NLP实操手册: 基于Transformer的深度学习架构的应用指南(综述)
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP实操手册: 基于Transformer的深度学习架构的应用指南(综述)相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :翻译来自:百分点认知智能实验室 易显维 桂安春
论文:The NLP Cookbook: Modern Recipes for Transformer based Deep Learning Architectures
编辑:zenRRan(深度学习自然语言处理公众号)
摘要
近年来,自然语言处理(Natural Language Processing, NLP)模型在文本分类、机器翻译、认知对话系统、自然语言理解(Natural Language Understanding, NLU)信息检索和自然语言生成(Natural Language Generation, NLG)等语言和语义任务中取得了显著的成功。这一壮举主要归功于开创性的Transformer架构,导致了诸如BERT、GPT (I、II、III)等设计。尽管这些大尺寸模型取得了前所未有的性能,但它们的计算成本很高。因此,一些最近的NLP架构已经使用了迁移学习、剪枝、量化和知识蒸馏的概念来实现适度的模型规模,同时保持与前人取得的性能几乎相似。此外,为了从知识抽取的角度缓解语言模型带来的数据量挑战,知识检索器已经被构建,以更高的效率和准确性从大型数据库语料库中提取显式数据文档。最近的研究也集中在通过对较长的输入序列提供有效注意的高级推理上。在本文中,我们总结并检验了目前最先进的(SOTA) NLP模型,这些模型已被用于许多NLP任务,以获得最佳的性能和效率。我们提供了对不同体系结构的详细理解和功能、NLP设计的分类、比较评估和NLP的未来发展方向。
关键词:深度学习,自然语言处理,自然语言理解,自然语言生成,信息检索,知识提炼,剪枝,量化
I.导言
自然语言处理(NLP)是机器学习的一个领域,处理建立和发展语言模型的语言学。语言建模(LM)通过概率和统计技术确定单词序列在句子中出现的可能性。由于人类语言涉及单词序列,最初的语言模型是基于循环神经网络(RNNs)。由于rnn会导致长序列的消失和爆炸梯度,因此改进的循环网络(如lstm和gru)被用来提高性能。尽管lstm有增强作用,但研究发现,当涉及相对较长的序列时,lstm缺乏理解。这是由于称为上下文的整个历史是由单个状态向量处理的。然而,更大的计算资源导致新的架构的涌入,导致基于深度学习[1]的NLP模型迅速崛起。
2017年,突破性的Transformer[2]架构通过注意力机制克服了LSTM的上下文限制。此外,它提供了更大的吞吐量,因为输入是并行处理的,没有顺序依赖关系。随后在2018年推出的基于改进的Transformer模型,如GPT-I[3]和BERT[4],成为了NLP世界的转折点。这些架构是在大型数据集上训练的,以创建预训练模型。随后,迁移学习被用于针对特定任务特征的微调这些模型,从而显著提高了几个NLP任务[5],[6],[7],[8],[9],[10]的性能。这些任务包括但不限于语言建模、情感分析、问答和自然语言推理。
这一成就未能实现迁移学习的主要目标,即用最小的微调样本实现高模型精度。此外,模型性能需要跨多个数据集通用,而不是特定于任务或数据集的[11]、[12]、[13]。然而,由于越来越多的数据被用于训练前和微调目的,高泛化和迁移学习的目标受到了影响。这使得是否应该合并更多的训练数据或改进的体系结构来构建更好的SOTA语言模型的决定变得模糊。例如,随后的XLNet[14]体系结构拥有新颖而复杂的语言建模,这比仅用XLNet数据的10% (113GB)进行训练的简单BERT体系结构提供了微小的改进。之后,通过引入RoBERTa[15],一个大型的基于BERT的模型训练了比BERT (160GB)更多的数据,表现优于XLNet。因此,一个更一般化的体系结构,并在更大的数据上进行进一步训练,就会产生NLP基准测试。
上述架构主要是语言理解模型,其中自然方言被映射到正式解释。这里的初始目标是将输入用户的话语翻译成传统的短语表示。对于自然语言理解(NLU),上述模型的最终目标的中间表示由下游任务决定。
与此同时,对于NLU模型中的特定任务角色来说,微调逐渐成为一种挑战,因为它需要更大的样本容量来学习特定的任务,这使得这种模型从泛化[16]中失去了。这引发了自然语言生成(NLG)模型的出现,与NLU训练相反,它从相应的被掩盖或损坏的输入语义中学习生成方言话语。这种模型与常规的粗略语言理解的下游方法不同,对于序列到序列的生成任务(如语言翻译)是最优的。T5[17]、BART[18]、mBART[19]、T-NLG[20]等模型在大量的损坏文本语料上进行预训练,并通过去噪目标[21]生成相应的净化文本。这种转换很有用,因为NLU任务的额外微调层对于NLG来说并不需要。这进一步提高了预测能力,通过零或几次射击学习(one-shot learning),使序列生成与最小或没有微调。例如,如果一个模型的语义嵌入空间预先训练了动物识别“猫”、“狮子”和“黑猩猩”,它仍然可以正确预测“狗”,而无需微调。尽管NLG具有优越的序列生成能力,但随着GPT-III[22]的后续发布,NLG的模型规模呈指数级增长,这是GShard[23]发布之前最大的模型。
由于NLU和NLG的超大型模型需要加载几个gpu,这在大多数实际情况下变得昂贵和资源限制。此外,当在GPU集群上训练几天或几周时,这些巨大的模型需要耗费大量的能量。为了减少计算成本[24],我们引入了基于知识蒸馏(KD)[25]的模型,如蒸馏BERT[26]、TinyBERT[27]、MobileBERT[28],并降低了推理成本和规模。这些较小的学生模型(student model)利用较大的教师模型(teacher model,如:BERT)的归纳偏见来实现更快的培训时间。类似地,剪枝和量化[29]技术在建立经济规模模型方面得到了广泛的应用。剪枝可以分为3类:权重剪枝、层剪枝和头部剪枝,即将其中某些最小贡献的权重、层和注意头从模型中删除。像剪枝一样,训练感知的量化被执行以实现不到32位的精度格式,从而减少模型的大小。
为了获得更高的性能,需要更多的学习,这将导致更大的数据存储和模型大小。由于模型的庞大和隐性知识存储,其学习能力在有效获取信息方面存在缺陷。当前的知识检索模型,如ORQA[30]、REALM[31]、RAG[32]、DPR[33],通过提供对可解释模块知识的外部访问,试图减轻语言模型的隐式存储问题。这是通过用“知识检索器”来补充语言模型的预训练来实现的,它有助于模型从像维基百科这样的大型语料库中有效地检索和参与明确的目标文档。
此外,Transformer模型无法处理超出固定标记范围的输入序列,这限制了它们从整体上理解大型文本主体。当相关单词的间隔大于输入长度时,这一点尤其明显。因此,为了增强对语境的理解,我们引入了Transformer-XL[34]、Longformer[35]、ETC[36]、Big Bird[37]等架构,并修改了注意机制,以处理更长的序列。
此外,由于对NLP模型的需求激增,以实现经济上的可行性和随时可用的边缘设备,创新的压缩模型推出了基于通用技术。这些是前面描述的蒸馏、修剪和量化技术之外的技术。这些模型部署了广泛的计算优化程序,从散列[38]、稀疏注意[39]、因式嵌入参数化[40]、替换标记检测[41]、层间参数共享[42],或上述的组合。
II. 相关综述/分类
我们提出了一种新的基于NLP的分类法,从六个不同的角度对当前的NLP模型进行了独特的分类:
(一)NLU模型:NLU善于分类,结构化预测或查询生成任务。这是通过由下游任务驱动的预培训和微调来完成的。
(二)NLG模型:与NLU模型不同,NLG模型在顺序生成任务中表现突出。他们通过少量的、一次性的学习,从相应的错误话语中生成干净的文本。
(三)减少模型尺寸:采用KD、剪枝、量化等基于压缩的技术,使大型模型更经济实用。它对于在边缘设备上操作的大型语言模型的实时部署很有用。
(四)信息检索(Information Retrieval, IR):上下文开放域问答(Contextual open domain question answer, QA)依赖于有效、高效的文档检索。因此,IR系统通过优越的词汇和语义提取物理来自大型文本语料库的文档在QA领域中创建SOTA,其性能优于当代语言模型。
(五)长序列模型:基于注意力的Transformers模型的计算复杂度与输入长度成二次关系,因此通常固定为512个tokens。这对于受益于较小输入长度[43]的共引用解析任务来说是可以接受的,但是对于需要跨多个冗长文档(例如HotpotQA数据集[44])进行推理的问答(QA)任务来说是不够的。
(六)有效率的计算架构:为了减少大型语言模型的高训练时间,我们构建了精度与大型语言模型相当的内存效率架构。
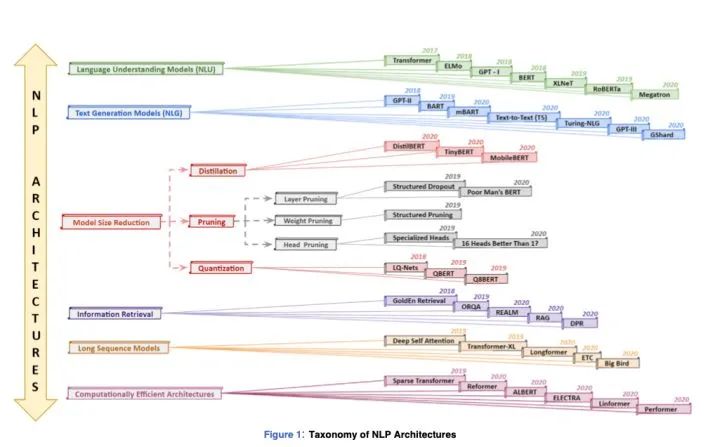
上述分类是一种广义分类,而不是硬分类,一些模型可以互换使用,可能有双重目的,但有明确的划分,尽管不具有普遍性。图1描述了这种分类法,给出了属于不同类别的重要模型及其发布年份的可视化分类。
III.现代NLP体系结构的雏形
传统的RNN编码器-解码器模型[45]由两个递归神经网络(RNN)组成,其中一个生成输入序列的编码版本,另一个生成其解码版本到一个不同的序列。为了使输入序列的目标条件概率最大化,该模型与以下语言建模联合训练:
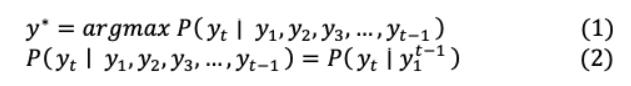
通过在机器翻译、序列到序列映射或文本摘要任务中实现相位对的条件概率,这种系统得到了优于普通rnn、lstm[46]或gru[47]的结果。
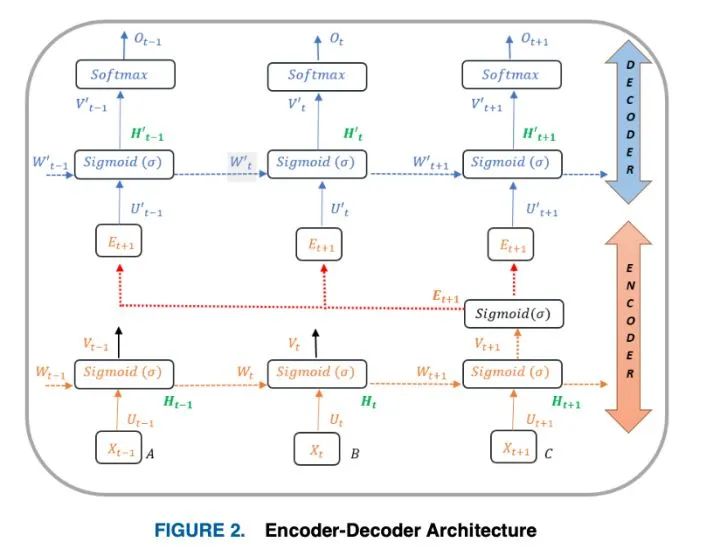
在上述架构(图2)中,编码器的最后一层 +1从其最终隐藏的 +1层向解码器传输信息,该层包含了通过概率分布对之前所有单词的整个上下文理解。
所有单词的组合抽象表示被输入到解码器,以计算所需的基于语言的任务。
就像它的前一层一样,最后一层是相应的可学习参数为 +1和 +1在输入和输出分别在编码器和 ' +1, ' +1在解码器。结合隐含状态和偏差的权重矩阵,可以用数学表示为:

