NLP自然语言处理学习笔记语音合成
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP自然语言处理学习笔记语音合成相关的知识,希望对你有一定的参考价值。
前言
本笔记参考的课程是李宏毅老师的自然语言处理
课程Link:https://aistudio.baidu.com/aistudio/education/lessonvideo/1000466
TTS
语音合成(TTS)指的是将文字信息转换成语音信息,这在各种自媒体工具上非常常见。
TTS before End-to-end
在端到端的模型出现之前,已经有人将深度学习应用在了语音合成之中。
下图中展示了Deep Voice初代结构,它用了四个模型。
首先,它将输入的文本信息(text)输入到Grapheme-to-phoneme转化成音位(phoneme),然后分成三部分,第一部分输入到Duration Prediction中,输出各音位的持续时间。第二部分输出到Fundamental Frequency Prediction中,输出各音位的频率,即模拟人发声时声带振动的频率,其中X表示不需要振动。最终,再将第三部分即原因素和前两部分一起输入到Audio Synthesis中,输出最终得到的语音(audio)。

Tacotron
Tacotron是17年提出的端到端的语音合成模型,其中Taco意思是墨西哥鸡肉卷,因为论文作者喜欢tacos,就这么命名。。
Tacotron的模型结构如下图所示:

Tacotron中包含经典的Encoder、Attention、Decoder,后续又添加了一个后处理的CBHG和Vocoder,输出语音信号。
Encoder
首先看第一部分Encoder。
首先,输入文本,通过embeddings编码成向量,经过一个Pre-net之后输入到CBHG结构,下图中左侧展示了CBHG的具体组成方式,即3个卷积层,1个池化层,1个残差结构,最后通过GRU输出。
不过这个CBHG结构也不是一成不变的,比如图中下侧展示了Tacotronv2版本的CBHG结构,只有3个卷积层和一个LSTM做输出。

Attention
Attention的机制大概和语音识别里的类似,这里只给了Attention效果的评估参考。纵轴是Encoder steps,横轴是Decoder steps,当Attention出现明显的对角线时,说明训练的效果好。个人觉得,也可以这样直观理解:Encoder和Decoder在相同的时间步中聚焦于同一个信号,说明注意力集中效果好,否则注意力涣散,效果不好。

Decoder
Encoder输出的context vector输入到Decoder,Decoder具有重复类似的结构,每个重复结构都包含一个Pre-net和两个RNN,每个结构输出是多个spectrogram(spectrogram是waveform的频谱图,在语音识别里有提到),其中,选取最后一个spectrogram作为下一层结构的输入。
注意,在第二个RNN结构中,还需要输出一个信号来判断句子是否结束,如果结束,则不再进行下一层的输出。
另外值得注意的是,在Pre-net中,必须有dropout的操作,如果没有dropout效果会很差,这里的dropout就相当于随机采样。

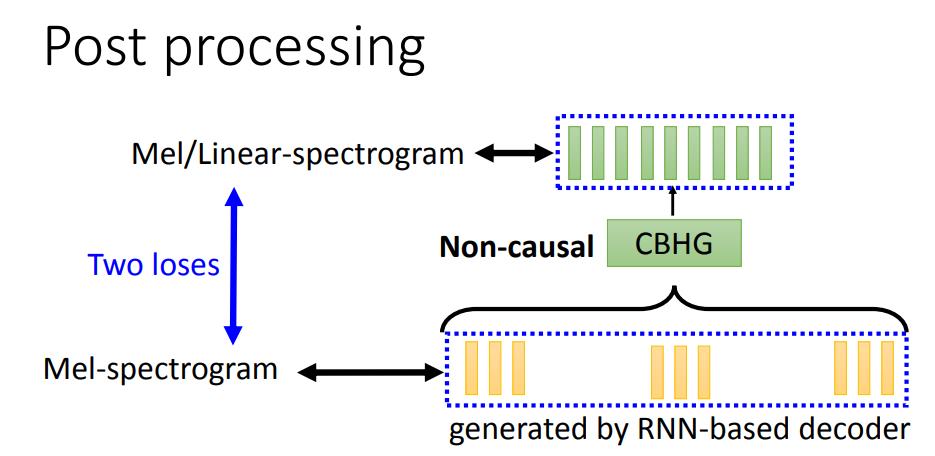
Post processing
在Decoder之后,进入到后处理(Post processing),后处理比较简单,将Decoder输出的spectrogram再经过一个CBHG结构输出spectrogram,为什么要再这样处理一下呢?这是因为RNN是根据前面的输入产生输出,是一个顺序结构,如果后面想要进行修改就没机会了。Post processing就是给模型在看过整个句子的情况下,再有一次修改输出的机会。
这里要计算两个Loss,在Post processing处理前后的向量都要和groundtruth做loss。
Vocoder
Vocoder就是将spectrogram转换成语音信号,这里具体结构不作细述。
第一代Tacotron使用的Vocoder是Griffin-Lim
第二代Tacotron使用的Vocoder是Wavnet

