批量爬取网站上的文本和图片,并保存至word中
Posted cooper-73
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了批量爬取网站上的文本和图片,并保存至word中相关的知识,希望对你有一定的参考价值。
1 from pyquery import PyQuery as pq 2 import requests as rs 3 from docx import Document 4 from docx.shared import RGBColor 5 6 7 html = ‘‘‘ 8 https://zhs.moo0.com/software/AudioTypeConverter/pad.xml 9 https://zhs.moo0.com/software/AudioEffecter/pad.xml 10 https://zhs.moo0.com/software/AudioPlayer/pad.xml 11 https://zhs.moo0.com/software/Mp3InfoEditor/pad.xml 12 https://zhs.moo0.com/software/VoiceRecorder/pad.xml 13 https://zhs.moo0.com/software/Magnifier/pad.xml 14 https://zhs.moo0.com/software/MultiDesktop/pad.xml 15 https://zhs.moo0.com/software/ScreenShot/pad.xml 16 https://zhs.moo0.com/software/SimpleTimer/pad.xml 17 https://zhs.moo0.com/software/TransparentMenu/pad.xml 18 https://zhs.moo0.com/software/WindowMenuPlus/pad.xml 19 https://zhs.moo0.com/software/WorldTime/pad.xml 20 https://zhs.moo0.com/software/AntiRecovery/pad.xml 21 https://zhs.moo0.com/software/DiskCleaner/pad.xml 22 https://zhs.moo0.com/software/FileMonitor/pad.xml 23 https://zhs.moo0.com/software/FileShredder/pad.xml 24 https://zhs.moo0.com/software/HashCode/pad.xml 25 https://zhs.moo0.com/software/TimeStamp/pad.xml 26 https://zhs.moo0.com/software/ColorPicker/pad.xml 27 https://zhs.moo0.com/software/FontViewer/pad.xml 28 https://zhs.moo0.com/software/ImageInColors/pad.xml 29 https://zhs.moo0.com/software/ImageTypeConverter/pad.xml 30 https://zhs.moo0.com/software/ImageSharpener/pad.xml 31 https://zhs.moo0.com/software/ImageSizer/pad.xml 32 https://zhs.moo0.com/software/ImageThumbnailer/pad.xml 33 https://zhs.moo0.com/software/ImageViewer/pad.xml 34 https://zhs.moo0.com/software/ImageViewer/pad.xml 35 https://zhs.moo0.com/software/ConnectionWatcher/pad.xml 36 https://zhs.moo0.com/software/RightClicker/pad.xml 37 https://zhs.moo0.com/software/RightClicker/pad.xml 38 