基于OpenSeq2Seq的NLP与语音识别混合精度训练
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于OpenSeq2Seq的NLP与语音识别混合精度训练相关的知识,希望对你有一定的参考价值。
基于OpenSeq2Seq的NLP与语音识别混合精度训练
Mixed Precision Training for NLP and Speech Recognition with OpenSeq2Seq
迄今为止,神经网络的成功建立在更大的数据集、更好的理论模型和缩短的训练时间上。特别是顺序模型,可以从中受益更多。为此,我们创建了OpenSeq2Seq——一个开源的、基于TensorFlow的工具包。OpenSeq2Seq支持一系列现成的模型,其特点是多GPU和混合精度训练,与其他开源框架相比,大大缩短了训练时间。机器翻译和语音识别任务的基准测试表明,根据模型和训练超参数,使用OpenSeq2Seq构建的模型在1.5-3倍更快的训练时间下提供最新的性能。
OpenSeq2Seq包含了大量的对话式人工智能示例,这些示例都经过了混合FP16/FP32精度的训练:
- Natural Language Translation: GNMT, Transformer, ConvS2S
- Speech Recognition: Wave2Letter, DeepSpeech2
- Speech Synthesis: Tacotron 2
- Language Modeling and transfer learning for NLP tasks
Overview of OpenSeq2Seq
自2014年引入序列到序列范式(Cho等人,2014[1])以来,其受欢迎程度持续增长。序列到序列模型通常由编码器和解码器组成,可用于各种任务。规范的序列到序列模型对于编码器和解码器都有RNN,并且适用于机器翻译、文本摘要和对话框系统等任务,如图1所示。然而,序列模型也可以用于其他任务。例如,用于解决情感分析任务的神经网络可以由RNN编码器和softmax线性解码器组成。图像分类任务可能需要卷积编码器和softmax线性解码器。甚至编码器和解码器的数量也可以改变。例如,将英语翻译为多种语言的模型可能有一个编码器和多个解码器。

Figure 1: Sequence-to-sequence model for a dialog system
已经有许多工具包使用序列到序列范式来构造和训练模型来解决各种任务。一些最流行的包括Tensor2Tensor[2]、seq2seq[3]、OpenNMT[4]和fairseq[5]。前两个基于TensorFlow,后两个基于PyTorch。这些框架采用模块化设计,许多现成的模块可以组装成理想的模型,降低了想要使用顺序到顺序模型来解决问题的人的进入壁垒,并有助于推动人工智能研究和生产的进展。
OpenSeq2Seq建立在这些现有框架的基础上,具有额外的特性,以减少训练时间,使API更易于使用。我们之所以选择使用TensorFlow,是因为TensorFlow已经成为应用最广泛的机器学习框架,并为机器学习模型的生产提供了一条巨大的管道。我们创建OpenSeq2Seq的目的如下:
模块化架构,允许从可用组件轻松组装新模型
支持混合精度训练[6],使用NVIDIA Volta GPUs中引入的张量核
快速,简单易用,基于Horovod的分布式训练和数据并行,支持多GPU和多节点
Modular architecture
OpenSeq2Seq模型由Python配置文件描述,该文件定义要使用的数据读取器、编码器、解码器、优化器、损失函数、正则化、超参数的类型。例如,为机器翻译创建GNMT[7]模型的配置文件可能如下所示:
base_params = {
"batch_size_per_gpu": 32,
"optimizer": "Adam",
"lr_policy": exp_decay,
"lr_policy_params": {
"learning_rate": 0.0008,
...
},
"encoder": GNMTLikeEncoderWithEmbedding,
"encoder_params": {
"core_cell": tf.nn.rnn_cell.LSTMCell,
...
"encoder_layers": 7,
"src_emb_size": 1024,
},
"decoder": RNNDecoderWithAttention,
"decoder_params": {
"core_cell": tf.nn.rnn_cell.LSTMCell,
...
},
"loss": BasicSequenceLoss,
...
