NLP基础知识之语音识别
Posted 今天学习算法了吗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP基础知识之语音识别相关的知识,希望对你有一定的参考价值。
1. 语音识别的输出类别:
1)phoneme:输出为发音,比较简单,因为语音跟发音是一一对应的,但是需要一个词汇表,表示发音跟word的对应。
2)Grapheme:字母或者token
3)word:短语,V会很大
4)morpheme:代表含义的最小单位
5)byte:utf-8,适用于任何语言

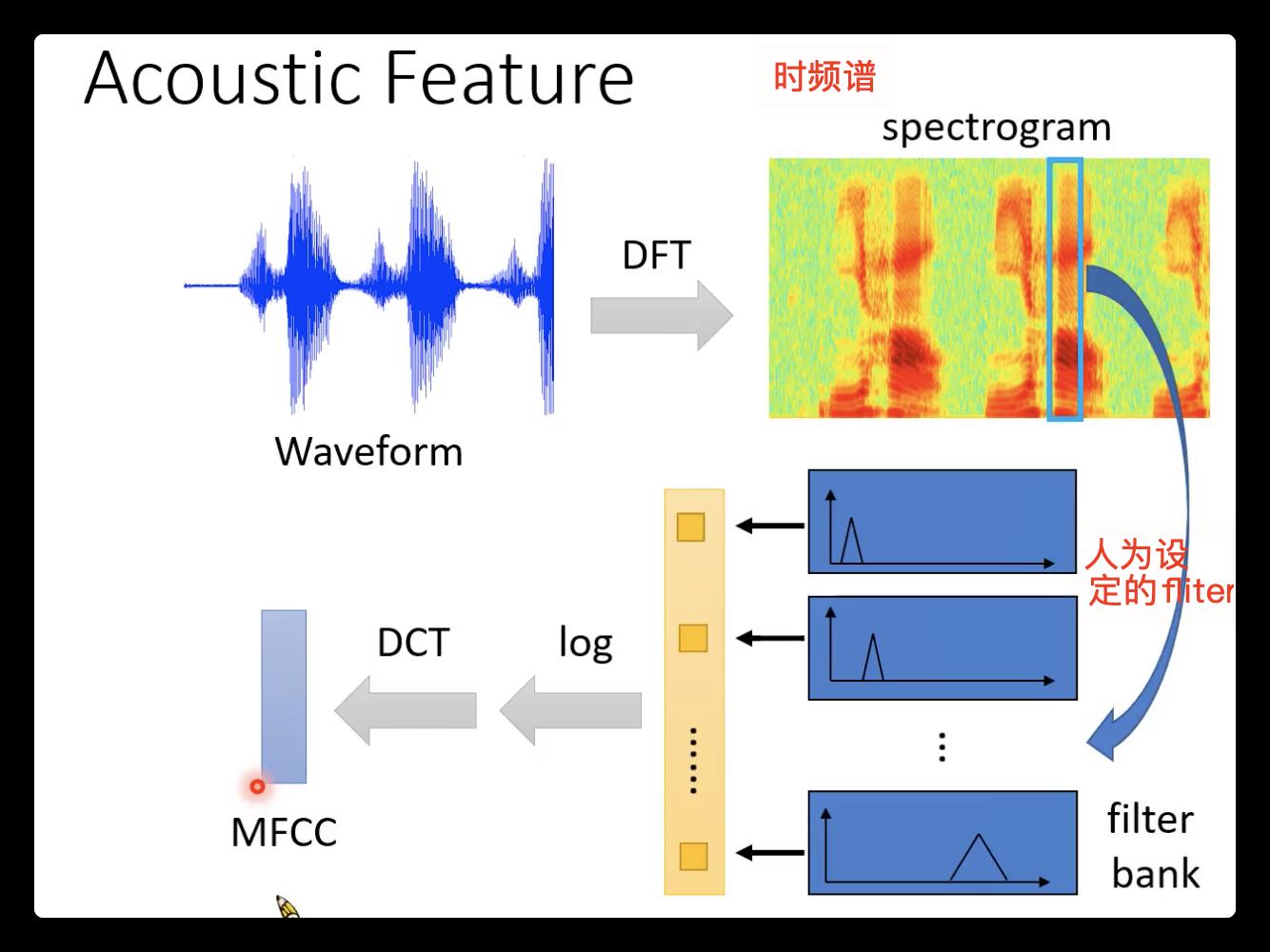
2. 输入特征:(具体的处理可以看下图,以MFCC为例子,如果不经过DCT,就是目前用的最普遍的fliter bank output)
3. 那确定了输入以及输出,接下来介绍中间的模型。
1)以下的模型都是seq-to-seq模型架构的:
⚠️encoder:
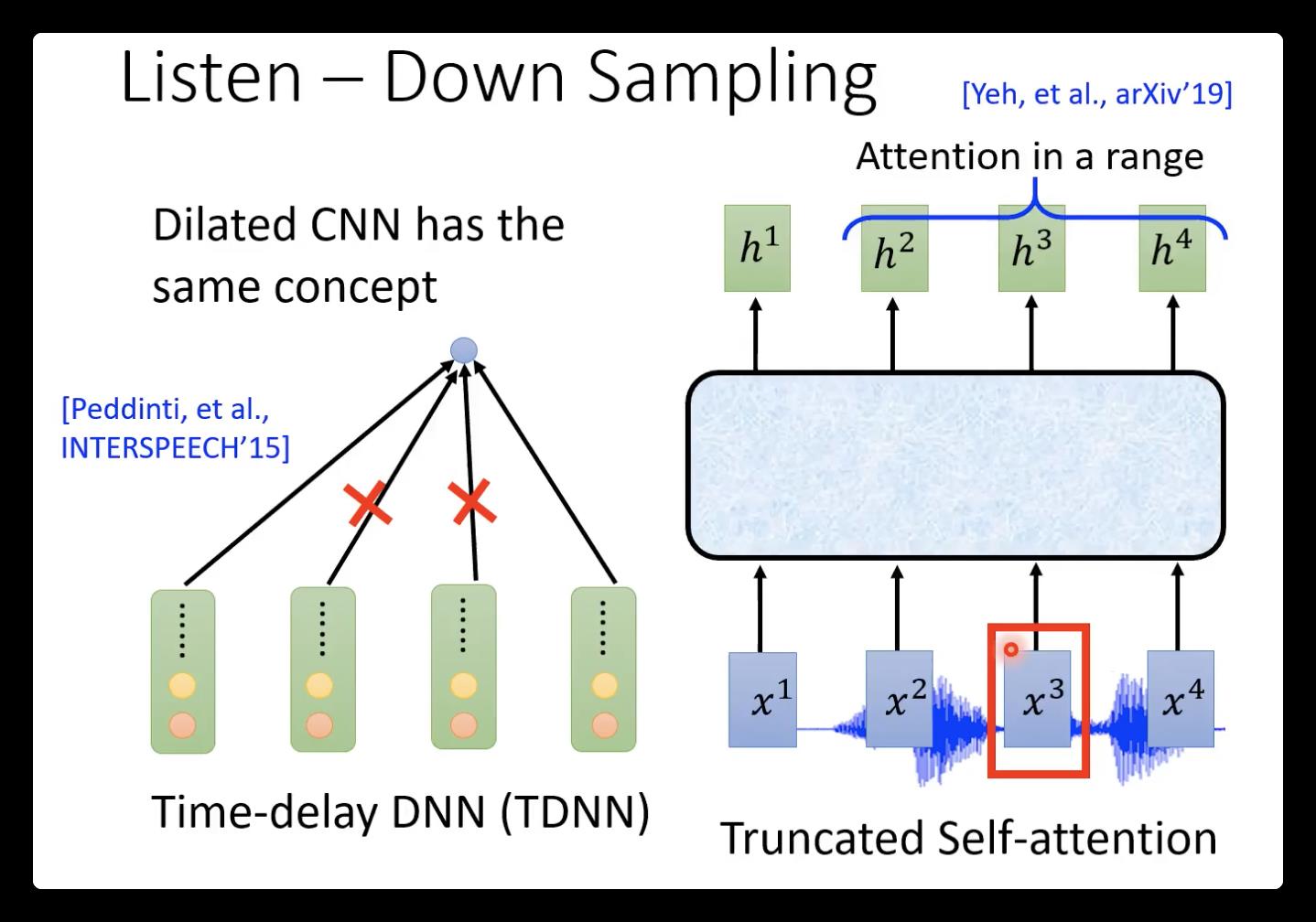
因为语音feature太长了,所以通常要使用down-sampling: 比如下面两个图分别是RNN、CNN和self-attention的模型图,这样输出的hidden就会减少为原来的一半。