Python爬虫爬取网页上的所有图片
Posted 卡卡南安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫爬取网页上的所有图片相关的知识,希望对你有一定的参考价值。
一. 前言
以该网页(链接)为例,上面有图片形式的PPT内容,我的目的是将所有图片下载下来保存到本地,如果鼠标一张一张点击下载效率很低,于是可以用爬虫批量爬取图片。
采用爬虫爬取网页中的图片主要分为两个步骤:
- 获取网页中所有图片的链接;
- 下载图片对应链接并保存在本地。
接下来我将分别从以上两个步骤讲解图片爬取过程。
二. 获取图片链接
在网页中按下键盘右上角的F12,找到网页的html,如图所示:
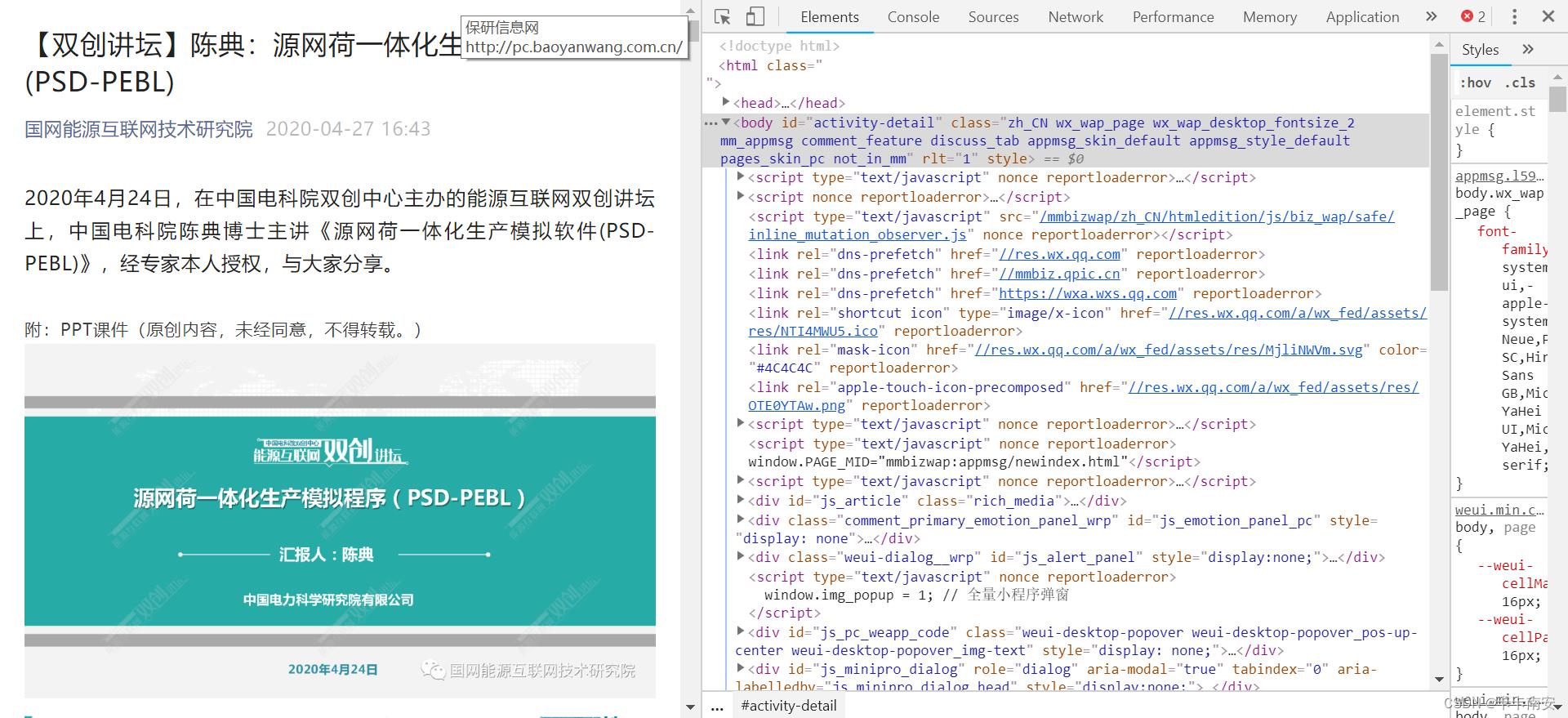
当我们的鼠标在Html上移动时,左边对应位置处将会变成蓝色。在Html中查找img,直到看到左边图片对应的部分变成蓝色了,就说明找到了该图片对应的Html语句,如图所示:
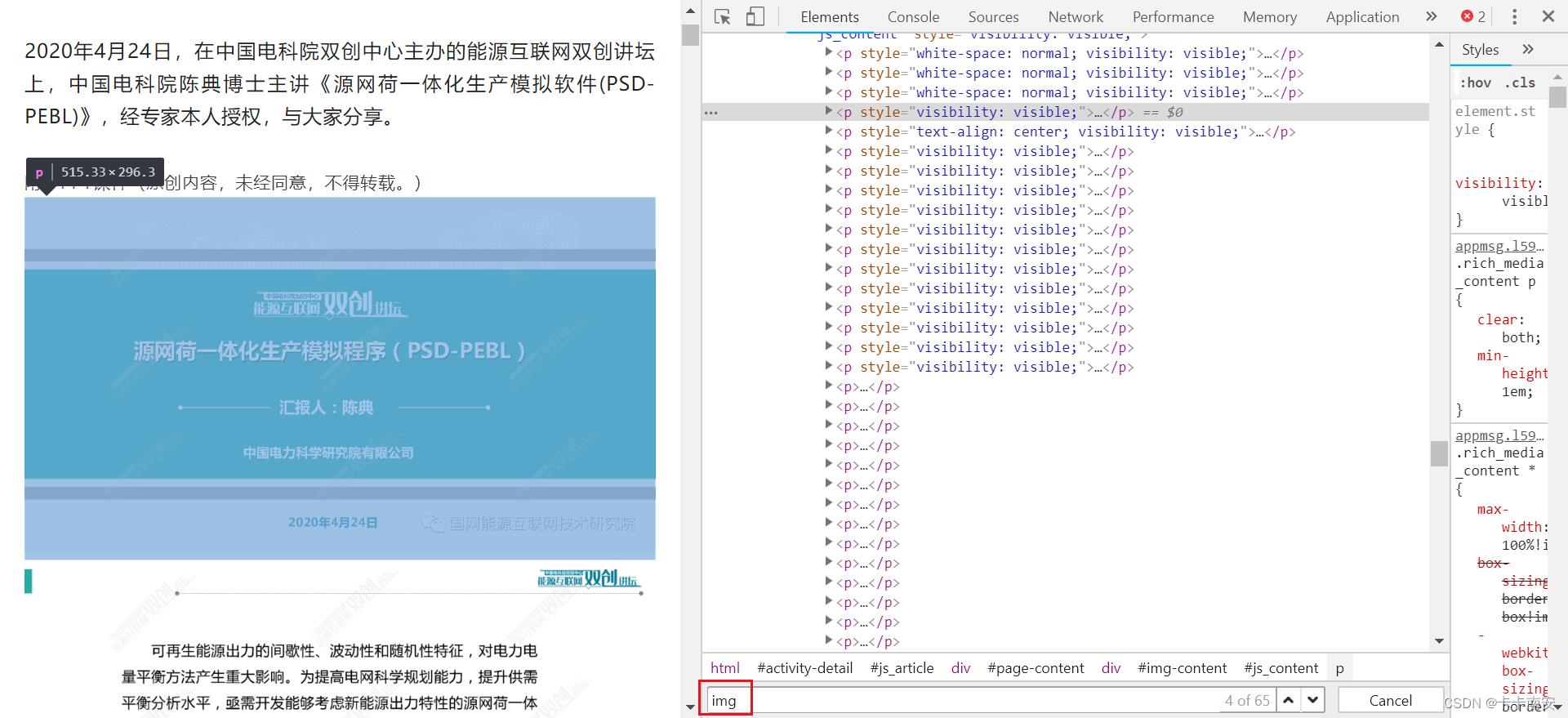
展开Html语句,可以看到里面包含了图片的链接:
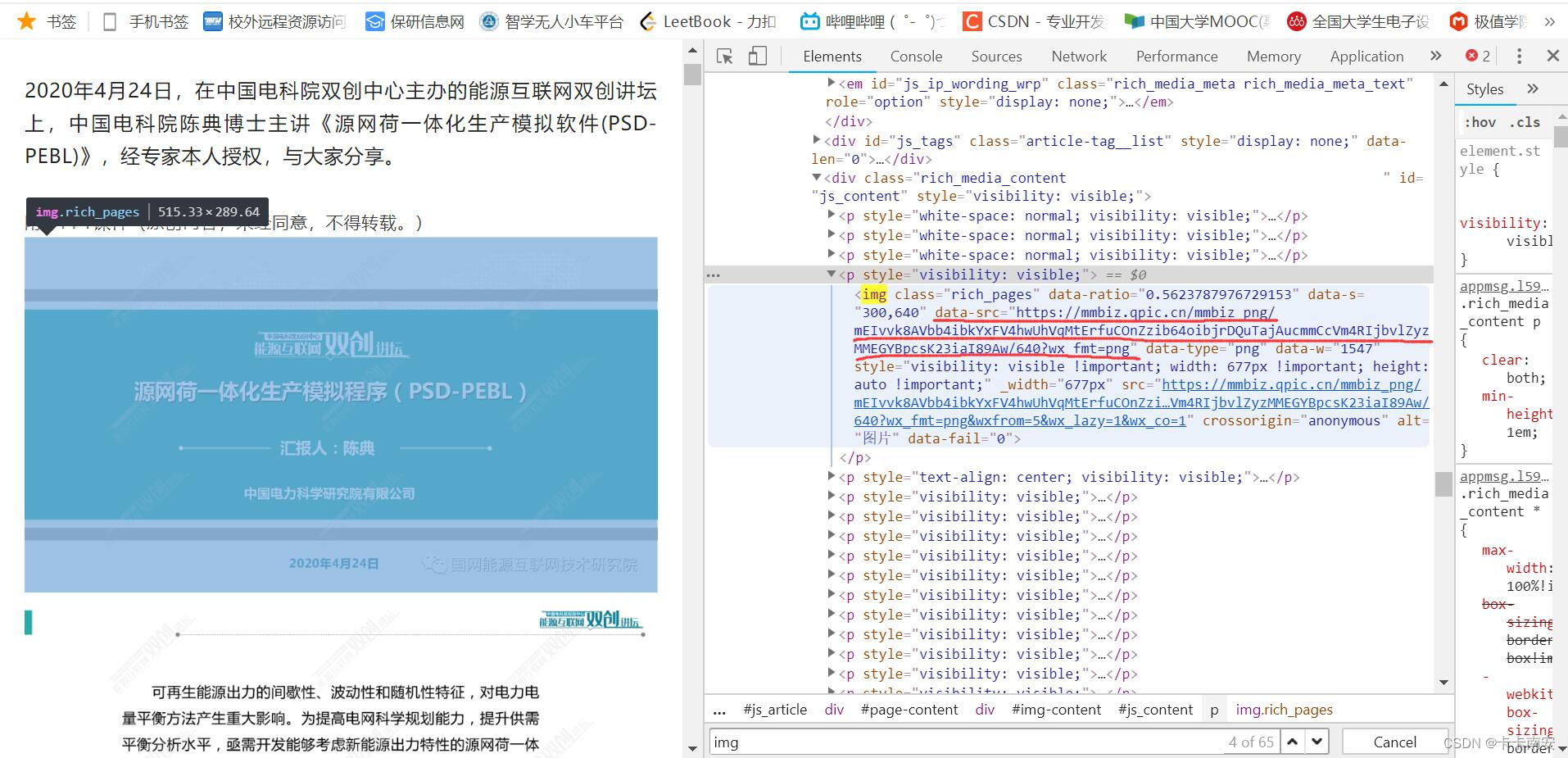
其他图片链接的位置同理,可以发现他们都有一个共同点,那就是图片的链接都出现在data-src=和 data-type=之间,利用正则表达式即可获取所有图片的链接。
三. 批量下载图片
这部分比较简单,只需要循环访问图片链接,下载后保存到本地即可。
完整程序如下所示:
# -*- coding: utf-8 -*-
import re
import requests
from urllib import error
from bs4 import BeautifulSoup
import os
file = ''
List = []
#爬取图片链接
def Find(url, A):
global List
print('正在检测图片总数,请稍等.....')
