货拉拉大数据对Bitmap的探索与实践(下)
Posted @SmartSi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了货拉拉大数据对Bitmap的探索与实践(下)相关的知识,希望对你有一定的参考价值。

1. 引言
在大数据时代,想要不断提升基于海量数据获取的决策、洞察发现和流程优化等能力,就需要不停思考如何利用有限的资源实现高效稳定地产出可信且丰富的数据,从而提高赋能下游产品的效率以及效果。继上篇 货拉拉大数据对BitMap的探索与实践(上),介绍了 bitmap 的底层实现原理与应用优化,以及在一些常见业务场景中的实践应用。本篇则重点介绍在大数据OLAP场景下,对bitmap的一些应用落地。
bitmap 索引广泛应用于很多大数据 OLAP 引擎中,如 Druid、Kylin、Doris 等,是一种高效的索引技术。货拉拉大数据使用 Apache Druid OLAP 引擎支持罗盘、AB test 等多个分析场景,所以本篇将介绍在 Druid 中如何构建 bitmap 索引实现高效查询。同时也介绍了如何利用 bitmap 的去重能力实现高效的精确去重功能,以及为了支撑更多场景我们做的一些改造优化。希望大家读后都能有所收获。
2. Druid Bitmap 索引
Apache Druid 架构原理不是本文章重点,有兴趣的同学可自行Google了解。Druid 中构建 bitmap 索引时会为每个维度构建维度字典,对于字典中的每个元素,都会生成一个 bitmap,其中 1 表示该 bit 下标对应的行的值是对应字典元素的值,反之不是。
2.1 维度字典
为维度列构建维度字典是 Druid 中非常重要的一个步骤,将列的所有值去重,然后按照字典顺序排序组成数组,字典中存储了排序后的维度值,每个维度值对应一个编码值,编码值就等于数组的下标。
2.2 构建 Bitmap 索引
对字典中每个维度列都会生成一个 bitmap 数组:MutableBitmap[] bitmaps,数组大小为每个维度列的可取值多少。为了更加具体地理解整个bitmap索引构建的过程,以下面表格数据为例子来模拟构建的过程。
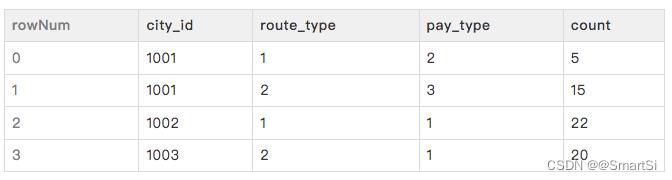
上表格中的 city_id、route_type、pay_type 是维度列,count 为指标列 在数据摄入时,以其中一行数据为例介绍构建 bitmap 索引的过程:
- 首先会为每一行生成一个自增的rowNum
- 遍历所有维度列,分别为每个维度列构建相应的bitmap数组
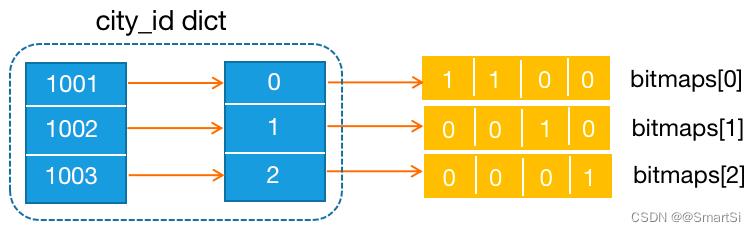
如上图为 city_id 维度列的字典,以及对表格中 city_id 列构建 bitmap 索引,索引数组共有 3 个元素,分别对应 1001、1002 和 1003,其中 1001 出现在 rowNumber=0 和 1 的行,则 bitmaps[0] 的第 0 和 1 位为1,其他位为0,依次类推为字典中每个元素构建位图索引。
2.3 如何查询
简单分析下 Druid 在查询中如何使用到上面的数据结构,为了简化查询过程,假设只命中了一个数据文件,就可忽略多个数据文件的结果合并等问题。我们以下面简单查询为例:
select sum(count)
from table
where city_id = 1001 and route_type= 2

