多视点三维行人检测
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多视点三维行人检测相关的知识,希望对你有一定的参考价值。
多视点三维行人检测
Improving 3D Object Detection for Pedestrians with Virtual Multi-View Synthesis Orientation Estimation
论文地址:https://arxiv.org/pdf/1907.06777.pdf
摘要
准确估计行人的方向对于自动驾驶来说是一项重要而具有挑战性的任务,因为这些信息对于跟踪和预测行人的行为至关重要。本文提出了一种灵活的虚拟多视图综合模块,可应用于三维目标检测方法中,以改进方向估计。该模块使用一个多步骤的过程来获取精确方位估计所需的背景语义信息。首先,使用结构保持深度完成算法对场景的点云进行加密,并使用相应的RGB像素对每个点进行着色。接下来,虚拟摄像机被放置在密度点云中的每个对象周围,以生成新的视点,从而保持对象的外观。实验结果表明,该模块在KITTI基准上大大提高了对具有挑战性的行人类别的方向估计。当与开源的三维探测器AVOD-FPN一起使用时,在行人定位、三维和鸟瞰基准上的表现优于所有其他已发布的方法。

一.基本原理与贡献
深度神经网络在三维目标检测方面取得了显著的进展,使其具有足够的鲁棒性,可以应用于自主车辆上。KITTI[1]基准测试展示了3D物体检测方法的成功,特别是在汽车和自行车类上,但也强调了需要改进的地方。基准测试表明,现有的三维检测方法[2]、[3]能够非常精确地估计汽车和自行车的方位,平均角度误差(AAE)[4]分别小于7°和20°而行人的平均误差几乎为56°左右。在这项工作中,处理行人的三维姿势估计的任务,重点是方向估计。此任务对于自动驾驶尤其重要,因为此信息对于跟踪和预测行人行为非常有用。此外,重要的是将方向估计纳入检测管道,而不是依赖于跟踪方法进行估计,因为等待过马路的行人的方向必须在没有运动线索的情况下推断出来。基于图像的检测方法可以从RGB数据中获取丰富的语义信息。为了准确估计方向,这些方法必须提取对象的细粒度细节。然而,由于三维场景的透视变换会导致对象的尺度和外观发生变化,因此提取语义信息具有很大的挑战性。一些方法[5],[6]试图通过使用多尺度图像来提取特征来解决这个问题。然而,如[4]所述,从ROI裁剪中仍然存在对象外观的不一致性。相比之下,建议通过将虚拟摄像机放置在三维场景中相对于每个对象的一致位置来呈现对象的多个视点,从而学习细粒度信息。如图1所示,使用这些生成的视点可以保持更一致的对象外观,这有助于在神经网络中学习对象方向。
激光雷达方法可以利用精确的深度信息实现鲁棒定位。对于汽车类和自行车类,可以利用3D对象的长宽比来简化方向估计问题[2]。然而,基于激光雷达的方法在提取对象的细粒度语义信息方面也面临挑战。激光雷达数据的稀疏性限制了这些方法的工作范围,特别是对于行人等较小的物体。在较长距离内,由于激光雷达数据的稀疏性变得非常严重,很难区分树木、电线杆和行人,从而导致误报,从而丢失了细粒度信息。图2显示,即使在20米和30米的较短距离内,使用高密度64束HDL-64E激光雷达,由于数据的稀疏性,人类也很难识别有意义的方向信息。为了解决这种稀疏性问题,利用深度完成的任务来生成稠密的点云,这允许一对一像素点合并RGB图像数据。此外,受F-PointNet[7]使用2D检测器进行精确分类的启发,利用2D检测器进行假阳性抑制。此外,方位估计性能取决于可用训练数据的数量。
训练集必须能够很好地代表所有可能的方向,但是标记的3D数据是昂贵和耗时的获取[8]。KITTI[1]数据集只有4500个带有3D标签的行人训练实例,这使得训练通常需要大量数据才能获得良好性能的神经网络变得困难。一个常见的解决方案是利用CAD模型和附加注释来获取更多的训练数据[9],[10]。但是,不需要使用额外的数据源或标签。为了减少数据量,开发了一个虚拟多视图渲染管道,从图像和激光雷达输入中生成新的真实数据。在训练和推理过程中,生成的数据被合并到网络中。检测到的对象将从一组规范的相机视图重新渲染,以便与使用由公共感兴趣区域(ROI)cropand resize过程获得的二维裁剪相比,对象保持更一致的外观。在推断时,这些附加的视点用于确定更精确的方向估计。
