NLP自然语言处理学习笔记语音识别
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP自然语言处理学习笔记语音识别相关的知识,希望对你有一定的参考价值。
前言
本笔记参考的课程是李宏毅老师的自然语言处理
课程Link:https://aistudio.baidu.com/aistudio/education/lessonvideo/1000466
Token

Token是模型的输出形式,以上图语音识别为例,输出的text包含了N个Token,每个Token有V种符号
目前,Token主要有下面五种具体形式:
-
Phoneme
音标,即语言的发音。
如果想要换算成文本,需要有个Lexicon(词典表),例如cat ⟶ K AE T -
Grapheme
字母
最直接的形式,总数为26个字母+空格+其它符号,不需要词典表 -
Word
词组
也是比较直观的形式,存在的问题是词组的总量太多,比如英文常用词组数量>100K -
Turkish
介于Word和Grapheme之中的词元,比如英文里的词根词缀 -
Bytes
常用编码,比如UTF-8,好处是数量V大小固定为256,并且可以用同样的形式表示符号和不同语言
根据统计,目前用的最多的是Grapheme和Phoneme

Acoustic Feature
上面的Token考虑的是输出部分,现在考虑输入部分的形式,即声学特征(Acoustic Feature)
Acoustic Feature主要有下面4种形式:

-
Waveform
最原始的声波信号
存在的问题是不同语音可能会存在类似的信号 -
Spectrogram
频谱图,声波信号进行DFT变换得到
在频域中,可以对不同语言的特征有较好的区分 -
filter bank
滤波器组
将频谱图通过不同的滤波器,进一步提取特征 -
MFCC
梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients)
filter bank的结果取log之后再用DCT获得MFCC
根据统计,目前用的最多的是filter bank

Models
上面解决了输入和输出两个部分,下面进入到中间的模型(Models)部分。
在自然语言处理中,模型的架构基本一致,分成三个部分:编码器(Encoder)、上下文(Context)、解码器(Decoder)
主要模型有下面6种:
- Listen, Attend, and Spell (LAS)
- Connectionist Temporal Classification (CTC)
- RNA
- RNN Transducer (RNN-T)
- Neural Transducer
- Monotonic Chunkwise Attention (MoChA)
Listen, Attend, and Spell (LAS)
LAS分成Listen, Attend,Spell三个部分,其中Listen对应编码器,Spell对应解码器,Attend是在Context中引入了注意力(Attend)机制。
Listen
首先看Listen编码器部分,结构如下图所示:

输入输出数量相同,中间的Encoder可以使用各种神经网络。
比如,使用RNN:

也可以使用CNN,这里的CNN和图像领域的卷积神经网络比较类似:

也可以使用多个CNN,或者CNN+RNN的组合形式
另外,输入和输出个数一样,参数可能会太多,并且效果不一定很好。因此,也可以引入图像领域中下采样(Down Sampling)的方式
如图所示,下面展示了四种下采样的思路。