}
目前,OpenSeq2Seq使用配置文件为机器翻译(GNMT、ConvS2S、Transformer)、语音识别(Deep speech 2、Wav2Letter)、语音合成(Tacotron 2)、图像分类(ResNets、AlexNet)、语言建模和情感分析传输学习创建模型。它们存储在example_configs文件夹中。您可以使用工具箱中提供的模块创建一个新的模型配置,其中包含TensorFlow中的基本知识。编写新模块或修改现有模块以满足您的特定需求也很简单。
OpenSeq2Seq还提供了各种可以处理流行数据集的数据层,包括用于机器翻译的WMT、用于语言建模的WikiText-103、用于语音识别的LibriSpeech、用于情绪分析的SST和IMDB、用于语音合成的LJ语音数据集等等。
Mixed-precision training
神经网络训练的速度取决于三个主要硬件因素:计算吞吐量、带宽和GPU-DRAM大小。如今,大型神经网络拥有数千万甚至数亿个参数。它们需要大量的算术和内存资源才能在合理的时间范围内进行训练。加速训练需要现代的深度学习硬件来满足这些不断增长的资源需求。
Volta和Turing GPU上提供的张量核提供了训练大型神经网络所需的性能。它允许在单精度浮点(FP32)和半精度浮点(FP16)中进行矩阵乘法,即神经网络训练和推理的核心操作,如图2所示。为了训练,张量核心提供高达12倍的峰值TFLOPS相比,在P100的标准FP32操作。为了便于推断,张量核提供了高达6倍的峰值TFLOPS,相比于P100上的标准FP16操作[8]。
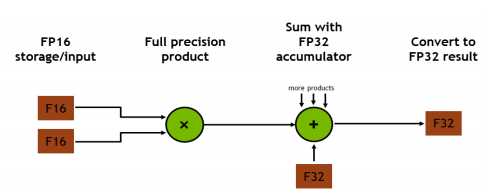
Figure 2: Arithmetic is done in FP16 and accumulated in FP32
利用张量核的计算能力,需要使用混合精度算法训练模型。OpenSeq2Seq提供了一个简单的接口。当启用混合精度训练时,数学运算在FP16中完成,但结果在FP32中累积,如图3所示。结果在存储到内存之前被转换成FP16。FP16提高了计算吞吐量,因为当前一代gpu为降低精度的数学运算提供了更高的吞吐量。除了提高速度外,混合精度还减少了训练所需的内存量。这允许用户增加批次或模型的大小,进而增加模型的学习能力并减少训练时间。
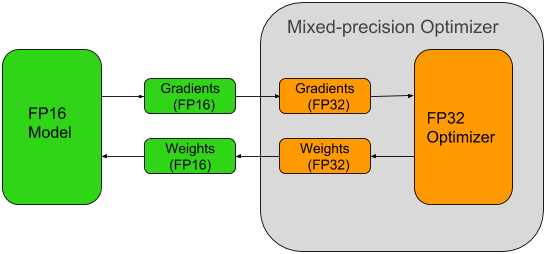
Figure 3: Mixed-precision training iteration for a layer
为了防止由于精度降低而造成的精度损失,使用了两种技术:
自动缩放损失功能,防止梯度在反向传播期间下溢和溢出。
维护一份FP32权重副本,以便在每个优化器步骤之后累积梯度。
利用这些技术,混合精度训练可以在不损失模型精度或修改超参数的情况下显著加快训练时间。与仅使用FP32相比,在Volta GPU上使用混合精度时,OpenSeq2Seq型号(如Transformer、ConvS2S和Wave2Letter)的端到端加速比为1.5-3倍。
要在OpenSeq2Seq中启用混合精度训练,只需在配置文件中将model_params的dtype参数更改为“mixed”。您可能需要通过将model_params中的loss_scale参数设置为所需的数字,或者通过将loss_scaling参数设置为“Backoff”或“LogMax”来动态启用损耗缩放。您可能需要注意输入和输出的类型,以避免某些计算类型的不匹配类型。不需要修改体系结构或超级参数。
base_params = {
...
"dtype": "mixed",
# enabling static or dynamic loss scaling might improve model convergence
# "loss_scale": 10.0,
# "loss_scaling": "Backoff",
...