总之,在这项工作中的贡献如下:
•提出了一个灵活的模块,可用于三维目标检测管道,以改进方向估计。
•解决了有限位姿数据的问题,以及在使用虚拟摄像机在彩色深度完成的激光雷达点云上生成视点的新型管道中,从图像和激光雷达数据中获取精细颗粒细节的挑战。
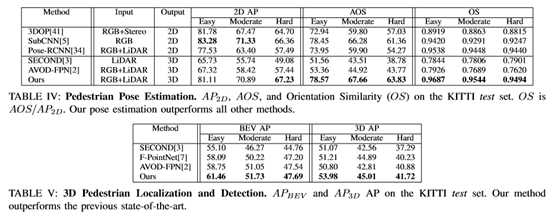
•在提交时,当纳入开源AVOD-FPN[2]3D目标探测器的检测管道时,方法在KITTI[1]行人定位、3D和鸟瞰基准上与所有其他已发布的方法相比排名第一。
•与具有可比方向估计性能的其他检测方法相比,方法运行速度快8倍以上。

三.相关研究
方向(偏航、俯仰、横滚)表示定义对象三维姿势的组件之一。3D位姿数据集的引入[1]、[11]、[12]、[13]催生了大量的3D位姿估计方法,并由此探索了许多方位估计技术。
多尺度特征提取
以前的工作已经认识到,准确的方向估计需要一个特征提取过程,捕捉对象的细粒度语义信息。Zhang等人[14] 确定标准的快速R-CNN特征地图对于行人来说分辨率太低,而使用的是阿托罗斯卷积[15]和浅层的池特征。金字塔结构包括图像金字塔[16]和特征金字塔[17]也被用来从多个尺度获取信息。SubCNN[5]使用图像金字塔来处理对象的比例变化,并且[2]强调金字塔结构对于行人等小类的重要性。此外,[18]、[19]、[20]已经表明了方法裁剪ROI特征的重要性。Kundu等人[4] 注意,标准的ROI裁剪可以扭曲形状和姿势的外观,并建议使用虚拟ROI相机来解决这个问题。取而代之的是,使用多个虚拟感兴趣区摄像机,在每个物体检测到的质心周围规范地放置,从而获得细粒度的细节。与文献[4]相比,不仅使用二维RGB数据,而且还使用三维点云生成逼真的新颖视点,以保持对象外观的一致性。
关键点和CAD模型
使用关键点检测[21]、[22]、[23]、[24]和CAD模型[25]、[26]已被证明在获得感兴趣对象的语义理解方面是有效的。使用二维关键点检测来估计姿态已经作为透视点(PnP)问题得到了很好的研究,并提出了许多解决方案[27]、[28]、[29]。最近,[25],[26]使用3D CAD模型和卷积神经网络(CNNs)检测关键点来学习3D姿势。在自主驾驶环境中,DeepMANTA[10]预测车辆部件协调性,并使用车辆CAD模型数据集来估计3D姿势。CAD模型也被用来创建额外的地面真实性标签。Su等人[9] 认为视点标注训练数据的稀缺性阻碍了视点估计性能的提高,因此采用三维模型生成准确的地面真实数据。与上述方法不同,不需要额外的关键点标签或外部CAD数据集。提出了一个利用可用数据的通用管道,并使用虚拟摄像机生成新的高分辨率视点。
多视角学习
使用多个视图已经被证明可以有效地让神经网络学习形状和姿势信息。Su等人[30]从CAD数据集中围绕一个对象呈现多个视图,然后根据每个视图的特征预测形状。其他[31]、[32]、[33]使用多个视图来确保投影一致性,以学习形状和姿势信息。这些方法倾向于使用CAD模型,从背景中分割感兴趣的对象,包含完整的360°形状信息,并允许从任何角度完美地生成数据。然而,在自动驾驶中的应用程序只能访问激光雷达扫描,只提供来自单一方向的输入数据。表明,仍然能够通过将虚拟摄像机小心地放置在特定的操作区域内来利用这些数据来保持真实的渲染图像,如图4所示。
方向表示法
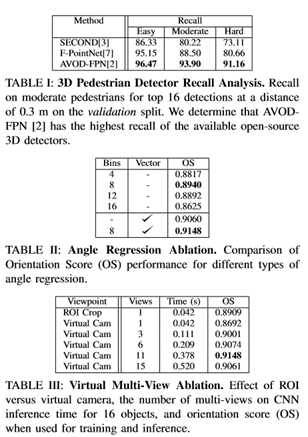
与工作最相似的是为自主驾驶场景设计的三维姿态估计方法。这些方法主要集中在方向的表示和新的损失函数的设计上。姿势RCNN[34]使用位数表示作为[35]建议的方向。单目三维目标检测方法Deep3DBox[36]提出了一种角元公式,将帧方向估计作为一个混合分类回归问题。在这里,方向被离散成若干个箱子,网络的任务是分类正确的箱子和预测一个回归偏移。该公式已被包括[7]在内的激光雷达方法采用。[2] 识别一个模糊问题,即尽管方向估计值相差±∏弧度,但创建相同的三维长方体。他通过将方向参数化为角度向量来解决这个问题,而Yan等人[3] 用正弦误差损失来处理同样的问题。消融研究显示将方向参数化为角矢量,同时使用离散连续角bin公式作为辅助损失是最有效的。
