开发平台的架构和实现细节,以及舆情业务中的应用,希望能为大家提供一些参考。
一、背景介绍
本文中重点介绍NLP模型开发平台在百分点舆情洞察系统(MediaForce)中的设计和实践。MediaForce是一款面向政企客户,提供信息监测、智能分析等多功能的一款SaaS产品。从2014年发展至今,客户标准化的建立以及数据资产的积累,为开展自动化和智能化打下了坚实基础。对内要提高生产和运营效率,缩短行为结果的反馈时间;对外要提供个性化服务,提高客户亲密度。舆情信息是通过关键词检索来获取对应的相关数据, 在基于BM25、TF-IDF等传统信息检索机制下,只是考虑关键词和文档的匹配程度,忽略了文档主题、查询理解、搜索意图等因素,致使召回文档与客户诉求相差较大。另一方面,在客户定制化场景下,需要人工对客户数据进行标签处理,这是一个极其费时费力的过程。
在一个NLP模型开发任务中,一般包括如下三个大模块: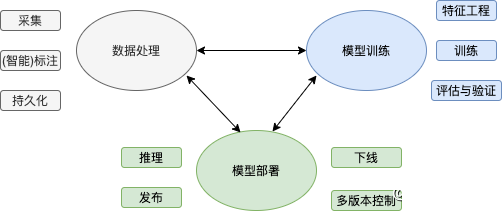
舆情分析的赋能者:NLP模型开发平台设计实践
在早期,主要是围绕和重复这三个模块来支持业务。在业务规模小时,人工方式保证了工作的灵活与创新突破,但是随着业务模式的成熟与增长,逐渐凸显出人工方式的局限性,主要体现在如下几个方面:
(1)NLP模型开发任务的增多,无疑增加开发人员的维护工作,尤其是在算法迭代更新、模型版本管理等方面,将是灾难性质的。
(2)业务人员是核心业务的把控者,但是由于模型学习门槛相对较高,使其参与度大大降低。
而NLP模型开发平台的构建不仅能解决以上问题,也更将聚焦算法工程师模型开发和基准验证,使分工更加明确、全民参与。集数据管理、模型全生命周期管理、计算资源和存储资源统一管理等特性,力求达到以下目标:
(1)复用性:通用算法集成、算法管理、避免重复造轮子。从脚本开发到可视化操作,专注于算法效果提升和模块复用。
(2)易用性:即便是运营(业务)人员,也可以定制私有业务模型,真正实现业务赋能。依据自己的个性化诉求可进行数据标注、模型训练、效果评估、模型发布等操作。
(3)扩展性:算力资源可扩展、模型算法框架(TF、Pytorch、H2o)可扩展、语言(Java、Python、R)可扩展。