Pyramid RNN类似池化的思想,将两个相邻融合成一个进行输出。
Pooling over time是间隔得舍弃进行输出。
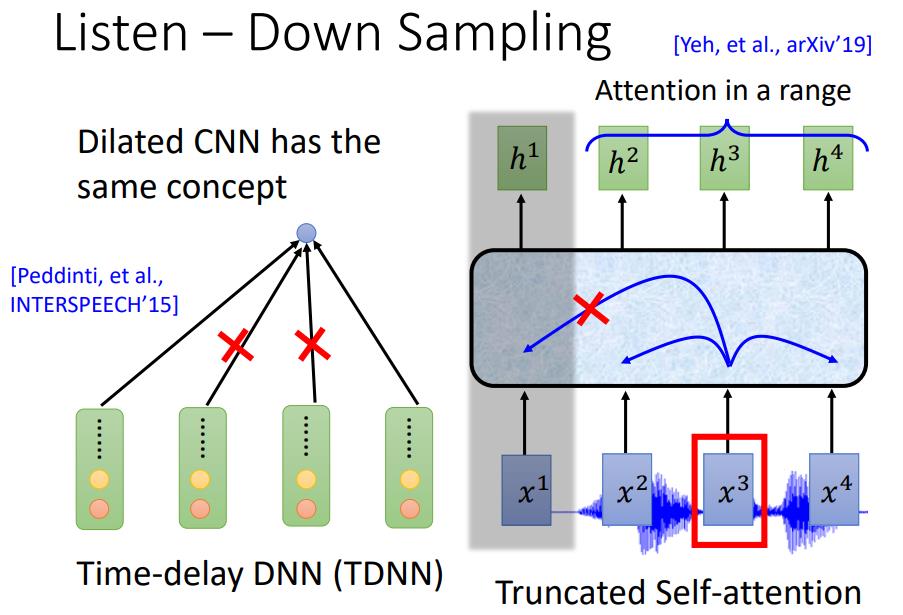
TDNN是类似Dropout的思想,将DNN输出的一部分选择性舍弃
Truncated Self-attention是通过一定时间范围内,选取范围内的进行输出。
Attention
有了输出h向量之后,需要引入注意力机制,将其转换成Context向量。
Attention机制有不同的方法,下面是两种方法:

如图所示,第一种是Dot-product Attention。
图中的z0是后续解码器中的一个状态,输入h和z,然后进行指数变换后再点乘,最后用一个函数来进行输出a
这个过程就是匹配(match)的过程,用来匹配相似度,相似度越高,则a越大

另一种方法是Additive Attention。
即输出a的方式发生了变化,先进行指数变换,再相加,利用函数输出a。

这里的a就是注意力权重,每个h有了a之后,context就可以用权重相乘的方式计算出来。
这里初学可能会产生一个疑问,为什么要引入注意力机制?除了提升效率之外,更主要的是语音识别的场景中,翻译的第一个字的语义可能并不是第一个声音产生的,比如英文和中文的语序不一样。使用注意力就可以解决这个问题。
Spell
有了c向量之后,下面就可以进入到解码环节。
这里的解码器和编码器一样,仍然可以采用多种网络模型,这里以RNN为例。

如图所示,将z0和c0输入到隐藏状态z1,输出得到各个Token的概率,选取概率最大的toekns作为输出,因此得到字母c。

循环上述过程,可以得到预测的单词cat,最后<EOS>表示预测终止。
注意,这和循环神经网络略有区别的是,上一时刻输出的结果同时要输入到下一时刻的隐藏状态。
Training
上面是整个模型预测过程,下面将进入到模型的训练。

该网络属于有监督模型,因此需要Token的标签,如图所示,这里的C就是标签,注意这是独热编码(One-hot)形式,输出的token和这个标签做交叉熵损失,让损失尽可能小,就可以让输出逐渐趋近于标签。

上面是第一个状态z0的训练,对于下一个状态,需要把前面的标签(ground truth)同时输入进去训练,这个步骤也叫做Teacher Forcing。
前面在解读Spell时提到,考虑到语义间的相关性,下一个输入中需要包含前面的输出。这里为什么不选择输入前面的输出内容?下图作了解释:

对于z1状态,它正确的训练方式应该是,看到c,输出a,如果看到的不是c,却输出a,那之前的训练都白费了!这就是为什么需要使用Teacher Forcing。
Work
下面需要来看看这个模型是否有效(work)

表中的指标为错误率,研究表明,训练2000小时,LAS的效果还不如传统模型(CLDNN-HMM),错误率几乎比后者高一半,但在训练12500小时后,LAS的错误率超越了传统模型,并且,相比于其它模型结构,LAS把所有内容融合成一个整体的大网络,模型大小仅有0.4GB。
综上,LAS还是有效果的!
Limitation
任何模型都有局限性(Limitation),LAS的问题在于,需要听完整段话才能进行识别翻译,这就无法胜任同声翻译这样的场景。
Connectionist Temporal Classification (CTC)
Structure
既然LAS无法实现实时性,那么一个朴素的想法就是,能否根据单个h,直接输出一个Token。CTC就是这么干的。

