大数据实战——微博舆情大数据分析
Posted 编程圈子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据实战——微博舆情大数据分析相关的知识,希望对你有一定的参考价值。
CSDN 直播课程学习笔记
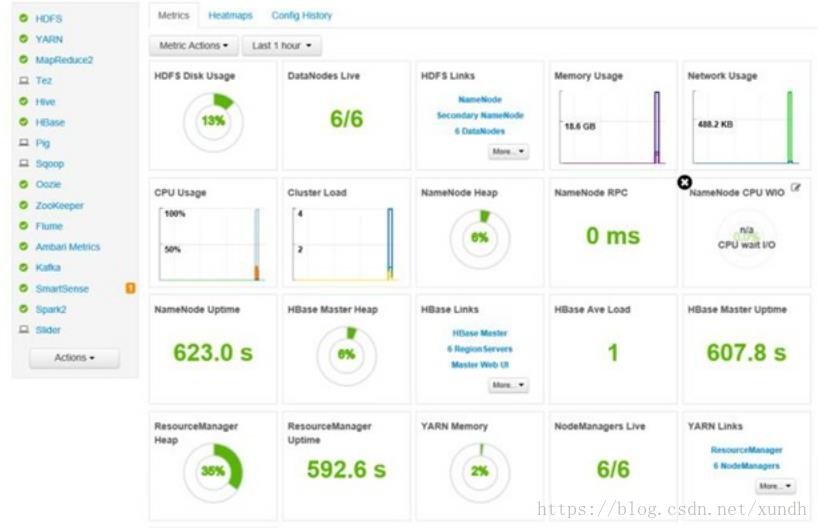
云端实验室环境
基于开源的ambari大数据平台,部署了7个节点:
一、 项目背景
企业可能对用户在微博上的评价内容有监测需求,如活动效果、用户对产品的评价,用户关注于产品的价格还是功能等等。
本平台用来获取微博的数据(数据量大、非结构化数据),进行数据分析,存储在云平台,将结果输出给企业。
