货拉拉数据治理平台建设实践
Posted 学而知之@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了货拉拉数据治理平台建设实践相关的知识,希望对你有一定的参考价值。
导读:在数据开发和数仓建设过程中,数据治理落地和提升数据质量的重要性逐渐凸显,本文将从货拉拉的数据治理实践出发,分享货拉拉在数据治理体系构建、数据质量平台建设、元数据平台建设方面的实践。
今天的分享会围绕以下三个话题展开:
货拉拉数据治理体系
数据质量平台建设实践
元数据平台建设实践
01
货拉拉数据治理体系
首先和大家分享下数据治理的背景和现状。
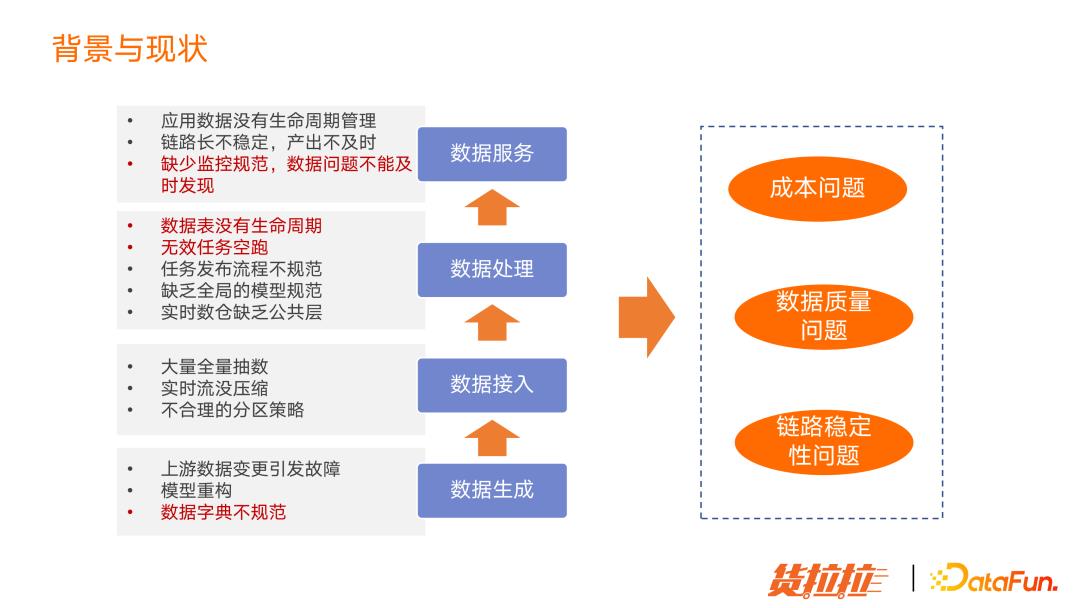
1. 背景与现状
我们在做数据开发或数仓建设过程中,会遇到大量问题,有些会导致成本和数据质量问题,有些会影响数据链路稳定性。比如数据表没有生命周期或无效的任务空跑,会造成成本浪费;又比如数据字典不规范、缺乏监控规范,以及数据问题不能及时发现,会造成数据质量问题,甚至导致链路稳定性。
2. 数据治理关键环节
基于以上背景,我们在以下四个环节做了相应工作:
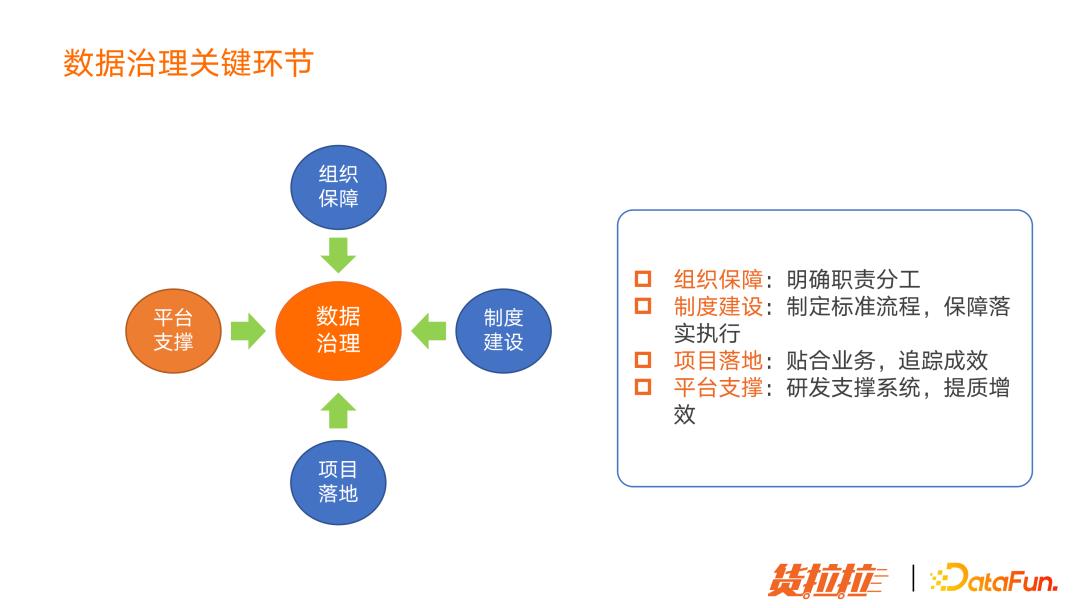
组织保障:明确成员角色,明确职责分工;我们成立了存储治理小组、计算治理小组,以及稳定性保障小组。
制度建设:制定标准流程,保证落实执行;如我们制定了大数据接入规范、数据开发规范、数据模型规范,这些都是需要长期推广和落地的过程。
项目落地:开展专项治理动作,比如存储治理、计算治理等;实践证明专项治理的效果比较明显,但问题是比较耗时耗力;不是长效机制,是一种运动式的治理,需要把能力产品化,让数据责任方自助式治理,驱动自主治理。
平台支撑:研发支撑系统,提质增效。
今天我的分享主要是围绕平台支撑这个环节开展,其他三个环节,是接下来由其他老师带来。