如图所示,CTC没有采用注意力机制,而是直接将输出的h单独输入进一个模型W,之后做Softmax来输出各Token的分布,取最大值输出。
但是,并不是每一个h都有语义信息。因此,需要在输出的Token中引入一个空对象,因此Token集的大小为V+1。
值得注意的是,很多情况下,两个相邻的语音向量表达同一个意思,因此CTC对连续相同的输出进行剔除,同时,最终的输出值会把空对象去除。规则举例如下:

Training
对这个模型进行训练,就会产生一个额外的问题。比如,我拿到一段语音信息,它的label是好棒,那么将如何对四个输出进行合理的分配空对象或连续情况。CTC的做法很粗暴,既然无法搞清楚,那就罗列所有可能的情况,所有标签全部塞进去。

Work
实验表明,CTC确实有一定的效果,但从表中的数据看,CTC似乎并不显得非常优秀。

RNA
由于CTC是每个输出都是独立的,因此即使除去空对象,输出很有可能还是会产生连续的Token,像口吃一样,一个朴素的想法是能不能把前面的输出再输入到下一时刻。
RNA就做了这点改进。

但是,这样做仍然会产生的一个问题是,有的音节对应的是两个Token,比如“th”,这样就比较难输出,RNN-T就做了改进,用来解决这一问题。
RNN-T

如图所示,RNN-T在RNA的基础上,将一个ht复制多份进行输出,直到输出一个空对象表示输出完成。
(注:图中箭头右侧是RNN-T的部分结构)。
为什么说是部分结构,因为真正的RNN-T又在上面加了一个Language Model:

这个Language Model主要是用来方便训练,因为和CTC的训练问题一样,并没有严格划分的合适标签,而这里的Language Model输出会忽略空对象,这样就可以和标签做交叉熵损失。
Neural Transducer
CTC、RNA、RNN-T都没有用到注意力机制,而LAS用到了。一个朴素的想法是,既然注意力机制有效果,为什么不用呢?于是,Neural Transducer就在RNN-T的基础上,加入了注意力机制。

如图所示,Neural Transducer规定一个窗口window,将窗口内的h进行注意力处理,从而选取部分进入到Decoder之中。这个窗口的长度是一个人为给定的超参数。
窗口的长度和模型的效果对应关系如图所示。

MoChA:Monotonic Chunkwise Attention
Neural Transducer创新性地提出了一个窗口,那么,这个窗口长度是否可以动态变化呢?MoChA就注意到了这一点。

如图所示,MoCha在Neural Transducer的基础上,单独设置了一个判别器,输入状态z和当前的h,输出yes和no,yes表示窗口在这里截止。这张图可能并不太清楚,看原视频的动态效果比较有助于理解。
summary
下面对各模型进行一个简单概况小结:
- LAS: 就是 seq2seq
- CTC: decoder 是 linear classifier 的 seq2seq
- RNA: 输入一个东西就要输出一个东西的seq2seq
- RNN-T: 输入一个东西可以输出出多个东西的 seq2seq
- Neural Transducer: 每次输入一个window的 RNN-T
- MoCha: window 移动伸缩自如的 Neural Transducer
Language Model
在这一节需要引入一个新的概念:Language Model
在之前提到的Models,以LAS为例,所做的工作基本可以用下面这个式子来进行表示。即输入X,输出概率值最大的Y作为结果。

但是,能够能进一步优化?

借鉴传统语音识别模型(HMM)的计算公式,在当前的输出Y后乘上一个P(Y)的Token sequence的概率。而这个P(Y)的数值就要通过Language Model来计算得到。
N-gram
N-gram是一种比较简单的计算方式。
以2-gram为例,要计算右上角的句子的整体概率,就要计算每个单词在前一个单词基础上的概率,然后进行乘积。
而每一部分的概率可以用下面的公式进行计算得到,以P(beach|nice)为例,其计算方式为(nice beach)出现的数量/nice的数量。
同理可以扩展到3-gram,4-gram …