二、 项目架构
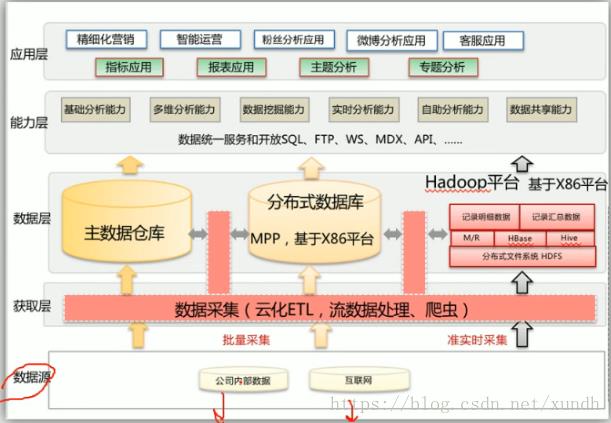
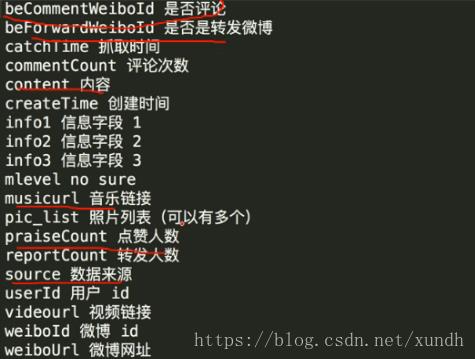
1. 数据源
微博数据:
2. 数据层
本次数据层主要讲主数据仓库。
数据仓库是为应用层提供数据服务的。

数据仓库表设计
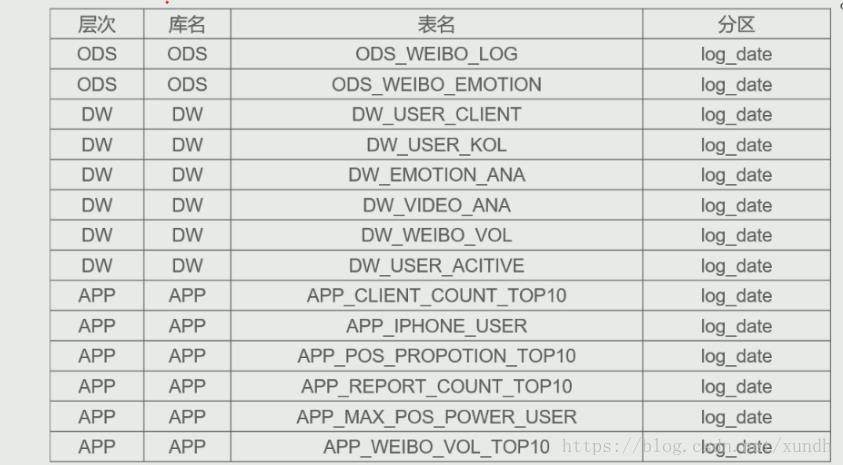
数据仓库一般是离线数据分析使用,每天要跑的固化需求。如果是临时需求(提数),就要让大数据开发人员专门做一条数据报表出来。
3. 平台层
ODS层:数据是清洗后的。
4. APP区