二、NLP模型开发工具栈回顾
在传统软件开发中,我们需要对程序的行为进行硬编码,而在NLP机器学习模型开发中,我们将大量内容留给机器去学习数据,开发流程上有着本质的不同,如下图所示: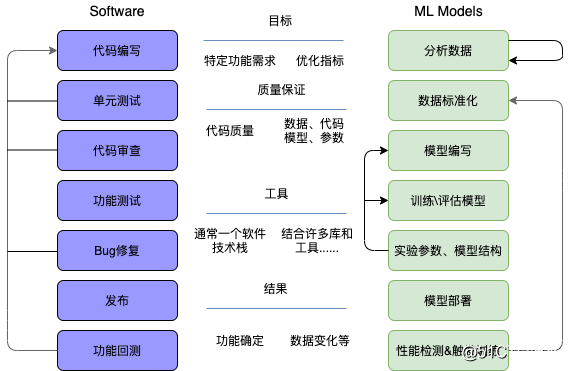
舆情分析的赋能者:NLP模型开发平台设计实践
许多传统软件工程工具可用于开发和服务于机器学习任务,但是由于机器学习的特殊性,也往往需要自己的工具。比如:Git通过逐行比较差异来进行版本控制,适用于大多数软件开发,但是不适合对数据集或模型检查点进行版本控制。在2012年随着深度学习的兴起,机器学习工具栈种类和数量爆炸式增长,包括All-in-one(一站式机器学习平台):Polyaxon、MLFlow等,Modeling&Training(模型开发、训练):PyTorch、Colab、JAX等,Serving(发布、监控、A/B Test):Seldon、Datatron等。下图表明MLOps每种类型的工具数目: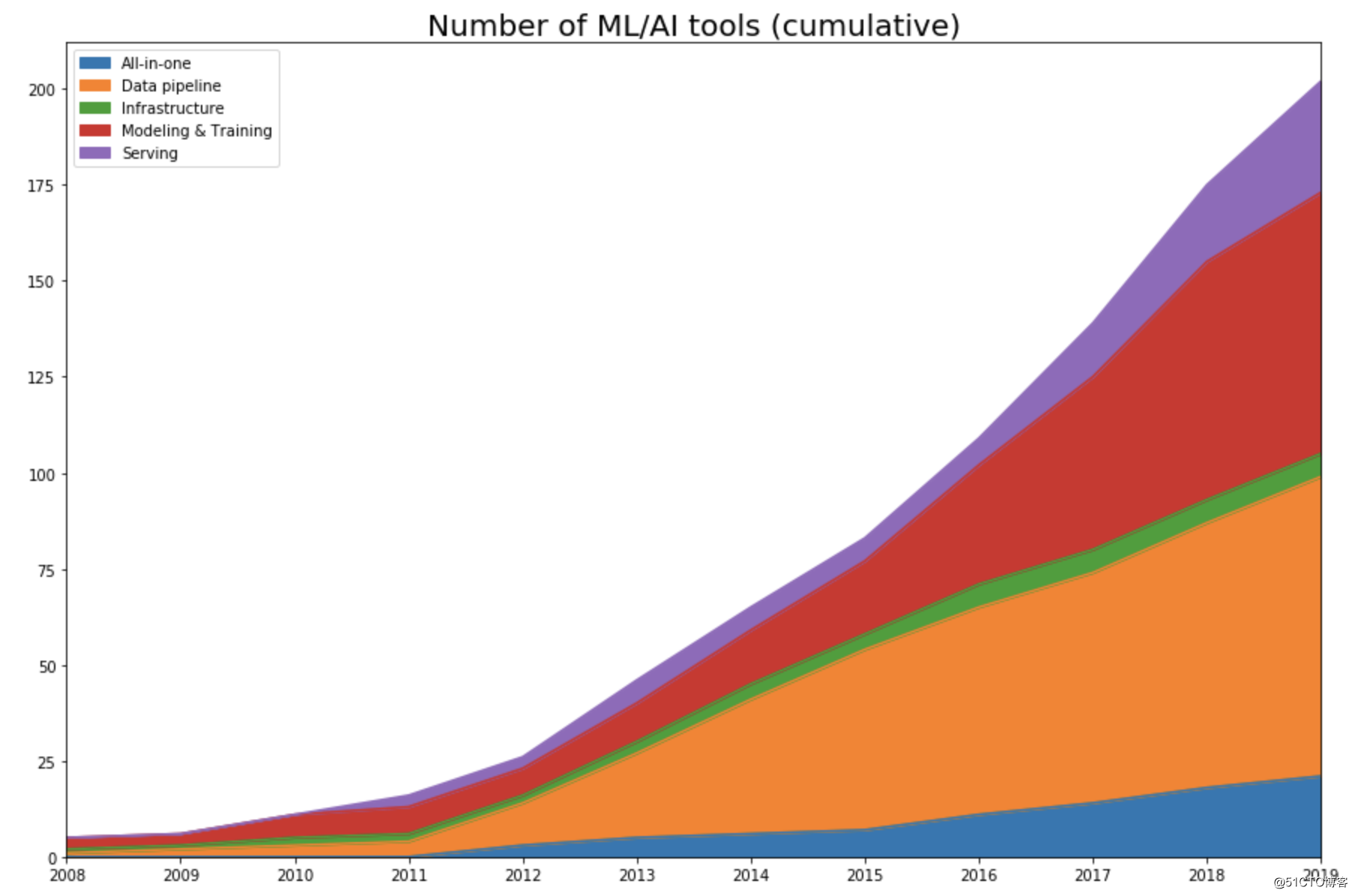
舆情分析的赋能者:NLP模型开发平台设计实践
对机器学习工具栈进行细化包括:标注、监控、版本管理、实验追踪、CI/CD等,详细内容不再赘述,详情参照下图: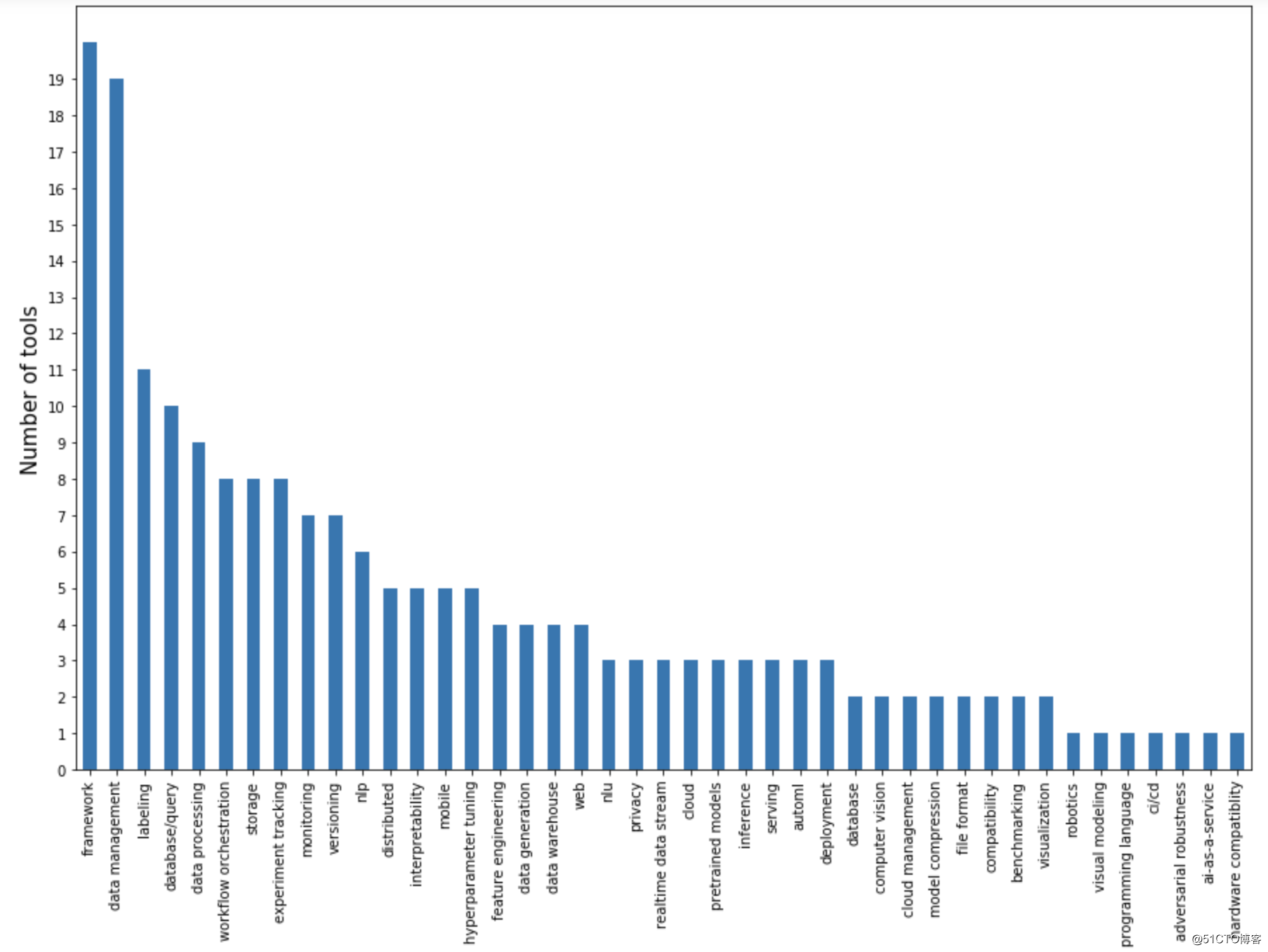
舆情分析的赋能者:NLP模型开发平台设计实践
可以看到机器学习工具栈种类和数量目前是极其繁多的,有些是面向OSS的,有些是商业收费的。下图主要举例在不同种类的工具栈上的产品: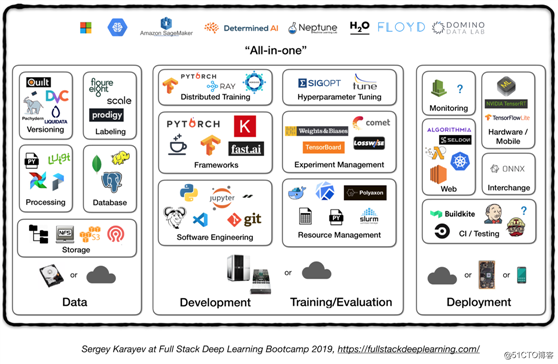
舆情分析的赋能者:NLP模型开发平台设计实践
三、NLP模型开发平台构建
- AI训练模型的基本流程简介

舆情分析的赋能者:NLP模型开发平台设计实践
(1)分析业务需求:在正式启动训练模型之前,需要有效分析和拆解业务需求,明确模型类型如何选择。
(2)采集、收集、预处理数据:尽可能采集与真实业务场景一致的数据,并覆盖可能有的各种数据情况。