3. 货拉拉数据治理产品体系
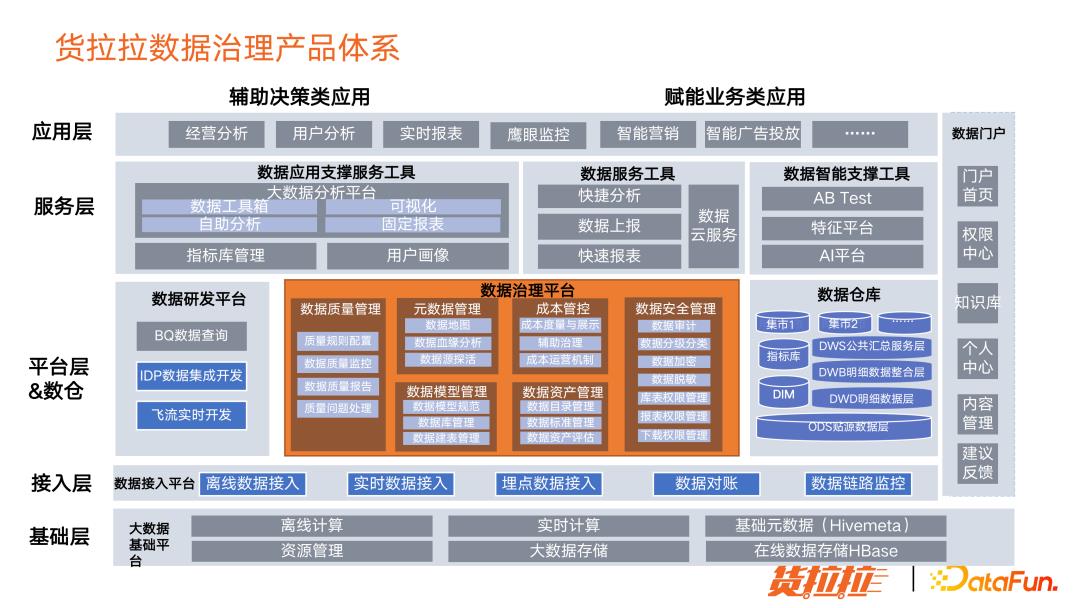
货拉拉数据治理产品体系,由数据质量管理平台、元数据管理平台以及数据安全管理平台这三个平台支撑。
元数据管理平台包含数据地图、数据血缘分析、数据模型管理、成本管控、数据资产管理。
数据地图主要提供找数据和帮助用户理解数据的能力。
数据血缘分析主要是在数据链路出现问题的时候,帮助排查定位问题。
数据模型管理,提供规范落地能力:把所有正式表的建表收归到数据模型管理平台。这样的好处是,如数据安全等级、数据生命周期都会有设置,防止数据出现无序增长的趋势。
成本管控平台,它的作用是度量当前数据资源有哪些,资源消耗是怎样的,每天花了多少钱。
辅助治理措施:冷数据归档、数据生命周期管理能力。
成本运营机制:可以让用户自驱地做成本运营,不用做保姆式的人治。
数据资产管理:主要提供数据目录管理、数据标准管理,供评估数据资产;
数据质量管理:提供全链路的数据质量监控,有问题可以及时发现和处理,防止问题进一步扩散,可以及时止损。
02
数据质量平台建设实践
1. 面临的数据质量问题有哪些
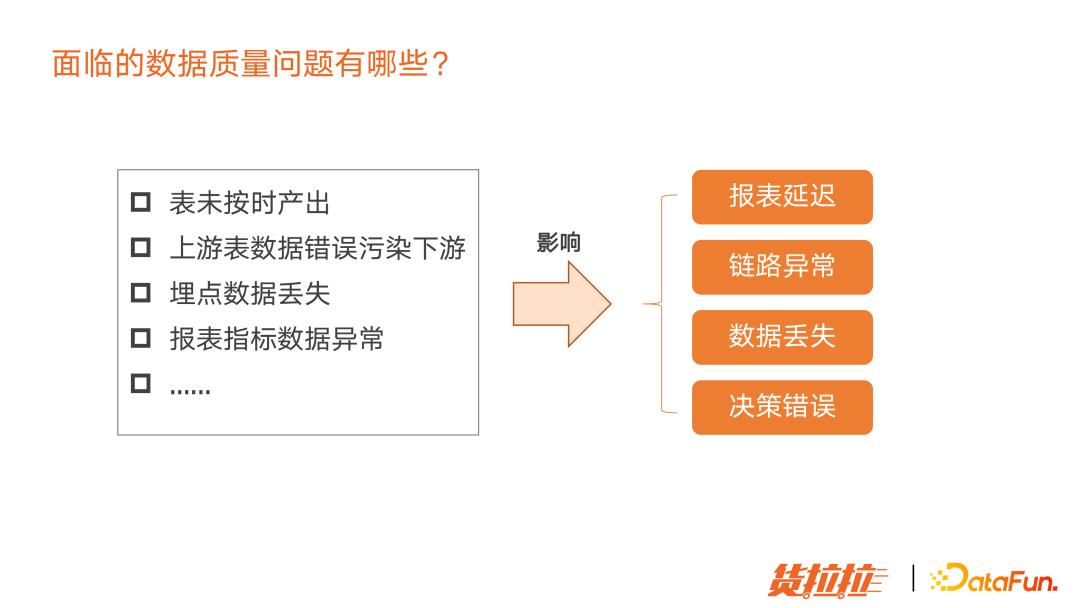
数据开发过程中会遇到很多问题,如:
表未按时产出
上游数据错误,污染下游,导致链路异常
埋点数据丢失,无监控造成数据丢失无法发现
报表数据异常,造成决策错误
2. 产生数据质量问题的原因
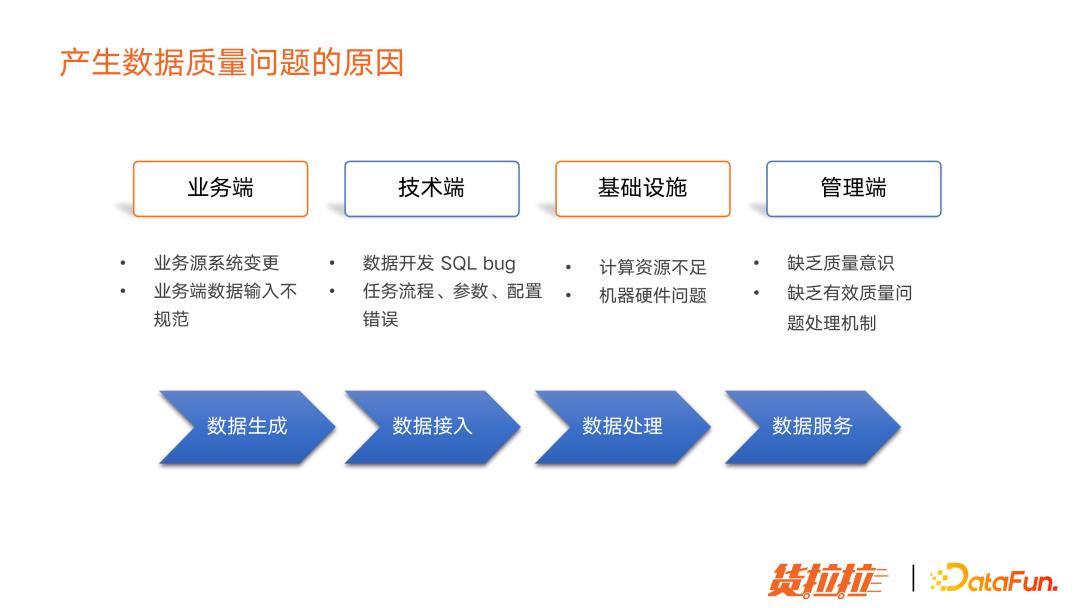
产生数据质量问题的原因,归结为四个方面:
业务端:业务源系统变更,或业务端数据输入不规范,会导致数据生产以及数据接入出现异常。
技术端:数据开发过程中出现的 Bug,或任务参数配置错误,导致任务运行失败。
基础设施:计算资源不足,或网络带宽不足,磁盘被打满,也会影响数据产出。
管理端:缺乏质量意思,缺乏有效质量问题处理机制,质量问题会越来越严重。