Work
下面通过具体的指标来看看Tacotron的效果。这里的指标采用的是mean opinion score,即让一群人听合成出的声音来进行评分,总分5分,然后取平均值作为MOS。
从下图数据中,可以发现Tacotron1代的评分为3.82,还不如其它方法,但在Tacotron2代,它的评分达到了4.526,基本接近了Ground truth的水平。

Beyond Tacotron
在这一节,将讨论Tacotron之外的一些问题。
Mispronunciation
通过前面对Tacotron的了解,大致知道Tacotron产生的语音是通过模型进行合成的,这就难免会造成一些发音错误(mispronunciation)。
一种解决方式是构造一个词典(lexicon),这样Tacotron就可以根据词典查询对应的发音。

如果出现了一些词典中没有的新词汇,Tacotron就根据自己的猜测进行发音,如果发音正确,将词典进行扩充。
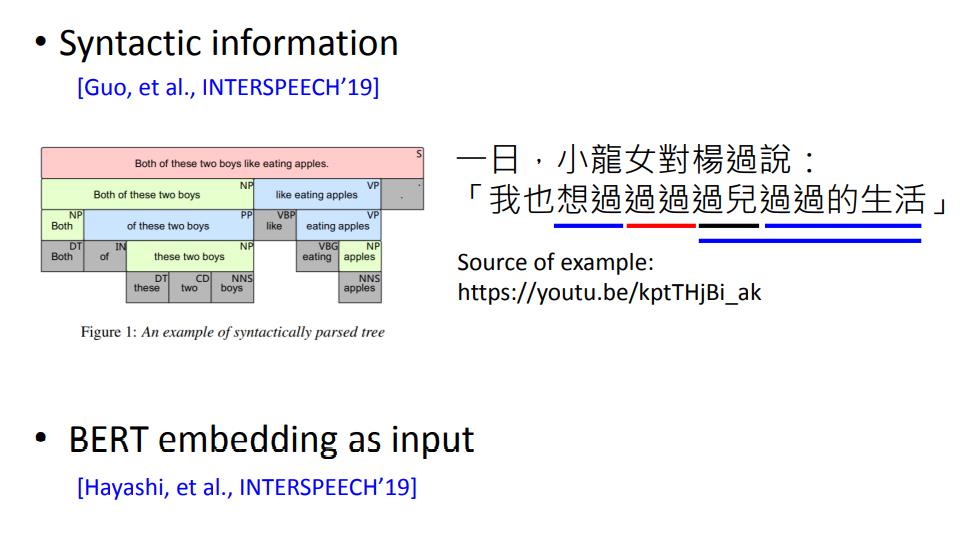
More information for Encoder
关于Encoder也有优化的地方。比如,遇到下面这种语法比较复杂的句子,输入时可以对其进行语序划分。比如Syntactic information的方法,以及BERT embedding方法(这个后续会继续深入学习)。
Attention
关于Attention,也有优化的地方,这里简单描述三种优化方式。
Guided Attention
前面提到过Attention最好是一条清晰的对角线。
Guided Attention的思路是给这条对角线限定蓝色区域的范围,如果Attention进入到红色区域,就会收到相应惩罚。