(3)标注数据 :按照规则定义进行数据标签处理。如果是一些分类标签,可以在线下直接标注;如果是一些实体标注、关系标注就需要对应一套在线标注工具进行高效处理。
(4)训练模型:训练模型阶段可以将已有标注好的数据基于已经确定的初步模型类型,选择算法进行训练。
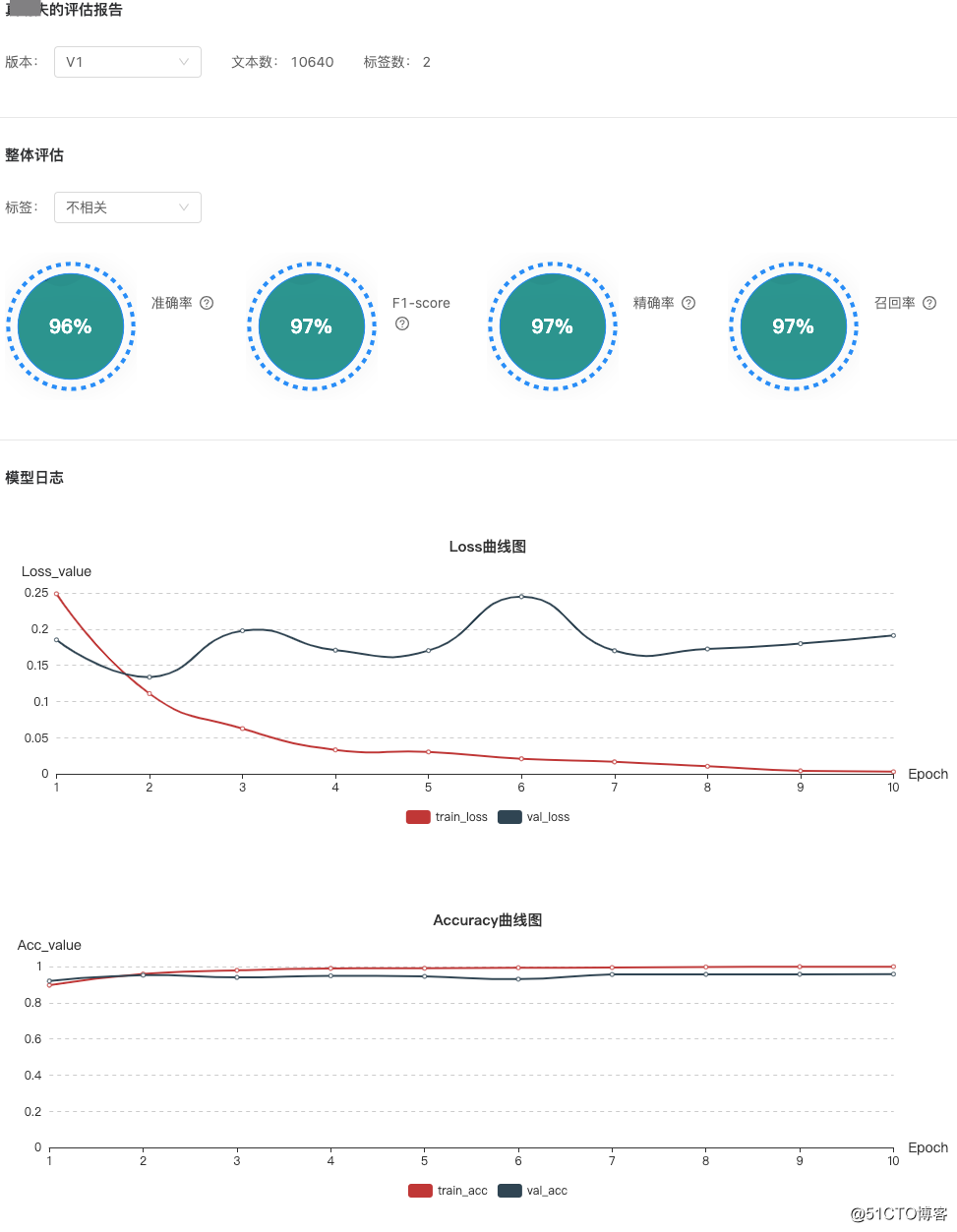
(5)效果评估:训练后的模型在正式集成之前,需要评估模型效果是否可用。需要详细的模型评估报告,以及在线可视化上传数据进行模型效果评估,并且在灰度环境进行业务验证。
(6)模型部署:当确认模型效果可用后,可以将模型部署至生产环境中。同时要支持多版本管理、AutoScale等功能。
- 整体架构
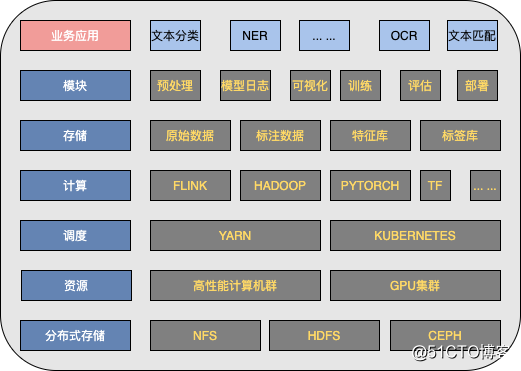
舆情分析的赋能者:NLP模型开发平台设计实践
(1)分布式存储包括NFS、HDFS、CEPH。HDFS是存储原始数据以及样本特征,NFS是存储训练后的模型文件,CEPH是K8S集群的文件分布式存储系统。
(2)底层计算资源分为CPU集群和GPU集群,高性能CPU集群主要用于部署和训练传统的机器学习模型,GPU集群则用来部署和训练深度(迁移)学习模型。
(3)资源不同,计算的选型也有差别。机器学习训练使用 Alink 做计算,通过 Yarn 来调度计算资源;深度学习训练使用 K8S 做调度,支持主流的 Pytorch、Tensorflow、PaddlePaddle、H2o等深度学习框架,目前只是做到单机训练,而模型的部署都是借助K8S进行统一发布和管理。
模块对外提供数据标注、模型训练、模型评估、模型管理、模型部署、模型预测等功能,同时平台还抽象出分类、NER、评估、预测等组件。
- 平台构建实践
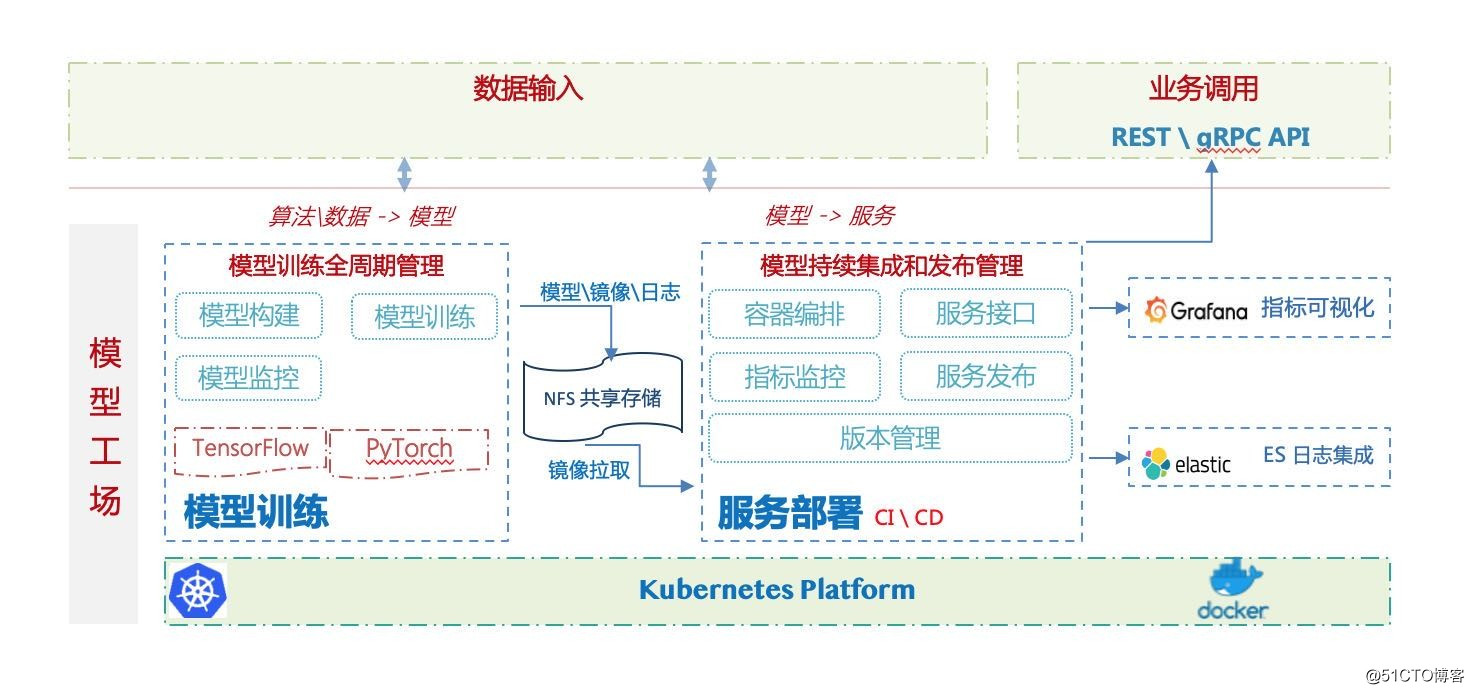
舆情分析的赋能者:NLP模型开发平台设计实践
平台上层提供了一套标准的可视化操作界面,供业务运营人员使用,平台底层提供全生命周期的模型管理,支持上层应用扩展。
上文主要介绍NLP模型开发平台构建的基本流程和整体架构 ,本章节会对技术选型与实践进行展开。