(这样做还有一个依据,相邻的语音vector其实是比较相近的,因为每次只移动了10ms)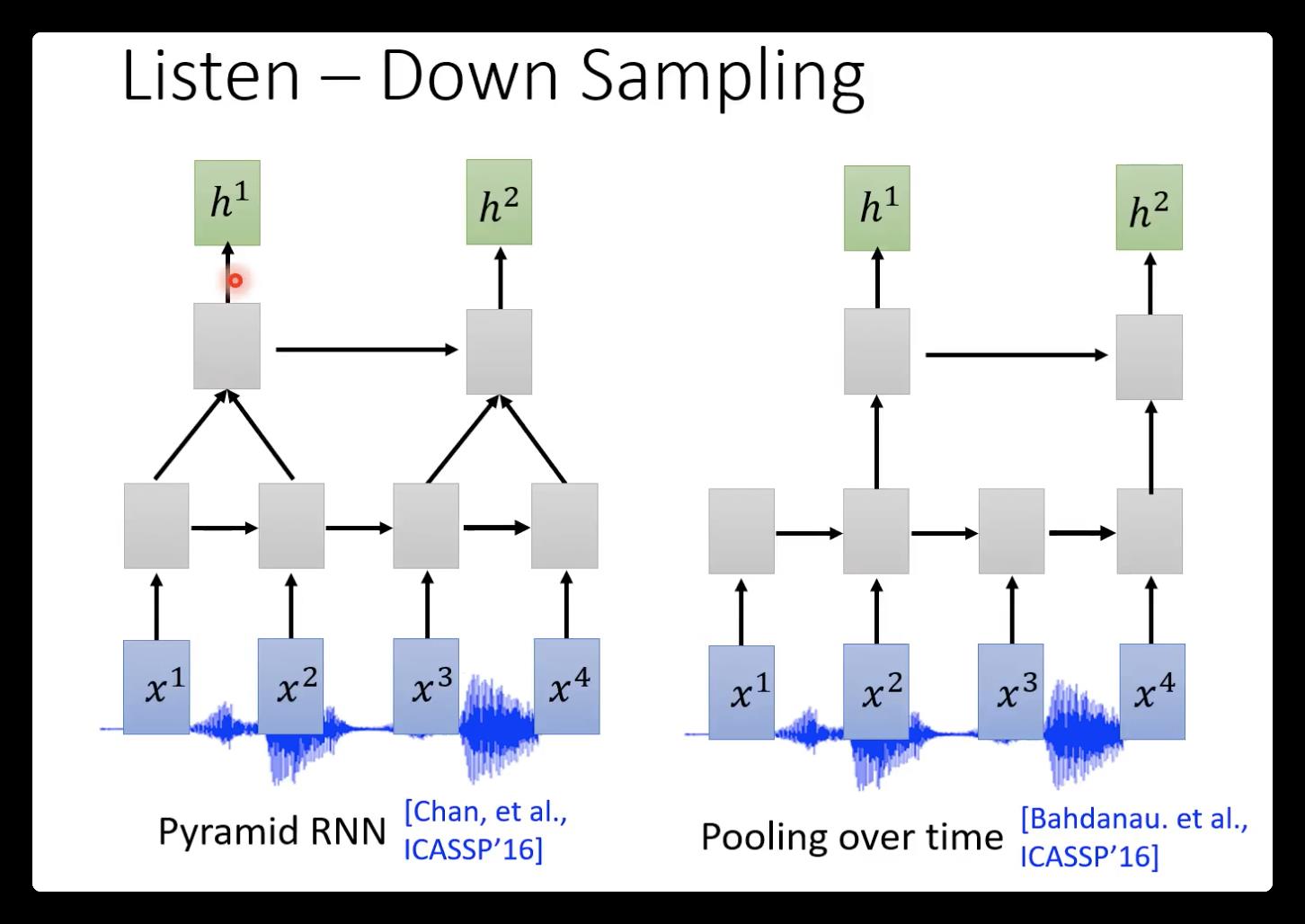
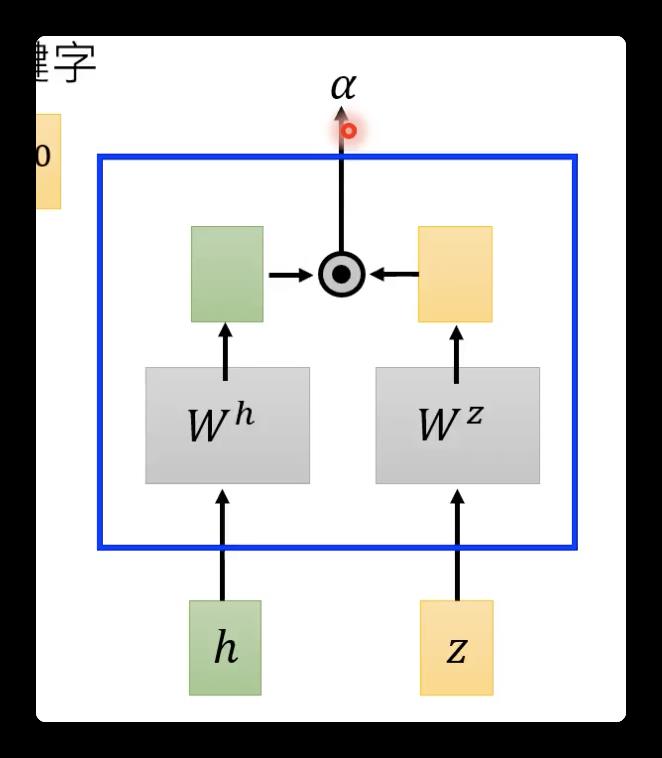
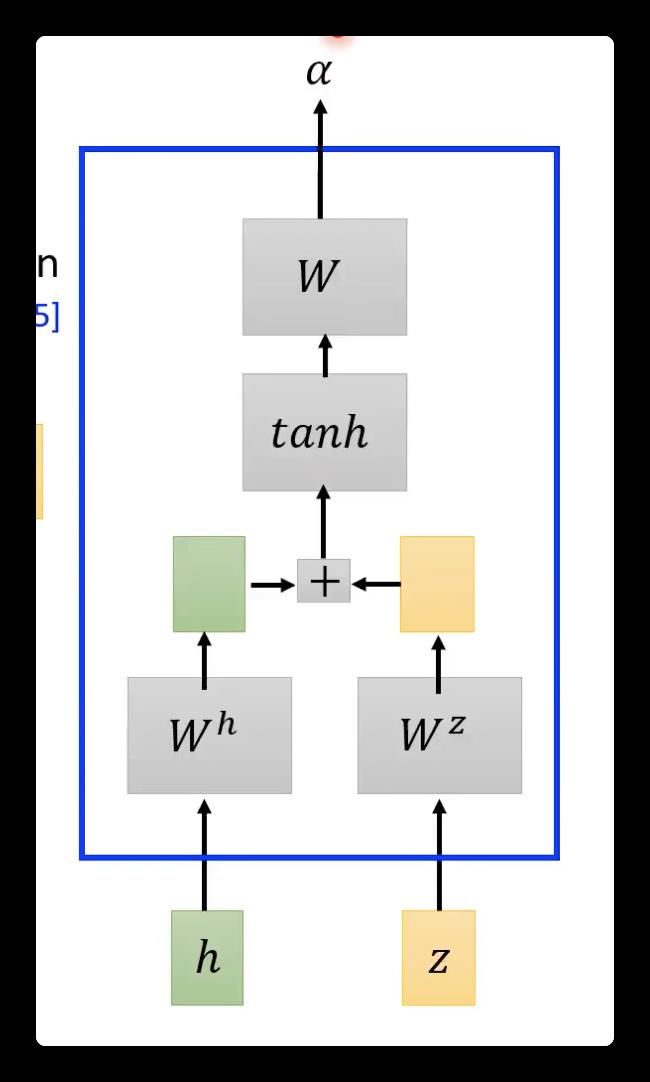
⚠️attention:
其常见计算方式: 直接乘法、加法。在transformer面试时可能会问,为什么选择乘法而不是加法计算相似度:虽然加法计算量小,但是求出来的只是中间结果(矩阵),还要再✖️矩阵才能得到标量。