从数据仓库区取数据分析展示。
三、 平台演示
运维人员一般使用Ambari,作为大数据的管理平台,而给开发人员使用跳板机(或堡垒机)。
开发界面示例:
select count(*) from web_log_192g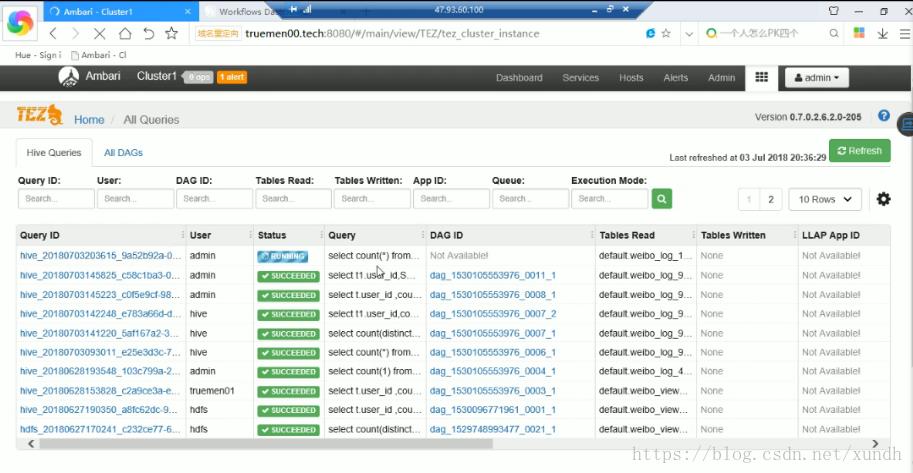
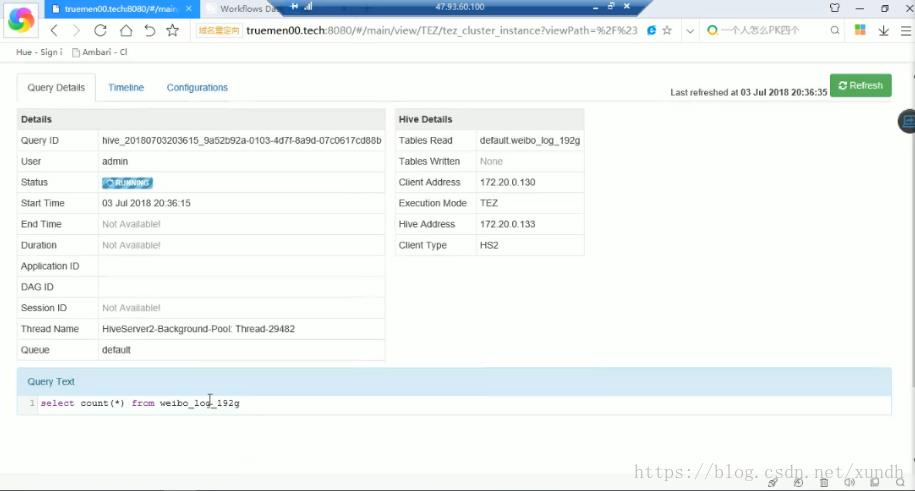
公司开发时,运维一般给不同团队分配不同队列,不同队列会有不同资源。
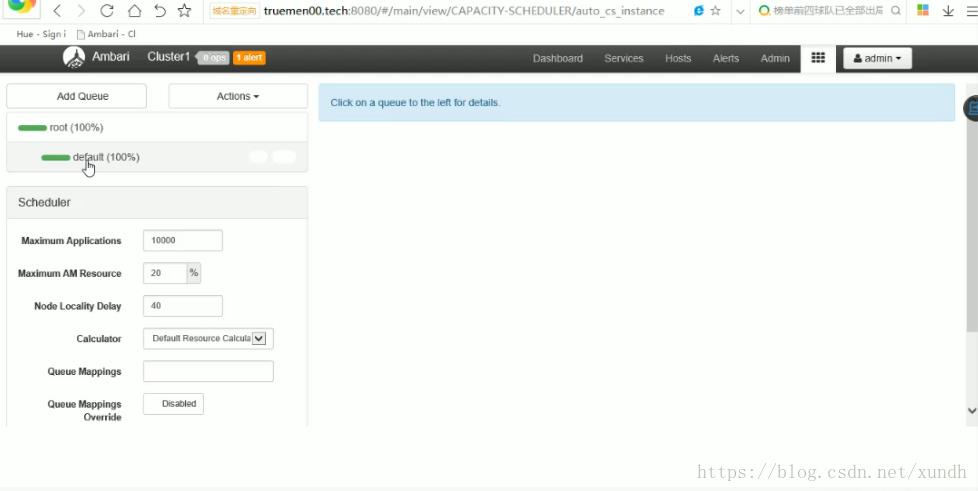
虽然Spark比较成熟,但大多数公司对离线分析还是用Hive多一些。