然而,这样做可能存在的一个问题是,由于语料库的数量不完全,有些没出现过的gram概率为0。比如下图中的狗会跳(jumped | the,dog)因为没出现过概率为0,变成了不可能事件,显然与事实不符。于是就使用一个很小的数字来替代0,这就是平滑操作。

Continuous LM
Continuous LM的方式是借鉴到了推荐系统中的一个算法Matrix Factorization。
以下图为例,B的超电磁炮数值不确定,但可以根据A喜欢御坂美琴和超电磁炮,以及B喜欢御坂美琴的信息来推测B喜欢超电磁炮。

Continuous LM就是将不同的history和Vocabulary类似地进行表示,通过最小化损失L的方式,利用已知的信息来推算出合适的h和v向量。

可以进一步构建网络,来替换表格这种形式。

这里简单使用全连接网络,即NN-based LM,训练过程如下图所示。
给出第一个单词,输出下一个单词,不断往后,直到句子结束。

当然,这个NN结构也可以替换成更复杂一些的RNN

Fusion
现在Models和Language Model都准备好了,下面就用三种方式将他们融合(Fusion)。
Shallow Fusion
Shallow Fusion的思路比较简单,即将两个模型的输出取对数之后相加,如图中紫色方框,公式中的
λ
\\lambda
λ用来控制两个模型的相加的权重。

Deep Fusion
Deep Fusion的结构在下图中右侧位置。它并不是将两个模型的输出直接相加,而是将两个模型的隐藏层输入到一个新的神经网络中进行训练。这会导致的一个问题是,假如更换了Language Model,那个就需要重新进行训练。
为什么有时候需要更换Language Model呢?因为LM用来统计的是词典中各词的分布概率,在不同领域中,相同的单词可能会倾向不同的语义,这就需要更换LM来实现更精准的识别/翻译。
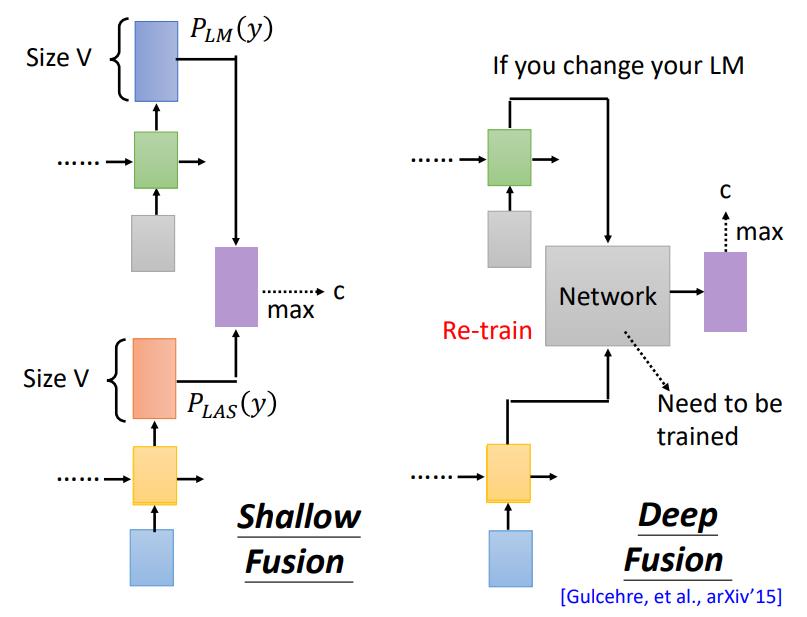
为了解决这一问题,下面就是对Deep Fusion进行进一步改造,在LM中,并不是直接输出隐藏层结果,而是输出下一层在SoftMax前的结果,这样的好处是更换LM后无需再次训练。

Cold Fusion
Cold Fusion结构上和Deep Fusion一模一样,区别在于Cold Fusion的LM在正式训练之前已经单独完成训练,个人猜测这个名称中Cold的意思就是将LM这样的变量提前变成常量。这样做的好处是可以加快LAS的训练速度,但同时问题是不能随便更换LM,否则要重复训练。

以上是关于NLP自然语言处理学习笔记语音识别的主要内容,如果未能解决你的问题,请参考以下文章