3. 数据质量保障思路
分为事前、事中、事后三个部分:
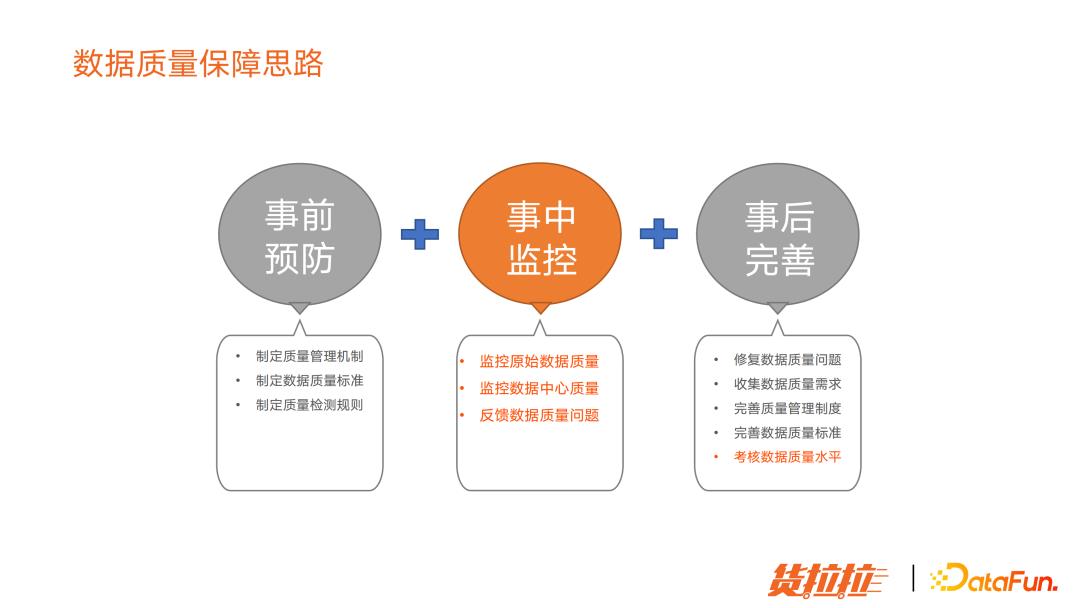
事前:制定机制、标准流程和质量检查规则,预防质量问题。
事中:数据质量平台搭建,可以监控全链路数据质量。
事后:发现质量问题要及时修复,并考核数据链路质量,驱动数据链路负责人做数据质量提升。
4. 货拉拉数据质量平台
货拉拉数据质量平台是一站式数据质量管理平台,用户基本上不用编写代码,就可以完成质量规则配置,完成质量检测,支持自助生成质量报告。
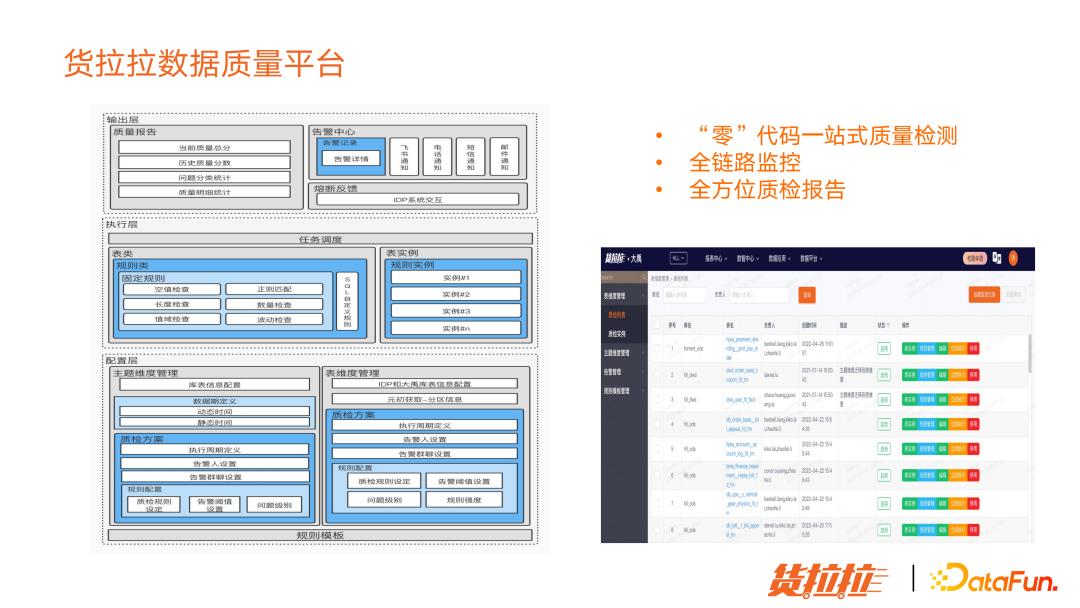
(1)平台特点
零代码一站式质量监测。
支持表维度管理和主题维度管理:表维度是对单张表做质量规则配置,主题维度是对同一类别的表做相同类别的质量配置。
借助了元数据平台中的数据血缘,完成整个数据链路的质量规则配置。
当质量规则配置完成后,会生成一个质量检测任务,用户可以手动触发制定,也可以设置周期性调度执行,也可以去任务调度平台触发执行。因为一个任务对应一些输出表,当输出表落地后,会触发这个表关联的质检规则执行。如果关联的质检规则是强规则,且强规则检测未通过,会阻断下游任务执行,就能阻止数据质量问题进一步扩散。
质检完成后,会生成质量报告;对于质量检测不通过的,会触发告警。严重的会触发熔断。
(2)数据质量平台架构设计
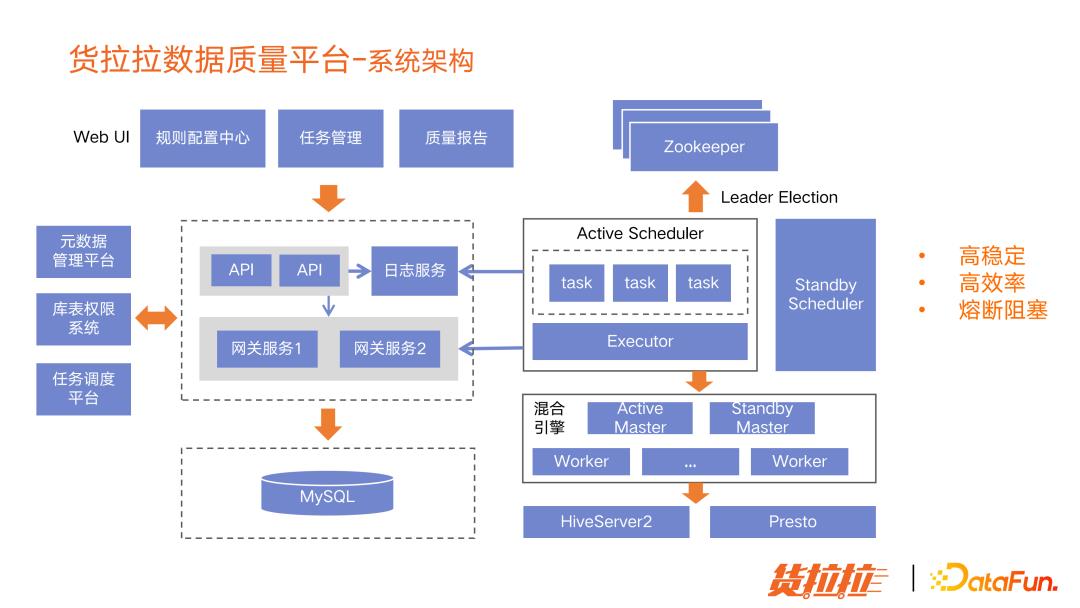
从图中看可以看出,后端的很多服务都是多实例部署的:比如 API 向前端提供接口服务;与数据库所有交互的请求都会走网关服务;还有负责任务调度的服务。API 和网关服务都是无状态的服务,用微服务架构部署的,是多实例部署,如果一个实例挂了,流量会打到另外一个实例上面去,保证稳定性、高可用。