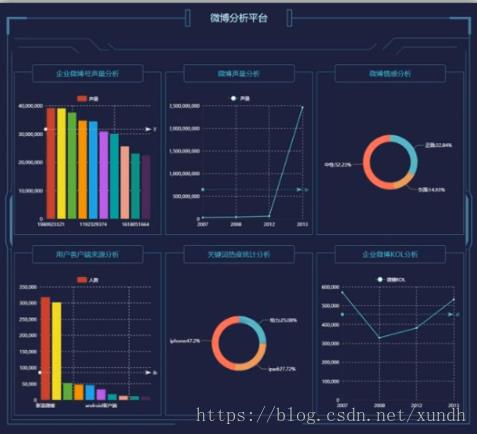
企业微博声量号的分析:
统计微博最新状态下被评论 最多的Top10账户id,
注意:每个用户的微博进行去重之后,筛选出同一条微博的最新状态。

开发有两种方式,一种在Ambari web平台写脚本。
实际中使用引入一个开发平台。这里是Hue。
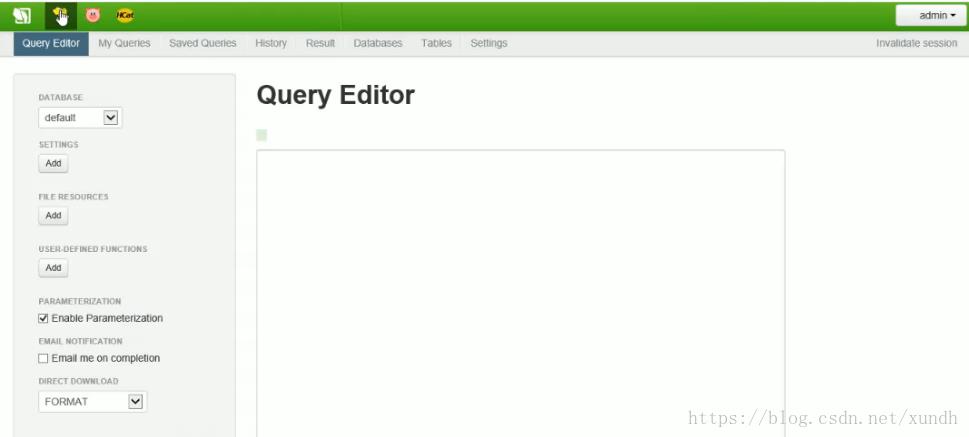
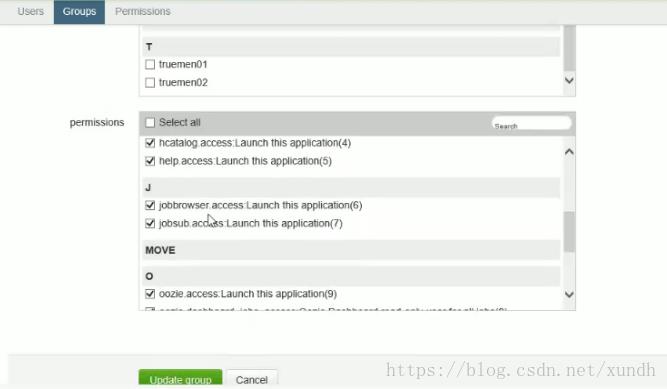
每天都要跑的定时任务,一般用这样的平台设置一些权限,
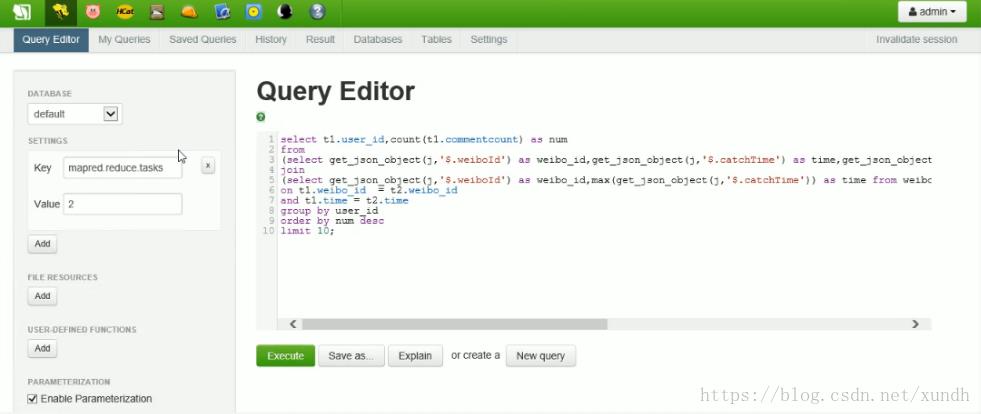