}
Distributed training with Horovod
OpenSeq2Seq利用了两种主要的分布式训练方法:
- Parameter server-based approach (used in native TensorFlow towers)
o
§ Builds a separate graph for each GPU
§ Sometimes faster for 2 to 4 GPUs
o Uses MPI and NVIDIA’s NCCL library to utilize NVLINK between GPUs
o Significantly faster for 8 to 16 GPUs
o Fast multi-node training
要使用第一种方法,只需将配置参数num_gpus更新为要使用的gpu数量。
您需要安装Horovod for GPU、MPI和NCCL才能使用Horovod(可以找到Horovod for GPU安装的详细说明)。之后,只需在配置文件中将参数“use_horovod”设置为True并执行run.py使用mpirun或mpiexec编写脚本。例如:
mpiexec --allow-run-as-root -np <num_gpus> python run.py --config_file=... --mode=train_eval --use_horovod=True --enable_logs
Horovod还允许您启用多节点执行。用户唯一需要做的是定义数据“分割”,仅用于评估和推断。否则,用户为多个/单个GPU或Horovod/塔式机箱编写完全相同的代码。
与Tensorflow原生塔式方法相比,Horovod为多GPU训练提供了更好的缩放效果。具体的缩放取决于许多因素,如数据类型、模型大小、计算量。例如,Transformer模型的比例因子为0.7,而ConvS2S的比例因子接近0.875,如图4所示。
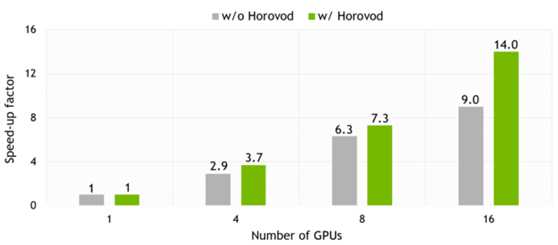
Figure 4: Multi-GPU speed-up for ConvS2S
在下一部分中,我们将介绍神经机器翻译、语音识别和语音合成等任务的一些流行模型的混合精度训练结果。
Models
Machine Translation
目前OpenSeq2Seq有三种机器翻译模型:
所有模型均在WMT英德数据集上接受过训练:
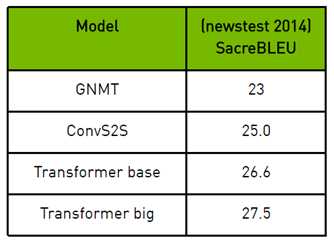
这些模型的混合精度训练比FP32快1.5-2.7倍[10]。
Speech Recognition
OpenSeq2Seq有两个用于语音识别任务的模型:
- Wave2Letter+ (fully convolutional model based on Facebook Wav2Letter)
- DeepSpeech2 (recurrent model originally proposed by Baidu)
这些模型仅在LibriSpeech数据集上训练(约1k小时):
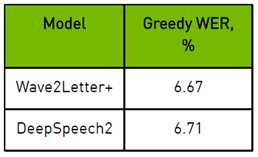
WER(单词错误率)是在LibriSpeech数据集的dev clean部分使用贪婪解码器(即在每个时间步取最可能的字符,而不需要任何额外的语言模型重新评分)来测量的。
与FP32相比,OpenSeq2Seq中的语音识别模型在混合精度模式下的训练速度提高了3.6倍。
Speech Synthesis
OpenSeq2Seq支持Tacotron 2和Griffin Lim进行语音合成。该模型当前支持LJSpeech数据集。我们计划另外支持MAILABS数据集。两个数据集上的音频示例可以在此处找到。 与FP32相比,Tacotron 2在混合精度模式下的训练速度快1.6倍。
Conclusion
OpenSeq2Seq是一个基于TensorFlow的工具包,它建立在当前可用的序列到序列工具包的优势之上,具有额外的功能,可以加速3倍的大型神经网络训练。它允许用户切换到混合精度训练,利用Tensor核中可用的计算能力单标签。它结合了Horovod库以减少多GPU和多节点系统的训练时间。
目前在语音识别、机器翻译、语音合成、语言建模、情感分析等方面拥有一整套最先进的模型。它的模块化架构允许快速开发出现有模块之外的新模型。代码库是开源的
以上是关于基于OpenSeq2Seq的NLP与语音识别混合精度训练的主要内容,如果未能解决你的问题,请参考以下文章
入门NLP实现语音识别和语音合成,用这个开源工具SoEasy | 英伟达NLP公开课