但 Scheduler 是有状态的,因为它上面每时每刻都在运行一些任务,不能只是多实例部署就可以,而是需要主备架构。我们用了 Zookeeper 做 Leader 选举,当一个 Scheduler 挂掉之后,就会把另一个 Scheduler 拉起,把挂掉的 Scheduler 上的任务迁移到新起的 Scheduler 上。这样能保证任务不会挂掉,不会影响到数据质量检测。
最开始计算引擎只用了 Hive,后来用了我们公司自主研发的混合引擎服务,自动会把符合条件的 SQL 录用到 Presto 上去,Presto 是基于内存计算的分析引擎,速度比 Hive 快很多,下面会展示具体的提升效果。
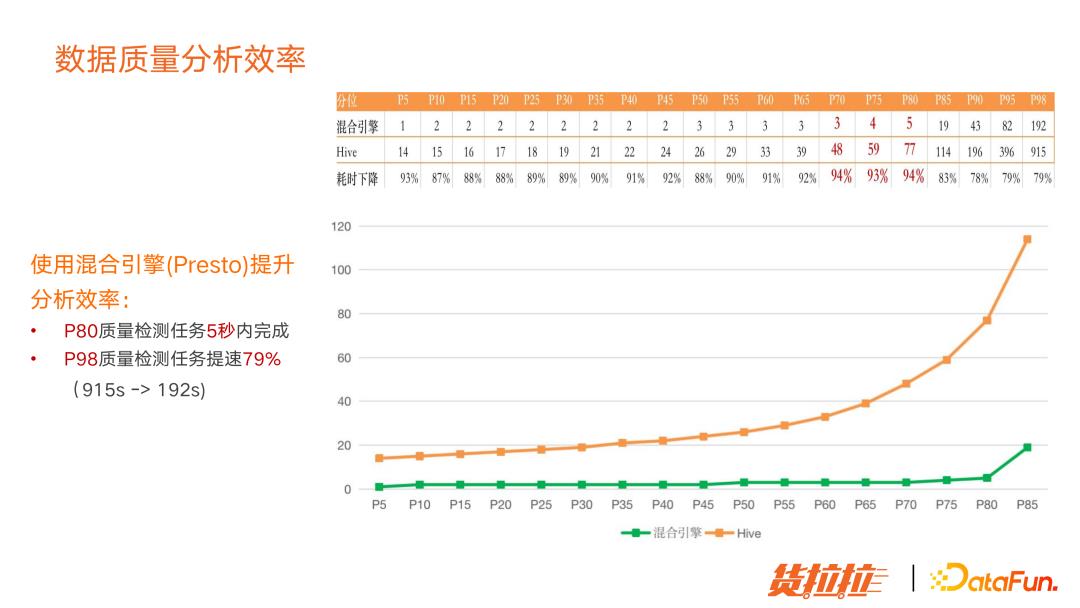
图中展示的效果比较明显,图中绿色折线表示混合引擎的执行效果,黄色的是 Hive 的执行效果。基本混合引擎可以保证 85% 的质量检测任务都会在 20s 内完成。现在 80% 的质量检测任务都会在 5s 内完成,98% 的质量检测任务速度都会有 79% 的提升(之前 Hive 用 915s,现在混合引擎只需 192s),可以大大提升数据质量检测效率,不会影响数据链路的产出时间。
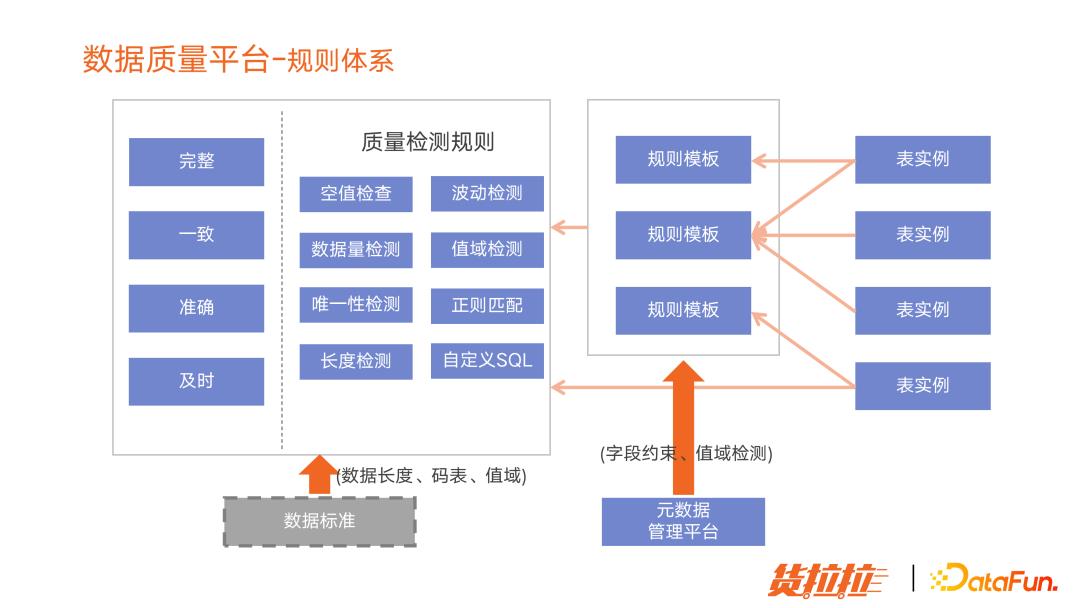
(3)数据质量平台规则体系
包含完整性、准确性、一致性、及时性。
在配置规则的时候,一张表可以应用多个模板,配相应规则。规则模板和规则的区别是,规则模板已经配了相应的阈值和调度时间,以及其他规则信息,只是还没有和表关联,为了提升规则配置效率。
这部分还和元数据平台做了联动:所有建表操作,都会统一在元数据平台完成,所以元数据平台会输入字段约束、值阈检查一些信息给规则模板,这时候规则模板只要和表实例关联,就可以完成规则配置,可以大大提升质量规则提升效率。之后有规划将数据标准管理平台的标准作为输入,如数据长度、码表、值阈等等信息,这样可以进一步节省规则配置的时间。
(4)数据质量平台熔断机制