⚠️decoder:
常见的decoder 方法有:1)greedy decoding(可能找不到最好的)2)beam search方法(保留分数最高的两个)3)我感觉如果是label已知,目前大多数训练用的是teacher forcing。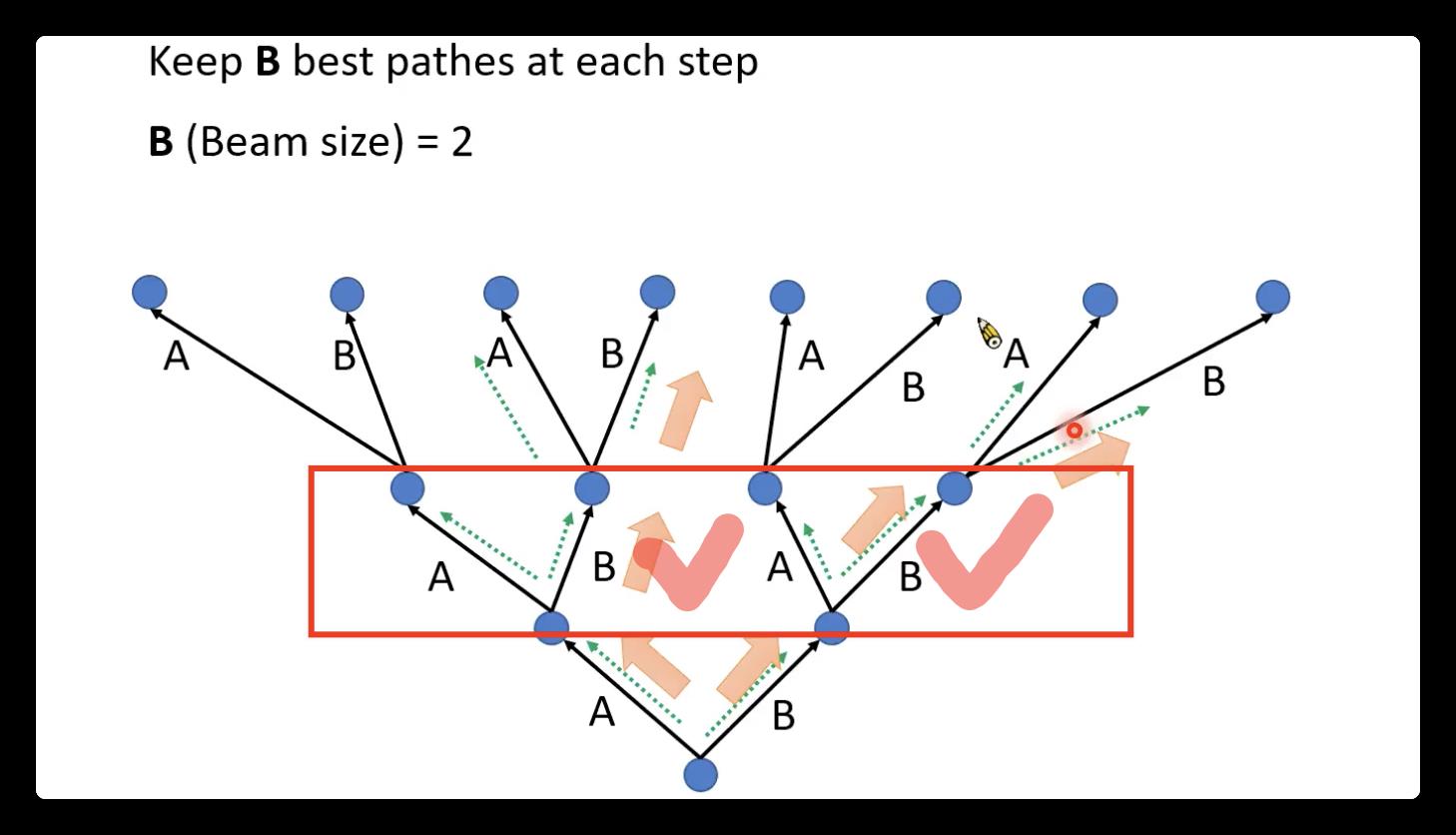
⚠️损失函数:交叉上损失函数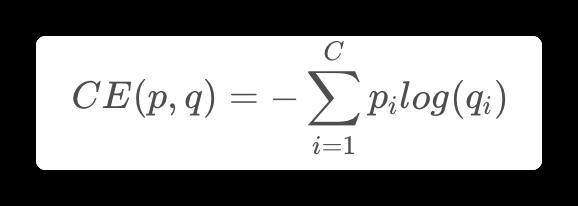
其中C为样本数量,p是label(one-hot),q是预测的概率。其中q的计算公式(softmax)为:即现扩大差距,在进行归一化。
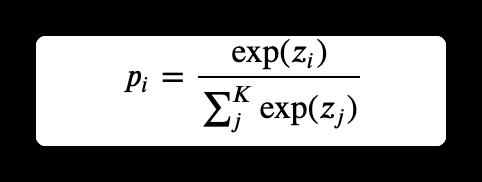
因为p是one-hot,会使得最终预测的logits向量中目标类别zi的值会趋于无穷大,使得模型向预测正确与错误标签的logit差值无限增大的方向学习,而过大的logit差值会使模型缺乏适应性,对它的预测过于自信,过拟合,所以有时候会使用label smothing(soft “one-hot”)
以上是关于NLP基础知识之语音识别的主要内容,如果未能解决你的问题,请参考以下文章