上面介绍了 Druid 中构建 bitmap 索引以及根据索引如何做查询的简要步骤,实际 Druid 实现更加复杂,要解决如索引如何存储、如何快速定位到维度的字典编码等问题,本文章不做进一步介绍,感兴趣的同学可自行google。
3. Druid 精确去重
在超大的数据集规模下,实现精确去重计数是一件非常困难的事,需要兼顾精确去重与快速响应,但是当数据数据到一定量级这两个目标可能是相互矛盾相互约束的。精确去重意味着要保留所有数据细节,这样才能使结果可上卷;快速响应需要通过预计算或者内存计算等手段来加快速度。
在货拉拉大数据 OLAP 多维查询场景中,就有精确去重要求,比如A/B实验平台业务中一个实验对应多个司机,需对司机精确去重。由于 Druid 原生不支持精确去重,这里合入了由快手提供的精确去重实现,采用字典编码+ bitmap 的方式实现。下面介绍方案细节,以及为满足货拉拉大数据精确去重需求所做的一些改动。
3.1 字典编码+Bitmap方案
快手此方案是在 Kylin 方案基础上进行的优化改进。这种方案的思路是:对要去重的数据列,新增一个叫 unique 的指标存储,将每个列数据(string 或其他类型)转化成 int 整型的全局字典编码,摄入到 Druid 后通过 bitmap 的格式存储;在查询时对多个 bitmap 做交集,得到最终去重结果。bitmap 的范围是 42 亿,占用存储空间最大约500M;使用压缩算法,使空间占用大大减少。
3.1.1 字典编码
要解决的第一个核心问题是如何构建字典编码,即如何能将所有数据转换成字符串类型后都统一编码并映射到 int 类型的数据。目前使用的是 Apache Kylin 实现的 AppendTrie,是基于通用性高的 Trie 树实现的字典编码,其空间和性能效率都比较高。Trie 树又名前缀树,是一种有序树,一个节点的所有子孙节点都有相同的前缀,即该节点对应的字符串,而每个字符串对应的编码值由对应节点在树中的位置来决定。下图是一棵典型的Trie树示意图。

而 AppendTrie 在 Trie 树基础上,做了一些改造:
- 序列化数据中保存节点对应的映射id,而不是位置id,这样节点变更后id不会变;记录当前模型最大 ID,以实现追加节点
- 为防止整棵树的内存占用和序列化数据过大,需要将整棵树拆成多颗子树,并且查询时候只需要查询一颗子树即可;再通过LRU算法来控制所有子树的加载和淘汰行为
在 Druid 中利用 MR 的分布式能力构建全局字典,这样吞吐量更高,而且还拥有更高的容错性。但是 MR 仅支持离线导入任务,所以
- 离线任务使用离线 MR 构建字典编码,通过小时级任务保证实时性
- 实时任务仅支持原始 int 去重,这样就无需编码
3.1.2 字典并发构建
为了支持字典并发读写构建,在持久化时分别使用 MVCC 理念以及 Zookeeper 分布式锁的方案。
- 使用 MVCC 每次构建持久化在 hdfs 上作为一个版本 ,后续更新必须拷贝版本数据到 working 中进行构建,构建完成持久化为生成新的版本;并设置了版本个数和存活时间的版本淘汰机制,以此来清理历史数据
- 构建全局字典的过程中会操作临时目录,就会有多个进程同时去写临时目录的读写冲突问题;因此引入 Zookeeper 分布式锁,基于 DataSource 和列来做唯一的标示,从而保证同一个字典同时只能有一个进程在读写
3.2 精准去重流程

- 第一个Job,DetermineConfigurationJob 计算Segment 分片数量,决定第三个job的reducer数量
- 第二个job,构建全局字典。Map 将同一去重列发送到一个 reducer 中 ( Map 端可先 combine ) ;每个 reducer 构建一列的全局字典,字典存在HDFS上;为每列字典构建申请 ZK 锁,格式为