下面再介绍一下数据质量平台熔断机制的运行流程:
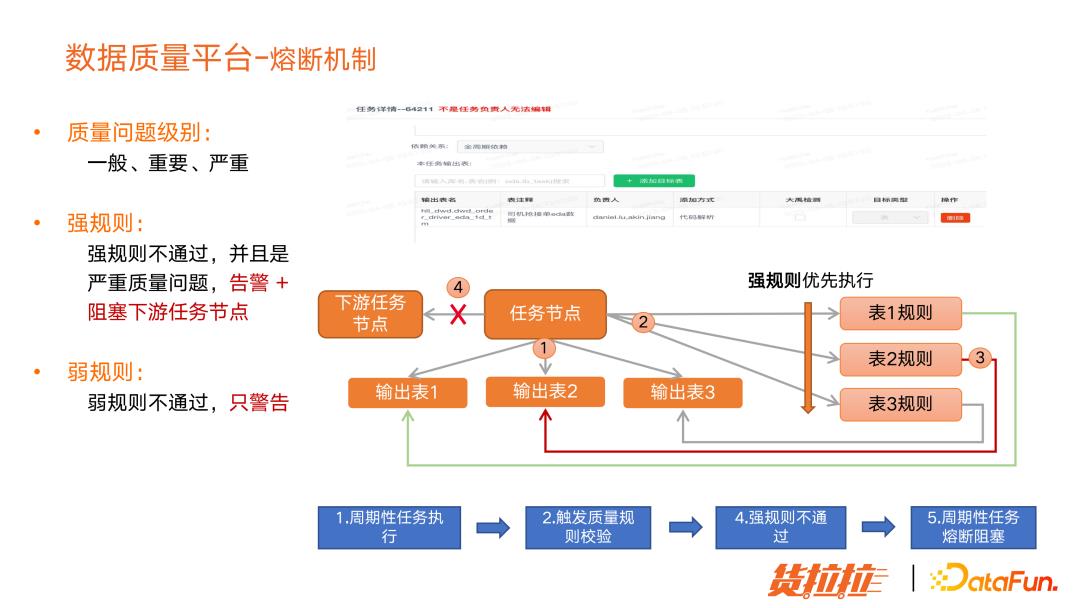
首先任务开发平台里的任务对应多个输出表,当任务被调度执行的时候,会触发质量规则的校验。如果规则不通过,会触发熔断阻塞,下游任务不会执行,让质量问题不会进一步扩散。
(5)数据质量平台质量报告
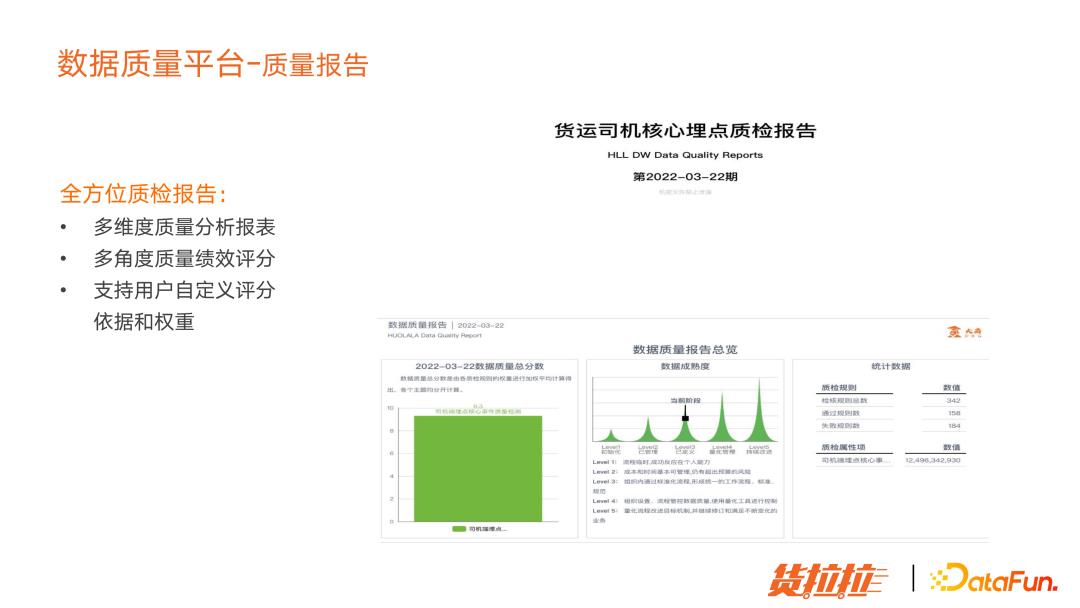
上图是质量报告截图,支持多角度质量绩效分评分,并且支持用户自定义评分依据和权重。
(6)数据质量平台监控告警
监控告警是为了及时发现数据质量问题。
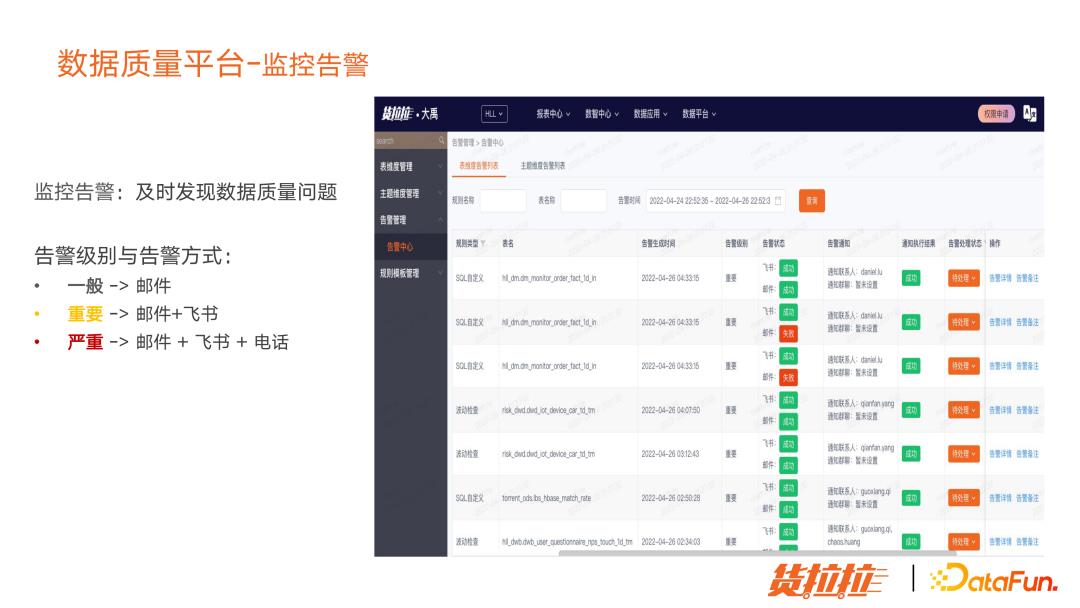
问题主要分为三类:
一般问题:只需要邮件通知
重要问题:邮件+飞书通知
严重问题:邮件+飞书+电话通知
(6)数据质量平台运行现状
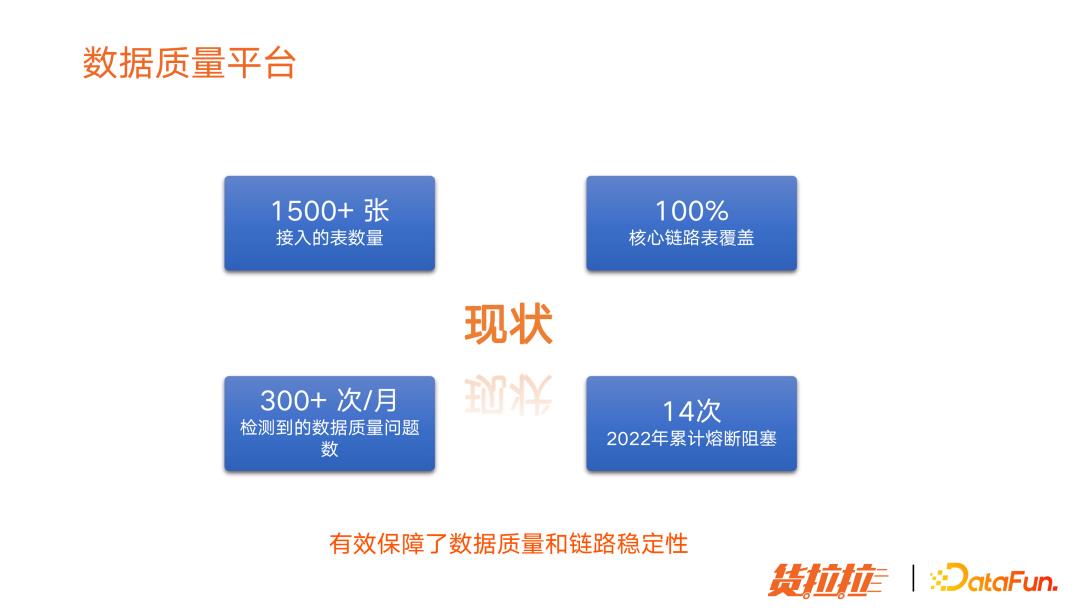
目前已经接入 1500 多张表,每个月都会发生 300 次以上数据质量问题数,今年以来熔断阻塞了 14 次,有效保障了数据质量和链路稳定性。
(7)数据质量平台未来规划
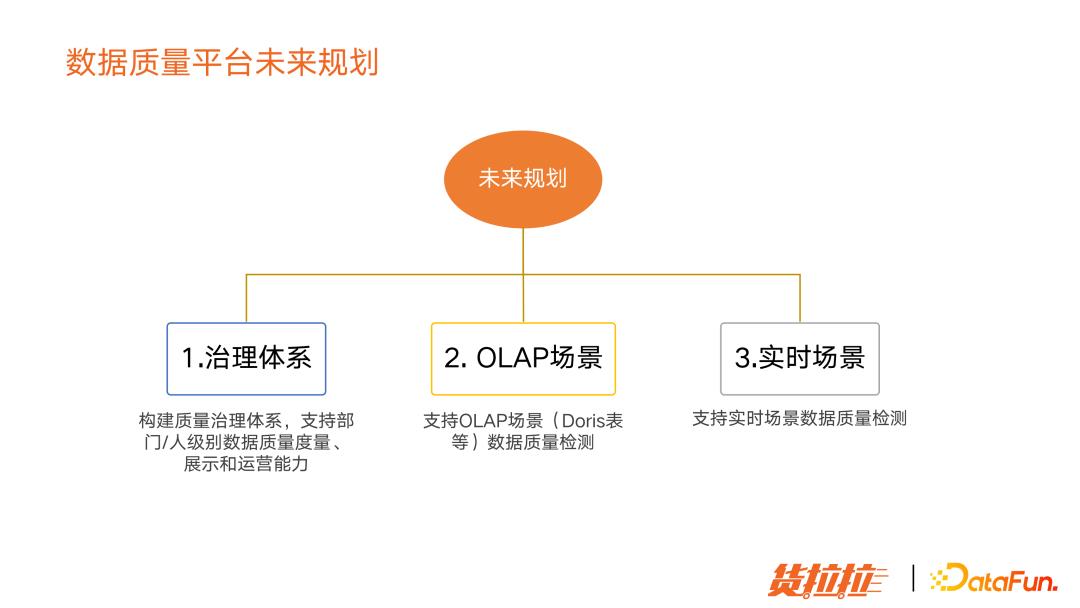
其实现在整体数据质量水平不能直接度量和观察,所以下一步我们要规划整体的质量治理体系,支持自驱的数据质量治理;支持 OLAP 场景的质量检测和实时场景的数据质量检测。
我的介绍就到这里,下面将由张放介绍元数据管理平台,欢迎。
03
元数据平台建设实践
线上的老师同学下午好,接下来将由我为大家介绍货拉拉的元数据管理平台。
大数据体系在发展到一定规模,就会面临:怎样找到需要的数据,如何梳理出上下游关系,数据治理靠什么来驱动,数据资产管理等问题;元数据管理平台就是为了解决以上这些问题。
今天从以下四方面展开元数据管理平台介绍:平台介绍、成本治理体系、数据血缘、未来规划。