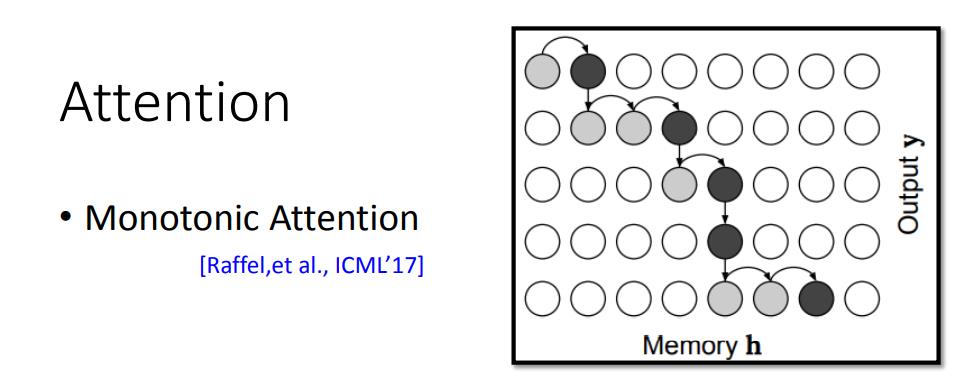
Monotonic Attention
Monotonic Attention的思路是给Attention加了一个限制,即要求Attention必须要从左向右,如图所示,这样限制出来就近似会接近对角线的情况。
Location-aware attention
Location-aware attention的思路是计算attention是查看上一时刻附近的attention,比如下图中要计算a1,2,就会选取a0,1 a0,2 a0,3的attention参与计算。

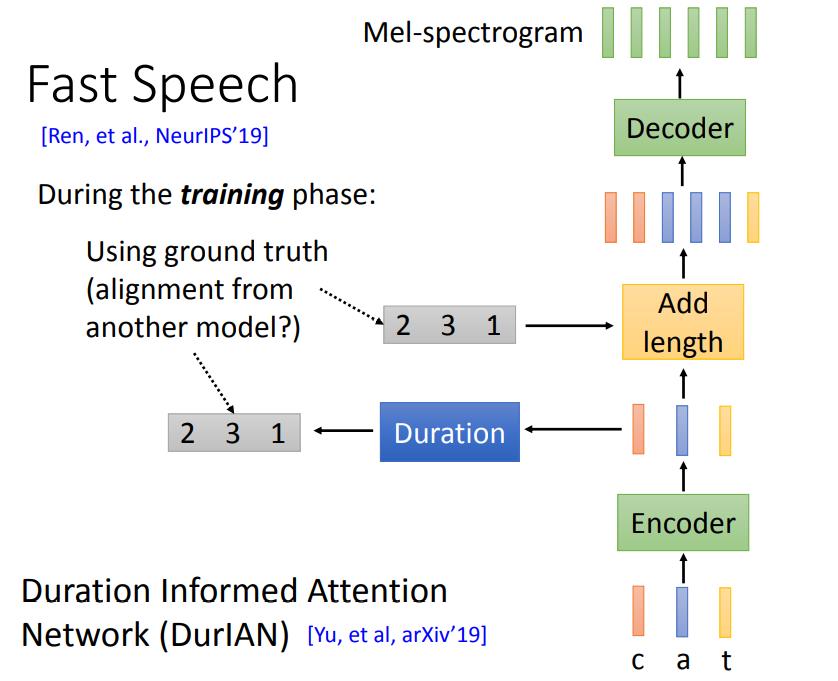
Fast Speech
Fast Speech和DurlAN是同时期独立提出的模型,其结构如下图所示。
输入文本信息,将其Encoder之后,再计算Duration,这里的Duration表示持续时间,取的是整数。比如下图中,Duration取值为2,3,1,Add length就将红色复制为2,蓝色复制为3,黄色不变保持1,然后输入到Decoder中,输出spectrogram。

值得注意的是,由于Duration取值为整数,直接进行反向传播训练时,duration无法求微分,于是训练思路就是在Duration中引入groundtruth进行单独训练。这里的groundtruth比较难直接获取,可以通过其它模型计算得到。
下面看一下对于比较复杂的长难度句,Fast Speech的表现如何。