此后,在2014-15年注意力[48],[49]的导入克服了RNN编码器-解码器的限制,即先前的输入依赖,使其难以推断更长的序列,并遭受消失和爆炸梯度[50]。注意机制通过最后一个Encoder节点禁用整个输入上下文来消除RNN依赖关系。它单独权衡提供给解码器的所有输入,以创建目标序列。这导致了更大的上下文理解,也导致更好的预测目标序列的生成。首先,对齐决定了 th输入和 th输出之间的匹配程度,可以将其确定为

更准确地说,对齐得分以所有编码器输出状态和之前解码的隐藏状态为输入,表示为:
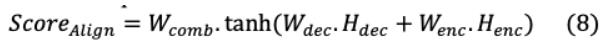
解码器的隐藏状态和编码器输出通过它们各自的线性层及其可训练权值传递。每个编码的隐藏表示h 的权重 计算为

这一注意机制中产生的上下文向量由以下因素决定:
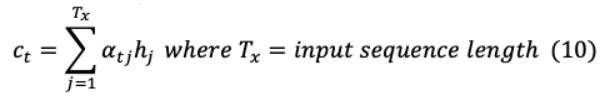
注意机制本质上是根据不同位置的对齐分数计算出上下文向量的生成,如图3所示。Luong的注意机制在对齐得分计算方面与上述的Bahdanau不同。它同时使用全局和局部注意,其中全局注意使用所有编码器输出状态,而局部注意关注单词的一个小子集。这有助于实现较长的序列的高级翻译。这些注意力设计导致了现代Transformer架构的开发,该架构使用了一种增强的注意力机制,如下一节所述。
IV.NLU架构
NLU的神经语言表征传输方法表明,与从头学习[51],[52]相比,预训练的嵌入可以改善下游任务的结果。随后的研究工作加强了学习,以捕获上下文化的单词表示,并将它们转移到神经模型[53],[54]。最近的努力不仅限于[55]、[56]和[57],通过为下游任务添加端到端语言模型微调,以及提取上下文单词表示,进一步构建了这些思想。这种工程进展,加上大量计算的可用性,使得NLU的最先进的方法从转移词嵌入到转移整个数十亿参数语言模型,在NLP任务中取得了前所未有的成果。现代NLU模型利用Transformer进行建模任务,并根据需求专门使用基于编码器或解码器的方法。这样的模型将在下一节中进行生动的解释。
IV-A TRANSFORMERS
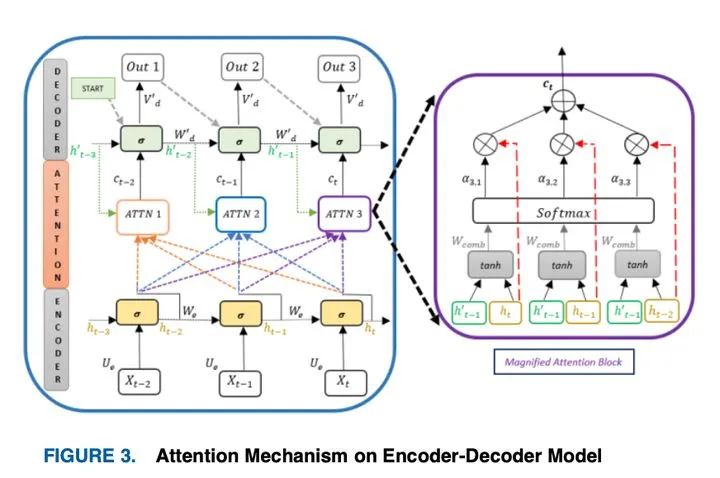
IV-A.1. The Architecture
最初的Transformer是一个6层的编码器-解码器模型,它通过编码器从源序列中通过解码器生成目标序列。编码器和解码器在较高的层次上由自注意层和前馈层组成。在Decoder中,中间的额外关注层使其能够将相关标记映射到Encoder,以实现转换目的。“自我注意”可以在不同的位置查找剩余的输入单词,以确定当前处理的单词的相关性。这是为所有输入的单词执行的,这有助于实现一个高级编码和上下文理解所有单词。在RNN和LSTM的顺序数据中,输入标记被即时输入,并通过编码器同时生成相应的嵌入,构建了Transformer架构来引入并行性。这种嵌入将一个单词(标记)映射到一个可以实时预训练的向量,或者为了节省时间,实现了一个类似GloVe的预训练嵌入空间。但是,不同序列中的类似标记可能有不同的解释,这些解释通过一个位置编码器来解决,该编码器生成关于其位置的基于上下文的单词信息。然后,将增强的上下文表示反馈给注意层,注意层通过生成注意向量来进一步语境化,注意向量决定了 h单词在一个与其他单词相关的序列中的相关性。然后这些注意向量被输入前馈神经网络,在那里它们被转换成更容易理解的形式,用于下一个“编码器”或解码器的“编码器-解码器注意”块。
后者与编码器输出和解码器输入嵌入,执行注意两者之间。当解码器在源和目标映射之间建立实际的向量表示时,这将确定Transformer的输入标记与其目标标记的相关性。解码器通过softmax预测下一个单词,softmax在多个时间步长内执行,直到生成句子标记的末尾。在每个Transformer层,有剩余连接,然后进行层归一化[58]步,以加快反向传播过程中的训练。图4展示了所有Transformer体系结构的细节。
IV-A.2. Queries, Keys, and Values
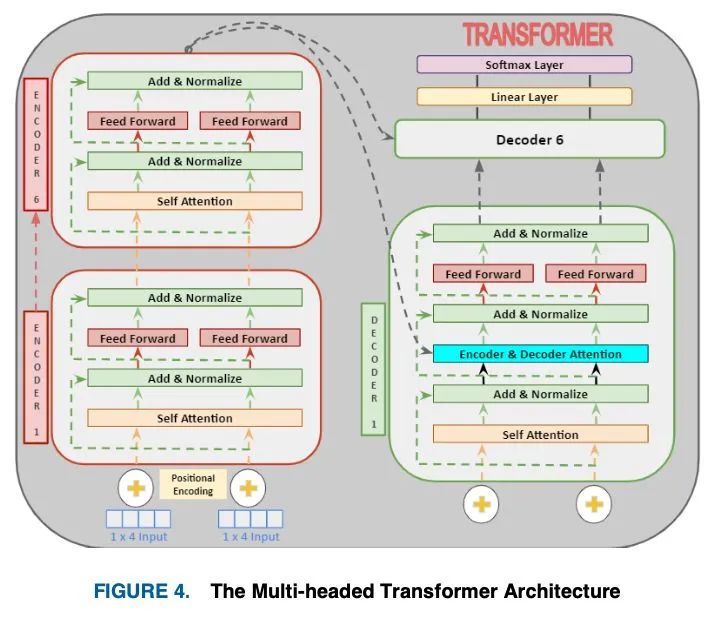
Transformer的注意机制的输入是目标tokens查询向量 ,其对应的源tokens密钥向量 和值 ,它们都是嵌入矩阵。在机器翻译中,源标记和目标标记的映射可以通过内点积来量化每个标记在序列中的相似程度。因此,要实现准确的翻译,关键字应与其对应的查询,通过两者之间的高点积值。假设 ⋵{ , }和 ⋵{ , },其中 , 表示目标长度和源长度, 表示单词嵌入维度。Softmax的实现是为了实现一个概率分布,其中所有查询,密钥相似点加起来为一个,并使注意力更集中于最佳匹配的密钥。
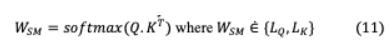
查询为键分配匹配的概率,值通常与键相似,因此