在这里写经常用的SQL
点击Save As,
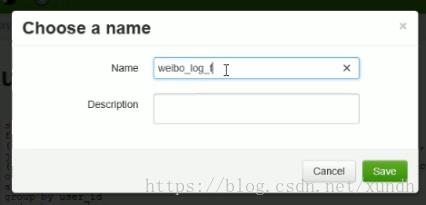
这样平时开发的SQL都可以保存下来。
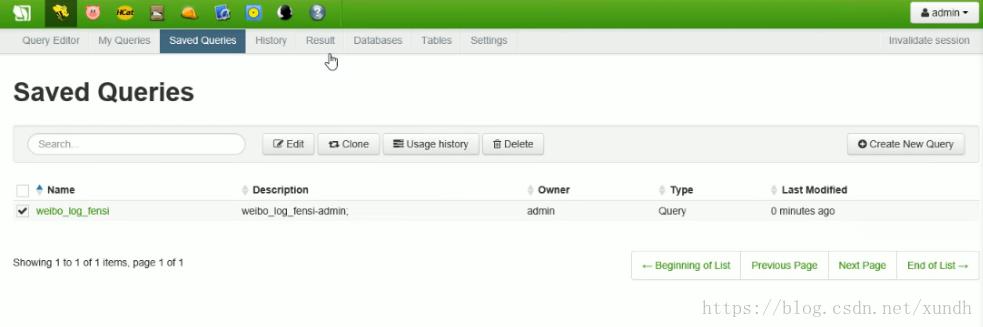
如果要执行,那要设计一个执行器:
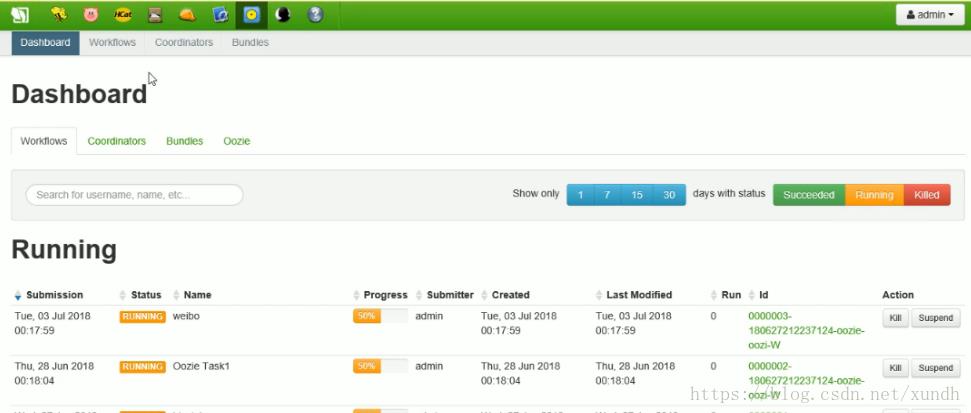
企业中使用一般会针对这个界面进行二次开发
新建一个流程:
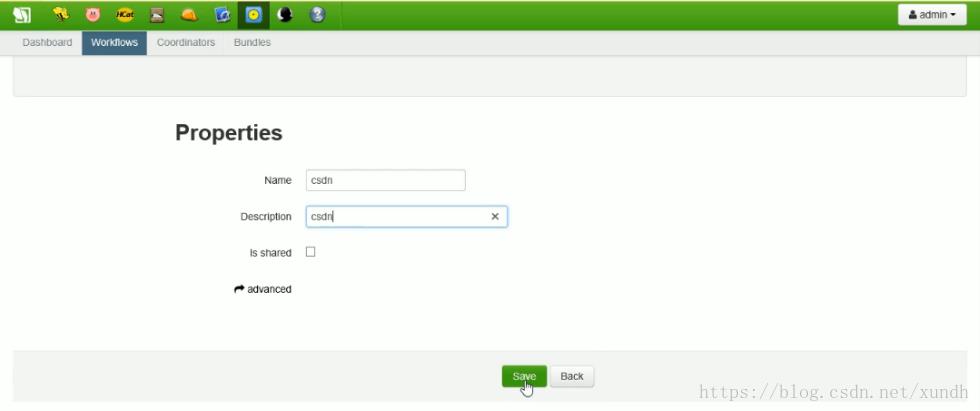
然后添加流程:
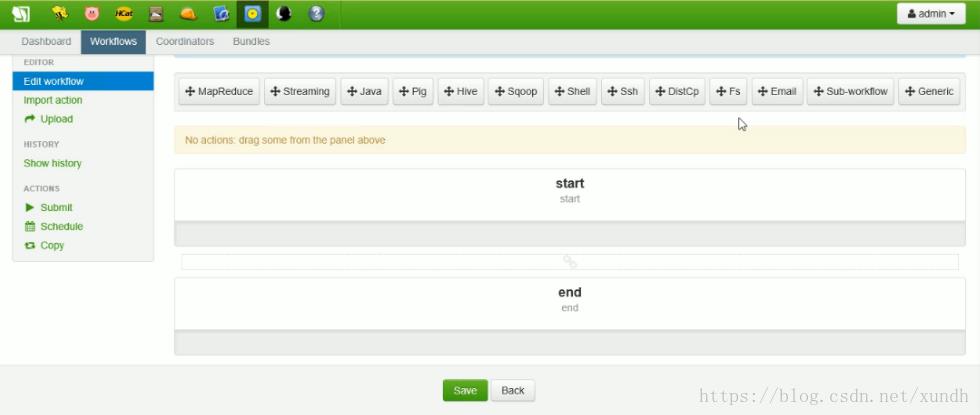