1. 平台介绍
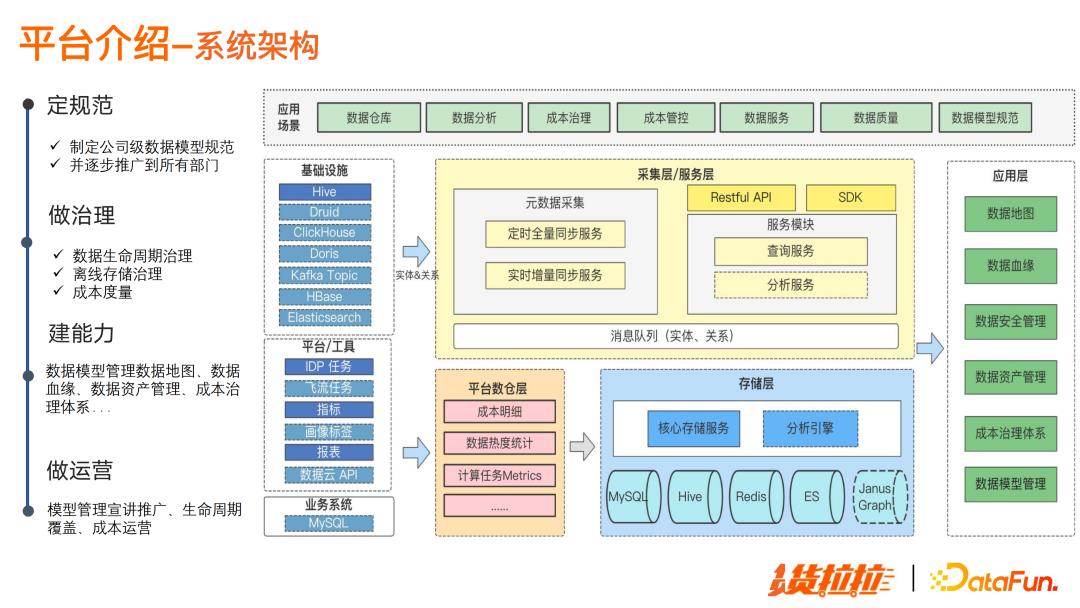
平台的建设思路是:定规范、做治理、建能力、做运营。
系统架构图左边展示了元数据管理平台的基础设施、平台/工具和业务系统;右边的应用层,提供数据地图、数据血缘、数据安全等能力,支撑上层的数据仓库、成本管理、数据分析、数据服务、数据模型等应用场景,在整个数据治理体系中扮演了非常重要的角色。
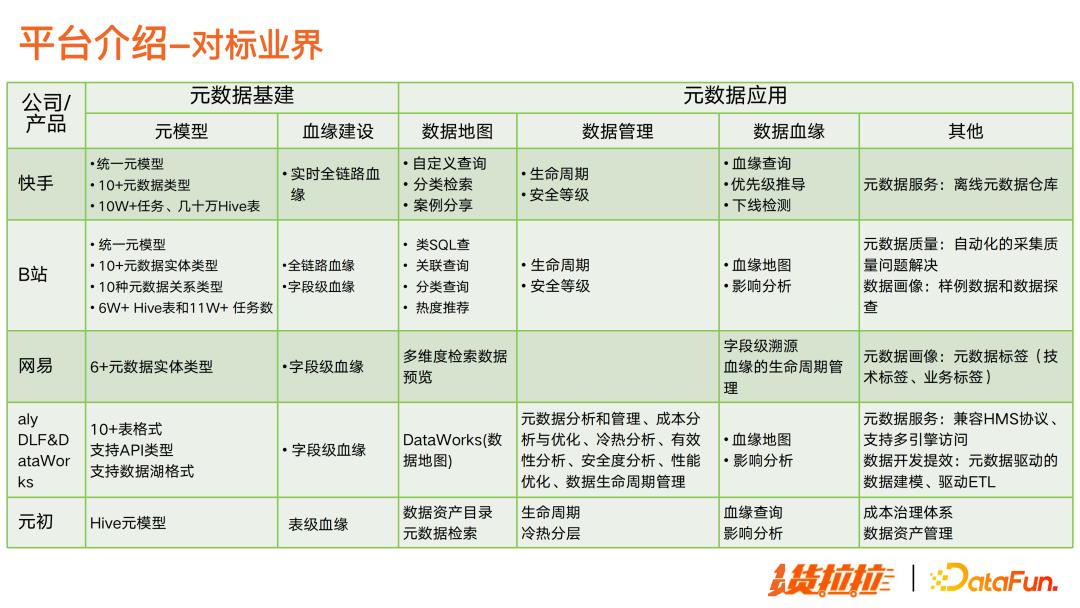
这里也对大厂的元数据平台进行了调研,列举了他们在元数据基建以及核心应用场景的建设情况。
总体来说,大厂元数据管理核心应用场景建设都比较完善。货拉拉元数据管理平台对标大厂,目前处于约 50% 的水平,还处在发展阶段。
2. 成本治理体系
介绍完平台总体框架,下面介绍本次分享的重要部分,成本治理体系。降本增效目前是行业趋势,而建设成本治理体系是数据治理中非常必要的一环。
下面将介绍基于元数据平台,货拉拉在这方面主要做了哪些工作。
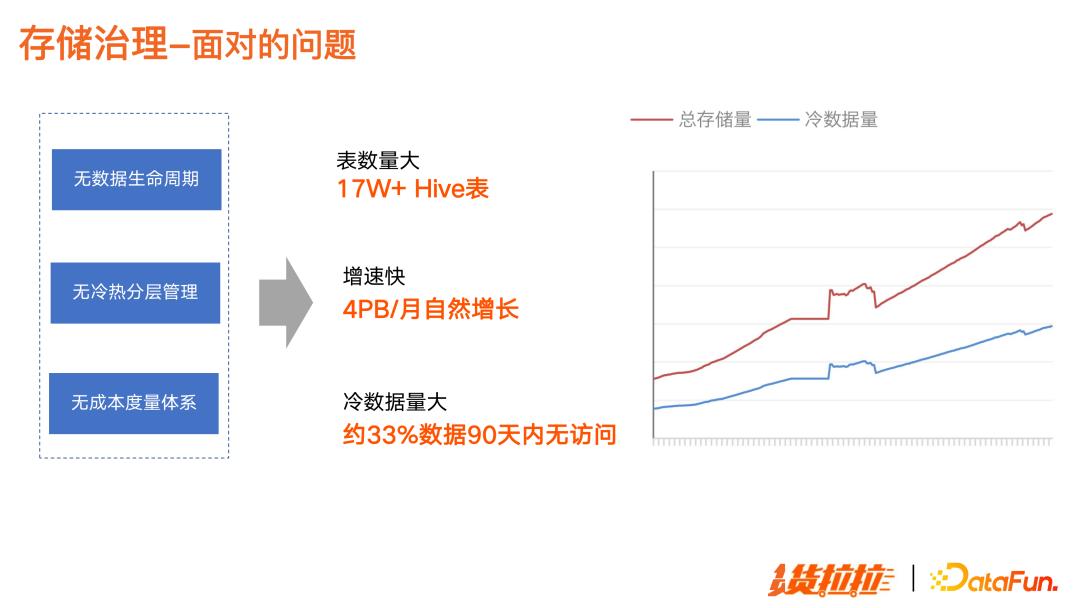
(1)以存储治理为例,在没有治理的情况下,主要面临以下问题:
表数量大
增长快速
冷数据占比多:约33%的数据90天内无访问,但是这些冷数据存储成本消耗和标准存储是一样的,造成很大的成本浪费
(2)围绕存储和计算成本高的问题,建设了成本治理体系。
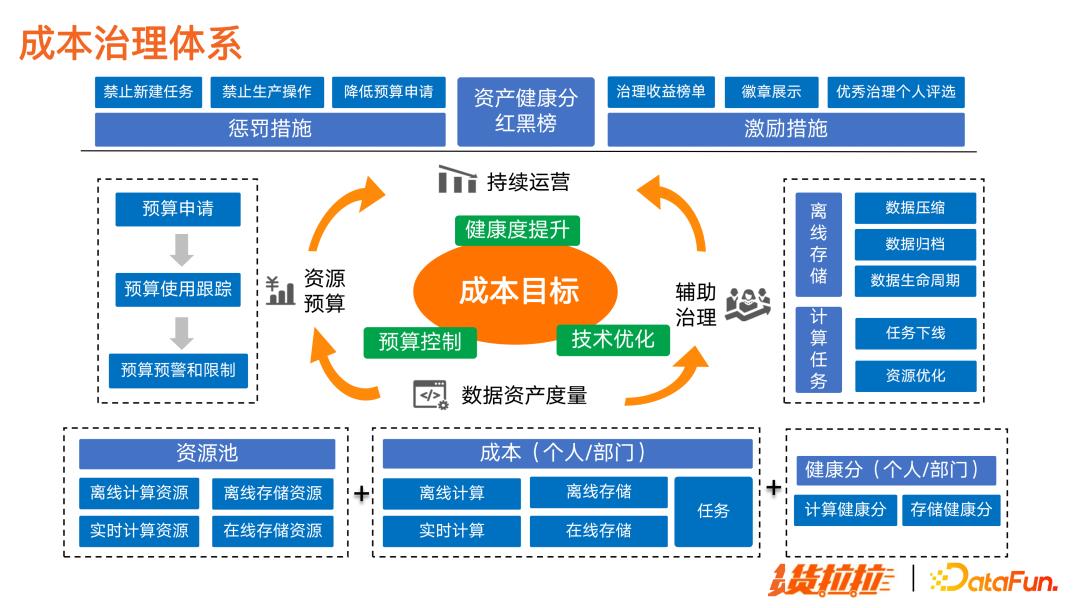
图中是成本治理体系的框架:
首先建立资源预算机制,通过预算预警和限制,从部门层面控制整体成本使用。
其次,落地数据资产度量体系。能够清晰掌握各项资源消耗,并核算成部门和个人级别的成本明细,转换成健康分,就能非常客观地度量成本使用情况。
并且,配合有效的辅助治理措施,对离线存储和计算任务进行技术优化。