IV-A.3. Multi-Headed Attention (MHA) and Masking
MHA通过多次并行实现注意力,增强了模型强调序列不同标记位置的能力。由此产生的个人注意输出或头部通过一个线性层连接和转换到预期的维度。每个头部都可以从不同的角度参与序列部分,为每个标记提供类似的表示形式。这是执行,因为每个标记的自我注意向量可能权衡它所代表的词比其他由于高的结果点积。这是没有效率的,因为目标是实现与所有tokens进行类似的评估交互。因此,计算8次不同的自我注意,得到8次单独的注意用于计算最终结果的每个标记的向量注意向量通过所有8个向量的加权和tokens。由此产生的多重注意力载体是并行计算,馈给前馈层。每个后续目标tokens 都使用 +1生成编码器中的许多源标记( 0,..., + )。然而,在自回归解码器中,只有前一个时间步进考虑目标tokens( 0,. ., t),为未来目标0 预测的目的被称为因果掩蔽。提供此功能是为了最大限度地学习随后转换的目标标记。因此,在通过矩阵运算进行并行化的过程中,保证了后续的目标词被屏蔽为零,从而使注意网络无法预见未来。上面描述的Transformer导致了NLP领域的显著改进。这导致了我们将在后续部分中描述的大量高性能体系结构。
IV-B EMBEDDINGS FROM LANGUAGE MODELS: ELMo
ELMo[59]的目标是生成一个深度上下文的单词表示,可以建模
(i)单词复杂的句法和语义特征
(ii)一词多义或词汇歧义,发音相似的单词在不同的上下文或位置可能有不同的含义。
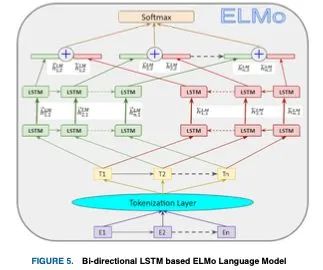
这些增强带来了上下文丰富的单词嵌入,这在以前的SOTA模型(如GloVe)中是不可用的。与使用预先确定的嵌入的模型不同,ELMo考虑所有 个tokens的出现( 1, 2,. . )为每个token 在创建嵌入之前的整个序列。作者假设该模型可以通过任务特定的双向LSTM提取其体系结构顶层的抽象语言属性。
这可以通过组合正向和反向语言模型实现。在时间步 −1时,前向语言模型根据(13)所示的输入序列的前一个观察到的标记,预测下一个标记 _ 。同样,在(14)中,倒序后向语言模型在给定未来标记的情况下预测之前的标记。
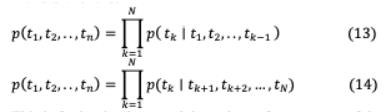
这是通过最终LSTM层之上的softmax进一步实现的,如图5所示。
ELMo对每个令符表示 _ 在LSTM模型的每一层 上计算其中间双向向量表示h_ , 为:
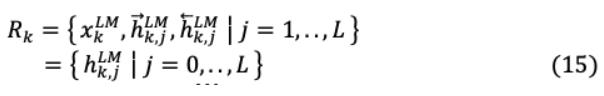
数学上h^{ }_{k,o}= _k将是最低级别的标记表示,可以概括为:
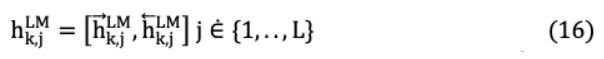
ELMo通过softmax ^{ }_{j}学习关于L层的归一化权重层表示。这就产生了一个特定于任务的超参数 ^ ,它支持任务的可伸缩性优化。因此,对于一个特定的任务,不同层中的单词表示差异表示为:
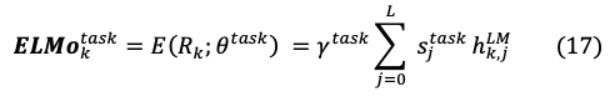
IV-B GENERATIVE PRE-TRAINING MODEL: GPT-I
在第一阶段,通过无监督学习,基于解码器的GPT-I在一个大数据集上进行预训练。这促进了原始数据计算,消除了监督学习的数据标注瓶颈。第二阶段在具有边际输入变化的相当小的监督数据集上执行任务特定的微调。结果表明,与ELMo、ULMFiT[60]等SOTA模型相比,该模型在更复杂的任务(如常识推理、语义相似性和阅读理解)中表现出更强的性能。GPT-I的预训练可以被建模为一个无监督标记的最大化函数{ ,…, }。

其中 为上下文窗口大小,条件概率通过 参数化。利用多头注意和前馈层,通过softmax生成了基于目标标记的概率分布。
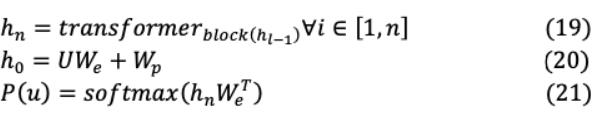
这里( = − ,. ., −1)为上下文标记向量集, 为层数, 和 分别为标记和位置嵌入矩阵。训练后,对监督结束任务进行参数调整。这里输入序列( ^1,. ., ^ ),将标记数据集 输入到先前的预训练模型,以获得Transformer块最终激活h^{ }_{l},输入到参数化( _y)线性输出层进行预测 。另外,目标 2( )是最大化如下

在微调过程中结合二级语言建模目标,通过更好地泛化监督模型来增强学习,并加速收敛:

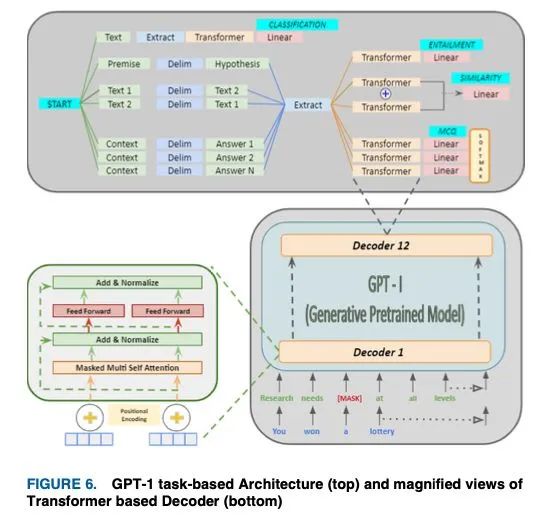
GPT执行分类、蕴涵、相似度指数、选择题(MCQ)等任务,如图6所示。提取阶段从文本主体中提取特征,然后在文本预处理过程中通过' Delimiter '标记将文本分离。分类任务不需要这个tokens,因为它不需要测量多个序列之间的关系。此外,问答或文本蕴涵任务涉及定义输入,如文档中的有序句子对或三联体。对于MCQ任务,需要在输入时更改上下文以获得正确的结果。这是通过基于Transformer的Decoder训练目标来实现的,其中输入转换针对各自的答案进行了微调。
IV-C BIDIRECTIONAL ENCODER REPRESENTATIONS FROM TRANSFORMER: BERT
BERT是一组预训练的Transformer编码器克服了先前模型的限制性表达,如:GPT缺乏双向语境和ELMo的浅薄双重上下文的连接。BERT的更深层次的模型提供具有多个上下文的tokens层和双向模型提供了更丰富的学习环境。然而,双向性引起了人们的关注,认为tokens可以隐式地预见未来的tokens在训练期间,从而导致最少的学习和导致琐碎预测。为了有效地训练这样一个模型,BERT实现掩码语言建模(MLM)每个输入序列中随机输入标记的15%。这种掩码词的预测是新要求不一样的在单向LM中重建整个输出序列。BERT在训练前的掩码,因此[MASK]标记在微调期间不显示,从而产生不匹配的“masked”tokens不会被替换。为了克服这个差异,精细的建模修改被执行在训练前阶段。如果一个token _i 被选择为掩码,那么80%的情况下它会被[MASK]替换token,10%的情况下选择一个随机token,剩下的10%没有改变。此后 _i的交叉熵损失会预测原始的tokens,使用不变的token步长来保持对正确预测的偏差。这种方法为Transformer编码器创造了一种随机和不断学习的状态,它必须维护每个token的分布式上下文表示。此外,由于随机替换仅占所有tokens的1.5%(15%中的10%),这似乎不会损害语言模型的理解能力。
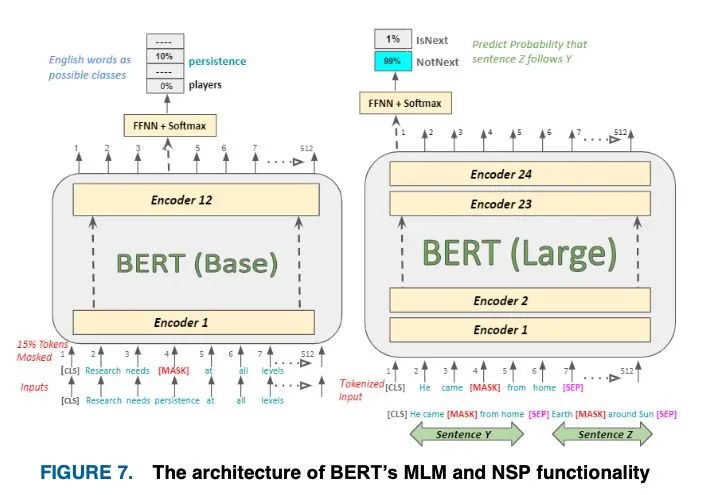
语言建模不能明确地理解多个序列之间的关联;因此,它被认为是推理和问答任务的次优选择。为了克服这一问题,我们使用单语语料库对BERT进行了预训练,以完成二值化的下一句预测(NSP)任务。如图7所示,句子 (He came [MASK] from home)和 (Earth [MASK] around Sun)没有形成任何连续性或关系。由于 不是 后面实际的下一个句子,输出分类标签[NotNext]将被激活,而[IsNext]将在序列一致时被激活。
IV-D GENERALIZED AUTOREGRESSIVE PRETRAINING FOR LANGUAGE UNDERSTANDING: XLNeT
XLNet在这两个方面都取得了最好的效果,它保留了自回归(AR)建模和双向上下文捕获的优点。为了更好地理解XLNet为什么优于BERT,请考虑5-tokens的序列(San, Francisco, is, a, city)。这两个标记选择预测(圣弗朗西斯科),因此BERT和XLNet最大化 ( | )如下:

对于目标( )和非目标标记集( ),以上可进一步一般化,BERT和XLNet将最大化日志 ( | ),并具有以下不同的可解释性:
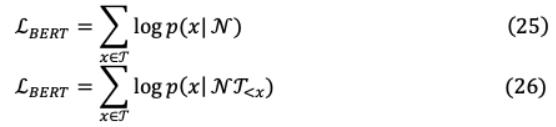
XLNet考虑用于预测的目标标记和其余标记,而BERT只考虑非目标标记。因此,XLNet捕获对间依赖[San, Francisco],这与BERT不同,在BERT中[San]或[Francisco]都会导致正确的预测。此外,通过AR XLNet对所有可能的tokens排列执行因式排序( !)= 5)的序列长度 设置即{(1、2、3、4、5),(1、2、5、4、3 ],. . ., [ 5、4、3、2、1]}≅[,城市,圣弗朗西斯科)等。
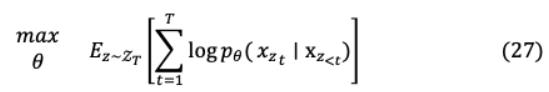
其中set _ 包含所有长度的置换序列 [1,2,. ., ], _ 是引用标记。因此,目标学习从无数的组合获得更丰富更符合实际的学习。此外,对于所有可置换的因子分解顺序,模型参数被共享,以从所有因子中构建知识和双向上下文,如公式27所示。
IV-D.1. Masking
由于不考虑决定自回归的标记( _ ),因此很难确定序列中的词序。这个词序部分是通过位置编码实现的,但是为了上下文理解XLNet使用了屏蔽。考虑一个在3-token序列中生成的排列[2,1,3],其中第一个token(即,2)没有上下文,因此所有屏蔽结果都在3×3屏蔽矩阵的第二行[0,0,0]中。类似地,第2和第3个掩码将导致查询流(QS)掩码矩阵的第1行和第3行中[0,1,0]和[1,1,0],tokens不能看到自己。带有一个对角包含的QS矩阵构成了内容流(CS)屏蔽矩阵,每个标记都可以看到自己。这个3-token序列屏蔽如下面的图8所示。
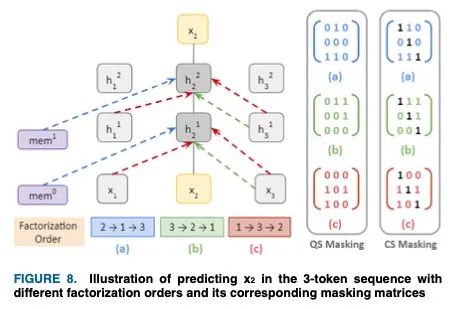
第一个引用' 2 '没有上下文,它是从对应的'mem块'中收集的,这是一个基于transformer-xl的扩展缓存内存访问。此后,它从tokens' 3 '和' 1 ',' 3 '接收上下文,用于后续排序。
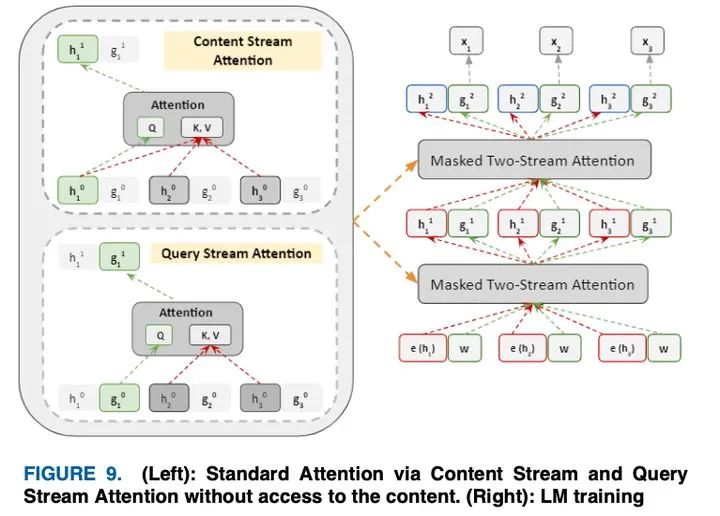
IV-D.2. Model Architecture
图9展示了模型的双流注意框架,它由内容和查询流注意过程组成,通过上下文实现更好的理解。这个过程是通过目标感知的表示开始的,其中目标位置被烘烤到输入中,用于后续的tokens生成目的。
(i)目标感知表示:一种普通的实现基于参数化的Transformer是不够的复杂的基于排列的语言建模。这是因为下一个记号分布 ( ∣ )是 < 独立于目标位置,即 。随后,产生冗余分布,无法发现有效表示,因此,我们提出了下一个tokens分布的目标位置感知重参数化方法:
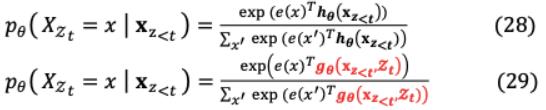
其中 (x < , )是一个修改过的表示,它另外将目标位置 视为输入。
(ii)two stream自我注意:尽管有上述解决方案,但 的表述仍然是一个挑战,因为目标是依靠目标位置 通过注意来收集语境信息 < ,因此:预测其他token _ ,其中 > , 应该编码上下文 _ 提供完整的语境理解。
为了进一步解决上述冲突,作者提出了以下两组隐含表示:
1)该隐藏内容表示h ( < )≅h that对上下文和内容进行编码
2)查询表示 ( < , )≅ 哪个单独访问上下文信息 < 和位置 ,没有内容
以上两个注意课程对每个自我注意层进行参数化共享和更新 为:

这种双重关注如图9所示。为简单起见,考虑不允许从上一层访问其对应嵌入的tokens 的预测。然而,为了预测 +1,tokens 需要访问其嵌入,并且这两个操作必须在一次传递中发生。
因此,实现了两个隐藏表示,其中h_ ( )通过令币嵌入初始化, _ ( )通过加权转换初始化。由上式h( )可以访问包括当前位置在内的历史,而gzt(m)只能访问以前的hzt(m)位置。tokens预测通过 ( )发生在最后一层。为了进行更大的序列长度处理,内存块来自Transformer-xl,它可以处理比标准Transformer输入序列长度更长的数据。上面提到的隐藏表示也存储在内存块中。
IV-E A Robustly Optimized BERT Pretraining Approach: RoBERTa
这篇论文声称,BERT是相当缺乏训练,因此,RoBERTa入了一个更大的训练密集制度。这是为基于bert的模型,可以匹配或超过以前的方法。他们的改进包括:
(i)更长的训练时间和更大的数据和批量
(ii)消除BERT的NSP目标
(iii)更长的序列训练
(iv)动态修改的训练数据掩蔽模式。
作者声称,对于更多样化和更大量的CC-News数据集,下游任务的性能优于BERT。
此外,BERT实现了一个低效的静态屏蔽实现,以避免冗余屏蔽。例如,在40个训练时期,一个序列以10种不同的方式被掩蔽,训练数据重复10次,每个训练序列用相同的掩蔽被看到4次。RoBERTa通过合并动态掩蔽提供了略微增强的结果,在预训练更大的数据集时,每次给模型输入一个序列时都会生成一个掩蔽模式。最近的研究质疑BERT的NSP[61]角色,该角色被推测在语言推理和问答任务中发挥关键作用。RoBERTa合并了这两种假设,并提供了许多类似BERT的补充训练格式,并且在不考虑NSP损失的完整句子训练中表现优于BERT。在GLUE基准测试以及RACE和SQUAD数据集上,RoBERTa提供的结果与BERT类似,但稍好于BERT,而无需对多个任务进行微调。
IV-E MEGATRON LANGUAGE MODEL (LM)
Megatron在发布时是最大的模型,尺寸为24 × BERT和5.6 × GPT-2,不适合单独的GPU。因此,关键的工程实现是归纳其8和64路模型,以及参数在(~512)gpu上拆分的数据并行版本。它保持了高性能(15.1千万亿次)和可伸缩效率(76%),而BERT则导致性能随尺寸增长而下降。这一壮举主要归功于层的规范化和Transformer层内剩余连接的重新排序。这导致在增加模型规模的下游任务上单调地优越性能。
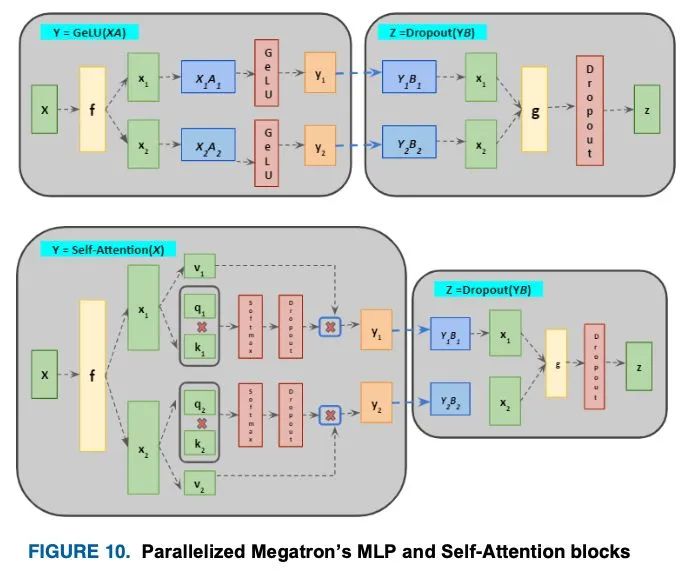
Megatron通过将模型拆分到几个加速器上,克服了先前模型的内存限制。这不仅解决了内存使用问题,而且增强了模型的并行性,与批处理大小无关。它将分布式张量计算集成到涌流模型的大小或加速度中,并将注意头计算并行化。这不需要新的编译器或重写代码,并且可以通过一些参数实现。
首先,多层感知器(Multi-Layer Perceptron, MLP)块在两列中并行划分GEMM,使GeLU非线性独立应用于每个划分的GEMM。这个GeLU输出被直接发送到行并行化的GEMM, GEMM的输出在传递到dropout层之前通过一个前进和后退的all-reduce算子(g和f)来减少。
自我关注块中的并行性是通过按列为每个键、查询和值集划分GEMMs来实现的。因此,由于每个注意力头在单个GPU上执行矩阵乘法,工作负载被分散到所有GPU上。生成的GEMM输出,像MLP一样,经过了全reduce操作,并跨行并行化,如图10所示。这种技术消除了MLP和注意块gem之间的同步需求。
V. NLG ARCHITECTURES
在NLU模型中,学习大量经过训练的“微调”任务所需要的大量数据计算在参数上是低效的,因为每个任务都需要一个全新的模型。这些模型可以作为狭隘的专家而不是精通的多面手的例证。因此,NLG模型提供了一个向构建通用系统的过渡,它可以完成几个任务,而不必为每个任务手动创建和标记一个训练数据集。此外,NLU模型中的传销不能捕获多个序列之间的丰富关系。此外,最有效的NLU模型从传销模型变体中派生出其方法,传销模型变体是经过文本重构训练的去噪自动编码器,其中单词的随机子集被屏蔽掉。因此,在过去的几年中,NLG模型在文本翻译和摘要、问答、NLI、会话参与、图片描述等方面取得了巨大的进展,其准确性达到了前所未有的水平。
V-A LANGUAGE MODELS ARE UNSUPERVISED MULTI- TASK LEARNERS: GPT-II
GPT-II[62]可能是随着NLG模型的兴起而出现的第一个模型。它在无监督的情况下接受训练,能够学习包括机器翻译、阅读理解和摘要在内的复杂任务,而无需进行明确的微调。其数据集对应的任务特异性训练是当前模型泛化不足的核心原因。因此,健壮的模型可能需要各种任务领域的培训和绩效衡量标准。GPT-II集成了一个通用的概率模型,在该模型中可以执行与 ( | , )相同的输入的多个任务。随着模型规模的扩大,训练和测试集的性能得到了提高,结果,它在巨大的WebText数据集上得到了匹配。在前面提到的零射击环境下的任务中,具有15亿个参数的GPT-2在大多数数据集上都优于它的前辈。它是GPT-I解码器体系结构的扩展,训练了更大的数据。
V-B BIDIRECTIONAL AND AUTOREGRESSIVE TRANSFORMERS: BART
去噪自动编码器BART是一个序列到序列[63]模型,它包含两个阶段的预处理训练:(1)通过随机噪声函数破坏原始文本,(2)通过训练模型重建文本。噪声的灵活性是该模型的主要好处,其中不限于对原始文本的长度更改的随机转换应用。两个这样的噪声变化是原始句子的随机顺序重组和填充方案,其中任何长度的文本被随机替换为一个mask标记。BART部署了所有可能的文档损坏方案,如图11所示,其中最严重的情况是所有源信息丢失,BART的行为就像一个语言模型。
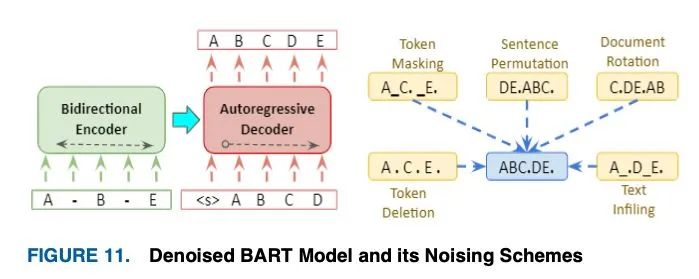
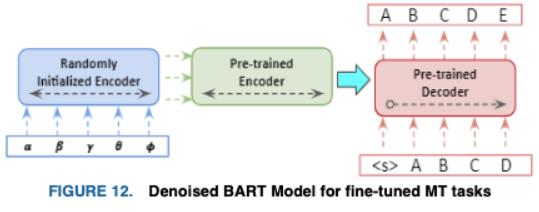
这迫使模型在整个序列长度上开发更大的推理,从而实现更大的输入转换,从而得到比BERT更好的泛化。BART是通过优化被破坏的输入文档上的重构损失来进行预训练的,即解码器的输出和原始文档之间的交叉熵。对于机器翻译任务,BART的编码器嵌入层被替换为一个任意初始化的编码器,该编码器使用预先训练的模型进行端到端训练,如图12所示。这个编码器将它的外语词汇映射到BART的输入,然后去噪到它的目标语言英语。源编码器的训练分为两个阶段,这两个阶段共享BART输出的交叉熵损失的反向传播。首先,对大部分BART参数进行冻结,仅对任意初始化的编码器、BART的位置嵌入以及编码器的自注意输入投影矩阵进行更新;其次,对所有模型参数进行联合训练,迭代次数较少;BART在几个文本生成任务上取得了最先进的性能,为NLG模型的进一步探索提供了动力。与RoBERTa相比,它在区分性任务上取得了比较结果。
V-C MULTILINGUAL DENOISING PRE-TRAINING FOR NEURAL MACHINE TRANSLATION: mBART
V-C.1. Supervised Machine Translation
mBART表明,通过自回归预处理训练BART,通过从公共爬行(CC-25)语料库中对25种语言的去噪目标进行序列重构,与之前的技术相比,取得了相当大的性能增益[64]。mBART的参数微调可以是有监督的,也可以是无监督的,适用于任何没有特定任务修改的语言对。例如,对语言对进行微调,即(德语-英语),使模型能够从单语训练前集中的任何语言,即(法语-英语)进行翻译,而无需进一步训练。由于每种语言都包含具有显著数字变化的标记,语料库通过对每种语言 进行文本上/下采样,其比例为 来进行平衡