https://zhs.moo0.com/software/SystemCloser/pad.xml 39 https://zhs.moo0.com/software/SystemMonitor/pad.xml 40 https://zhs.moo0.com/software/XpDesktopHeap/pad.xml 41 https://zhs.moo0.com/software/VideoConverter/pad.xml 42 https://zhs.moo0.com/software/VideoCutter/pad.xml 43 https://zhs.moo0.com/software/VideoInfo/pad.xml 44 https://zhs.moo0.com/software/VideoMinimizer/pad.xml 45 https://zhs.moo0.com/software/VideoToAudio/pad.xml 46 https://zhs.moo0.com/software/FFmpeg/pad.xml 47 ‘‘‘ 48 49 def get_info(address):#爬取网页上的信息 50 add = rs.get(address) 51 res = pq(add.content, parser=‘html‘) 52 name = res(‘Program_Name‘).text() 53 versize = ‘软件版本:‘ + res(‘Program_Version‘).text() + ‘ ‘ + ‘软件大小:‘ + res(‘File_Size_MB‘).text() 54 introduce = ‘软件介绍:‘ + ‘ ‘ + res(‘ChineseSimplified‘).find(‘Char_Desc_45‘).text() + ‘ ‘ + res( 55 ‘ChineseSimplified‘).find(‘Char_Desc_2000‘).text() 56 photourl = res(‘Application_Screenshot_URL‘).text() 57 download = res(‘Primary_Download_URL‘).text() 58 return [name,versize,introduce,photourl,download] 59 60 def get_pic(pic_url):#docx无法直接插入网络图片,因此在这里先将网络图片下载到本地 61 pic = rs.get(pic_url) 62 with open(‘pic_tmp.png‘, "wb")as f: 63 f.write(pic.content) 64 65 def insert_doc(n,res): #将爬取的内容导入document。 66 name = str(n)+‘、‘+ res[0] 67 document.add_heading(name) 68 document.add_paragraph(res[1]) 69 document.add_paragraph(res[2]) 70 document.add_picture(‘pic_tmp.png‘) 71 p = document.add_paragraph() 72 run = p.add_run(‘下载地址: ‘) 73 run = p.add_run(res[4]) 74 run.italic = True 75 run.underline = True 76 run.font.color.rgb = RGBColor(31,77,225) 77 78 def main(): 79 n = 0 80 for address in html.split(): 81 n += 1 82 print(n) 83 respon = get_info(address) 84 get_pic(respon[3]) 85 insert_doc(n, respon) 86 87 if __name__== ‘__main__‘: 88 document = Document() 89 main() 90 document.save(‘./demo.docx‘)
效果预览:
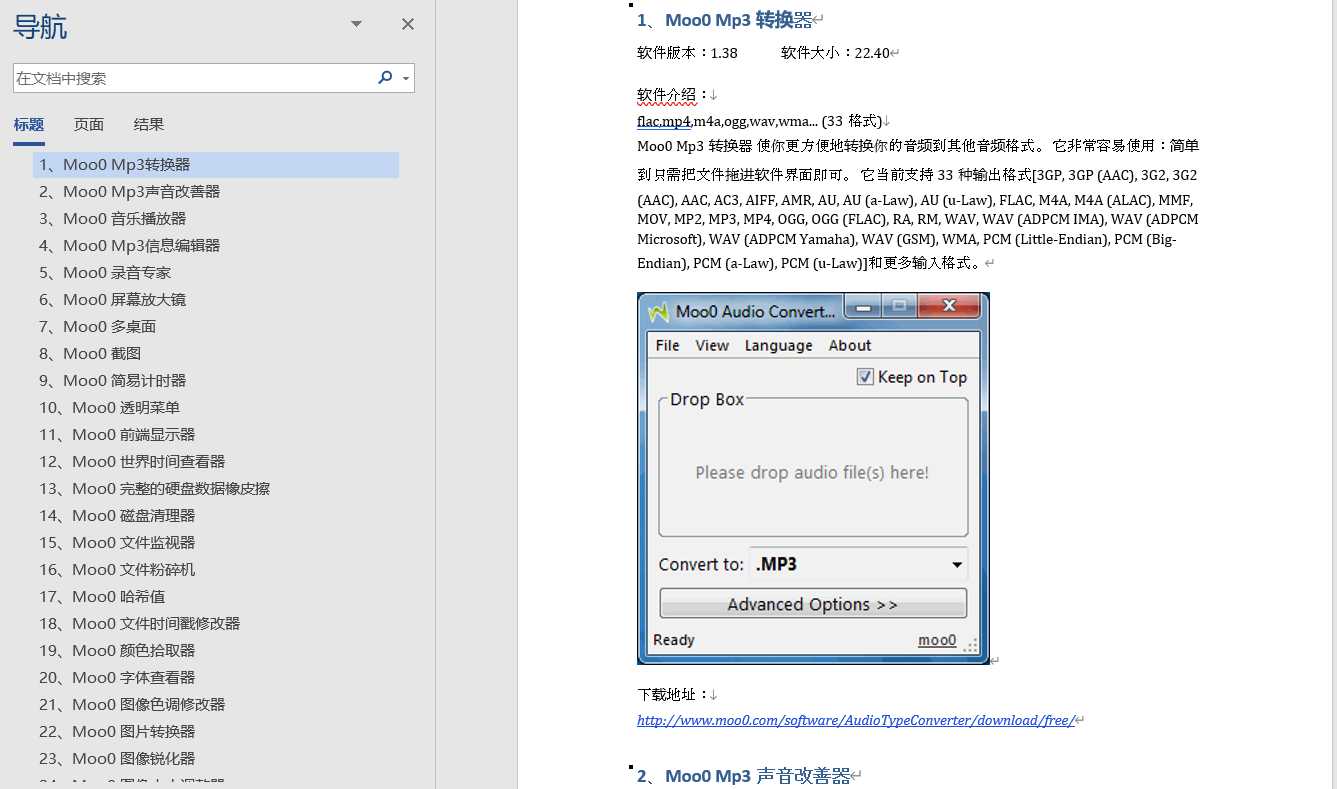
以上是关于批量爬取网站上的文本和图片,并保存至word中的主要内容,如果未能解决你的问题,请参考以下文章