有了数据资产度量和辅助治理体系,再推广资产健康分红黑榜,对个人和部门实施奖惩措施,促使用户和业务部门主动参与到成本治理中,提升健康度,形成良性循环,最终达到成本目标。
(3)下面具体介绍成本度量和展示的实现思路:
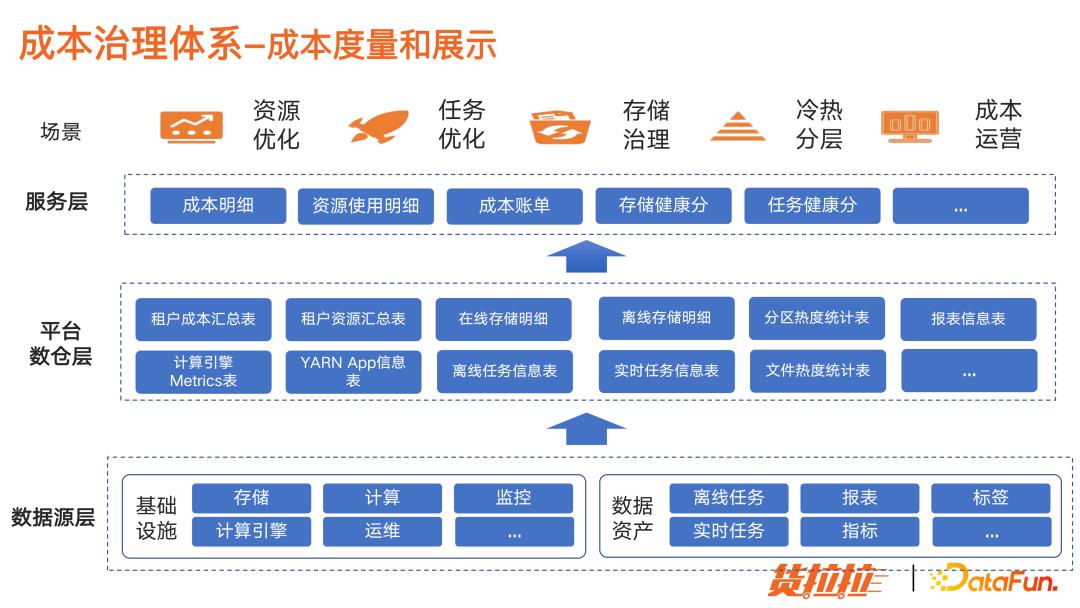
从下至上:
最下面是数据源层,成本消耗主要来自于计算任务产出的表、报表、标签等数据资产,它们分散在基础设施各处。
要度量这些资产的成本数据,需要从各个平台或引擎采集消耗的明细数据,以个人或部门维度统计分析。
经过平台数仓层,加工成可量化展示的成本数据,并根据这些明细数据分析转换成存储和任务的健康分。用户就可以非常直观地知道自己名下哪些任务资源消耗大,哪些表占用存储空间大;为推动任务优化和存储治理提供非常有利的数据支撑。相比以往需要人工核算成本账单,现在自动化统计运营的过程,更加精确高效,也节约了人工成本。
(4)下面再介绍辅助治理的具体方案:
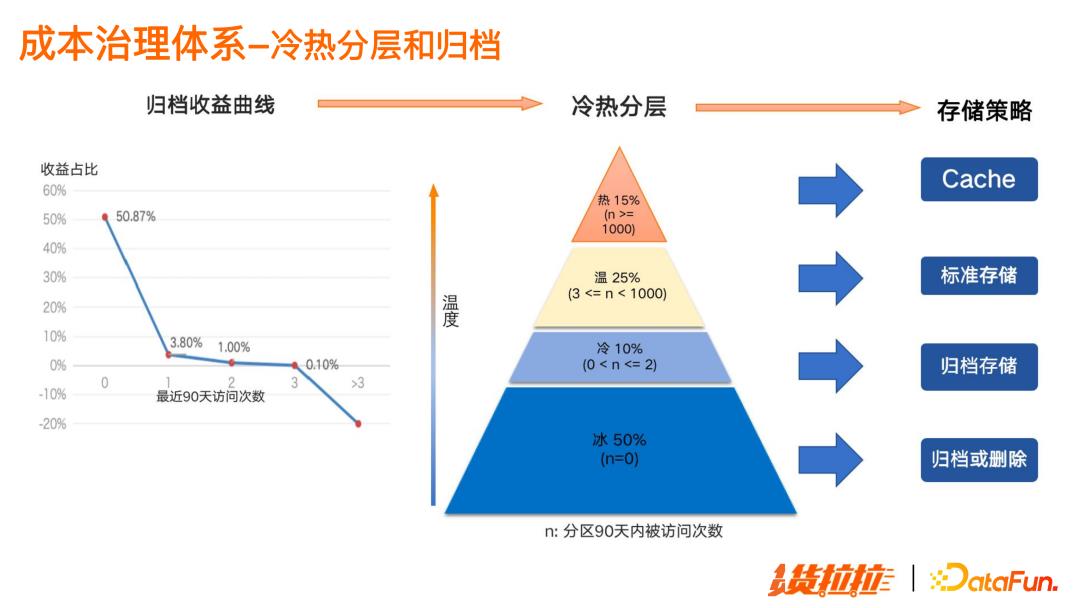
冷热分层和归档
上图左边的曲线,是通过综合分析归档,以及归档后数据取回的花费,得到归档最近 90 天数据被访问次数和收益占比的关系图;通过该关系图可给到分区的冷热分层(即热、温、冷、冰)定义。冰数据占比 50%,热数据仅 15%,分别采用不同的存储策略,分阶段地对冰、冷数据进行归档,降低存储成本。
以下是分层和归档的概要设计:
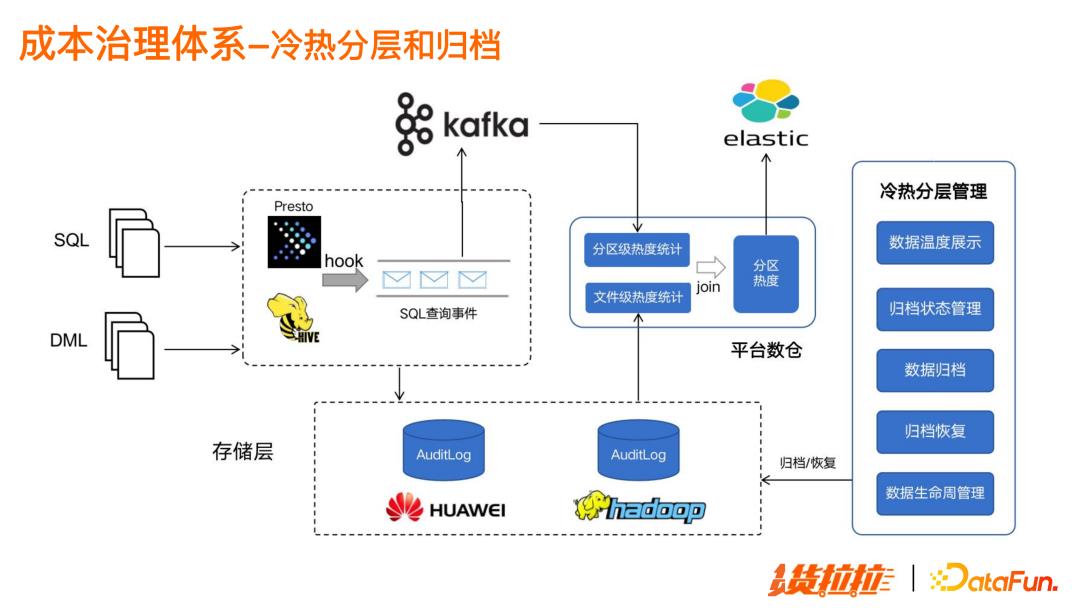
各平台系统提交的 SQL 经过引擎执行,解析为具体的分区访问记录,统计出分区级别的热度信息;采集文件系统的文件记录,得到文件的热度信息,join得到最终的分区热度信息表,根据该信息进行后续的归档工作。
在平台层支持分区温度展示,使用户主动进行分区归档工作。
生命周期管理
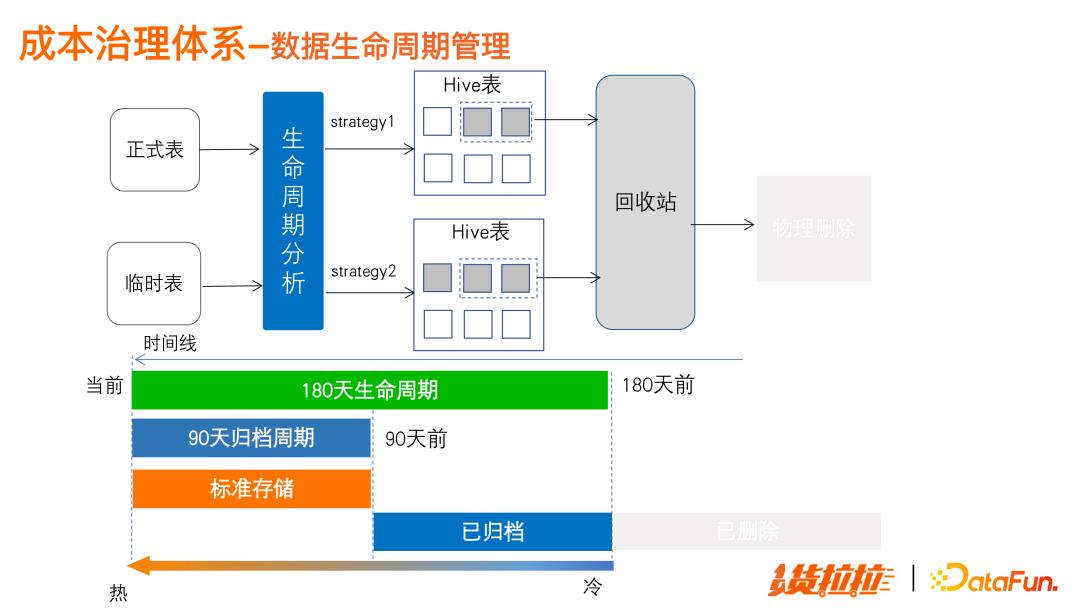