(1)容器管理调度平台选型
主流的容器管理调度平台有三个,分别是Docker Swarm、Mesos Marathon和Kubernetes。但是同时具备调度、亲和/反亲和、健康检查、容错、可扩展、服务发现、滚动升级等诸多特性,非Kubernetes莫属。同时基于OSS的机器学习工具栈大多也都是基于Kubernetes而进行的上层开发和应用,像我们熟知的Kubeflow等。另一方面深度学习领域通常是用GPU来做计算的,而Kubernetes对GPU卡的调度和资源分配有很好的支持和扩展。比如现在集群有多种类型的GPU卡,可以对GPU节点打上label,启动任务配置nodeSelector实现卡类型的精准分配。最终我们选择用 K8S 作为平台的容器管理系统。
(2)GPU资源调度管理
目前较新版本的docker是支持 NVIDIA GPU的runtime,而不再考虑旧版的nvidia-docker或者nvidia-docker2。其实在runtime基础上,是可以直接使用GPU来执行深度学习任务的,但是却无法限定GPU资源以及异构设备的支持。这里主要给出两种解决方案:
a. Device Plugin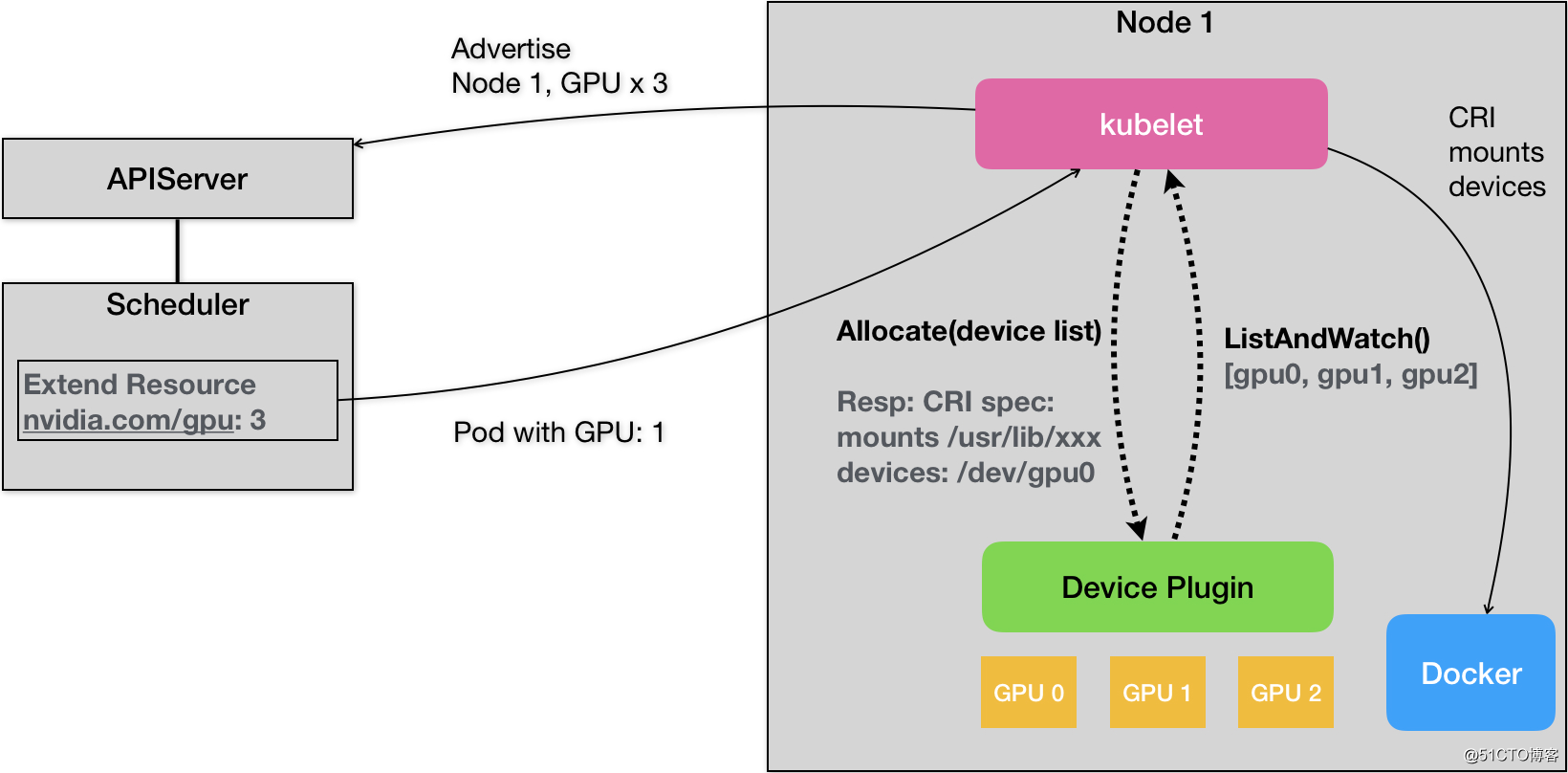
舆情分析的赋能者:NLP模型开发平台设计实践
为了能够在Kubernetes中管理和调度GPU, Nvidia提供了Nvidia GPU的Device Plugin。主要功能如下:
支持ListAndWatch 接口,上报节点上的GPU数量。
支持Allocate接口,支持分配GPU的行为。
但是这种机制导致GPU卡都是独享的。特别是在推理阶段,利用率是很低的。这也是我们采用第二种方式的主要原因。
b. GPU Sharing
GPU Device Plugin可以实现更好的隔离,确保每个应用程序的GPU使用率不受其他应用程序的影响。它非常适合深度学习模型训练场景,但是如果场景是模型开发和模型推断,会造成资源浪费。所以要允许用户表达共享资源的请求,并保证在计划级别不会超额订购GPU。我们这里尝试Aliyun在GPU Sharing上的开源实现,如下图所示: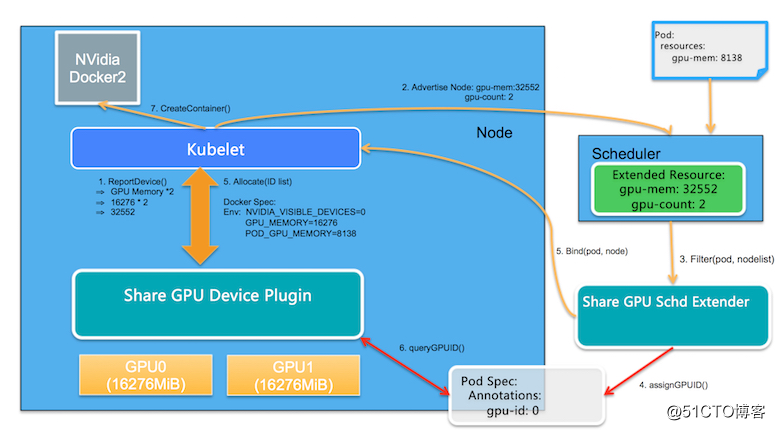