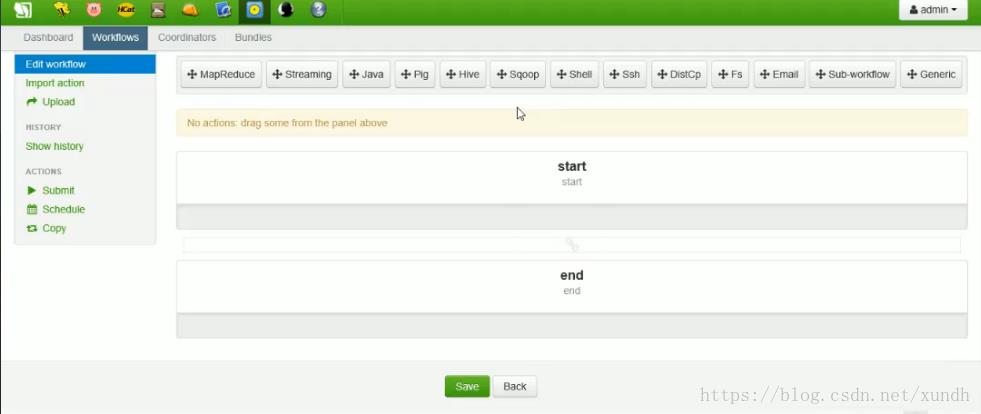
设置运行条件:
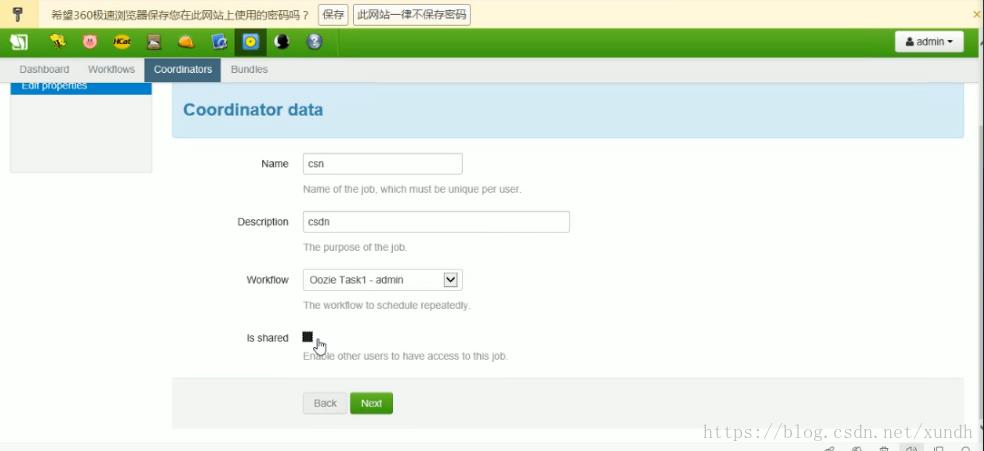
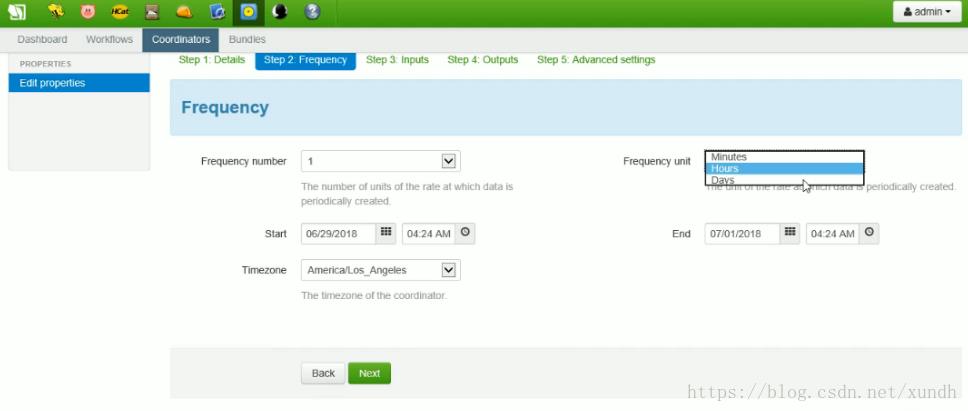
选择数据:
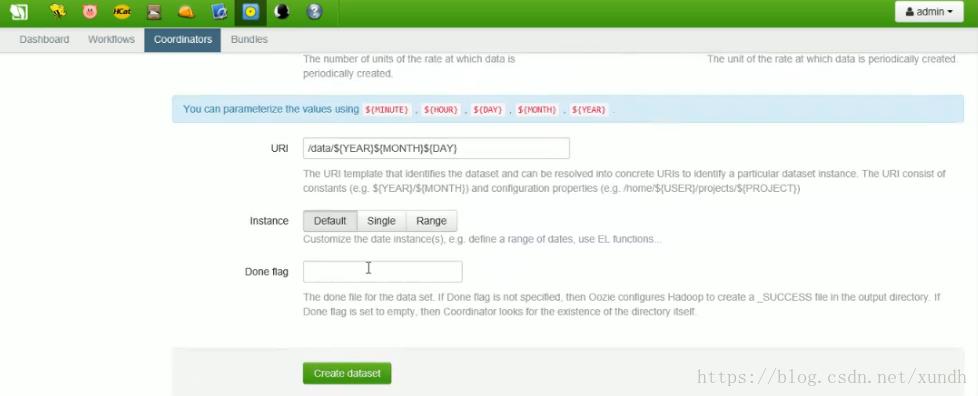

固定的报表一般会配置WorkFlow,这里使用Oozie作为工作流平台
以上是关于大数据实战——微博舆情大数据分析的主要内容,如果未能解决你的问题,请参考以下文章
[大数据项目]-0010-基于大数据技术推荐系统算法案例实战视频教