/dict/dataSource_fieldName,防止对临时目录多线程读写冲突 - 第三个job,进行数据摄入。在 Map 中加载字典,从字典中为去重列找到对应 int编码并转换;Reducer 将 int 编码聚合成 bitmap 存储;每个 reducer 生成一个 Segment
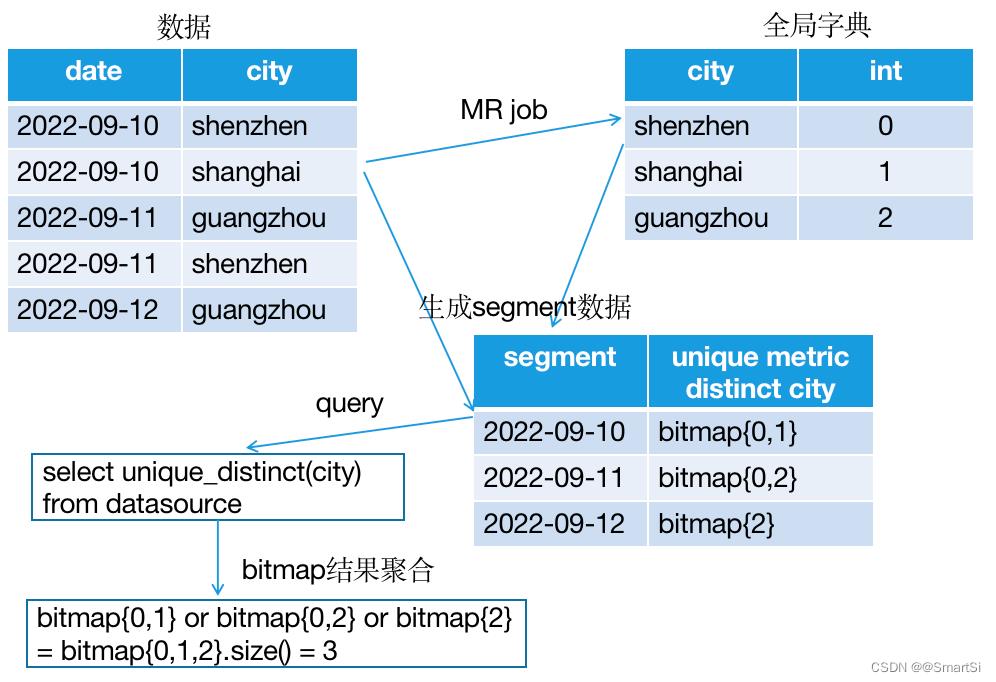
如上图,数据从摄入到构建全局字典,以及将维度列int编码用bitmap聚合并存储生成segment数据,到精确去重查询。整个过程最复杂的是为维度列构建全局字典,其次使用bitmap存储即保留了所有数据细节,也能使结果可上卷,并且存储压力非常小,是一种非常高效的精确去重方案。
3.3 高基维整数精确去重改造
上述介绍的精准去重方案目前能支持货拉拉大多数相关场景需求,但是在A/B实验平台业务中需要对司机id进行精确去重,直接使用上述方案进行构建,需要上游将数据打散为明细数据,而随着维度增多,数据膨胀严重,导致 Druid 离线导数链路构建时间过长,下游无法按时产出。耗时长原因有以下几点:
- 打散后数据量大:千万级别,离线导入需要起上千个map task,task总耗时长
- 内存不足:司机id维度基数大,百万级别且无规律,导致构建的全局字典树非常大,每个map都需将字典加载到内存,但内存资源有限,频繁的换进换出导致过多的磁盘io,因此索引查找维度编码慢
- 全局字典树持续增大:随着时间推移,全局字典树会越来越大,构建也会越来越慢
因此,大基数且不可枚举的维度做精确去重时,不适合构建全局字典。
基于此思路实现了跳过全局字典构建,整形id直接使用bitmap做去重的方案。这样无需打散数据,多个司机id逗号拼接摄入,减少上游数据量。我们通过改造离线摄入MR job,修改序列化与反序列化逻辑,以及Aggregator相关实现类,支持了以下两种数据类型:
- 支持上游bitmap字符串的数据类型摄入,转换后进行聚合,存储数据仍为bitmap
- 支持上游整形数组数据类型摄入,存储数据仍为bitmap 上游业务方使用了方案1,无需打散数据,司机id数组转为bitmap字符串数据格式直接摄入,跳过字典构建,因此也无需索引查找维度编码,整体数据量也大大降低,最终整条链路由原来2个多小时缩短至40min,提效收益明显。
当然这种方案也有弊端:
- 由于未构建字典,底层直接存储原始司机id的bitmap,和映射成int相比占用的磁盘空间更大
- 这里仅支持了上述这种整形的高基维精确去重场景,对其他无法转成整形的数据类型暂时还不支持
4. 结语
以上介绍了Apache Druid中如何构建bitmap索引和维度字典来实现高效查询的,同时介绍了由快手在Druid平台上实现的基于全局字典编码+bitmap实现的精确去重方案,以及我们在此方案上进行了一些改造,使其能够支持整形高基围的精确去重场景。
参考:
- https://mp.weixin.qq.com/s/P2I0N8QNieASNEg8-hHaMg
- https://cloud.tencent.com/developer/news/662342
- https://www.infoq.cn/article/YdPlYzWCCQ5sPR_iKtVz
- https://mp.weixin.qq.com/s/cpHbL_OAYCbCfTdW956P0Q
以上是关于货拉拉大数据对Bitmap的探索与实践(下)的主要内容,如果未能解决你的问题,请参考以下文章