在配置文件中,限定显存大小,这里的单位是GiB:
舆情分析的赋能者:NLP模型开发平台设计实践
舆情分析的赋能者:NLP模型开发平台设计实践
执行如下命令:
舆情分析的赋能者:NLP模型开发平台设计实践
在11GiB的显卡上,GPU分配状况如下: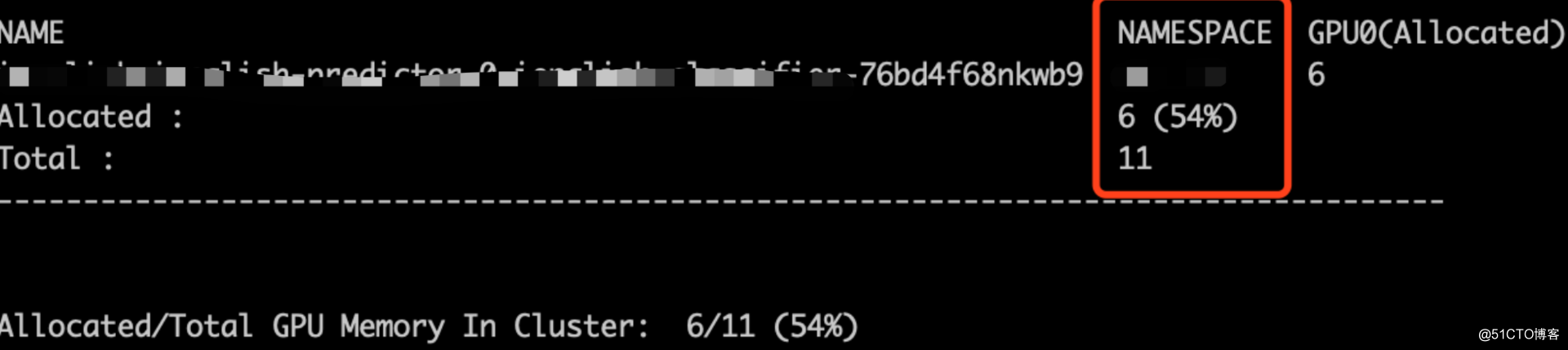
舆情分析的赋能者:NLP模型开发平台设计实践
(3)网关选型
在使用Kubernetes的Service时,一个必须要面对和解决问题是:如何从外部(kubernetes 集群之外),访问到Kuberentes里创建的Service?这里最常用的一种方式就是NodePort。它允许你使用任何一台宿主机IP进行访问。这种方式需要事先指明nodePort或者随机生成nodePort,对接口资源较难管理。而使用像Kong、nginx、HAProxy等主流网关所面临的问题是:不是自服务的、不是Kubernetes原生的、为Api管理而设计,而非微服务。Istio 是微服务的服务网格,旨在将应用层(L7)的可观察性、路由和弹性加入到从服务到服务的流量中。而模型部署需要与Kubernetes深度融合,也不需要进行服务间的调用,最后选用Ambassador作为最后网关选型。Ambassador作为一个较新推出的开源微服务网关产品,与kubernetes结合得相当好,基于annotation或CRD的配置方式与K8S浑然一体,真正做到了kubernetes native。下面给出一个实际中的一个例子:
舆情分析的赋能者:NLP模型开发平台设计实践
其中 timeout_ms 默认值为3000,在使用Cpu做推理设备时,可能会出现超时的情况,这里依据不同的场景对该值进行微调,以满足使用。同时可以从Route Table中查看相应的URL。
(4)可视化
这里的可视化是指在进行模型训练过程中,需要对模型性能进行评测和调优。这里率先融入Tensorboard,随后也将百度的VisualDl融入进去。在训练过程中启动一个单独的容器,暴露出接口供开发者查阅和分析。