数据生命周期,正式表和临时表采取不同的策略,将超过生命周期的分区滚动式地进行清理操作。
下图是生命周期和归档配合控制表数据的增长。比如,用户设置 180 天生命周期,和 90 天归档周期,生命周期之前的数据将被删除,生命周期内,90 天之前的数据将被归档。
运用这两种辅助治理手段,和数仓同学一起分阶段持续推进存量数据存储治理,初期就能有较可观的收益,同时推广运营产品化能力,全面覆盖增量表,能有效抑制存储增长趋势。
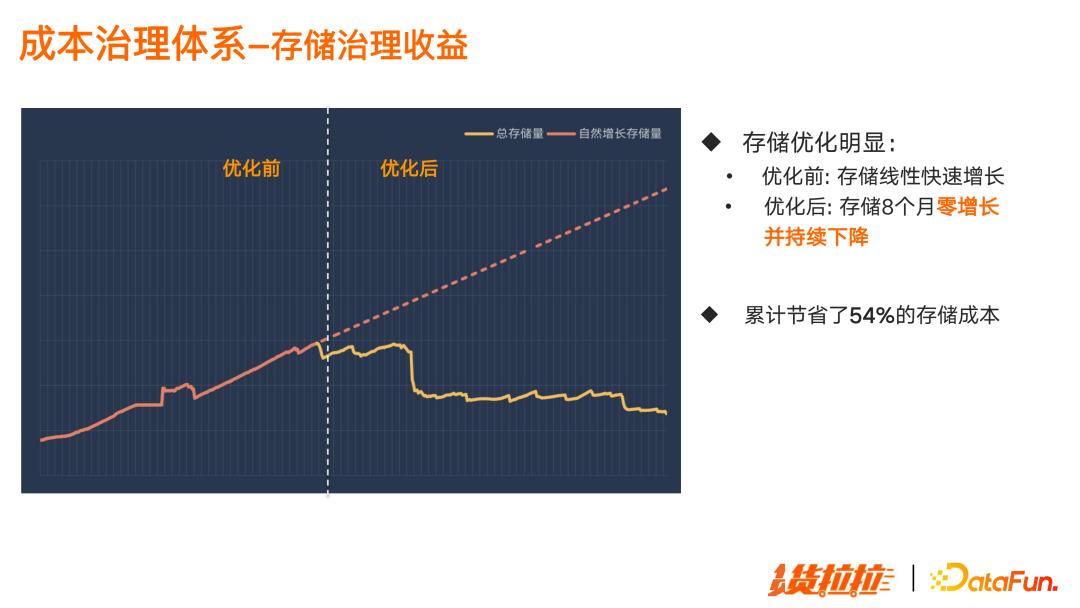
这是目前存储治理的收益情况,优化前存储呈线性快速增长,优化后存储8 个月零增长并持续下降,目前累计节省约 54% 的存储成本。
3. 数据血缘
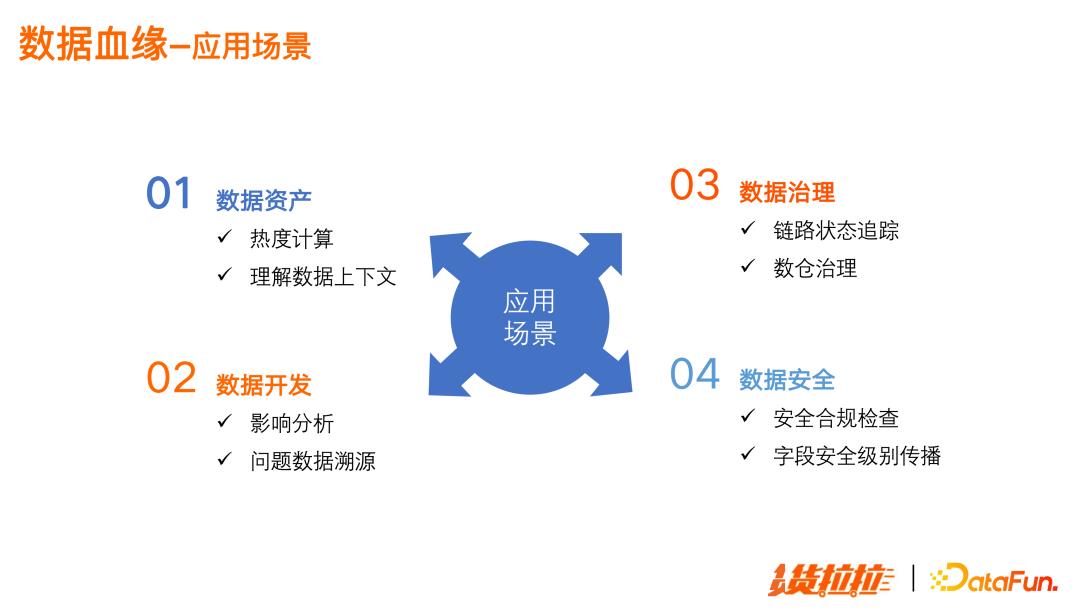
数据血缘主要有四个方面的应用场景:
数据资产:提供数据资产的热度统计,帮助理解数据上下文
数据开发:支持影响分析和问题数据溯源
数据治理:链路状态追踪,帮助数仓进行治理工作
数据安全:安全合规检查以及字段安全级别传播
以下是数据血缘的架构图:
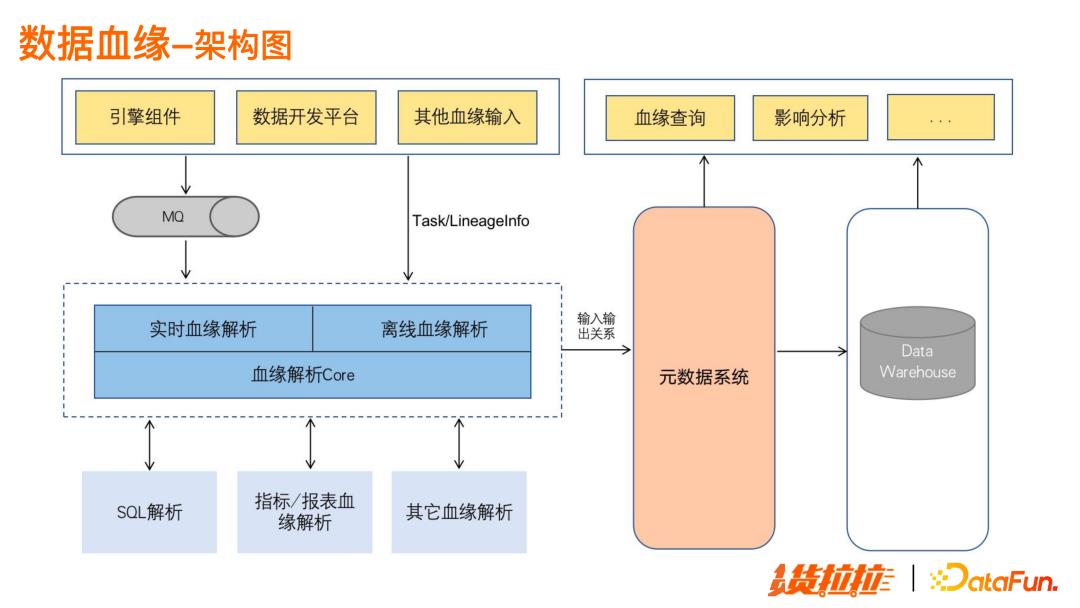
从引擎组件、大数据开发平台等,采集血缘信息和对应任务信息,经实时和离线解析,包括 SQL 解析和指标/报表血缘解析等,将解析出来的输入输出关系落到元数据系统中,供上层查询,并提供影像分析等能力。
4. 未来规划
元数据的未来规划,围绕以下四方面建设:
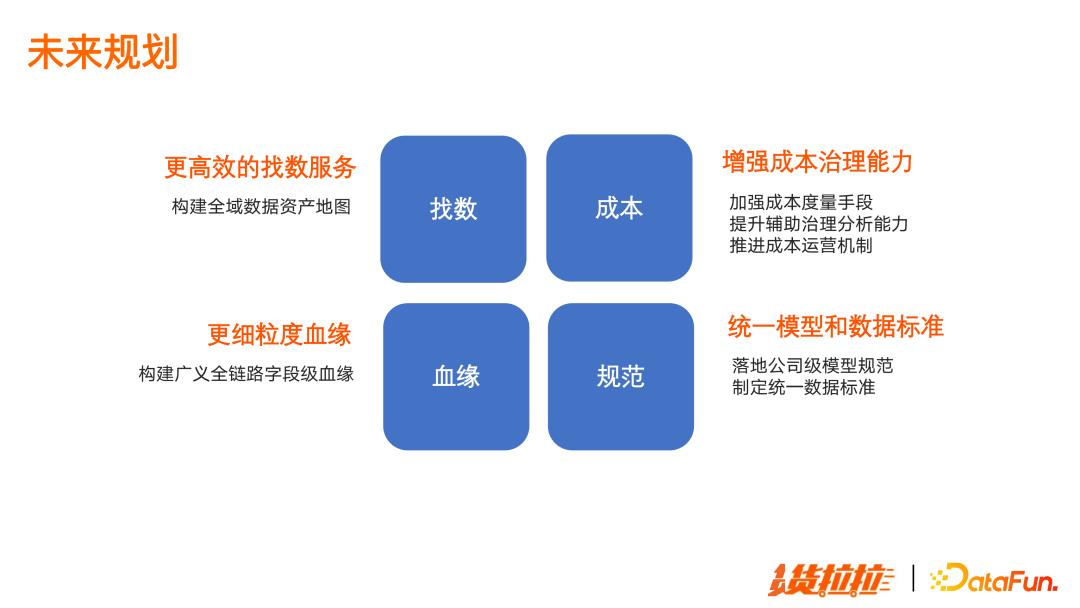
更高效的找数服务
更细粒度的血缘
增强成本治理能力
推广统一模型和数据标准
今天的分享就到这里,谢谢大家。关注公众号,获取技术文章。
🧐 分享、点赞、在看,给个3连击呗!👇
以上是关于货拉拉数据治理平台建设实践的主要内容,如果未能解决你的问题,请参考以下文章