上图中是一些比较拗口的难句,可以看到Tacotron和Transformer的错误率都在30%左右,而Fast Speech做到了0错误!可见其效果很强。
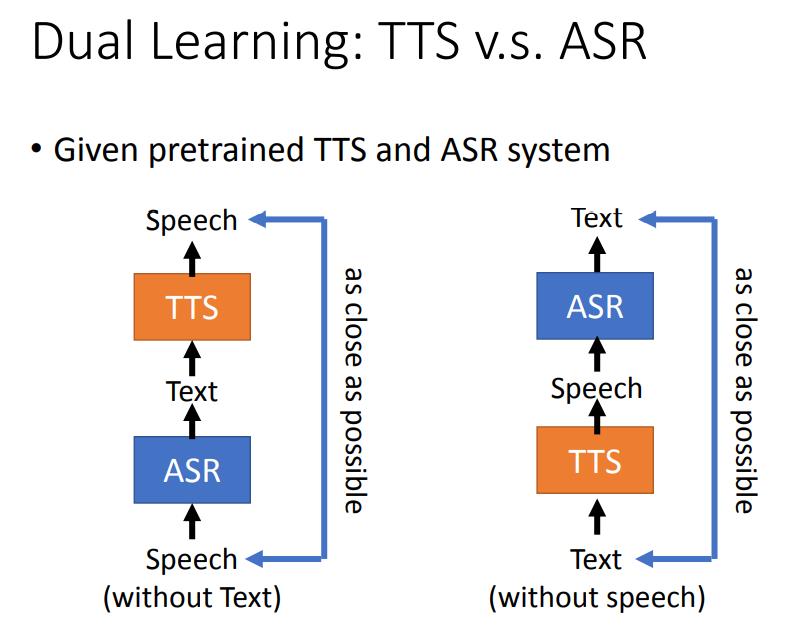
Dual Learning: TTS v.s. ASR
上面在Fast Speech中提到,Duration的groundtruth可以由其它模型得到,这带来的一个启发就是,是否可以用不同的模型实现对抗竞争性的训练(Dual Learning)。
下图中就提到了一种设计思路,可以将文字转语音(TTS)和语音转文字(ASR)放到一起训练,这样起到了同时训练的效果。
Controllable TTS
下面将前面的语音合成(TTS)再做进一步拓展。之前的模型结构,基本实现了文字转语音的功能,但是对语音的情绪,包括语调,重音,韵律等没做过多的控制(Control),下面将考虑这些因素。
下图展示了一种训练思路。
在TTS模型中,除了输入需要转换的文本外,还输入一段语音,输出的语音将包含文本的内容和输入语音的特征。然后训练目标就是让输出语音和输入语音尽可能接近。

这和前面语音转换中的思路比较类似,直接这样做会带来的一个问题就是,输出的语音将无限接近输入的语音,最终相当于直接copy输入语音来输出,这样的损失一定最小,这样的话就会忽视了输入文本的内容,因为这样做无法准确地把输入语音的语音信息排除开来。
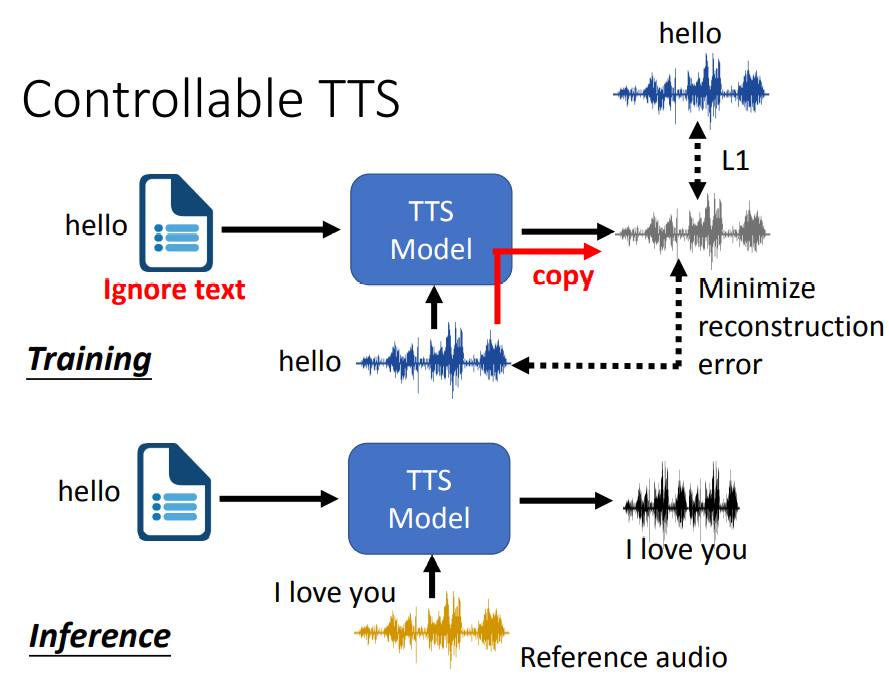
解决这一问题的思路也比较简单。在输入语音中,加一个特征提取器,我们只需要提取输入语音的特征,过滤掉输入语音的语义信息。