(5)模型部署
在第二章节中,介绍了不同功能的机器学习工具栈。在模型部署中我们使用Seldon Core来作为CD工具,同时Seldon Core也被Kubeflow深度集成。Seldon 是一个可在Kubernetes上大规模部署机器学习模型的开源平台,将ML模型(Tensorflow,Pytorch,H2o等)或语言包装器(Python,Java等)转换为生产 REST / GRPC 等微服务。
下面是推理镜像的构建过程,其中MyModel.py是预测文件: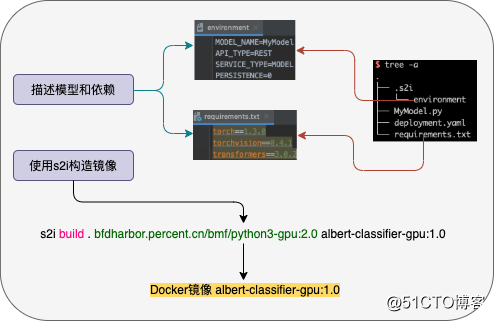
舆情分析的赋能者:NLP模型开发平台设计实践
其中部分 deployments 描述文件如下:
舆情分析的赋能者:NLP模型开发平台设计实践
四、平台应用和成效
NLP模型开发平台的构建极大地降低模型学习门槛,使业务人员不仅可以参与规则的制定,也可以参与到数据标注、服务发布、效果评估等多个阶段。同时使数据科学家和机器学习工程师能更加专注于模型本身的算法和性能,极大地提高工作效率、简化工作流程。下面举例借助平台在数据相关度、标签处理等方面的成效。
- 相关度
在过去几十年中,已经实现了各种自动信息检索系统。文档的有效表示是能够检索文档的核心,像矢量空间模型和概率模型都依赖于TF、IDF、文档长度等特征因素。将文档从文本转换为数字或基于矢量的表示形式,排序功能就需要根据特定的查询的相关性对文档进行排序。其中Okapi BM25是IR中最著名和使用最广泛的排序算法。传统信息检索方法没有考虑语义信息等诸多因素。而随后的Bert在GLUE中IR相关的基准测试达到最优,其中一部分原因是因为其大量的训练数据。此外基于Transformer神经网络架构促进了输入中各个token之间的深层关系,从而使模型可以更好地了解输入中存在的关系。在真正应用中,需要考虑查询意图、查询改写、同义词扩展等诸多技巧。下面将阐述在提高检索相关度方面的尝试和方案的演进,以及NLP模型开发平台在这方面的成效和应用。
(1)基于查询意图的传统信息检索
