elasticsearch插件之ik分词器
Posted hengzhi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elasticsearch插件之ik分词器相关的知识,希望对你有一定的参考价值。
ES默认对英文文本的分词器支持较好,但和lucene一样,如果需要对中文进行全文检索,那么需要使用中文分词器,同lucene一样,在使用中文全文检索前,需要集成IK分词器。
可以从GitHub上获取:https://github.com/medcl/elasticsearch-analysis-ik
因为是源码,我们要用到maven对其进行打包,因此你需要安装maven。
环境:centos6.9、elasticsearsh5.6.5、java1.8
1、下载
在GitHub上获取与easticsearch对应的ik分词器版本。我下载的是elasticsearch-analysis-ik-5.6.5.zip
2、打包
在本地解压,从dom窗口进入ik分词器的解压目录,
执行maven打包命令:
mvn install

在解压目录找到target/releases/elasticsearch-analysis-ik-5.2.2.zip文件
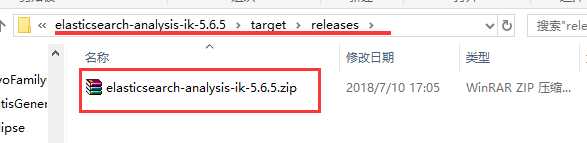
3、上传、解压
将此文件用fit协议上传到elasticsearch的插件目录下(elasticsearch安装目录里的plugins目录)

解压
unzip elasticsearch-analysis-ik-5.6.5.zip
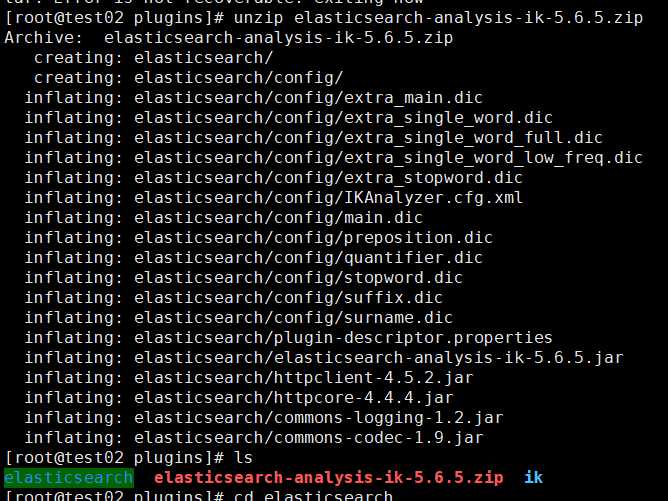
重命名
mv elasticsearch ik
删除压缩包
rm -rf elasticsearch-analysis-ik-5.6.5.zip

4、重启ES
5、测试分词器
POST _analyze
{
"analyzer":"ik_smart",
"text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
用kibana插件的测试效果如下:
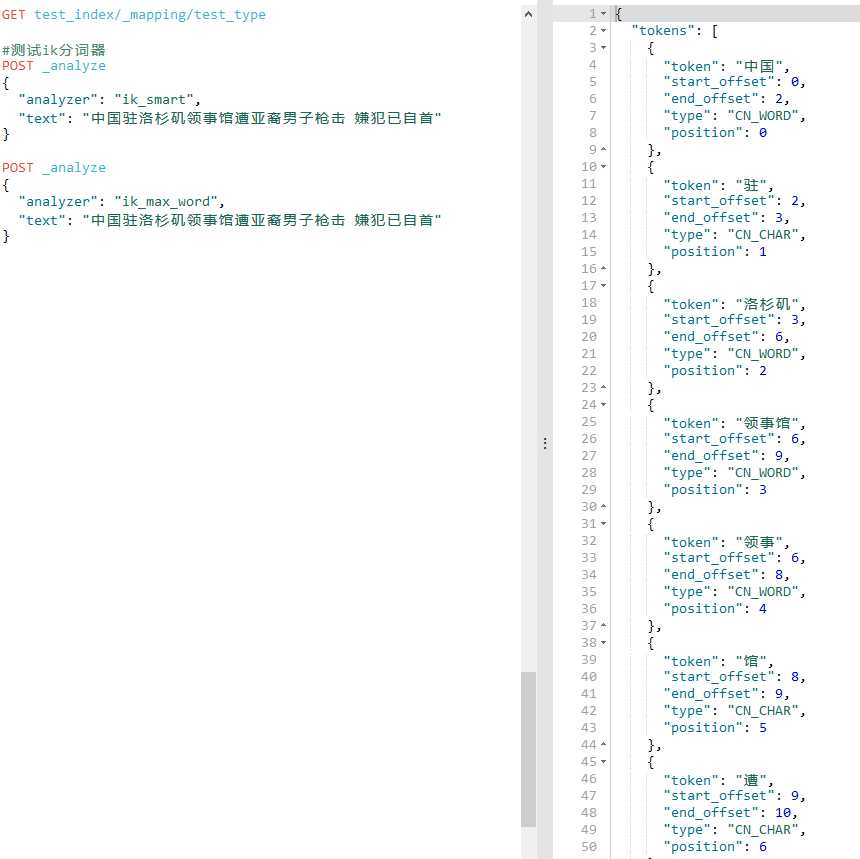
说明成功啦!
注意:IK分词器有两种类型,分别是ik_smart分词器和ik_max_word分词器。
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
以上是关于elasticsearch插件之ik分词器的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch之中文分词器插件es-ik的热更新词库
Elasticsearch之中文分词器插件es-ik的自定义词库
Elasticsearch之中文分词器插件es-ik的热更新词库