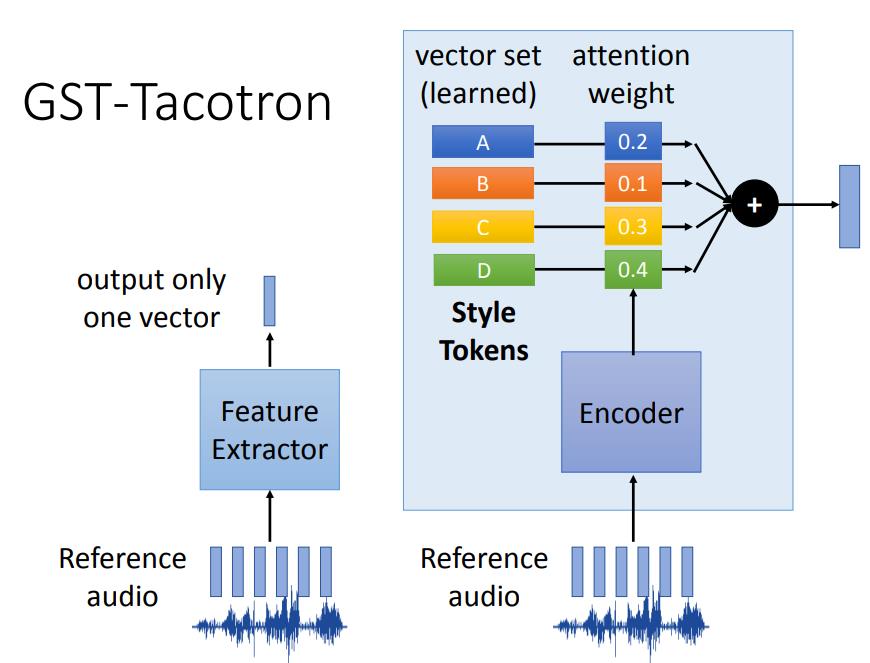
GST-Tacotron
GST-Tacotron方法提供了一个具体的处理方式。
它将输入语音(Reference audio)通过一个特征提取器只输出一个向量,将该向量复制多份和Encoder出的结果进行注意力计算,然后输入到Decoder后面输出,后续结构和Tacotron一样,下图中进行了省略。
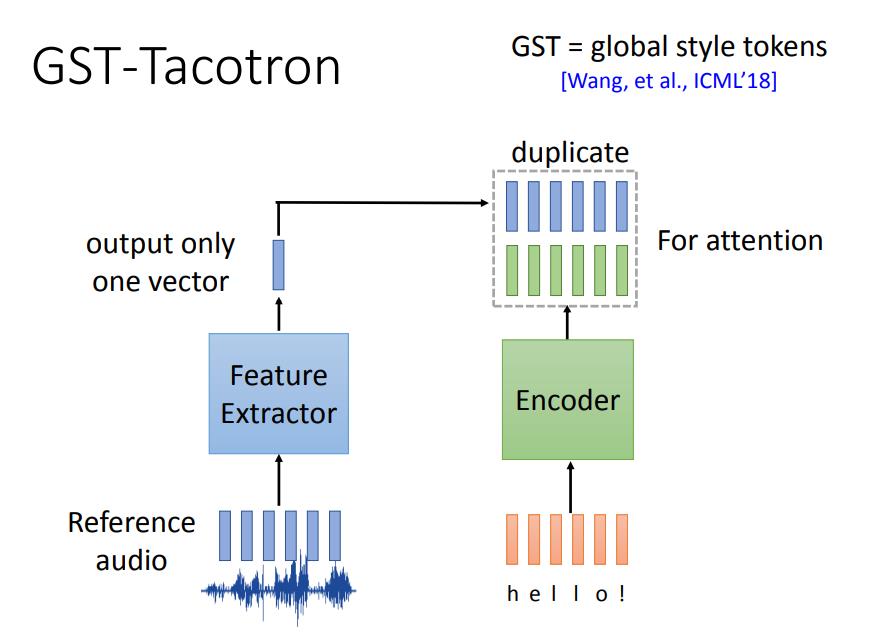
下面将特征提取器的结构拆开看看。
为什么GST-Tacotron能够将Reference audio的语义信息隔离开呢?
这是因为,Feature Extractor提取的信息不是直接输入到下一层,而是将其变成了一个权重向量。里面有一个已经提前学习好的vector set,这个是真正代表语义风格的Tokens,比如下图中的A代表高音,B代表低音,C代表韵律等特征,attention weight就是调整它们的比例,使其接近输入语音的特征,最后将他们加权相加,输出一个融合的特征向量。