s = 0
try:
Result = A.get(url, timeout=7, allow_redirects=False)
except BaseException:
print("error");
else:
result = Result.text
pic_url = re.findall('data-src="(.*?)" data-type', result) # 先利用正则表达式找到图片url
s += len(pic_url)
if len(pic_url) == 0:
print("没读到")
else:
List.append(pic_url)
return s
#下载图片
def dowmloadPicture():
num = 1
for each in List[0]:
print('正在下载第' + str(num) + '张图片,图片地址:' + str(each))
try:
if each is not None:
pic = requests.get(each, timeout=7)
else:
continue
except BaseException:
print('错误,当前图片无法下载')
continue
else:
if len(pic.content) < 200:
continue
string = file + r'\\\\' + str(num) + '.jpg'
fp = open(string, 'wb')
fp.write(pic.content)
fp.close()
num+=1
if __name__ == '__main__': # 主函数入口
headers =
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Upgrade-Insecure-Requests': '1'
A = requests.Session()
A.headers = headers
url = 'https://mp.weixin.qq.com/s/An0nKnwlml9gvyUDyT65zQ'
total = Find(url, A)
print('经过检测图片共有%d张' % (total))
file = input('请建立一个存储图片的文件夹,输入文件夹名称即可: ')
y = os.path.exists(file)
if y == 1:
print('该文件已存在,请重新输入')
file = input('请建立一个存储图片的文件夹,)输入文件夹名称即可: ')
os.mkdir(file)
else:
os.mkdir(file)
dowmloadPicture()
print('当前爬取结束,感谢使用')
程序使用时仅需要修改网址链接即可,必要时需要修改正则表达式。
python3下爬取网页上的图片的爬虫程序
1 import urllib.request 2 import re 3 #py抓取页面图片并保存到本地 4 5 #获取页面信息 6 def getHtml(url): 7 html = urllib.request.urlopen(url).read() 8 return html 9 10 #通过正则获取图片 11 def getImg(html): 12 reg = ‘src="(.+?.jpg)" pic_ext‘ 13 imgre = re.compile(reg) 14 imglist = re.findall(imgre,html) 15 # print(imglist) 16 return imglist 17 18 html = getHtml("http://*****") 19 20 list=getImg(html.decode()) 21 22 #循环把图片存到本地 23 x = 0 24 for imgurl in list: 25 print(x) 26 urllib.request.urlretrieve(imgurl,‘d:\%s.jpg‘% x) 27 x+=1 28 29 print("done")
指定网页获取图片并保存到AWS_s3
1 import boto3 2 import urllib.request 3 4 5 def lambda_handler(request, context): 6 #download_url = "https://s3.amazonaws.com/testforcustomerservice/192x192.png" 7 download_url = "https://gss2.bdstatic.com/-fo3dSag_xI4khGkpoWK1HF6hhy/baike/s%3D220/sign=3707d191fa03738dda4a0b20831bb073/279759ee3d6d55fb3cfdd81761224f4a20a4ddcc.jpg" 8 list = download_url.split(‘/‘) 9 upload_key = list[len(list)-1] 10 response = urllib.request.urlopen(url=download_url) 11 context = response.read() 12 #print(context) 13 bucket = "testforcustomerservice" 14 s3 = boto3.resource("s3") 15 file_obj = s3.Bucket(bucket).put_object(Key=upload_key, Body=context) 16 print(file_obj) 17 response = { 18 "url": "https://s3.amazonaws.com/testforcustomerservice/"+upload_key 19 } 20 return response
以上是关于Python爬虫爬取网页上的所有图片的主要内容,如果未能解决你的问题,请参考以下文章