其中 是数据集中每一种语言的百分比平滑参数 = 0.7。培训数据包含 语言: ={ 1,−, },其中每个 是 h语言的单语文档集合。考虑一个文本破坏噪声函数 ( ),其中训练模型预测原始文本 ,因此损失L 最大为:
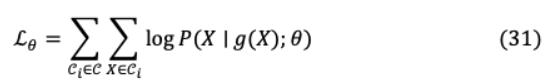
其中语言 有一个实例 和以上的分布 是通过序列到序列模型定义的。
V-C.2. Unsupervised Machine Translation
mBART是在目标双文本或文本对在这三种不同格式中不可用的任务上进行评估的。
1)没有任何形式的双文本是可用的,这里后面-翻译(BT)[67],[68]是一个熟悉的解决方案。mBART提供了一个干净而有效的初始化方案这样的技术。
2)目标对的双文本是不可用的,然而,在目标语言的bi-text中可以找到这一对其他语言对的文本语料库。
3)bi-text文本对目标pair是不可用的可从不同语言翻译到目标语言。这一新的评价方案显示了mBART在缺乏源语言双文本的情况下的迁移学习能力
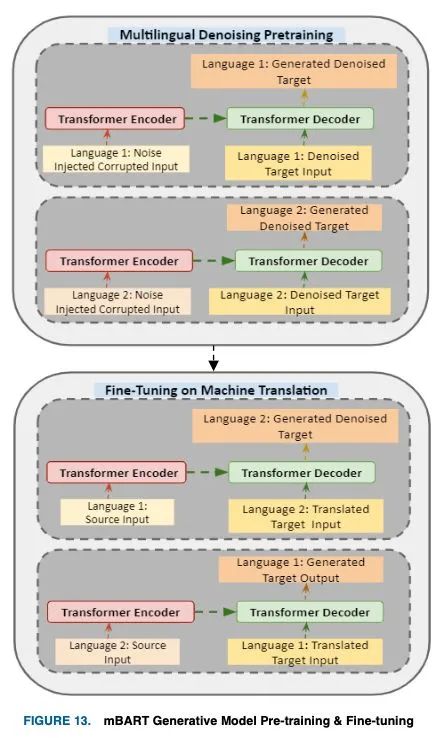
mBART是针对所有25种语言进行的预培训,并针对目标语言进行了微调,如图13所示。
V-D EXPLORING THE LIMITS OF TRANSFER LEARNING WITH A TEXT-TO-TEXT TRANSFORMER: T5
该模型是通过对最有效的迁移学习实践的调查和应用建立的。在这里,所有的NLP任务都安排在同一个模型中,超参数被重新定义为一个统一的文本到文本设置,其中文本字符串是输入和输出。需要一个高质量的、多样化的、庞大的数据集来测量在110亿个参数T5中训练前的放大效果。因此,开发了巨型清洁爬行语料库(C4),是维基百科的两倍大。
作者的结论是,因果掩蔽限制了模型的能力,只在 _ h输入一个序列,这是有害的。因此,T5在序列的前缀部分(前缀LM)包含完全可见掩蔽,而因果掩蔽则用于训练目标的预测。通过对迁移学习现状的调查,我们得出以下结论。
1)模型配置:通常带有编码器-解码器架构的模型优于基于解码器的语言模型。
2)预训练目标:去噪对于填空的角色是最有效的,在这个角色中,模型被预先训练以一个可接受的计算成本来检索输入的遗漏词
域内数据集:域内数据训练是有效的,但是预处理小数据集通常会导致过拟合。
3)训练方法:一个训练前的、微调的多任务学习方法可能是有效的,但是,每个任务的训练频率需要被监控。
4)经济缩放:为了有效地访问有限的计算资源,对模型尺寸缩放、训练时间和集成模型数量进行了评估。
V-E TURING NATURAL LANGUAGE GENERATION: T- NLG
T-NLG是一个基于78层变形器的生成语言模型,拥有170亿个可训练参数,比T5更大。它拥有比英伟达的威震天(Megatron)更快的速度,威震天是基于通过低延迟总线互连多台机器。T-NLG是一个逐渐变大的模型,它预先训练了更多种类和数量的数据。它通过较少的微调示例在通用下游任务中提供优越的结果。因此,它的作者概念化训练一个巨大的集中多任务模型,它的资源在不同的任务之间共享,而不是为一个任务分配每个模型。因此,该模型可以在没有背景的情况下有效地进行问答,从而增强了零射击学习。零冗余优化器(Zero)同时实现了模型和数据并行,这可能是训练T-NLG高吞吐量的主要原因。
V-F LANGUAGE MODELS ARE FEW-SHOT LEARNERS: GPT-III
GPT族(I、II和III)是基于Transformer解码器块的自回归语言模型,不像基于去噪自编码器的BERT。GPT-3从用于生成模型训练示例的3000亿个文本标记的数据集中训练1750亿个参数。由于GPT-3的大小是以前任何语言模型的10倍,并且对于所有任务和目的,它采用了通过文本界面的少量学习,没有梯度更新或微调,它实现了任务竞争。它采用无监督的预训练,语言模型获得广泛的技能和模式识别能力。这些都是在运行中实现的,以快速适应或识别所需的任务。GPT-3在几个NLP任务中实现了SOTA,尽管它的几次学习在其他任务中无法复制类似的结果。
V-G SCALING GIANT MODELS WITH CONDITIONAL COMPUTATION AND AUTOMATIC SHARDING: GShard
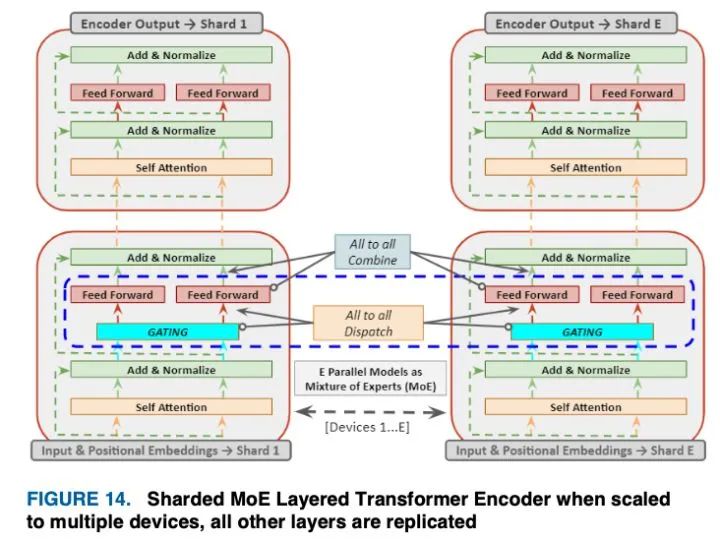
GShard允许扩展超过6000亿个参数通过稀疏门控混合的多语言机器翻译在低计算的情况下,采用自动分片的方法对专家(MoE)进行分类成本和编译时间。变形金刚的规模很小引入一个由 前馈网络 ,。, E组成的位置混合专家层,通过其Transformer得到