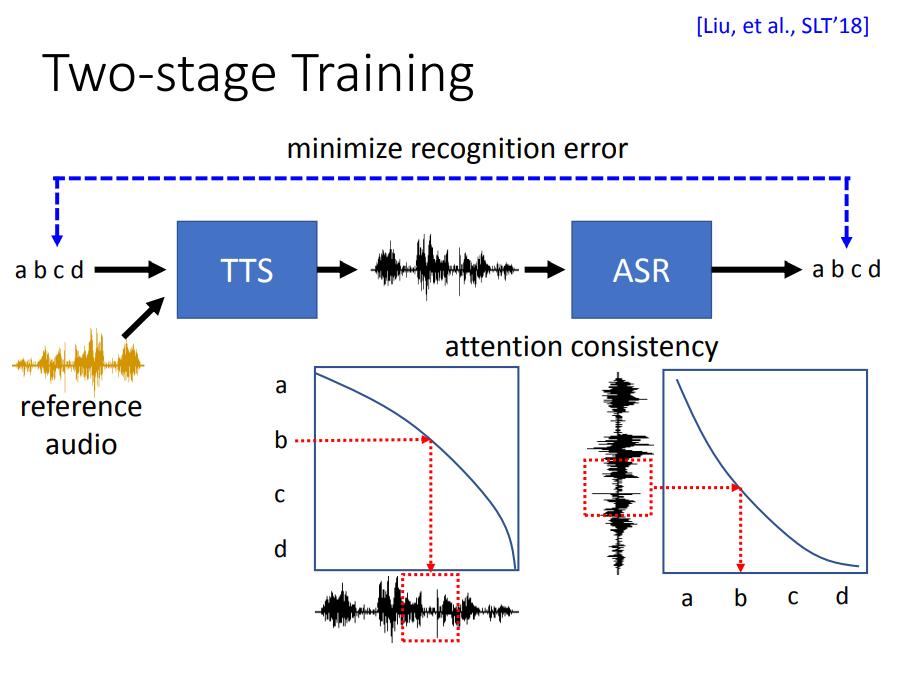
2nd stage training
当然,除了特征提取的思路外,还有另一种处理思路。 2nd stage training就是保持了训练场景和测试场景一样,即输入文本和参考语音。然而,因为这样没有groundtruth,无法直接训练。

于是2nd stage training就借鉴了前面Dual Learning的思想,再输出语音后面加上一个ASR,将输出语音重新转回文本,然后比较输入输出文本的差异,从而做损失进行训练。这样就可以自然地让TTS逐渐倾向于只提取reference audio的特征信息,过滤语义信息。
以上是关于NLP自然语言处理学习笔记语音合成的主要内容,如果未能解决你的问题,请参考以下文章
自然语言处理NLP之自然语言生成文本相似性看图说话说话生图语音合成自然语言可视化