三.姿态估计框架
图3提供了用于3D行人姿势估计的管道的概述。

该方法的核心思想是从彩色稠密点云中生成真实新颖的物体视点,并利用这些视点提取出丰富的物体语义信息,从而实现对物体的方位估计。首先,在现有三维探测器性能的基础上,使用三维探测作为质心建议。这些建议由虚拟多视图合成模块处理,该模块使用密集点云重建来呈现一组新的视图。重要的是,这些视图是在一组规范的摄像机视点中创建的,方法是将虚拟摄像机放置在相对于每个对象的一致位置布氏体从这些虚拟相机生成的对象视图与进行ROI裁剪相比,可以更好地保留对象的3D形状和外观。对于生成的每个新视图,方向是通过将视图通过CNN,然后通过方向回归输出头来估计的。最终方向输出是通过合并方向估计值产生的。最后,由于流水线中使用的3D检测器是在具有高召回率的基础上选择的,因此使用鲁棒的2D检测器来抑制误报。
A、 虚拟多视图综合
加密RGB点云生成
首先注意到,激光雷达点云只是底层场景的稀疏表示,可以全方位观看,每个视图都提供了场景的独特视觉表示。然而,激光雷达数据的稀疏性只能提供低分辨率的场景透视图。因此,将激光雷达扫描的一部分对应于图像的可见部分,并通过结构保持深度完成算法进行处理[37]。特别地,使用提供的3×4相机投影矩阵Pcam将LiDAR点投影到图像中,从而创建稀疏的深度映射Ds。深度完成算法生成一个密集的深度图Dd,每个像素表示一个深度,然后将其重新投影为一个3D点云。由于得到的点云来自于与RGB图像具有相同分辨率的稠密深度图,接下来通过将RGB图像中的每个3D点与其对应的像素着色,从图像中注入语义信息。该场景点云的彩色密集重建解决了激光雷达扫描的低分辨率问题,并允许生成更逼真的新视图,以保留细粒度语义信息,如图2所示。
多视图生成
目标是学习每个对象的细粒度细节。最直接的过程是简单地对每个对象对应的图像区域进行ROI裁剪,但是正如[4]所指出的,这种常见的裁剪过程可能导致同一对象的外观大不相同。最近,以对象为中心的坐标框架的使用被证明对促进学习任务是有效的[7],[38],因此,设计了模块来使用规范视角进行估计。为了创建标准摄像机视点,将虚拟摄像机沿N个等距的角度分割放置在与对象质心等距的位置。摄像机位置与感兴趣物体的中心水平放置,在一个角度范围内,从原始摄像机中心到物体质心的光线定义的水平视图角度α的左侧和右侧,ρ∈[-ρmax,ρmax]之间,如图4所示。选择视点的最小和最大角度时,生成的视图不会显示从原始相机视点看不到的对象部分,这会使对象看起来不现实。对象的N个视图是在一组标准视点中生成的,这些视点沿对象周围半径r的弧均匀分布。每个视点生成一个保持外观的H×W ROI图像,如图1所示。这些渲染输出密集地将点云和图像信息融合为3通道RGB格式,从而允许使用成熟的CNN架构进行方向估计。
B、 方位估计
渲染的ROI图像通过CNN生成最终的方向估计。有几种方法[36],[7]使用离散的连续损失,以B角箱的形式,在每个箱中进行回归。然而,假设这会分割训练数据,因为每个bin只会有训练样本总数的一小部分可供学习。
C、 最终姿态估计
最终的三维检测由物体质心T、尺寸D和方向O参数化。质心和尺寸估计直接从三维检测中获取,而方向的偏航θ设置为方向估计模块产生的输出。
D、 假正性抑制
与包含图像数据的方法相比,KITTI测试基准上基于行人激光雷达的3D探测器的平均精度(AP)曲线显示出显著的低精度。这支持了这样一种假设,即仅从激光雷达数据中识别行人等较小物体非常困难,而且误报现象普遍存在。为了提高检测性能,使用0.4的交超并(IoU)阈值,将鲁棒2D检测器的2D盒与3D检测的2D投影进行匹配。投影不符合此阈值的3D框的分数降低,这起到了假阳性抑制的作用。由于KITTI平均方向相似性(AOS)的评估也依赖于2D检测性能,因此每个3D盒的投影被其来自2D检测器的相应2D盒替换,这使得AOS可以被评估。
E、 训练损失
多任务训练在提高神经网络性能方面有着显著的效果。根据[36]中的离散连续角仓公式,添加了一个辅助输出层,生成B向仓和B角回归。角度箱用软最大损失训练,而箱回归和角度向量输出用平滑的L1损失训练。总损失计算如下:

以上是关于多视点三维行人检测的主要内容,如果未能解决你的问题,请参考以下文章