舆情中的搜索往往是词或短语,在缺少外部知识的情况下,搜索意图往往无法得知。在使用Okapi BM25传统的信息检索方式,只能得到查询关键词与文档相关,而并不符合搜索意图。在当时的架构下,主要是基于Elasticsearch的全文检索,以便考虑能否使用ES得出一个比较通用的处理框架。Elasticsearch是基于Luence的架构。很多要素都是一脉相承的,例如文档和字段的概念、相关性的模型、各种模式的查询等。流程如下图所示: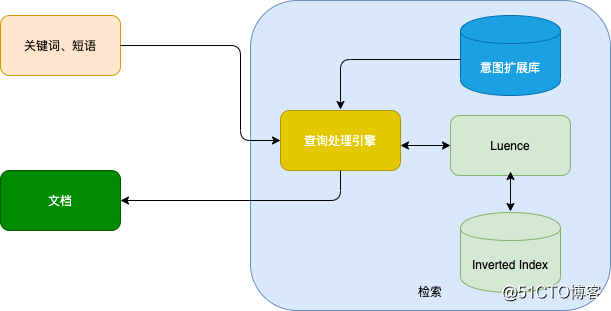
舆情分析的赋能者:NLP模型开发平台设计实践
这里的意图扩展库其实是对查询关键词进行扩展,例如,关键词为"真功夫",如果你的搜索意图指的是餐饮品牌“真功夫”,那么可以扩展一系列行业相关词:餐饮、门店、优惠券等。联合Query一起查询,这里的意图扩展库(扩展相关词)只是贡献权重得分,而不作为检索过滤条件,使用ES中should语句即可实现。这种机制在一定程度上缓解了数据相关度问题,特别是在垂直领域中,效果甚佳。而一旦涉及跨领域、搜索意图宽泛,就显得无能为力。
(2)基于Bert分类模型应用
在以上的实现机制中,都是无监督排序算法的典范,这样的排序算法并不是最优的。在极度简化的情况下,如果标签定义为,某个文档针对某个关键字是否相关,也就是二分标签,训练排序算法的问题就转换成了二分分类(Binary Classification)的问题。这样,任何现成的二分分类器,几乎都可以在不加更改的情况下直接用于训练排序算法,比如经典的“对数几率”分类器或者支持向量机都是很好的选择。这类算法称之为“单点法排序学习”(Pointwise Learning to Rank)。这种机制与我们的应用场景十分吻合,只不过将Query上升为话题维度。而像DSSM等经典的文本匹配算法解决的是查询串与文档的匹配程度,查询串往往是句子,而不是词语。因此我们将相关度问题转化为二分分类问题,召回阶段使用Elastcsearch索引库检索,排序阶段使用分类器对召回的文档进行判定。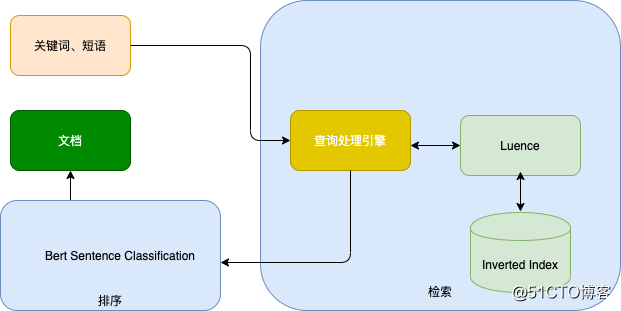
舆情分析的赋能者:NLP模型开发平台设计实践