其中 和 是MoE层的标记化输入和平均加权输出, 和 是专家(前馈层)的输入和输出投影矩阵。门控网络通过矢量 , 表示专家对最终输出的贡献。这将获取tokens的非零值,这些tokens被分派给最多两个专家,这些专家在稀疏矩阵中为非零值做出贡献。为了实现跨TPU集群的高效并行化:(i)并行化的关注层沿着批处理维度被分割,权重被复制到所有设备上。(ii)由于大小的限制,不可能在所有设备上复制MoE层专家,因此专家需要在多个设备上分片,如下图所示。
决定模型质量的两个因素是
(i)具有大量训练数据的高资源语言
(ii)对数据有限的低资源语言的增强。
在翻译模型中,增加任务或语言对会对低资源语言产生积极的语言迁移[69]。对大量语言进行合理的培训时间和效率的三个方面的策略是:
(i)通过堆叠更多层来增加网络深度
(ii)通过复制专家来增加网络宽度
(iii)通过学习到的路由模块将tokens稀疏地分配给专家。
在一个12层的深度模型中,当每层的专家数量从128增加到512时,在100种语言的BLEU评分中发现了3.3的显著性能提升。此外,宽度从512增加四倍到2048会导致BLEU增益减少1.3。将前面提到的专家宽度的层深度进一步增加三倍,从12到36,可以显著提高低资源语言和高资源语言的性能。然而,除非模型的容量约束(MoE宽度)不放松,否则增加模型深度并没有效果。
VI. MODEL SIZE REDUCTION
VI-A DISTILLATION
知识蒸馏(KD)的目标是在一个更大、更准确的教师模型的监督下,通过修正的损失函数训练一个较小的学生模型,以在未标记样本中实现类似的准确性。我们提供了预测的教师模型样本,使学生能够通过较软的班级概率分布进行学习,同时通过一个单独的损失函数通过硬目标分类进行预测。这种硬标签到软标签的转换使学生学习的信息变化更大,例如,硬目标将狗分类为{ , , , ∈0,1,0,0},软目标为{10−6,0.9,0.1,10−9}。对于硬分类计算,深度神经网络的最后一个完全连接层是一个logits 向量,其中 是 h类的logit。因此,可以通过(35)中的softmax函数评估输入符合 h类的概率 ,并引入温度元件 来影响(36)中要转移到学生模型学习中的每个软目标的重要性。

对于类上较软的概率分布,需要较高的温度( = )。实验发现,除了教师的软标签外,对学生模型进行正确(硬/地面真理)标签的训练是有效的。虽然学生模型不能完全匹配软目标,但硬标签训练进一步帮助它不绊倒在不正确的预测。软目标精馏损失( = )的计算方法是将教师模型与学生模型的对数匹配为:
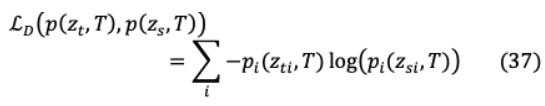
其中 和 分别表示教师模型和学生模型的对数。蒸馏机理如图15所示。ground truth label 和学生模型的软对数之间的交叉熵构成了学生损失:
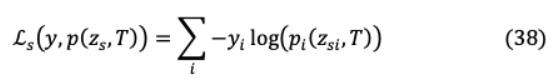
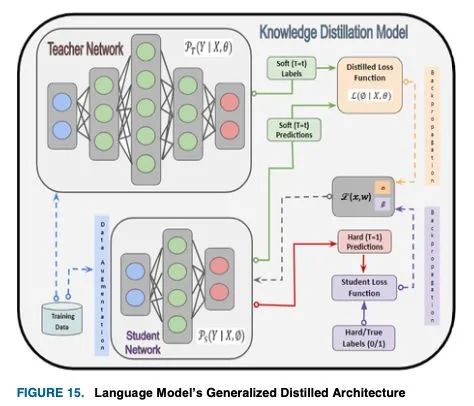
知识蒸馏的标准模型将蒸馏物和学生损失结合起来,如下图所示,

其中 ∈student参数 。在最初的平均用于 和 ,即 =1− ,为了得到最好的结果,观察到 ≫ 。
VI-A.1. DistilBERT
BERT的老师版本保留了BERT 97%的语言理解能力,推理时间更轻、更快,所需的培训成本更低。通过KD,蒸馏BERT将BERT大小减少了40%,速度提高了60%,压缩后的模型足够小,可以在边缘设备上运行。与BERT相比,蒸馏BERT的层深度被削减了一半,因为两者具有相同的维度,并且通常具有相同的架构。将其归一化后进行层约简,最终层线性优化计算无效。为了最大化大型预训练模型的归纳偏差,蒸馏器引入了三重损失函数,将蒸馏(L )与监督训练(L )或掩体语言建模损失线性结合。我们观察到用嵌入余弦损失(L )来补充先前的损失是有益的,因为它可以定向对齐教师和学生的隐状态向量。
VI-A.2. TinyBERT
为了克服训练前-微调范式的提炼复杂性,TinyBERT引入了一个清晰的知识转移过程,通过引入3个损失函数:
(i)嵌入层输出(ii)注意矩阵,
(ii)Transformer的隐藏状态
(iii)输出Logits
这不仅使得TinyBERT在大幅缩减尺寸的情况下保留了BERT的96%以上的性能,而且在所有基于BERT的精馏模型中只部署了28%的参数和31%的推理时间。此外,它利用了BERT的已学习注意力权重中未挖掘的可提取潜力[70],对于( + 1) h层,通过最小化:
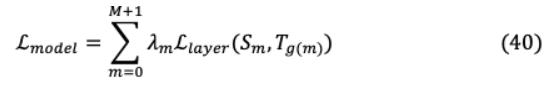
L 是Transformer或an的损耗函数嵌入层和超参数 表示 h层精馏的重要性。在TinyBERT中,BERT基于注意力的语言理解增强可以被合并为:

其中h表示正面次数, 表示注意力矩阵对应学生或老师的 h头, 表示输入文本长度和均方误差(MSE)损失函数。此外,TinyBERT提炼了知识从Transformer输出层,可以表示为:
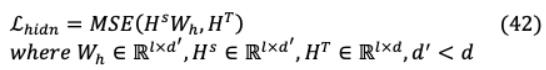
在这里 隐藏的状态的学生和教师 ( )分别隐藏大小的教师模型和学生模型是通过标量值 '和 表示, 是一个可学习的h将学生网络的隐藏状态转化为教师网络的空间状态。同样,TinyBERT还对埋层进行蒸馏:

其中 和 分别是学生网络和教师网络的嵌入矩阵。除了模拟中间层的行为,TinyBERT通过学生和教师的对数之间的交叉熵损失实现KD来拟合教师模型的预测。

这里 和 分别是教师和学生模型预测的logit。
VI-A.3. MobileBERT
与之前的蒸馏模型不同,MobileBERT从BERT中实现任务不可知压缩,通过预测和蒸馏损失实现训练收敛。为了训练这样一个非常瘦的模型,设计了一个独特的倒置瓶颈教师模型,该模型结合了BERT (IB- BERT),知识转移从BERT提炼到MobileBERT。它比BERT小4.3倍,快5.5倍,在基于glue的推理任务中,其竞争分数比BERT低0.6个单位。此外,Pixel 4手机上62毫秒的低延迟可归因于用更简单的Hadamard乘积(薄膜)线性转换取代层归一化和gelu激活。
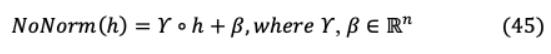
对于知识转移,均方误差之间将MobileBERT和bert的特征映射实现为迁移目标。
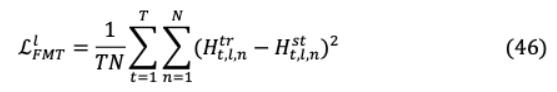
其中 是层索引, 是序列长度, 是特征地图的大小。为了让TinyBERT利用BERT的注意力能力,两种模型的人均分布之间的KL-divergence最小,其中 表示注意头的数量。
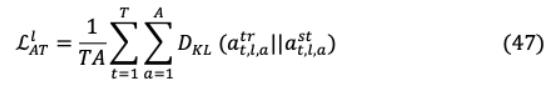
或者,在MobileBERT的预训练过程中,通过BERT的传销和NSP损失的线性组合,可以实现新的KD损失,其中 是(0,1)之间的超参数。
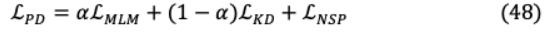
为实现上述目标,现提出3项培训战略:
(i)辅助知识转移:通过所有层转移损失和蒸馏前训练损失的线性组合进行中间转移。
(ii)联合知识转移:为了获得更好的结果,提出了2个单独的损失,其中MobileBERT与所有层联合转移损失并进行预先训练的蒸馏。
(iii)渐进式知识转移:为了最大限度地减少自上而下的错误转移,提出将知识转移分为 分层 阶段,每一层逐步训练。
VI-B PRUNING
修剪[71]是一种将不再是模型反向传播的一部分的某些权重、偏差、层和激活置零的方法。这引入了这些元素的稀疏性,它们是可见的后ReLU层,将负值转换为零(( ( ): (0, ))。迭代剪枝学习关键权值,根据阈值消除最不关键的权值,并重新训练模型,使其能够通过适应剩余的权值从剪枝中恢复。像BERT、RoBERTa、XLNet这样的NLP模型被修剪了40%,并保留了98%的性能,这与蒸馏BERT相当。
VI-B.1 LAYER PRUNING
VI-B.1-A STRUCTURED DROPOUT
该体系结构[72]在训练和测试时随机丢弃层,使子网络能够选择任何期望的深度,因为网络已经被训练为具有修剪健壮性。这是对当前技术的升级,需要重新训练一个新模型,而不是训练一个网络,从中提取多个浅层模型。这种子网络抽样,如Dropout[73]和DropConnect[74],如果聪明地选择了同时权值组,就会构建一个高效的健壮修剪网络。形式上,正则化网络的修剪鲁棒性可以通过伯努利分布独立地降低每个权值来实现,其中参数p > 0控制着跌落率。这相当于权矩阵 与任意采样的{0,1)掩码矩阵 , = ⨀ 的点积。
最有效的降层策略是每隔一层降一层,其中修剪率为 ,降层深度为 ,使 ≡0( ⌊1/ ⌋)。对于具有固定跌落比率 的 组,网络训练期间所利用的平均组数为 (1− ),因此对于 组的修剪大小,理想跌落率将为 ∗= 1− / 。这种方法在许多NLP任务中都非常有效,并且已经产生了与BERT精馏版本相当的模型,并且表现出更好的性能。
VI-B.1-B POOR MAN’S BERT
由于深度神经网络的过度参数化,在推理时不需要所有参数的可用性,因此策略性地减少了几个层,导致下游任务的竞争结果[75]。在所有任务中,奇数替代删除策略的结果优于顶部,甚至在间隔为 = 2的情况下进行替换。例如,在一个12层网络中,删除:top - {11,12};偶数交替- {10,12};奇交替-{9,11},得出的结论是
(i)连续丢弃最后两层比消除交替层更有害
(ii)保留最后一层比保留顶层其他层更重要。
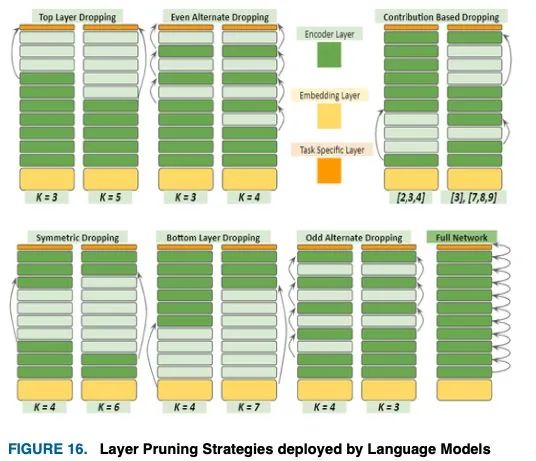
在 的较高值处,交替删除方法表示性能下降很大,假设这是由于消除了较低的层造成的。对称的方法强调顶层和底层的守恒,而中间层被去掉。这对BERT的影响很小,但却大大降低了XLNet的性能,从而导致BERT的次优策略即使去掉4层后也能给出健壮的结果。
通过观察,XLNet显示出比BERT更大的修剪鲁棒性,因为它的学习在接近其第7层时变得成熟,而BERT则一直学习到第11层。因此(i)与BERT相比,XLNet在较低的层收集面向任务的知识,(ii) XLNet的最终层可能会变得相当冗余,容易在性能没有显著下降的情况下被删除。作者进一步对蒸馏器进行了下降实验,在这里下降30%的层导致了最小的性能下降。
像以前的模型一样,顶层下降被证明是最可靠的,因为RoBERTa被证明比BERT更健壮,因为6层的RoBERTa表现出了与蒸馏RoBERTa相似的性能。所有的弃层策略都可以从上面的图16中可视化。
VI-B.2 WEIGHT PRUNING
先前的工作主要集中在非结构化的个体权剪枝[76],[77],尽管其产生的有效的非结构化稀疏矩阵在传统硬件上处理具有挑战性。这使得尽管模型减小了,但仍难以保证推理加速。相反,结构化剪枝强制高度结构化的权矩阵,当通过密集线性代数实现优化时,会导致显著的加速,但由于更大的约束,性能低于非结构化剪枝。
VI-B.2-A STRUCTURED PRUNING
为了克服上述缺点,本文采用了新颖的结构引入了低秩剪枝范式[78]因式分解保留了稠密矩阵的结构和 0规范,放松了通过结构化强制执行的约束修剪。权重矩阵被分解成乘积两个小矩阵的对角掩模修剪而训练通过 0正则化控制模型的末端稀疏性。这个泛型方法FLOP(Factorized 0 Pruning)可用于任何矩阵乘法。对于神经网络 (; )参数化 ={ } ,其中每个 表示单个重量 =1 或者一个权重块(例如,列矩阵), 表示块的数量。考虑一个精简二值化变量 = ̃̃{ }其中 ∈{0,1}, ={ }表示模型 =1 参数集,通过 0规范化后修剪。
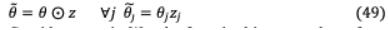
考虑一个矩阵 被分解成两个的乘积较小的矩阵 和 ,其中 = 。和 表示 列数或 行数。每个组件的结构化剪枝是通过剪枝变量 实现的

VI-B.3 HEAD PRUNING
虽然某些模型在多头注意力环境中对多头注意力有更大的依赖性,但最近的研究表明,可以删除相当一部分注意力头,从而形成一个具有更高记忆效率、速度和准确性的精简模型。在之前的研究中[79],[80]通过对特定位置所有头部的注意力权重进行平均,或者根据最大注意力权重值来判断头部的重要性。然而,这两种方法都没有明确考虑不同头部的波动意义。
VI-B.3-A Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, Rest Can Be Pruned
这个模型[81]发现了三个不同层次的头部角色:
(i)位置头:用于处理相邻标记
(ii)句法头:注意那些有句法的人
(iii)稀有词头:最少指示序列中频繁的标记。
基于上述角色[81]这些总结为:
(a)头的一小部分是翻译的关键
(b)关键头拥有一个单一,通常更专门化和可解释的模型功能
(c)头部角色对应于相邻标志的注意在显式语法依赖关系中。
高水头基于层次关联传播(LRP)的可信度[82]与标记的注意力定义的比例有关作为其最大关注权值的中值计算总的来说,这对于任务来说是至关重要的。通过每个产品修改的Transformer架构磁头的计算表示h 和标量门 , ( , )= ( .h ) ,这里 是输入独立头部特定参数, 0正则化适用于 ,用于较不重要的头需要被禁用,h∈( h )。
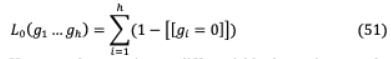
然而, 0 norm是不可微的;因此,它不能作为目标函数中的正则项归纳。因此,应用随机松弛,每个门 从头分布中随机选取,头分布是通过拉伸(0,1)到(−∈,1+∈),并将概率分布(−∈,1)坍塌到[1,1 +∈)到奇异点0和1得到的。这种修正的拉伸结果在[0,1]上的分布是离散-连续混合的。头像非零的概率和可以实现为一个宽松的L0范数。
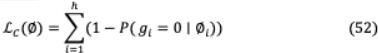
修改后的训练方案可以表示为L( ,∅)= L ( ,∅)+ L (∅),其中 为原Transformer参数,L ( ,∅)为平移模型的交叉熵损失,L (∅)为正则器。
VI-B.3-B ARE 16 HEADS REALLY BETTER THAN ONE?
在多头注意力(MHA)中,考虑 的序列 -dimensional vectors = 1,. ., ∈R ,查询向量 ∈R 。MHA层参数 h, h h h∈R h× 和 h∈R × h,当 = 。h为了掩蔽注意头,原Transformer方程修改为:

其中 h用值介于{0,1}之间的变量屏蔽, h( )是输入 的头h的输出。以下实验在测试时间修剪不同的头数上获得了最好的结果[83]:
(i)仅修剪一个头部:如果模型在屏蔽头部h时性能显著下降,则h为关键头部,否则在给定模型的其余部分时,它是冗余的。当被从模型中移除时,仅仅8次(总共96次)正面就会引起表现的显著变化,其中一半的结果是更高的BLEU分数。
(ii)除1个注意头外的所有注意头修剪:在测试时间内,大多数层只修剪一个注意头就足够了,即使对于有12或16个注意头的网络,也会导致显著的参数减少。然而,多个注意头是特定层的需求,即编码器-解码器注意的最后一层,在单个注意头上性能会降低13.5个BLEU点。模型对掩蔽的期望敏感性 被评估为头部显著性的代理评分。
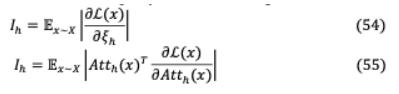
其中 为数据分布,L( )为样本 上的损失。如果 h很高,那么修改 h可能会对模型产生显著影响,因此,对 h值较低的头进行迭代修剪。
VI-C QUANTIZATION
32位浮点数(FP32)一直是深度学习的主要数字格式,然而当前减少带宽和计算资源的浪潮推动了更低精度格式的实现。已经证明通过8位整数(INT8)的权值和激活表示不会导致明显的精度损失。例如,BERT量化为16/8位权值格式导致4×模型压缩,精度损失最小,因此,一个扩展的BERT每天服务十亿CPU请求。
VI-C.1 LQ-NETS
该模型[84]通
以上是关于NLP实操手册: 基于Transformer的深度学习架构的应用指南(综述)的主要内容,如果未能解决你的问题,请参考以下文章