在这种机制下,为客户提供了个性化服务。在NLP模型开发平台的助力下,进行一站式处理,并且可以实现版本的迭代优化。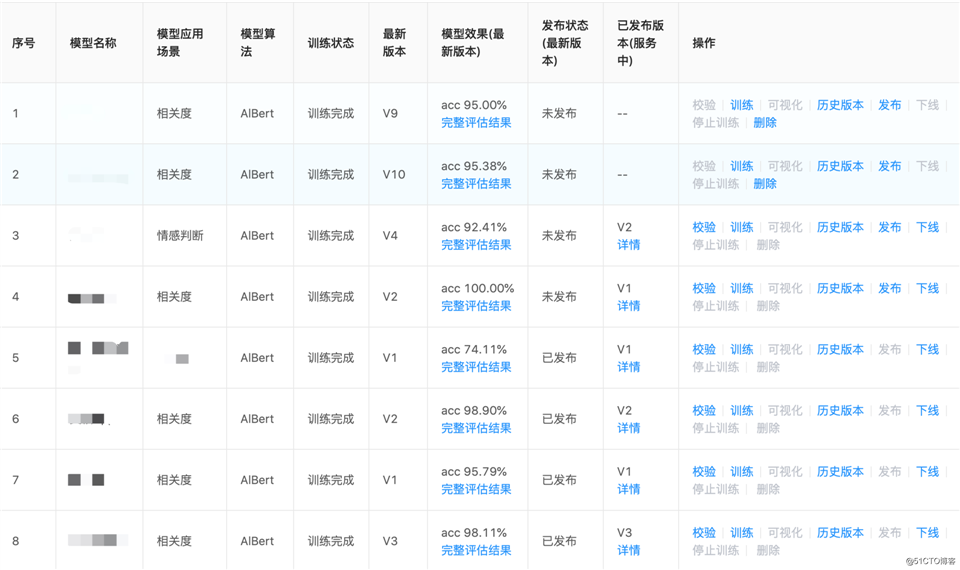
舆情分析的赋能者:NLP模型开发平台设计实践
舆情分析的赋能者:NLP模型开发平台设计实践
- 离线标签
在一些定制化场景下,需要对离线数据进行标签化处理。这是一个费时费力的过程,并且之前的劳动无法为后续的工作赋能。我们通过标注模块对已有数据进行整合,并且对新标签的样本数据进行标注,从而快速为业务赋能,解放生产力。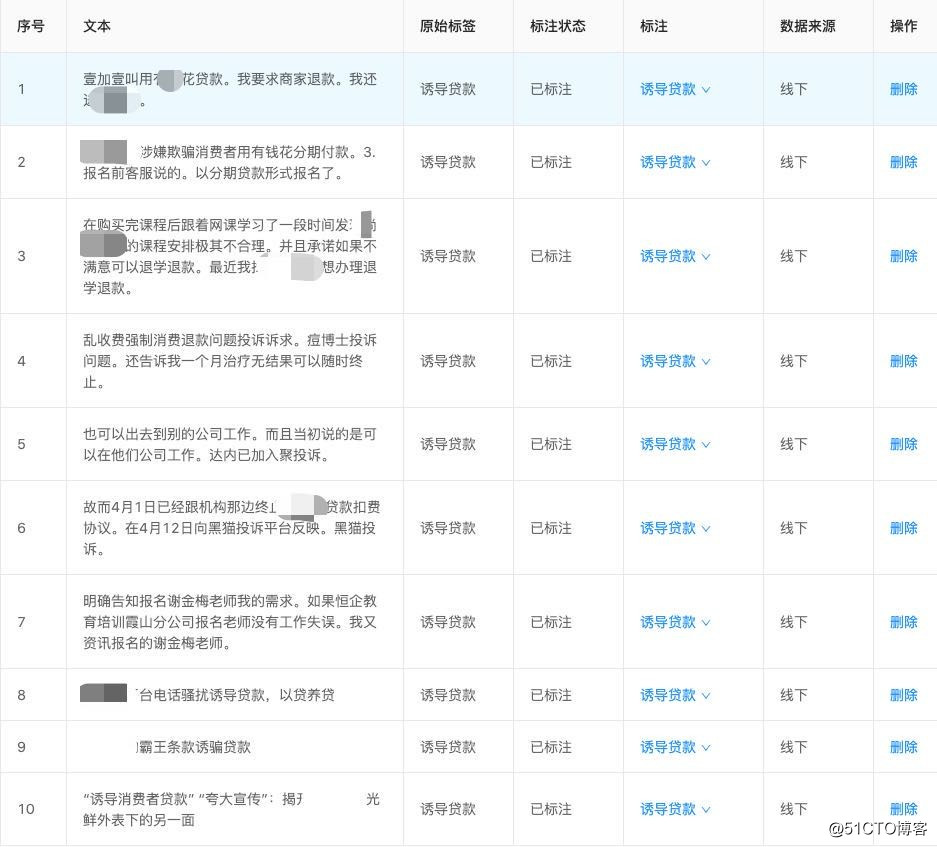
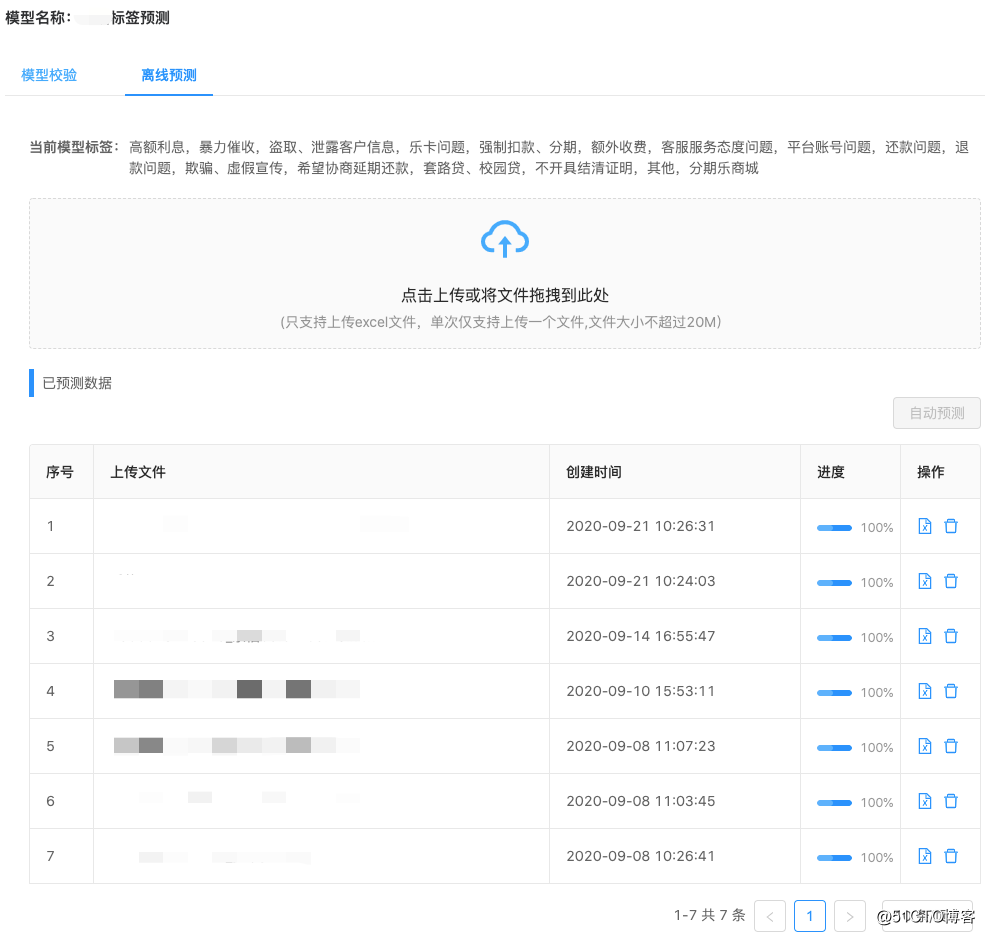
舆情分析的赋能者:NLP模型开发平台设计实践
舆情分析的赋能者:NLP模型开发平台设计实践
以及在实体识别的场景下,可以直接在标注模块进行标注: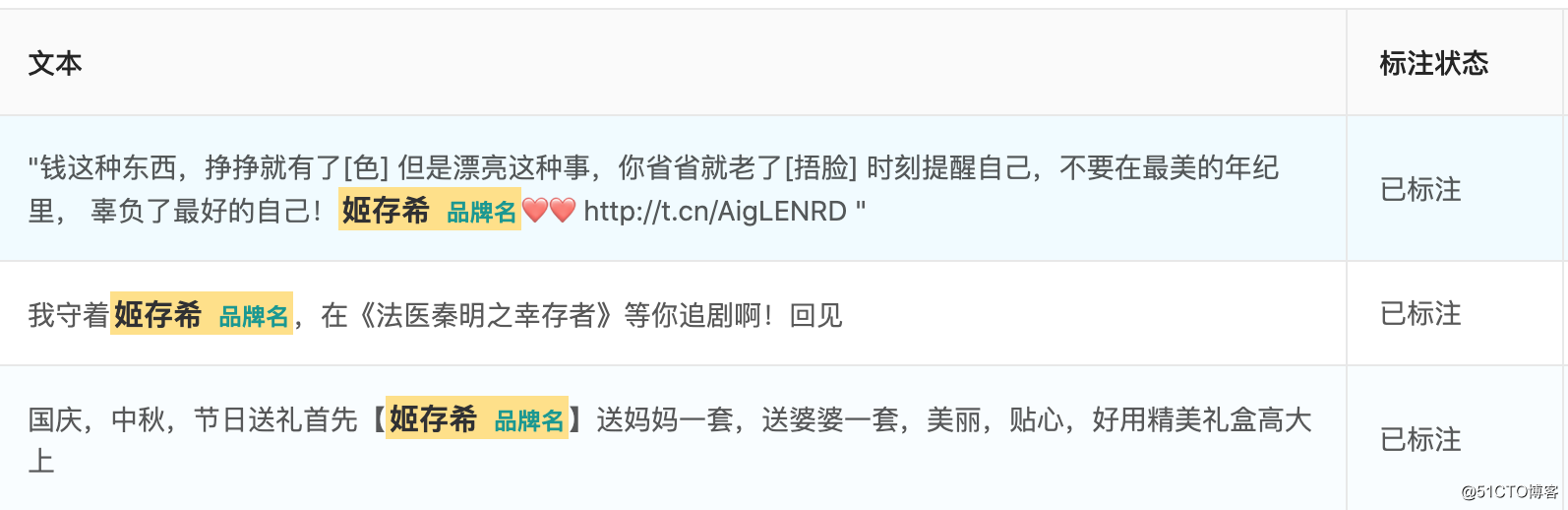
舆情分析的赋能者:NLP模型开发平台设计实践
五、平台展望
- 标注功能完善
在文本分类、NER等基础标注任务的基础上,还需要增加关系标注、seq2seq等主流任务的支持,以及任务分配、多人协作等特性。
- 丰富算法模块
在满足基础需求下,还需要增加文本匹配等算法模块,满足更加广泛的应用场景。
- 打造Piplines流水线式NLP模型开发平台
模型训练以及模型评估目前是耦合的,不利于组件模块复用,所以要按照细粒度的模块进行独立拆分,再按照 Pipline方式自由组合,来达到最大利用率。
参考资料:
[1]https://huyenchip.com/2020/06/22/mlops.html
[2]https://github.com/AliyunContainerService/gpushare-scheduler-extender
[3]https://docs.seldon.io/projects/seldon-core/en/latest/
以上是关于百分点认知智能实验室:NLP模型开发平台在舆情分析中的设计和实践(下)的主要内容,如果未能解决你的问题,请参考以下文章